elasticsearch实现入库分词,查询不分词,实现like关键字%
因为在工作中遇到一个需求,需要对请求内容实现类似于mysql的 like "关键字%" 模糊匹配功能,同时要保证效率大数据量效率问题,因此不能使用wildcard在网上看了很多也不太好使,自己琢磨了一下成功了,该功能仅对非中文存储的字段有效果,使用termquery去匹配自己也可以尝试别的方法,特此记录一下,项目使用spring-data-elasticsearch4.0.9(对应elasticsearch版本7.6.2)我本地装的7.9.3也兼容、spring-boot-starter-data-elasticsearch2.3.12
一、主要思路:
使用edge_ngram实现对数据入库时的金字塔式分词,如“0-1-2”会被分词为
“0”
“0-”
“0-1”
“0-1-”
“0-1-2”
查询时使用ik_smart分词器,该分词器插件会对中文进行最大颗粒度的分词,而我在数据中使用的都是非中文内容,它识别不出来,因此查询“0-1-2”内容时,效果等同于不会被分词的结果“0-1-2”,这样就可以实现对“0-1-2”分词后的结果类似于sql中like"0-1-2%"的效果。
二、具体实现:
1.索引配置(实体类映射)
设置配置在resources/es-config/settings.json
{
"index": {
"max_result_window": 10000,# 最大查询深度
"number_of_shards": 8,# 存储数据分片数量
"number_of_replicas": 1,# 副本数量
"analysis": { # 分词器集合
"filter": {
"edge_ngram_filter": {
"type": "edge_ngram", # edge_ngram分词器
"min_gram": 1, # 字段最小分词字符个数 例如“123” 会被分词为 “1”
"max_gram": 35 # 字段最大分词数量 例如 设置为3 “12345” 会被分词为 “1”“12”“123”
}
},
"analyzer": {
"custom_pyramid_analyzer": {
"type": "custom",
"tokenizer": "keyword",
"filter": [
"edge_ngram_filter" # 对应上面的filter名称
]
}
}
}
}
}
2.实体类映射
关于ik分词器插件的安装可以参考这片文章
elasticsearch IK分词器的安装、使用与扩展
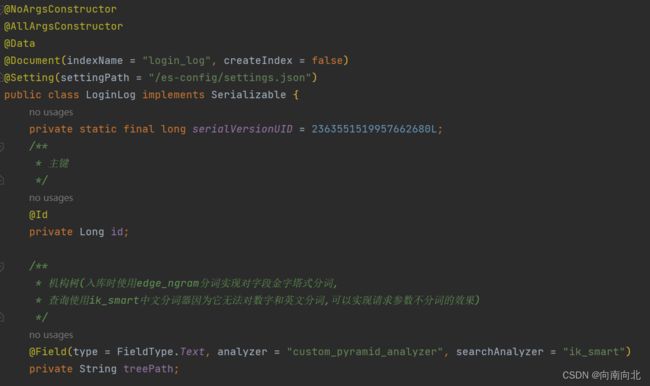
3. 数据新增(此处省略)
新增3条数据进行测试: "0-1-0"、"0-1-0-2"、"0-1-0-2-3"
4.查询效果,注意使用termquery
{
"from": 0,
"size":20,
"query": {
"term": {
"treePath": "0-1-0"
}
}
}
查询条件“0-1-0”,三条记录都查出来了,因为三条记录里都有0-1-0开头
{
"from": 0,
"size":20,
"query": {
"term": {
"treePath": "1-0-2"
}
}
}
查询条件“1-0-2”,一条都查不出来,因为说明请求参数没有分词,尽管记录中包含该内容
{
"from": 0,
"size":20,
"query": {
"term": {
"treePath": "0-1-0-2"
}
}
}
查询条件“0-1-0-2”,查到了第二和第三条,因为它们都是0-1-0-2开头的
到这里基本验证完毕,不会发生 like '%关键字%'的情况,也没有发生请求参数被分词的情况。