基于pytorch的SSD模型训练
SSD模型论文:https://blog.csdn.net/quincuntial/article/details/78854930
汉化
0、环境准备:
ubuntu18.04.4系统,pytorch1.2.0,CUDN10,CUDNN7.4.2,GPU为GTX1050
1、训练前的准备:
VOC数据集的准备,使用ImafeLable或其他数据集标注工具,将原始数据集转换为VOC数据集,使用ImageLable刚开始会出现两个文件夹,分别为Annotations、JPEGImages文件夹,我们还需要创建一个ImageSets文件夹,里面有一个Main文件夹,在ImageSets/Main文件夹中有四个txt文件,分别为test.txt,trainval.txt,train.txt和testval.txt,使用转换脚本transport.py:
import os
import random
trainval_percent = 0.8
train_percent = 0.5
xmlfilepath = 'VOC2007/Annotations/'
txtsavepath = 'VOC2007/ImageSets/Main/'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open(txtsavepath+'/trainval.txt', 'w')
ftest = open(txtsavepath+'/test.txt', 'w')
ftrain = open(txtsavepath+'/train.txt', 'w')
fval = open(txtsavepath+'/testval.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
可以得到四个txt文件
2、下载SSD-pytorch代码
代码下载:https://github.com/amdegroot/ssd.pytorch
预训练模型下载:https://download.csdn.net/download/qq_34374211/10712378
3、参数修改:
首先我们要知道自己数据集含有的类别(注:背景也算一类)
(1)config.py

打开config.py,可以找到这样一段代码,要修改的就是num_class(类别数),更具自己数据集的实际情况进行修改。至于max_iter指的是最大迭代数,在尝试训练阶段,建议把它调低,比如调到1000,在确认训练过程没有问题之后,在调大迭代次数。这样可以有效的节约训练时间。
(2)VOC0712.py

因为我是用的VOC格式的数据集,所以要在VOC0712.py处理数据。按照自己的数据的类别进行修改。(注:如果你的类别只有一类,voc_classes的小括号外面要加上中括号)
(3)train.py

要训练自己的数据集,在这个train.py中我们必须要修改的是预训练的模型,根据自己的下载的预训练模型修改,官方提供的是VGG16_reducedfc_pth,链接已提供。批处理数根据排至修改,batch_size越大对显卡的内存要求就越大,我使用的是NVIDIA 1050 2G ,batch_size大小使用1. (根据经验,batch_size大小适宜,训练效果会更好)
Batch Size从小到大的变化对网络影响
1、没有Batch Size,梯度准确,只适用于小样本数据库
2、Batch Size=1,梯度变来变去,非常不准确,网络很难收敛。
3、Batch Size增大,梯度变准确,
4、Batch Size增大,梯度已经非常准确,再增加Batch Size也没有用
注意:Batch Size增大了,要到达相同的准确度,必须要增大epoch。

在尝试阶段,为了节省时间,建议将根据迭代次数保存模型的参数调低,例如调节到500。之后正式开始训练后在调高。
(4)eval.py
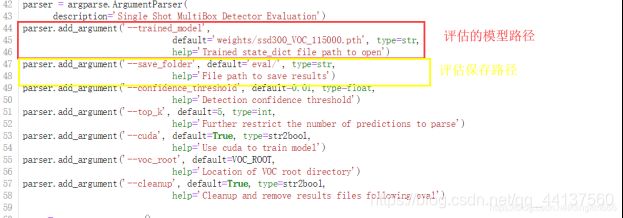
在训练得到模型之后,要修改评估的模型的名。
(5)ssd.py

4、可能遇到的问题
(1)

解决方法:

(2)自动跳出迭代:
解决方法:

(3)loss为nan:
解决方法:
![]()
这个问题是由学习率够高引起的,只需降低学习率即可,loss出现一直nan会导致训练出来的模型检测不出来任何东西。
(4)IndexError: too many indices for array
注意:该错误可能是由两个原因引起的:
a、.xml对应的图片为空(即因意外丢失了数据)
该错误可用以下代码检查,如果确为数据丢失,换数据集吧
import argparse
import sys
import cv2
import os
import os.path as osp
import numpy as np
if sys.version_info[0] == 2:
import xml.etree.cElementTree as ET
else:
import xml.etree.ElementTree as ET
parser = argparse.ArgumentParser(
description='Single Shot MultiBox Detector Training With Pytorch')
train_set = parser.add_mutually_exclusive_group()
parser.add_argument('--root', default='data/VOC2007' , help='Dataset root directory path')
args = parser.parse_args()
CLASSES = ( # always index 0
'person','car','diningtable','dog')
annopath = osp.join('%s', 'Annotations', '%s.{}'.format("xml"))
imgpath = osp.join('%s', 'JPEGImages', '%s.{}'.format("jpg"))
def vocChecker(image_id, width, height, keep_difficult = False):
target = ET.parse(annopath % image_id).getroot()
res = []
for obj in target.iter('object'):
difficult = int(obj.find('difficult').text) == 1
'''if not keep_difficult and difficult:
continue'''
name = obj.find('name').text.lower().strip()
bbox = obj.find('bndbox')
pts = ['xmin', 'ymin', 'xmax', 'ymax']
bndbox = []
for i, pt in enumerate(pts):
cur_pt = int(bbox.find(pt).text) - 1
# scale height or width
cur_pt = float(cur_pt) / width if i % 2 == 0 else float(cur_pt) / height
bndbox.append(cur_pt)
print(name)
label_idx = dict(zip(CLASSES, range(len(CLASSES))))[name]
bndbox.append(label_idx)
print(bndbox)
res += [bndbox] # [xmin, ymin, xmax, ymax, label_ind]
# img_id = target.find('filename').text[:-4]
print(res)
try :
print(np.array(res)[:,4])
print(np.array(res)[:,:4])
except IndexError:
print("\nINDEX ERROR HERE !\n")
exit(0)
return res # [[xmin, ymin, xmax, ymax, label_ind], ... ]
if __name__ == '__main__' :
i = 0
for name in sorted(os.listdir(osp.join(args.root,'Annotations'))):
# as we have only one annotations file per image
i += 1
img = cv2.imread(imgpath % (args.root,name.split('.')[0]))
height, width, channels = img.shape
print("path : {}".format(annopath % (args.root,name.split('.')[0])))
res = vocChecker((args.root, name.split('.')[0]), height, width)
print("Total of annotations : {}".format(i))
b、.xml文件中中的值不为0
即下图红框中的值为1:

解决方案:

将图中红框部分注释,在文件VOC0712中。
5、测试结果:
使用GTX1050跑了3个小时,LOSS降到了1左右,精度为0.6086,效果如下所示:

