k8s搭建EFK日志系统
搭建 EFK 日志系统
前面大家介绍了 Kubernetes 集群中的几种日志收集方案,Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch、Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案。
Elasticsearch 是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大量日志数据,也可用于搜索许多不同类型的文档。
Elasticsearch 通常与 Kibana 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 允许你通过 web 界面来浏览 Elasticsearch 日志数据。
Fluentd是一个流行的开源数据收集器,我们将在 Kubernetes 集群节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
我们先来配置启动一个可扩展的 Elasticsearch 集群,然后在 Kubernetes 集群中创建一个 Kibana 应用,最后通过 DaemonSet 来运行 Fluentd,以便它在每个 Kubernetes 工作节点上都可以运行一个 Pod。
安装 Elasticsearch 集群
在创建 Elasticsearch 集群之前,我们先创建一个命名空间,我们将在其中安装所有日志相关的资源对象。
$ kubectl create ns logging
环境准备
ElasticSearch 安装有最低安装要求,如果安装后 Pod 无法正常启动,请检查是否符合最低要求的配置,要求如下:

这里我们要安装的 ES 集群环境信息如下所示:

这里我们使用一个 NFS 类型的 StorageClass 来做持久化存储,当然如果你是线上环境建议使用 Local PV 或者 Ceph RBD 之类的存储来持久化 Elasticsearch 的数据。
此外由于 ElasticSearch 7.x 版本默认安装了 X-Pack 插件,并且部分功能免费,需要我们配置一些安全证书文件。
1、生成证书文件
# 运行容器生成证书,containerd下面用nerdctl
$ mkdir -p elastic-certs
$ nerdctl run --name elastic-certs -v elastic-certs:/app -it -w /app elasticsearch:7.17.3 /bin/sh -c \
"elasticsearch-certutil ca --out /app/elastic-stack-ca.p12 --pass '' && \
elasticsearch-certutil cert --name security-master --dns \
security-master --ca /app/elastic-stack-ca.p12 --pass '' --ca-pass '' --out /app/elastic-certificates.p12"
# 删除容器
$ nerdctl rm -f elastic-certs
# 将 pcks12 中的信息分离出来,写入文件
$ cd elastic-certs && openssl pkcs12 -nodes -passin pass:'' -in elastic-certificates.p12 -out elastic-certificate.pem
需要注意 nerdctl 如果是 v0.20.0 版本,需要更新 CNI 插件版本,否则会出现错误
FATA[0000] failed to create shim: OCI runtime create failed: container_linux.go:380: starting container process caused: process_linux.go:545: container init caused: Running hook #0:: error running hook: exit status 1, stdout: , stderr: time="2022-06-06T16:37:03+08:00" level=fatal msg="failed to call cni.Setup: plugin type=\"bridge\" failed (add): incompatible CNI versions; config is \"1.0.0\", plugin supports [\"0.1.0\" \"0.2.0\" \"0.3.0\" \"0.3.1\" \"0.4.0\"]",将 CNI 插件从 https://github.com/containernetworking/plugins/releases/download/v1.1.1/cni-plugins-linux-amd64-v1.1.1.tgz 下载下来覆盖/opt/cni/bin目录即可。
2、添加证书到 Kubernetes
# 添加证书
$ kubectl create secret -n logging generic elastic-certs --from-file=elastic-certificates.p12
# 设置集群用户名密码
$ kubectl create secret -n logging generic elastic-auth --from-literal=username=elastic --from-literal=password=ydzsio321
安装 ES 集群
首先添加 ELastic 的 Helm 仓库:
$ helm repo add elastic https://helm.elastic.co
$ helm repo update
ElaticSearch 安装需要安装三次,分别安装 Master、Data、Client 节点,Master 节点负责集群间的管理工作;Data 节点负责存储数据;Client 节点负责代理 ElasticSearch Cluster 集群,负载均衡。
首先使用 helm pull 拉取 Chart 并解压:
$ helm pull elastic/elasticsearch --untar --version 7.17.3
$ cd elasticsearch
在 Chart 目录下面创建用于 Master 节点安装配置的 values 文件:
# values-master.yaml
## 设置集群名称
clusterName: 'elasticsearch'
## 设置节点名称
nodeGroup: 'master'
## 设置角色
roles:
master: 'true'
ingest: 'false'
data: 'false'
# ============镜像配置============
## 指定镜像与镜像版本
image: 'elasticsearch'
imageTag: '7.17.3'
imagePullPolicy: 'IfNotPresent'
## 副本数
replicas: 3
# ============资源配置============
## JVM 配置参数
esJavaOpts: '-Xmx1g -Xms1g'
## 部署资源配置(生成环境要设置大些)
resources:
requests:
cpu: '2000m'
memory: '2Gi'
limits:
cpu: '2000m'
memory: '2Gi'
## 数据持久卷配置
persistence:
enabled: true
## 存储数据大小配置
volumeClaimTemplate:
storageClassName: local-path
accessModes: ['ReadWriteOnce']
resources:
requests:
storage: 5Gi
# ============安全配置============
## 设置协议,可配置为 http、https
protocol: http
## 证书挂载配置,这里我们挂入上面创建的证书
secretMounts:
- name: elastic-certs
secretName: elastic-certs
path: /usr/share/elasticsearch/config/certs
defaultMode: 0755
## 允许您在/usr/share/elasticsearch/config/中添加任何自定义配置文件,例如 elasticsearch.yml、log4j2.properties
## ElasticSearch 7.x 默认安装了 x-pack 插件,部分功能免费,这里我们配置下
## 下面注掉的部分为配置 https 证书,配置此部分还需要配置 helm 参数 protocol 值改为 https
esConfig:
elasticsearch.yml: |
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.enabled: true
# xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
## 环境变量配置,这里引入上面设置的用户名、密码 secret 文件
extraEnvs:
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-auth
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-auth
key: password
# ============调度配置============
## 设置调度策略
## - hard:只有当有足够的节点时 Pod 才会被调度,并且它们永远不会出现在同一个节点上
## - soft:尽最大努力调度
antiAffinity: 'soft'
# tolerations:
# - operator: "Exists" ##容忍全部污点
然后创建用于 Data 节点安装的 values 文件:
# values-data.yaml
# ============设置集群名称============
## 设置集群名称
clusterName: 'elasticsearch'
## 设置节点名称
nodeGroup: 'data'
## 设置角色
roles:
master: 'false'
ingest: 'true'
data: 'true'
# ============镜像配置============
## 指定镜像与镜像版本
image: 'elasticsearch'
imageTag: '7.17.3'
## 副本数(建议设置为3,我这里资源不足只用了1个副本)
replicas: 3
# ============资源配置============
## JVM 配置参数
esJavaOpts: '-Xmx1g -Xms1g'
## 部署资源配置(生成环境一定要设置大些)
resources:
requests:
cpu: '1000m'
memory: '2Gi'
limits:
cpu: '1000m'
memory: '2Gi'
## 数据持久卷配置
persistence:
enabled: true
## 存储数据大小配置
volumeClaimTemplate:
storageClassName: local-path
accessModes: ['ReadWriteOnce']
resources:
requests:
storage: 10Gi
# ============安全配置============
## 设置协议,可配置为 http、https
protocol: http
## 证书挂载配置,这里我们挂入上面创建的证书
secretMounts:
- name: elastic-certs
secretName: elastic-certs
path: /usr/share/elasticsearch/config/certs
## 允许您在/usr/share/elasticsearch/config/中添加任何自定义配置文件,例如 elasticsearch.yml
## ElasticSearch 7.x 默认安装了 x-pack 插件,部分功能免费,这里我们配置下
## 下面注掉的部分为配置 https 证书,配置此部分还需要配置 helm 参数 protocol 值改为 https
esConfig:
elasticsearch.yml: |
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.enabled: true
# xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
## 环境变量配置,这里引入上面设置的用户名、密码 secret 文件
extraEnvs:
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-auth
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-auth
key: password
# ============调度配置============
## 设置调度策略
## - hard:只有当有足够的节点时 Pod 才会被调度,并且它们永远不会出现在同一个节点上
## - soft:尽最大努力调度
antiAffinity: 'soft'
## 容忍配置
# tolerations:
# - operator: "Exists" ##容忍全部污点
最后一个是用于创建 Client 节点的 values 文件:
# values-client.yaml
# ============设置集群名称============
## 设置集群名称
clusterName: 'elasticsearch'
## 设置节点名称
nodeGroup: 'client'
## 设置角色
roles:
master: 'false'
ingest: 'false'
data: 'false'
# ============镜像配置============
## 指定镜像与镜像版本
image: 'elasticsearch'
imageTag: '7.17.3'
## 副本数
replicas: 1
# ============资源配置============
## JVM 配置参数
esJavaOpts: '-Xmx1g -Xms1g'
## 部署资源配置(生成环境一定要设置大些)
resources:
requests:
cpu: '1000m'
memory: '2Gi'
limits:
cpu: '1000m'
memory: '2Gi'
## 数据持久卷配置
persistence:
enabled: false
# ============安全配置============
## 设置协议,可配置为 http、https
protocol: http
## 证书挂载配置,这里我们挂入上面创建的证书
secretMounts:
- name: elastic-certs
secretName: elastic-certs
path: /usr/share/elasticsearch/config/certs
## 允许您在/usr/share/elasticsearch/config/中添加任何自定义配置文件,例如 elasticsearch.yml
## ElasticSearch 7.x 默认安装了 x-pack 插件,部分功能免费,这里我们配置下
## 下面注掉的部分为配置 https 证书,配置此部分还需要配置 helm 参数 protocol 值改为 https
esConfig:
elasticsearch.yml: |
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.enabled: true
# xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
## 环境变量配置,这里引入上面设置的用户名、密码 secret 文件
extraEnvs:
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-auth
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-auth
key: password
# ============Service 配置============
service:
type: NodePort
nodePort: '30200'
现在用上面的 values 文件来安装:
# 安装 master 节点
$ helm upgrade --install es-master -f values-master.yaml --namespace logging .
# 安装 data 节点
$ helm upgrade --install es-data -f values-data.yaml --namespace logging .
# 安装 client 节点
$ helm upgrade --install es-client -f values-client.yaml --namespace logging .
在安装 Master 节点后 Pod 启动时候会抛出异常,就绪探针探活失败,这是个正常现象。在执行安装 Data 节点后 Master 节点 Pod 就会恢复正常。
安装 Kibana
Elasticsearch 集群安装完成后接下来配置安装 Kibana
使用 helm pull 命令拉取 Kibana Chart 包并解压:
$ helm pull elastic/kibana --untar --version 7.17.3
$ cd kibana
创建用于安装 Kibana 的 values 文件:
# values-prod.yaml
## 指定镜像与镜像版本
image: 'kibana'
imageTag: '7.17.3'
## 配置 ElasticSearch 地址
elasticsearchHosts: 'http://elasticsearch-client:9200'
# ============环境变量配置============
## 环境变量配置,这里引入上面设置的用户名、密码 secret 文件
extraEnvs:
- name: 'ELASTICSEARCH_USERNAME'
valueFrom:
secretKeyRef:
name: elastic-auth
key: username
- name: 'ELASTICSEARCH_PASSWORD'
valueFrom:
secretKeyRef:
name: elastic-auth
key: password
# ============资源配置============
resources:
requests:
cpu: '500m'
memory: '1Gi'
limits:
cpu: '500m'
memory: '1Gi'
# ============配置 Kibana 参数============
## kibana 配置中添加语言配置,设置 kibana 为中文
kibanaConfig:
kibana.yml: |
i18n.locale: "zh-CN"
# ============Service 配置============
service:
type: NodePort
nodePort: '30601'
使用上面的配置直接安装即可:
$ helm install kibana -f values-prod.yaml --namespace logging .
下面是安装完成后的 ES 集群和 Kibana 资源:
$ kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-client-0 1/1 Running 0 9m25s
elasticsearch-data-0 1/1 Running 0 9m33s
elasticsearch-master-0 1/1 Running 0 8m29s
kibana-kibana-79b9878cd7-7l75v 1/1 Running 0 6m12s
$ kubectl get svc -n logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-client NodePort 10.108.226.197 9200:30200/TCP,9300:32746/TCP 3m25s
elasticsearch-client-headless ClusterIP None 9200/TCP,9300/TCP 3m25s
elasticsearch-data ClusterIP 10.104.121.49 9200/TCP,9300/TCP 3m33s
elasticsearch-data-headless ClusterIP None 9200/TCP,9300/TCP 3m33s
elasticsearch-master ClusterIP 10.102.72.71 9200/TCP,9300/TCP 6m8s
elasticsearch-master-headless ClusterIP None 9200/TCP,9300/TCP 6m8s
kibana-kibana NodePort 10.109.35.219 5601:30601/TCP 12s
上面我们安装 Kibana 的时候指定了 30601 的 NodePort 端口,所以我们可以从任意节点 http://IP:30601 来访问 Kibana。
我们可以看到会跳转到登录页面,让我们输出用户名、密码,这里我们输入上面配置的用户名 elastic、密码 ydzsio321 进行登录。登录成功后进入如下所示的 Kibana 主页:
部署 Fluentd
Fluentd 是一个高效的日志聚合器,是用 Ruby 编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd 足够高效并且消耗的资源相对较少,另外一个工具 Fluent-bit 更轻量级,占用资源更少,但是插件相对 Fluentd 来说不够丰富,所以整体来说,Fluentd 更加成熟,使用更加广泛,所以这里我们使用 Fluentd 来作为日志收集工具。
工作原理
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储等等。Fluentd 支持超过 300 个日志存储和分析服务,所以在这方面是非常灵活的。主要运行步骤如下:
- 首先 Fluentd 从多个日志源获取数据
- 结构化并且标记这些数据
- 然后根据匹配的标签将数据发送到多个目标服务去

配置
一般来说我们是通过一个配置文件来告诉 Fluentd 如何采集、处理数据的,下面简单和大家介绍下 Fluentd 的配置方法。
日志源配置
比如我们这里为了收集 Kubernetes 节点上的所有容器日志,就需要做如下的日志源配置:
@id fluentd-containers.log
@type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。
path /var/log/containers/*.log # 挂载的宿主机容器日志地址
pos_file /var/log/es-containers.log.pos
tag raw.kubernetes.* # 设置日志标签
read_from_head true
# 多行格式化成JSON
@type multi_format # 使用 multi-format-parser 解析器插件
format json # JSON 解析器
time_key time # 指定事件时间的时间字段
time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式
format /^(?
上面配置部分参数说明如下:
- id:表示引用该日志源的唯一标识符,该标识可用于进一步过滤和路由结构化日志数据
- type:Fluentd 内置的指令,
tail表示 Fluentd 从上次读取的位置通过 tail 不断获取数据,另外一个是http表示通过一个 GET 请求来收集数据。 - path:
tail类型下的特定参数,告诉 Fluentd 采集/var/log/containers目录下的所有日志,这是 docker 在 Kubernetes 节点上用来存储运行容器 stdout 输出日志数据的目录。 - pos_file:检查点,如果 Fluentd 程序重新启动了,它将使用此文件中的位置来恢复日志数据收集。
- tag:用来将日志源与目标或者过滤器匹配的自定义字符串,Fluentd 匹配源/目标标签来路由日志数据。
路由配置
上面是日志源的配置,接下来看看如何将日志数据发送到 Elasticsearch:
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
type_name fluentd
host "#{ENV['OUTPUT_HOST']}"
port "#{ENV['OUTPUT_PORT']}"
logstash_format true
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size "#{ENV['OUTPUT_BUFFER_CHUNK_LIMIT']}"
queue_limit_length "#{ENV['OUTPUT_BUFFER_QUEUE_LIMIT']}"
overflow_action block
- match:标识一个目标标签,后面是一个匹配日志源的正则表达式,我们这里想要捕获所有的日志并将它们发送给 Elasticsearch,所以需要配置成
**。 - id:目标的一个唯一标识符。
- type:支持的输出插件标识符,我们这里要输出到 Elasticsearch,所以配置成 elasticsearch,这是 Fluentd 的一个内置插件。
- log_level:指定要捕获的日志级别,我们这里配置成
info,表示任何该级别或者该级别以上(INFO、WARNING、ERROR)的日志都将被路由到 Elsasticsearch。 - host/port:定义 Elasticsearch 的地址,也可以配置认证信息,我们的 Elasticsearch 不需要认证,所以这里直接指定 host 和 port 即可。
- logstash_format:Elasticsearch 服务对日志数据构建反向索引进行搜索,将 logstash_format 设置为
true,Fluentd 将会以 logstash 格式来转发结构化的日志数据。 - Buffer: Fluentd 允许在目标不可用时进行缓存,比如,如果网络出现故障或者 Elasticsearch 不可用的时候。缓冲区配置也有助于降低磁盘的 IO。
过滤
由于 Kubernetes 集群中应用太多,也还有很多历史数据,所以我们可以只将某些应用的日志进行收集,比如我们只采集具有 logging=true 这个 Label 标签的 Pod 日志,这个时候就需要使用 filter,如下所示:
# 删除无用的属性
@type record_transformer
remove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash
# 只保留具有logging=true标签的Pod日志
@id filter_log
@type grep
key $.kubernetes.labels.logging
pattern ^true$
安装
要收集 Kubernetes 集群的日志,直接用 DasemonSet 控制器来部署 Fluentd 应用,这样,它就可以从 Kubernetes 节点上采集日志,确保在集群中的每个节点上始终运行一个 Fluentd 容器。当然可以直接使用 Helm 来进行一键安装,为了能够了解更多实现细节,我们这里还是采用手动方法来进行安装。
可以直接使用官方的对于 Kubernetes 集群的安装文档: Kubernetes - Fluentd。
首先,我们通过 ConfigMap 对象来指定 Fluentd 配置文件,新建 fluentd-configmap.yaml 文件,文件内容如下:
# fluentd-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-conf
namespace: logging
data:
# 容器日志
containers.input.conf: |-
@id fluentd-containers.log
@type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志
path /var/log/containers/*.log # Docker 容器日志路径
pos_file /var/log/es-containers.log.pos # 记录读取的位置
tag raw.kubernetes.* # 设置日志标签
read_from_head true # 从头读取
# 多行格式化成JSON
# 可以使用我们介绍过的 multiline 插件实现多行日志
@type multi_format # 使用 multi-format-parser 解析器插件
format json # JSON解析器
time_key time # 指定事件时间的时间字段
time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式
format /^(?
# 在日志输出中检测异常(多行日志),并将其作为一条日志转发
# https://github.com/GoogleCloudPlatform/fluent-plugin-detect-exceptions
# 匹配tag为raw.kubernetes.**日志信息
@id raw.kubernetes
@type detect_exceptions # 使用detect-exceptions插件处理异常栈信息
remove_tag_prefix raw # 移除 raw 前缀
message log
multiline_flush_interval 5
# 拼接日志
@id filter_concat
@type concat # Fluentd Filter 插件,用于连接多个日志中分隔的多行日志
key message
multiline_end_regexp /\n$/ # 以换行符“\n”拼接
separator ""
# 添加 Kubernetes metadata 数据
@id filter_kubernetes_metadata
@type kubernetes_metadata
# 修复 ES 中的 JSON 字段
# 插件地址:https://github.com/repeatedly/fluent-plugin-multi-format-parser
@id filter_parser
@type parser # multi-format-parser多格式解析器插件
key_name log # 在要解析的日志中指定字段名称
reserve_data true # 在解析结果中保留原始键值对
remove_key_name_field true # key_name 解析成功后删除字段
@type multi_format
format json
format none
# 删除一些多余的属性
@type record_transformer
remove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash
# 只保留具有logging=true标签的Pod日志
@id filter_log
@type grep
key $.kubernetes.labels.logging
pattern ^true$
###### 监听配置,一般用于日志聚合用 ######
forward.input.conf: |-
# 监听通过TCP发送的消息
@id forward
@type forward
output.conf: |-
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
host elasticsearch-client
port 9200
user elastic # FLUENT_ELASTICSEARCH_USER | FLUENT_ELASTICSEARCH_PASSWORD
password ydzsio321
logstash_format true
logstash_prefix k8s
request_timeout 30s
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
上面配置文件中我们只配置了 docker 容器日志目录,收集到数据经过处理后发送到 elasticsearch-client:9200 服务。
然后新建一个 fluentd-daemonset.yaml 的文件,文件内容如下:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: 'true'
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: 'true'
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ''
resources:
- 'namespaces'
- 'pods'
verbs:
- 'get'
- 'watch'
- 'list'
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: 'true'
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: logging
apiGroup: ''
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ''
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: logging
labels:
app: fluentd
kubernetes.io/cluster-service: 'true'
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
kubernetes.io/cluster-service: 'true'
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
serviceAccountName: fluentd-es
containers:
- name: fluentd
image: quay.io/fluentd_elasticsearch/fluentd:v3.4.0
volumeMounts:
- name: fluentconfig
mountPath: /etc/fluent/config.d
- name: varlog
mountPath: /var/log
volumes:
- name: fluentconfig
configMap:
name: fluentd-conf
- name: varlog
hostPath:
path: /var/log
我们将上面创建的 fluentd-config 这个 ConfigMap 对象通过 volumes 挂载到了 Fluentd 容器中,另外为了能够灵活控制哪些节点的日志可以被收集,还可以添加了一个 nodSelector 属性:
nodeSelector:
beta.kubernetes.io/fluentd-ds-ready: 'true'
意思就是要想采集节点的日志,那么我们就需要给节点打上上面的标签。
!!! info "提示" 如果你需要在其他节点上采集日志,则需要给对应节点打上标签,使用如下命令:kubectl label nodes node名 beta.kubernetes.io/fluentd-ds-ready=true。
另外由于我们的集群使用的是 kubeadm 搭建的,默认情况下 master 节点有污点,所以如果要想也收集 master 节点的日志,则需要添加上容忍:
tolerations:
- operator: Exists
分别创建上面的 ConfigMap 对象和 DaemonSet:
$ kubectl create -f fluentd-configmap.yaml
configmap "fluentd-conf" created
$ kubectl create -f fluentd-daemonset.yaml
serviceaccount "fluentd-es" created
clusterrole.rbac.authorization.k8s.io "fluentd-es" created
clusterrolebinding.rbac.authorization.k8s.io "fluentd-es" created
daemonset.apps "fluentd" created
创建完成后,查看对应的 Pods 列表,检查是否部署成功:
$ kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-client-0 1/1 Running 0 64m
elasticsearch-data-0 1/1 Running 0 65m
elasticsearch-master-0 1/1 Running 0 73m
fluentd-5rqbq 1/1 Running 0 60m
fluentd-l6mgf 1/1 Running 0 60m
fluentd-xmfpg 1/1 Running 0 60m
kibana-66f97964b-mdspc 1/1 Running 0 63m
Fluentd 启动成功后,这个时候就可以发送日志到 ES 了,但是我们这里是过滤了只采集具有 logging=true 标签的 Pod 日志,所以现在还没有任何数据会被采集。
下面我们部署一个简单的测试应用, 新建 counter.yaml 文件,文件内容如下:
apiVersion: v1
kind: Pod
metadata:
name: counter
labels:
logging: 'true' # 一定要具有该标签才会被采集
spec:
containers:
- name: count
image: busybox
args:
[
/bin/sh,
-c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done',
]
该 Pod 只是简单将日志信息打印到 stdout,所以正常来说 Fluentd 会收集到这个日志数据,在 Kibana 中也就可以找到对应的日志数据了,使用 kubectl 工具创建该 Pod:
$ kubectl create -f counter.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
counter 1/1 Running 0 9h
Pod 创建并运行后,回到 Kibana Dashboard 页面,点击左侧最下面的 Management -> Stack Management,进入管理页面,点击左侧 Kibana 下面的 索引模式,点击 创建索引模式 开始导入索引数据:
在这里可以配置我们需要的 Elasticsearch 索引,前面 Fluentd 配置文件中我们采集的日志使用的是 logstash 格式,定义了一个 k8s 的前缀,所以这里只需要在文本框中输入 k8s-* 即可匹配到 Elasticsearch 集群中采集的 Kubernetes 集群日志数据,然后点击下一步,进入以下页面:

在该页面中配置使用哪个字段按时间过滤日志数据,在下拉列表中,选择@timestamp字段,然后点击 创建索引模式,创建完成后,点击左侧导航菜单中的 Discover,然后就可以看到一些直方图和最近采集到的日志数据了:
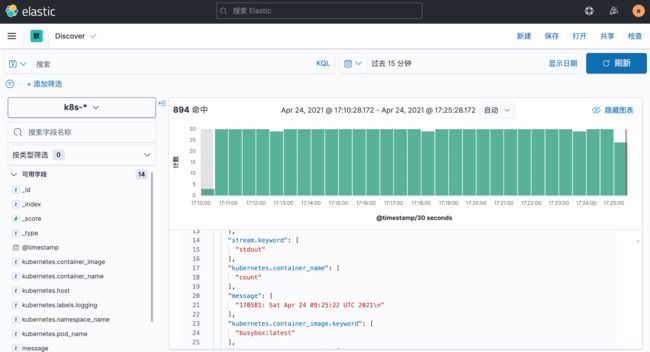
现在的数据就是上面 Counter 应用的日志,如果还有其他的应用,我们也可以筛选过滤:
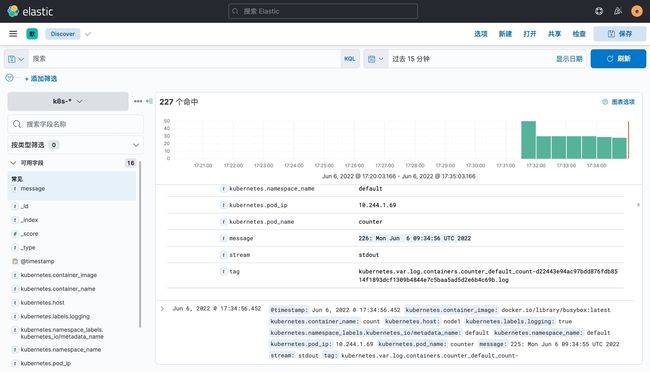
我们也可以通过其他元数据来过滤日志数据,比如您可以单击任何日志条目以查看其他元数据,如容器名称,Kubernetes 节点,命名空间等。
安装 Kafka
对于大规模集群来说,日志数据量是非常巨大的,如果直接通过 Fluentd 将日志打入 Elasticsearch,对 ES 来说压力是非常巨大的,我们可以在中间加一层消息中间件来缓解 ES 的压力,一般情况下我们会使用 Kafka,然后可以直接使用 kafka-connect-elasticsearch 这样的工具将数据直接打入 ES,也可以在加一层 Logstash 去消费 Kafka 的数据,然后通过 Logstash 把数据存入 ES,这里我们来使用 Logstash 这种模式来对日志收集进行优化。
首先在 Kubernetes 集群中安装 Kafka,同样这里使用 Helm 进行安装:
$ helm repo add bitnami https://charts.bitnami.com/bitnami
$ helm repo update
首先使用 helm pull 拉取 Chart 并解压:
$ helm pull bitnami/kafka --untar --version 17.2.3
$ cd kafka
这里面我们指定使用一个 StorageClass 来提供持久化存储,在 Chart 目录下面创建用于安装的 values 文件:
# values-prod.yaml
## @section Persistence parameters
persistence:
enabled: true
storageClass: 'local-path'
accessModes:
- ReadWriteOnce
size: 8Gi
mountPath: /bitnami/kafka
# 配置zk volumes
zookeeper:
enabled: true
persistence:
enabled: true
storageClass: 'local-path'
accessModes:
- ReadWriteOnce
size: 8Gi
直接使用上面的 values 文件安装 kafka:
$ helm upgrade --install kafka -f values-prod.yaml --namespace logging .
Release "kafka" does not exist. Installing it now.
NAME: kafka
LAST DEPLOYED: Thu Jun 9 14:02:01 2022
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: kafka
CHART VERSION: 17.2.3
APP VERSION: 3.2.0
** Please be patient while the chart is being deployed **
Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster:
kafka.logging.svc.cluster.local
Each Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster:
kafka-0.kafka-headless.logging.svc.cluster.local:9092
To create a pod that you can use as a Kafka client run the following commands:
kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:3.2.0-debian-10-r4 --namespace logging --command -- sleep infinity
kubectl exec --tty -i kafka-client --namespace logging -- bash
PRODUCER:
kafka-console-producer.sh \
--broker-list kafka-0.kafka-headless.logging.svc.cluster.local:9092 \
--topic test
CONSUMER:
kafka-console-consumer.sh \
--bootstrap-server kafka.logging.svc.cluster.local:9092 \
--topic test \
--from-beginning
安装完成后我们可以使用上面的提示来检查 Kafka 是否正常运行:
$ kubectl get pods -n logging -l app.kubernetes.io/instance=kafka
kafka-0 1/1 Running 0 7m58s
kafka-zookeeper-0 1/1 Running 0 7m58s
用下面的命令创建一个 Kafka 的测试客户端 Pod:
$ kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:3.2.0-debian-10-r4 --namespace logging --command -- sleep infinity
pod/kafka-client created
然后启动一个终端进入容器内部生产消息:
# 生产者
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-producer.sh --broker-list kafka-0.kafka-headless.logging.svc.cluster.local:9092 --topic test
>hello kafka on k8s
>
启动另外一个终端进入容器内部消费消息:
# 消费者
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-consumer.sh --bootstrap-server kafka.logging.svc.cluster.local:9092 --topic test --from-beginning
hello kafka on k8s
如果在消费端看到了生产的消息数据证明我们的 Kafka 已经运行成功了。
Fluentd 配置 Kafka
现在有了 Kafka,我们就可以将 Fluentd 的日志数据输出到 Kafka 了,只需要将 Fluentd 配置中的 fluent-plugin-kafka 插件,所以需要我们自定义下 Docker 镜像,最简单的做法就是在上面 Fluentd 镜像的基础上新增 kafka 插件即可,Dockerfile 文件如下所示:
FROM quay.io/fluentd_elasticsearch/fluentd:v3.4.0
RUN echo "source 'https://mirrors.tuna.tsinghua.edu.cn/rubygems/'" > Gemfile && gem install bundler
RUN gem install fluent-plugin-kafka -v 0.17.5 --no-document
使用上面的 Dockerfile 文件构建一个 Docker 镜像即可,我这里构建过后的镜像名为 cnych/fluentd-kafka:v0.17.5。接下来替换 Fluentd 的 Configmap 对象中的
# fluentd-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-conf
namespace: logging
data:
......
output.conf: |-
@id kafka
@type kafka2
@log_level info
# list of seed brokers
brokers kafka-0.kafka-headless.logging.svc.cluster.local:9092
use_event_time true
# topic settings
topic_key k8slog
default_topic messages # 注意,kafka中消费使用的是这个topic
# buffer settings
@type file
path /var/log/td-agent/buffer/td
flush_interval 3s
# data type settings
@type json
# producer settings
required_acks -1
compression_codec gzip
然后替换运行的 Fluentd 镜像:
# fluentd-daemonset.yaml
image: cnych/fluentd-kafka:v0.17.5
直接更新 Fluentd 的 Configmap 与 DaemonSet 资源对象即可:
$ kubectl apply -f fluentd-configmap.yaml
$ kubectl apply -f fluentd-daemonset.yaml
更新成功后我们可以使用上面的测试 Kafka 客户端来验证是否有日志数据:
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-consumer.sh --bootstrap-server kafka.logging.svc.cluster.local:9092 --topic messages --from-beginning
{"stream":"stdout","docker":{},"kubernetes":{"container_name":"count","namespace_name":"default","pod_name":"counter","container_image":"busybox:latest","host":"node1","labels":{"logging":"true"}},"message":"43883: Tue Apr 27 12:16:30 UTC 2021\n"}
......
安装 Logstash
虽然数据从 Kafka 到 Elasticsearch 的方式多种多样,比如可以使用 Kafka Connect Elasticsearch Connector 来实现,我们这里还是采用更加流行的 `Logstash`` 方案,上面我们已经将日志从 Fluentd 采集输出到 Kafka 中去了,接下来我们使用 Logstash 来连接 Kafka 与 Elasticsearch 间的日志数据。
首先使用 helm pull 拉取 Chart 并解压:
$ helm pull elastic/logstash --untar --version 7.17.3
$ cd logstash
同样在 Chart 根目录下面创建用于安装的 Values 文件,如下所示:
# values-prod.yaml
fullnameOverride: logstash
persistence:
enabled: true
logstashConfig:
logstash.yml: |
http.host: 0.0.0.0
# 如果启用了xpack,需要做如下配置
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.hosts: ["http://elasticsearch-client:9200"]
xpack.monitoring.elasticsearch.username: "elastic"
xpack.monitoring.elasticsearch.password: "ydzsio321"
# 要注意下格式
logstashPipeline:
logstash.conf: |
input { kafka { bootstrap_servers => "kafka-0.kafka-headless.logging.svc.cluster.local:9092" codec => json consumer_threads => 3 topics => ["messages"] } }
filter {} # 过滤配置(比如可以删除key、添加geoip等等)
output { elasticsearch { hosts => [ "elasticsearch-client:9200" ] user => "elastic" password => "ydzsio321" index => "logstash-k8s-%{+YYYY.MM.dd}" } stdout { codec => rubydebug } }
volumeClaimTemplate:
accessModes: ['ReadWriteOnce']
storageClassName: nfs-storage
resources:
requests:
storage: 1Gi
其中最重要的就是通过 logstashPipeline 配置 logstash 数据流的处理配置,通过 input 指定日志源 kafka 的配置,通过 output 输出到 Elasticsearch,同样直接使用上面的 Values 文件安装 logstash 即可:
$ helm upgrade --install logstash -f values-prod.yaml --namespace logging .
Release "logstash" does not exist. Installing it now.
NAME: logstash
LAST DEPLOYED: Thu Jun 9 15:02:49 2022
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Watch all cluster members come up.
$ kubectl get pods --namespace=logging -l app=logstash -w
安装启动完成后可以查看 logstash 的日志:
$ logstash kubectl get pods --namespace=logging -l app=logstash
NAME READY STATUS RESTARTS AGE
logstash-0 1/1 Running 0 2m8s
$ kubectl logs -f logstash-0 -n logging
......
{
"@version" => "1",
"stream" => "stdout",
"@timestamp" => 2022-06-09T07:09:16.889Z,
"message" => "4672: Thu Jun 9 07:09:15 UTC 2022",
"kubernetes" => {
"container_image" => "docker.io/library/busybox:latest",
"container_name" => "count",
"labels" => {
"logging" => "true"
},
"pod_name" => "counter",
"namespace_name" => "default",
"pod_ip" => "10.244.2.118",
"host" => "node2",
"namespace_labels" => {
"kubernetes_io/metadata_name" => "default"
}
},
"docker" => {}
}
由于我们启用了 debug 日志调试,所以我们可以在 logstash 的日志中看到我们采集的日志消息,到这里证明我们的日志数据就获取成功了。
现在我们可以登录到 Kibana 可以看到有如下所示的索引数据了:

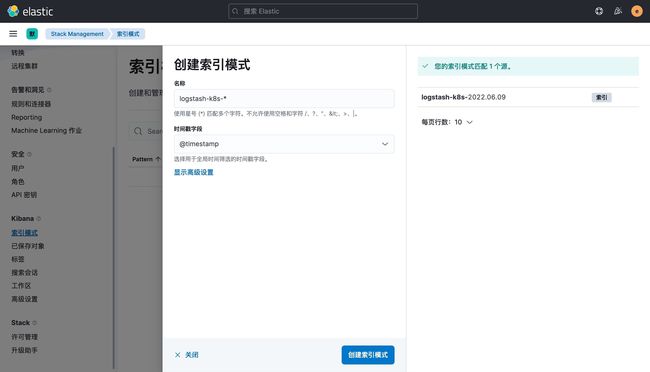
然后同样创建索引模式,匹配上面的索引即可:
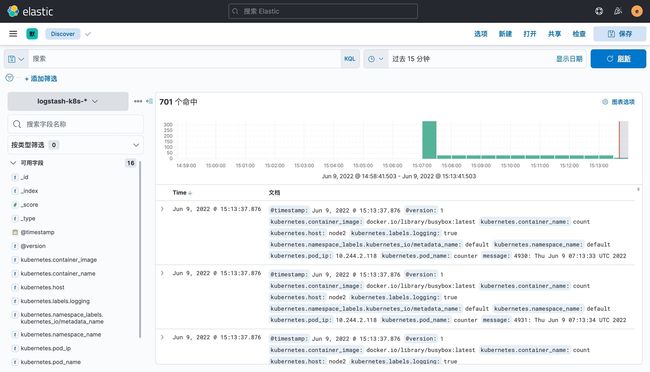
创建完成后就可以前往发现页面过滤日志数据了:
到这里我们就实现了一个使用 Fluentd+Kafka+Logstash+Elasticsearch+Kibana 的 Kubernetes 日志收集工具栈,这里我们完整的 Pod 信息如下所示:
$ kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-client-0 1/1 Running 0 128m
elasticsearch-data-0 1/1 Running 0 128m
elasticsearch-master-0 1/1 Running 0 128m
fluentd-6k52h 1/1 Running 0 61m
fluentd-cw72c 1/1 Running 0 61m
fluentd-dn4hs 1/1 Running 0 61m
kafka-0 1/1 Running 3 134m
kafka-client 1/1 Running 0 125m
kafka-zookeeper-0 1/1 Running 0 134m
kibana-kibana-66f97964b-qqjgg 1/1 Running 0 128m
logstash-0 1/1 Running 0 13m
当然在实际的工作项目中还需要我们根据实际的业务场景来进行参数性能调优以及高可用等设置,以达到系统的最优性能。
上面我们在配置 logstash 的时候是将日志输出到 "logstash-k8s-%{+YYYY.MM.dd}" 这个索引模式的,可能有的场景下只通过日期去区分索引不是很合理,那么我们可以根据自己的需求去修改索引名称,比如可以根据我们的服务名称来进行区分,那么这个服务名称可以怎么来定义呢?可以是 Pod 的名称或者通过 label 标签去指定,比如我们这里去做一个规范,要求需要收集日志的 Pod 除了需要添加 logging: true 这个标签之外,还需要添加一个 logIndex: <索引名> 的标签。
比如重新更新我们测试的 counter 应用:
apiVersion: v1
kind: Pod
metadata:
name: counter
labels:
logging: 'true' # 一定要具有该标签才会被采集
logIndex: 'test' # 指定索引名称
spec:
containers:
- name: count
image: busybox
args:
[
/bin/sh,
-c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done',
]
然后重新更新 logstash 的配置,修改 values 配置:
# ......
logstashPipeline:
logstash.conf: |
input { kafka { bootstrap_servers => "kafka-0.kafka-headless.logging.svc.cluster.local:9092" codec => json consumer_threads => 3 topics => ["messages"] } }
filter {} # 过滤配置(比如可以删除key、添加geoip等等)
output { elasticsearch { hosts => [ "elasticsearch-client:9200" ] user => "elastic" password => "ydzsio321" index => "k8s-%{[kubernetes][labels][logIndex]}-%{+YYYY.MM.dd}" } stdout { codec => rubydebug } }
# ......
使用上面的 values 值更新 logstash,正常更新后上面的 counter 这个 Pod 日志会输出到一个名为 k8s-test-2022.06.09 的索引去。
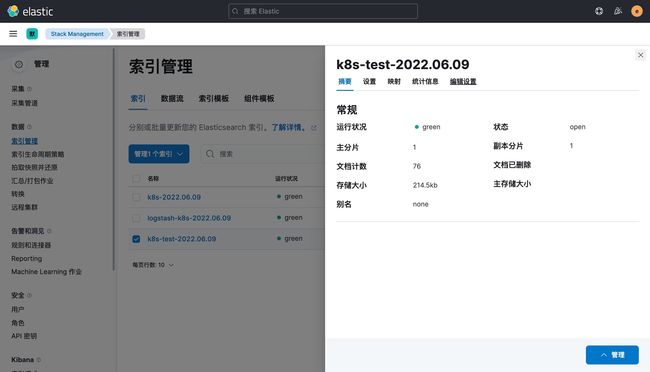
这样我们就实现了自定义索引名称,当然你也可以使用 Pod 名称、容器名称、命名空间名称来作为索引的名称,这完全取决于你自己的需求。