Super-Resolution 论文调研
目录
超分辨率综述
论文一 Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network (ECCV2018)
1. Abstract
2. Architecture
3. Experiment
4.Conclusion
论文二:Recurrent Back-Projection Network for Video Super-Resolution (CVPR2019)
1. Abstract
2. Architecture
3. Experiment
4.Conclusion
论文三:Detail-revealing Deep Video Super-resolution (ICCV2017)
1.Abstract
2. Architecture
3.Experiment
4.Conclusion
论文四:Frame-Recurrent Video Super-Resolution
1.Abstract
2.Architecture
3.Conclusion
超分辨率综述
超分辨率技术(Super-Resolution)是指从观测到的低分辨率图像重建出相应的高分辨率图像,在监控设备、卫星图像和医学影像等领域都有重要的应用价值。SR可分为两类:从多张低分辨率图像重建出高分辨率图像和从单张低分辨率图像重建出高分辨率图像。基于深度学习的SR,主要是基于单张低分辨率的重建方法,即Single Image Super-Resolution (SISR)。

下面将介绍几篇近几年在顶会中出现的关于超分辨率的论文。论文将通过摘要,框架,实验细节,结论进行分析,具体细节可以按文中所给链接下载精读论文。
论文一 Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network (ECCV2018)
1. Abstract
在本文中,为了减轻网络的体量,增强实用性提出一个精确和轻量化的图像超分辨率深网络。设计了一个在残差网络上实现级联机制的体系结构。为了进一步提高效率,我们还提出了级联残差网络的变型模型。大量实验表明,即使参数和操作少得多,模型的性能也可以与最先进的方法相媲美。
2. Architecture
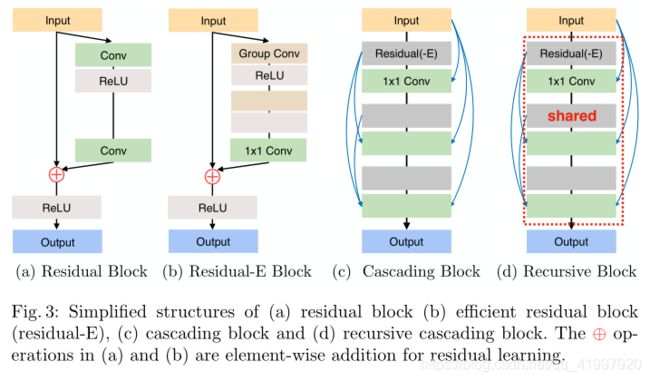
模型的中间部分是基于ResNet设计的。Resnet广泛应用于基于深度学习的SR方法。除了Resnet体系结构之外,CARN还使用本地和全局级别的级联机制来合并来自多个层的功能(下图所示)。这可以反映不同级别的输入,以便接收更多信息。除了CARN模型外,还提供了CARN-M模型,允许在模型的性能和重量之间进行权衡。它是通过有效的残差块(residual-e)和递归网络结构实现的。

图2(b)以图形方式描述了全局级联的发生方式。中间层的输出被级联到更高的层中,最后汇聚到一个1X1卷积层上。中间层是作为级联块实现的,它承载本地级联连接本身。这种局部级联操作如图3(c)和(d)所示。局部级联与全局级联几乎相同,只是单元块是纯残差块。
3. Experiment
| 项目 | 属性 |
| 数据集 | DIV2K/Set5/Set14/B100/Urban100 |
| 数据增强 | random horizontal flips and 90 degree rotation |
| 图片大小 | RGB 64*64 |
| 优化器 | Adam |
| batchsize | 64 |
| 学习率 | 10(-4) 每 4 × 10(5)steps减半 |
4.Conclusion

表2给出了局部和全局级联模块影响的消融研究。在这个表中,基线是resnet,CARN-NL是没有局部级联的CARN-NL,CARN-NG是没有全局级联的CARN。网络拓扑结构都是相同的,但是由于1×1的卷积层,参数的总数增加了10%。

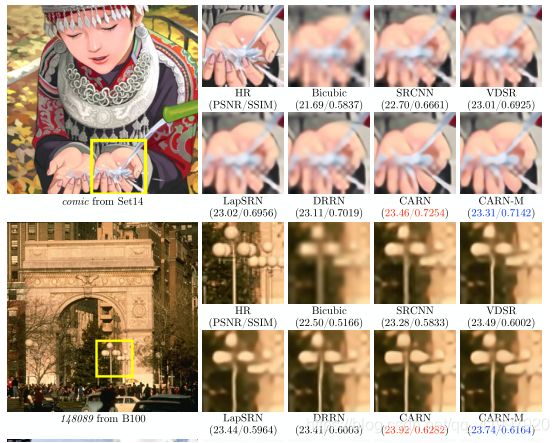
论文二:Recurrent Back-Projection Network for Video Super-Resolution (CVPR2019)
1. Abstract
提出了一种新的视频超分辨率问题的体系结构。使用循环编码器 - 解码器模块来集成来自连续视频帧的空间和时间上下文,其将多帧信息与用于目标帧的更传统的单帧超分辨率路径融合。与通过堆叠或变形将帧合并在一起的大多数先前工作相比,循环反向投影网络(RBPN)将每个上下文帧视为单独的信息源。这些来源在迭代细化框架中进行组合,其灵感来自多图像超分辨率中的反投影理念。这通过明确地表示关于目标的估计的帧间运动而不是明确地对准帧来辅助。提出了一种新的视频超分辨率基准测试,允许更大规模的评估并考虑不同运动状态下的视频。实验结果表明,RBPN在几个数据集上优于现有方法。
2. Architecture
反投影迭代地计算残差图像作为目标图像与其相应图像集之间的重建误差。残差被反投影到目标图像以提高其分辨率。多个残差可以独立地表示目标帧与其他帧之间的细微且显着的差异。深背投影网络(DBPN)在假设仅为目标图像给出一个LR图像的情况下将反投影扩展到Deep SISR。在这种情况下,DBPN生成一个高分辨率的特征图,它通过多个上采样层和下采样层进行实际细化。循环反投影网络(RBPN),集成了原始的MISR反投影和DBPN的优点,用于VSR。这里我们使用其他视频帧作为原始MISR反投影的相应LR图像。此外使用迭代优化HR特征映射的想法,通过上采样和下采样过程来表示缺失的细节,以进一步提高SR的质量。
将SISR和MISR集成到统一的VSR框架中:SISR和MISR从不同的源中提取缺失的详细信息。迭代SISR 提取表示目标帧细节的各种特征映射。 MISR从其他帧提供多组特征映射。
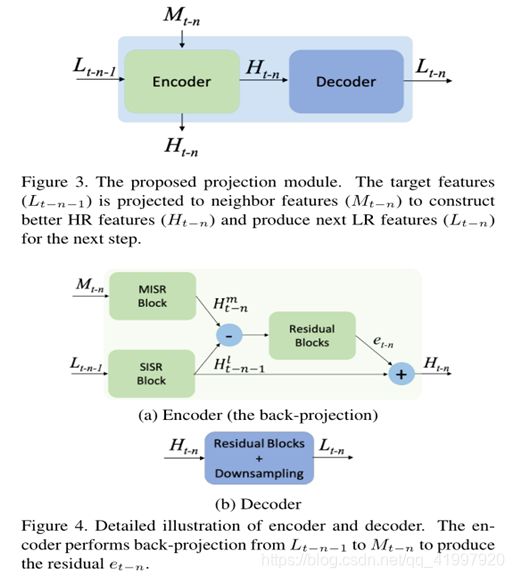
通过用于VSR的RNN以时间顺序迭代地更新不同的源。用于RBPN的反投影模块:我们开发了一种循环编码器 - 解码器机制,用于通过反投影结合在SISR和MISR路径中提取的细节。
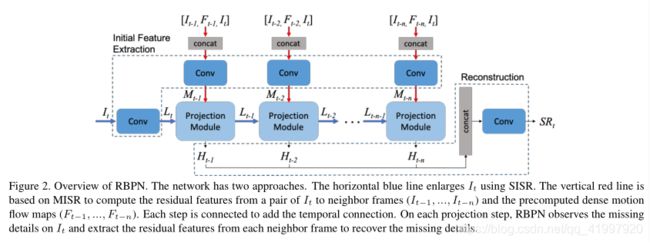
初始特征提取:
在进入投影模块之前,I t被映射到LR特征张量L t。对于I t-k,k∈[n]中的每个相邻帧,我们将I t-k和I t之间的预计算密集运动流图F t-k(描述每像素的2D矢量)与目标帧I t连接起来。It-k。运动流程图鼓励投影模块在一对I和I t-k之间提取缺失的细节。该堆叠的8通道“图像”被映射到相邻特征张量M t-k。
多次预测:
通过集成SISR和MISR路径来提取目标帧中缺失的细节,然后生成精确的HR特征张量。该阶段接收L t-k-1和M t-k,并输出HR特征张量H t-k。
重建:
最终的SR输出是通过将所有帧的连锁HR特征映射输入到重建模块中获得的
RBPN的多投影阶段使用循环编码器 - 解码器模块链,如图3所示。
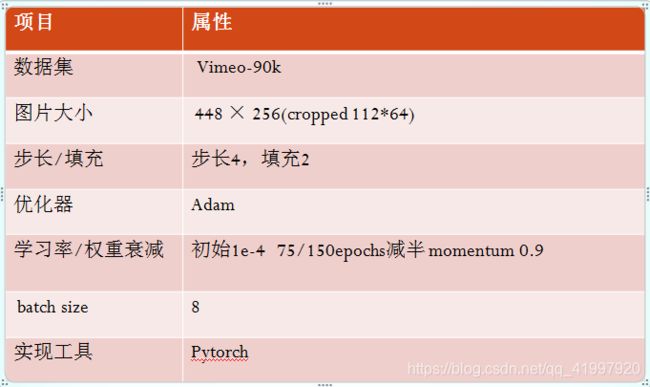
3. Experiment
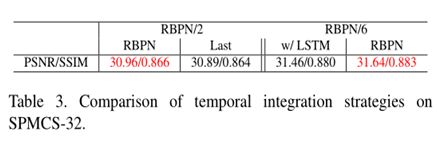
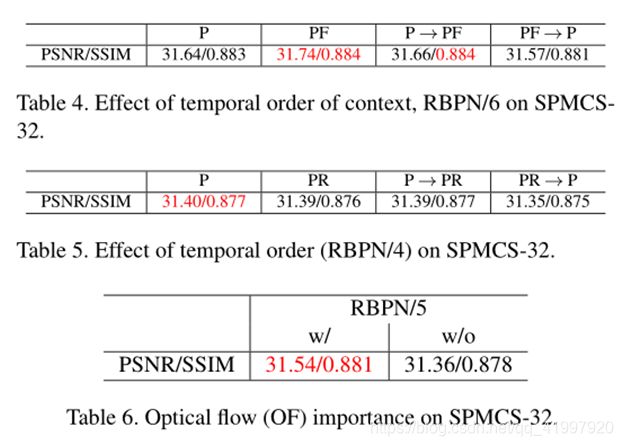
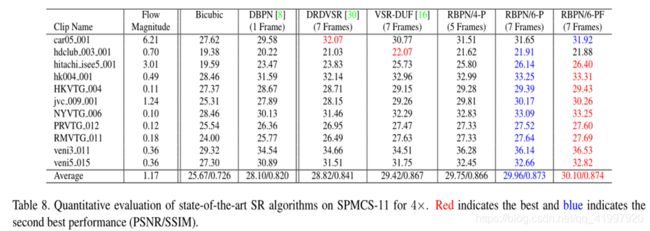
4.Conclusion



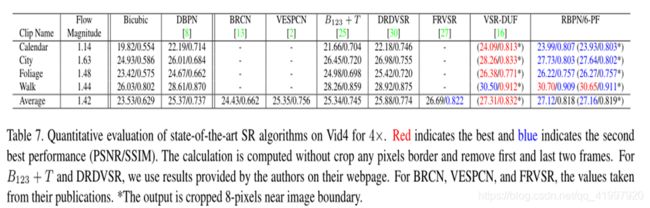

论文三:Detail-revealing Deep Video Super-resolution (ICCV2017)
1.Abstract
视频超分辨关注的主要问题有两个:一是如何充分利用多帧关联信息,而是如何有效地融合图像细节到高分辨率图像中。
动作补偿方面,深度学习方法用的是backward warping到参考帧,但这个方法其实并不是最优的。
多帧融合方面,虽然很多CNN方法可以产生丰富的细节,但不能确定图像细节是来自内部的帧,还是外部的数据。在可缩放性方面,现有的方法对多尺度超分辨都不太灵活,包括ESPCN、VSRnet、VESPCN。
基于现状,作者提出一个sub-pixel motion compensation(SPMC)层,用来有效处理动作补偿和特征图缩放。另外,用一个基于LSTM的框架来处理多帧输入。
2. Architecture
motion estimation , motion compensation ,detail fusion
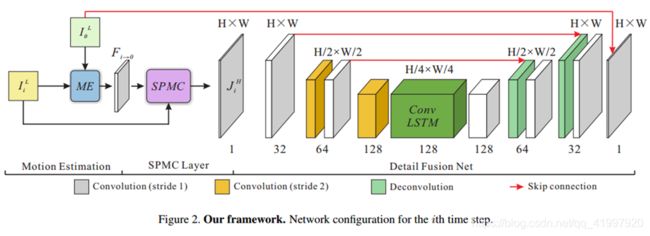
Motion Estimation
motion estimation已经相对比较成熟了,方法有Flownet-S和VESPCN中的motion compensation transformer(MCT)。最后作者计划使用MCT。
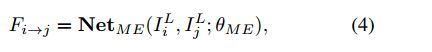
Motion Compensation
motion compensation用的就是SPMC层。首先记LR、HR图像分别为JLJL和JHJH。用公式可以表示为:
![]()
之前的模块已经得到帧之间的光流估计F=(u,v)F=(u,v),所以可以用Sampling Grid Generator生成格子(如下公式)。其中有一个αα参数,说明在这一步分辨率就已经提高了

三步训练:
- 只训练motion estimation的参数。鉴于没有label,所以用无监督的warping loss。
- 固定ME的参数,训练后面的网络。
- 联合训练。
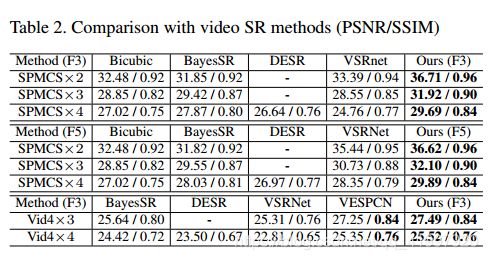
3.Experiment
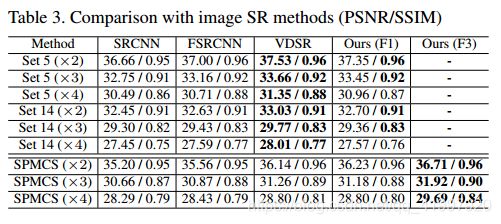
作者自己收集了一个数据集,有975个1080p HD视频序列,每个序列有31帧。HR的尺寸为540*960,LR的尺寸为270*480,180*320,135*240。训练集945个,测试集和验证集30个。
4.Conclusion
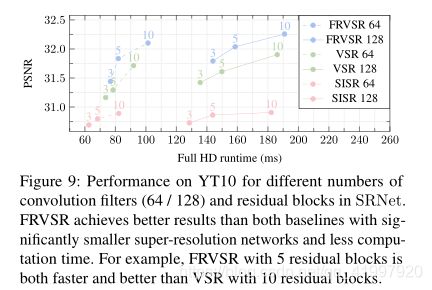
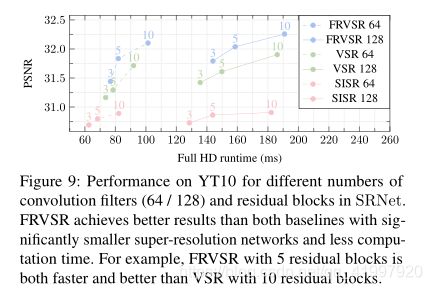
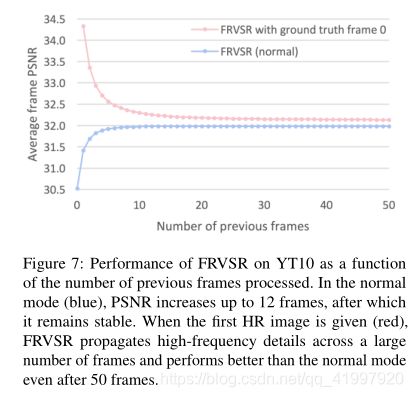
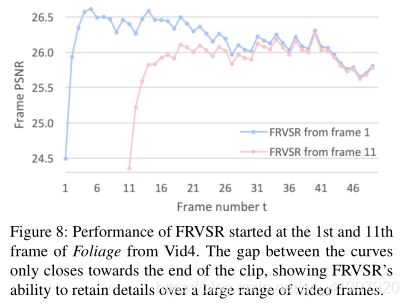
论文四:Frame-Recurrent Video Super-Resolution
1.Abstract
该文章主要是针对以前视频超分辨的缺点:将视频超分辨问题看作是大量的单独的多帧超分辨任务。每个多帧超分辨任务负责根据输入的多帧LR图像生成一个HR图像,这样产生的各个HR图像之间由于缺乏联系,在时间连续性上比较差,出现伪影。同时这样做的计算复杂度比较高。于是,作者提出在生成下一帧图像时,考虑之前生成的HR图像,将其也输入网络,这样不仅能产生时间连续的结果,也降低了计算复杂度。
2.Architecture
首先光流估计网络FNet,根据输入的当前LR和前一帧LR,估计它们两个之间的光流,得到LR光流图,接着通过双线性插值按照指定的比例上采样到相应的分辨率上,得到HR光流图,然后将所得到的HR光流图和前一帧的HR(生成的)进行Wrap操作,再将其输出进行space-to-depth操作(可以类比亚像素卷积的逆操作),从高分辨率空间变换到低分辨率空间中,最后将输出送入SRNet中进行最终的超分辨操作,输出当前LR图像的超分辨图像。
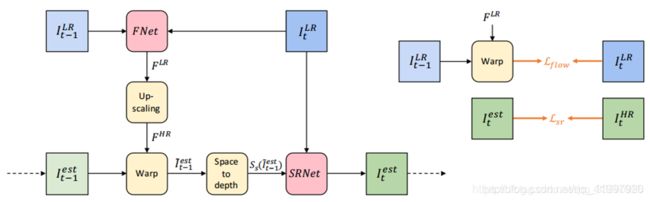
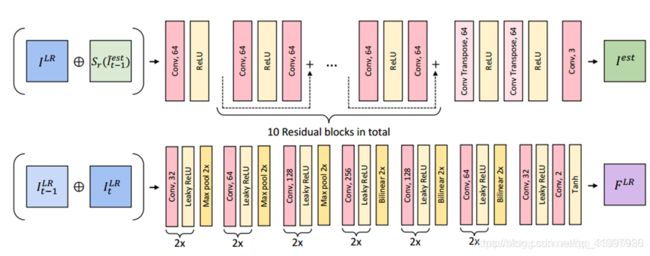
FNet和SRNet的内部结构如下:
网络使用的损失函数包含两项,如上图右边所示:
一项是网络预测出的HR图像与ground truth图像像素之间的差异:

另一项是:
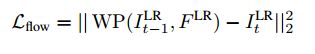
总的损失是这两项之和:
![]()
3.Conclusion