Java中的IO流概述以及字节流与字符流详解
文章目录
- IO流概述
- 字节流
-
- InputStream与OutputStream流
- FileInputStream与FileOutputStream流
-
- FileOutputStream流
- FileInputStream流
- 复制文件
- BufferdInputStream与BufferdOutputStream流
-
- BufferdInputStream流
- BufferdOutputStream流
- 复制文件的效率对比
- 复制单级/多级文件夹
- 字符流
-
- 字符流的由来
- 编码与解码
- Reader与Writer流
- InputStreamReader与OutputStreamWriter流
-
- InputStreamReader流
- OutputStreamWriter流
- 复制文本文件
- FileReader与FileWriter流
-
- 复制文本文件
- BufferdReader与BufferdWriter流
-
- BufferdReader流
- BufferdWriter流
- 复制文本文件
- 关于IO流的练习
-
- 把集合中的数据存储到文本文件
- 把文本文件中的数据存储到集合中
- 随机获取文本文件中的姓名
- 键盘录入学生信息按照总分排序并写入文本文件
- 复制指定目录下指定后缀名的文件并修改名称
IO流概述
- 输入输出技术并不那么令人兴奋,如果没有读写数据的能力,编写出来的程序会受到很大的限制;
- IO流就是用来进行数据之间的传输,如何从能够发送字节序列的任何数据源取得输入,如何将输出发送到能够接受字节序列的任何目的地;这些字节序列的源和目的地可以是文件,也可以是网络连接甚至是内存块;
- 在Java中,一个可以读取字节序列的对象被称为输入流,一个可以写入字节序列的对象被称为输出流,这是按照流向来划分的;在
抽象类InputStream与OutputStream里面对他们进行了说明,之所以把它们规定为抽象类,是为了将多种类的公共行为提取到最高层次的一种机制,这使得代码更加清晰,并使得类的继承树更易于理解; - 按照操作文件的数据类型,可以把流分为字节流和字符流,字节流可以操作任意类型的文件,字符流只能操作文本文件,也就是记事本可以打开的文件;
- 操作流的类都在
java.io包下;
字节流
InputStream与OutputStream流
InputStream与OutputStream流是所有字节输入/输出流的父类,本身是抽象类;
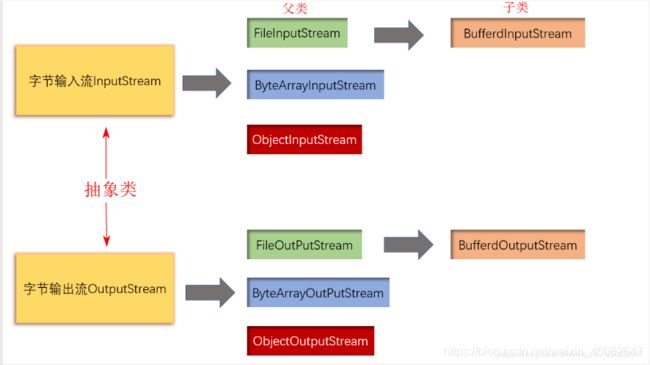
FileInputStream与FileOutputStream流
- 这是一对实现了InputStream与OutputStream抽象类的字节流;
FileOutputStream流

- 构造方法
1、
public FileOutputStream(File file) throws FileNotFoundException
- 创建一个向指定 File 对象表示的文件中写入数据的文件输出流;
2、
public FileOutputStream(String name) throws FileNotFoundException
- 创建一个向具有指定名称的文件中写入数据的文件输出流;
3、
public FileOutputStream(File file, boolean append) throws FileNotFoundException
- 创建一个向指定 File 对象表示的文件中读出数据的文件输出流;参数二表示是否是追加写入,true表示追加写入,false表示覆盖写入;
4、
public FileOutputStream(String name, boolean append) throws FileNotFoundException
- 创建一个向具有指定 name 的文件中写入数据的输出文件流,参数2同样表示是否追加写入;
- 如果该文件存在,但它是一个目录,而不是一个常规文件,或者该文件不存在,但无法创建它,或者无法打开它,都会抛出 FileNotFoundException;
注意: 追加写入指的是下一次程序运行时,再次往这个文件里面写入的内容是否覆盖这个文件已有的内容;
- write()方法
该方法实现了OutputStream抽象类里面的write()方法,有几个重载,这意味着,可以灵活的写入数据;
1、public void write(int b) throws IOException
- 将指定字节写入此文件输出流,一次写入一个字节;
2、
public void write(byte[] b) throws IOException
- 将 b.length 个字节从指定 byte 数组写入此文件输出流中,一次写入一个字节数组;
3、
public void write(byte[] b, int off, int len) throws IOException
- 将指定 byte 数组中从偏移量(索引) off 开始的 len 个字节写入此文件输出流
- flush()方法
public void flush() throws IOException
刷新此输出流并强制写出所有缓冲的输出字节,为什么要进行刷新?
- 字节流的刷新不是必要的,但是字符流的刷新是必要的,下面关于刷新的讨论是针对字符流来说;
- 由于CPU不能够直接访问外存(硬盘),而需要借助于内存来完成对硬盘中数据的读/取操作,想要完成此操作又不得不借助于I/0系统。但是,JAVA中的输入/输入流在默认情况下,是不被缓存区缓存的,因此,每发生一次read()方法和write()方法都需要请求操作系统再分发/接收一个字节,这样程序的运行效率必然会降低,相比之下,请求一个数据块并将其置于缓冲区中会显得更加高效。于是我们考虑可以将硬盘中的数据事先添加到预定义范围(大小合适)的缓冲池中来预存数据,待CPU产生I/O操作时,可以从这个缓存池中来读取数据,这样便减少了CPU的I/O的次数,提高了程序的运行效率。JAVA也正是采用这种方式,通过为基本流添加了处理流(缓冲机制)来减少I/O操作的次数。
- read()方法和write()是线程阻塞的,也就是说,当某个线程试图向另一端网络节点读取或写入数据时,有可能会发生网络连接异常或者是服务器短期内没有响应,这将会导致该线程阻塞,同样地,在无数据状态进行读取,数据已满进行写操作时,同样会发生阻塞。这时,其他线程抢占资源后继续执行。如果出现此现状,读取到缓冲池中的数据不能够及时的发送到另一端的网络节点,需要该线程再次竞争到CPU资源才可正常发送。
- 还有一种情况,当我们将数据预存到缓冲池中时,当数据的长度满足缓冲池中的大小后,才会将缓冲池中的数据成块的发送,若数据的长度不满足缓冲池中的大小,需要继续存入,待数据满足预存大小后再成块的发送。往往在发送文件过程中,文件末尾的数据大小不能满足缓冲池的大小。最终导致这部分的数据停留在缓冲池无法发送。
- 这时,就需要我们在write()方法后,手动调用flush()方法,强制刷出缓冲池中的数据,(即使数据长度不满足缓冲池的大小)从而保证数据的正常发送。当然,当我们调用流的close()方法后,系统也会自动将输出流缓冲区的数据刷出,同时可以保证流的物理资源被回收。
- close()方法
public void close() throws IOException
关闭此输出流并释放与此流有关的所有系统资源。
- 当完成了对应流的读取或者写入后,就应该调用close()方法将它关闭,这样可以释放流所占用的操作系统的资源。这些系统资源很有限,如果一个应用程序打开了太多的流而没有关闭它们,系统资源将会耗尽。
- 关闭一个输出流也可以刷新输出流占用的缓存区,即临时存储在缓冲区中等待形成较大的数据包后再发送的那些字符,此时将它们发送出去。
- 特别要注意的是,如果不关闭文件,最后一个字节包可能永远也不会被发送(字符流),当然也可以用flush方法手工刷新输出;
代码示例:
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
public class MyTest1 {
public static void main(String[] args) {
FileOutputStream fos1 = null;
FileOutputStream fos2 = null;
try {
//4中构造方法,方便我们创造写入的流对象
fos1 = new FileOutputStream("a.txt");
//追加写入该文本当中,如果给出的文件不存在,程序会帮我们自动创建文件
fos2 = new FileOutputStream(new File("b.txt"), true);
//一次写入一个字节
fos1.write(97);
//一次写入一个字节数组
byte[] bytes = {98, 99, 100};
fos1.write(bytes);
//从3索引处,写入2个字节
fos2.write(new byte[]{101, 102, 103, 104, 105, 106, 107, 108}, 3, 2);
//强制刷新
fos2.flush();
fos2.write(109);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fos1 != null) {
fos1.close();
}
if (fos2 != null) {
fos2.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
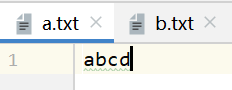
运行结果:
- 最后在关闭流的时候,一定要做非空的判断,如果程序中途遇到异常,没来得及创建流对象就终止运行,使null进行关闭操作,会报出空指针异常的错误;
FileInputStream流

- 构造方法
1、
public FileInputStream(File file) throws FileNotFoundException
- 通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的 File 对象 file 指定;
2、
public FileInputStream(String name) throws FileNotFoundException
- 通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的路径名 name 指定;
- 如果构造方法中指定文件不存在,或者它是一个目录,而不是一个常规文件,抑或因为其他某些原因而无法打开进行读取,则抛出 FileNotFoundException;
- read()方法
public int read() throws IOException
- 从此输入流中读取一个数据字节;
- 该方法指定于InputStream流;
public int read(byte[] b) throws IOException
- 从此输入流中将最多 b.length 个字节的数据读入一个 byte 数组中;
public int read(byte[] b, int off, int len) throws IOException
- 从此输入流中将最多 len 个字节的数据读入一个 byte 数组中;
上面3个方法返回值为:读入缓冲区的字节总数,如果因为已经到达文件末尾而没有更多的数据,则返回 -1;
- close()方法
public void close() throws IOException
- 关闭此文件输入流并释放与此流有关的所有系统资源。
- 代码示例:
import java.io.FileInputStream;
import java.io.IOException;
public class MyTest4 {
public static void main(String[] args) {
FileInputStream fis = null;
try {
fis = new FileInputStream("a.txt");
int i = fis.read();
//一次读取一个字节
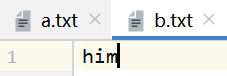
System.out.println(i);
//112
byte[] bytes = new byte[21];
int i1 = fis.read(bytes);
//返回读取到的字节个数,读取到的字节存放在定义好的字节数组里面
System.out.println(i1);
//21
System.out.println(new String(bytes,0,bytes.length));
//ackage org.westos.dem
byte[] bytes1 = new byte[21];
int i2 = fis.read(bytes1, 0, 10);
//返回值为读取到的字节个数,参数为将读取到的10个字节从数组0索引处开始放置
System.out.println(i2);
//10
System.out.println(new String(bytes1,0,bytes1.length));
//o;import j
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fis != null) {
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
复制文件
- 因为字节流可以操作任意类型的文件,比如文本文件、音频文件、视频文件等,在学习完字节输入流与输出流,我们就可以进行任意类型文件的复制;
- 练习:复制文本文件、音频文件
复制文件方式1:
从文本文件中以读取一个字节,写入一个字节的方式复制文件;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class MyTest2 {
public static void main(String[] args) throws IOException {
//所有的异常抛出去,交由虚拟机处理
FileInputStream fis = new FileInputStream("a.txt");
FileOutputStream fos = new FileOutputStream("D:\\桌面图标\\文件程序练习打包\\copy.txt");
long start = System.currentTimeMillis();
int by = 0;
while ((by = fis.read()) != -1) {
fos.write(by);
fos.flush();
}
long end = System.currentTimeMillis();
System.out.println("总共耗时:" + (end - start) + "毫秒");
//总共耗时:44毫秒
fis.close();
fos.close();
}
}
复制文件方式2:
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class MyTest3 {
public static void main(String[] args) {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream("D:\\桌面图标\\文件程序练习打包\\demo\\亲爱的旅人啊.mp3");
fos = new FileOutputStream("D:\\桌面图标\\文件程序练习打包\\copy.mp3");
byte[] bytes = new byte[1024 * 8];
int len = 0;
long start = System.currentTimeMillis();
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes, 0, len);
fos.flush();
}
long end = System.currentTimeMillis();
System.out.println("复制完成,总共耗时:" + (end - start) + "毫秒");
//复制完成,总共耗时:45毫秒
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fis != null) {
fis.close();
}
if (fos != null) {
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
BufferdInputStream与BufferdOutputStream流
- BufferdInputStream与BufferdOutputStream流继承自FileInputStream与FileOutputStream流,是一对高效的字节流,因为它的底层维护了一个缓冲区,我们使用他们的父类复制文件的时候还需要自己创建缓冲区字节数组,但是这个流自己就拥有缓冲区;
- 如果不采用一个一个字节复制,采用第2种方法一次读取一个字节数组,两种字节流的区别不是很大,我们可以使用计时的方法获得两种流的运行时间;
BufferdInputStream流
- 构造方法
public BufferedInputStream(InputStream in)
- 创建一个 BufferedInputStream和保存它的参数,输入流 in,供以后使用。一个内部缓冲数组创建并存储在 buf;
- 参数 :in -数据输入流,需要一个字节流,传递一个字节流的子类就可以;
public BufferedInputStream(InputStream in, int size)
- 创建一个具有指定的缓冲区大小 BufferedInputStream,并保存它的参数,输入流 in,供以后使用;
- 参数 :in -数据输入流;size -缓冲区大小;
异常 :如果 size <= 0 IllegalArgumentException
构造方法源码:

- read()方法
该流里面的两个read(),都是继承自它的父类,分别是一次读取一个字节,以及一次读取一个字节数组以及偏移量预读取字节长度,这里就不再赘述;
- 代码示例:
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;
public class MyTest {
public static void main(String[] args) {
BufferedInputStream bis = null;
try {
bis = new BufferedInputStream(new FileInputStream("a.txt"));
int i = bis.read();
//一次读取一个字节
System.out.println(i);
//112
byte[] bytes = new byte[10];
int i1 = bis.read(bytes, 0, 10);
//一次读取10个字节放在字节数组bytes里面,从0索引处开始放置,返回值为读取到的字节个数
System.out.println(i1);
//10
System.out.println(new String(bytes,0,bytes.length));
//ackage org
bis.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bis != null) {
bis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
BufferdOutputStream流
- 构造方法
public BufferedOutputStream(OutputStream out)
- 创建一个新的缓冲输出流,将数据写入到指定的基本输出流中;关联的文件不存在,将会自动创建文件;
参数:out -底层输出流;
public BufferedOutputStream(OutputStream out, int size)
- 创建一个新的缓冲输出流,用指定的缓冲区大小写数据到指定的基本输出流中。> 参数 :out -底层输出流,size -缓冲区大小;
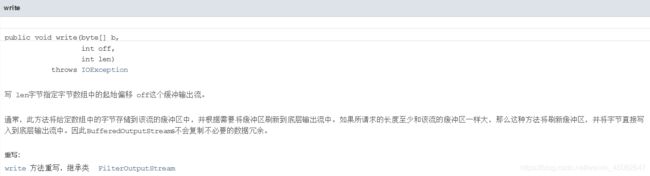
- write()方法
两个write()继承自父类:

- flush()方法
继承自父类;
- 代码示例:
import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class MyTest1 {
public static void main(String[] args) {
BufferedOutputStream bos = null;
try {
bos = new BufferedOutputStream(new FileOutputStream("c.txt"));
bos.write(97);
//一次写入一个字节,没有返回值
bos.write(new byte[]{98, 99, 100});
//一次写入一个字节
bos.write(new byte[]{101, 102, 103, 104, 105}, 0, 3);
//一次写入一个字节数组,从0索引处,开始写3个字节
bos.flush();
//强制刷新
bos.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bos != null) {
bos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
复制文件的效率对比
使用读一个字节写一个字节的方式复制文件,明显高效的字节流相对于它的父类来说效率更高;
但是如果采用的是一次读取一个字节数组,写入一个字节数组,两种流的差别不是很大;
复制文件方式1对比:
import java.io.*;
public class MyTest2 {
public static void main(String[] args) {
long start1 = System.currentTimeMillis();
bufferdCopy();
long end1 = System.currentTimeMillis();
System.out.println("总共耗时:" + (end1 - start1) + "毫秒");
//总共耗时:62毫秒
long start2 = System.currentTimeMillis();
fileCpoy();
long end2 = System.currentTimeMillis();
System.out.println("总共耗时:" + (end2 - start2) + "毫秒");
//总共耗时:110毫秒
}
private static void bufferdCopy() {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
bis = new BufferedInputStream(new FileInputStream("a.txt"));
bos = new BufferedOutputStream(new FileOutputStream("D:\\桌面图标\\copy.txt"));
int by = 0;
while ((by = bis.read()) != -1) {
bos.write(by);
bos.flush();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bis != null) {
bis.close();
}
if (bos != null) {
bos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
private static void fileCpoy() {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream("a.txt");
fos = new FileOutputStream("D:\\桌面图标\\copy1.txt");
int by = 0;
while ((by = fis.read()) != -1) {
fos.write(by);
fos.flush();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fis != null) {
fis.close();
}
if (fos != null) {
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
复制文件方式2对比:
import java.io.*;
public class MyTest3 {
public static void main(String[] args) {
long start1 = System.currentTimeMillis();
bufferdCopy();
long end1 = System.currentTimeMillis();
System.out.println("总共耗时:" + (end1 - start1) + "毫秒");
//总共耗时:72毫秒
long start2 = System.currentTimeMillis();
fileCpoy();
long end2 = System.currentTimeMillis();
System.out.println("总共耗时:" + (end2 - start2) + "毫秒");
//总共耗时:62毫秒
}
private static void bufferdCopy() {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
bis = new BufferedInputStream(new FileInputStream("D:\\桌面图标\\文件程序练习打包\\demo\\亲爱的旅人啊.mp3"));
bos = new BufferedOutputStream(new FileOutputStream("D:\\桌面图标\\copy.mp3"));
byte[] bytes = new byte[1024 * 8];
int len = 0;
while ((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0, len);
bos.flush();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bis != null) {
bis.close();
}
if (bos != null) {
bos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
private static void fileCpoy() {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream("D:\\桌面图标\\文件程序练习打包\\demo\\亲爱的旅人啊.mp3");
fos = new FileOutputStream("D:\\桌面图标\\copy1.mp3");
byte[] bytes = new byte[1024 * 8];
int len = 0;
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes, 0, len);
fos.flush();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fis != null) {
fis.close();
}
if (fos != null) {
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
复制单级/多级文件夹
复制单级文件夹:
我们使用图形界面化复制文件夹很简单,现在给出一个文件夹,里面有很多类型的文件,文本文件、音频文件、图片以及视频文件等,使用代码进行复制;
import java.io.*;
public class MyTest {
public static void main(String[] args) {
File file = new File("D:\\桌面图标\\demo");
File[] files = file.listFiles();
long start = System.currentTimeMillis();
for (File f : files) {
//因为是单级文件夹,所以直接复制,不进行判断了
copyFile(f);
}
long end = System.currentTimeMillis();
System.out.println("复制完成,总共耗时:" + (end - start) + "毫秒");
//复制完成,总共耗时:174毫秒
}
private static void copyFile(File f) {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
//先创建一个文件夹,用来存放复制过来的这些文件
File file = new File("D:\\桌面图标", "demo1");
file.mkdirs();
//创建输入输出流
bis = new BufferedInputStream(new FileInputStream(f));
bos = new BufferedOutputStream(new FileOutputStream(new File(file, f.getName())));
byte[] bytes = new byte[1024 * 8];
int len = 0;
while ((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0, len);
bos.flush();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bis != null) {
bis.close();
}
if (bos != null) {
bos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
- 刚开始在创建文件夹的时候出现了问题,程序运行都结束了,输出了复制文件夹的时间,但是在桌面上没有看到复制好的文件夹, 后来找到了问题,原因是:
- 原来创建文件夹的代码为:
File file = new File("D:\\桌面图标\\demo1"); file.mkdirs();- 因为这个demo1本身就不存在,如果这样创建文件夹的话,返回值是true,但是在桌面上看不到你创建出来的文件夹,程序默认你给定了一个空抽象路径名,虽然你这时候再去操作这个文件夹都可以成功,但是就是看不到他;
- File类有3个构造方法,在创建文件的时候可以采用给定一个路径字符串的方式,但是在创建文件夹的时候,最好不要这样写;
- 代码改正为:
File file = new File("D:\\桌面图标", "demo1"); file.mkdirs();
复制多级文件夹:
现在给出一个文件夹,里面嵌套有子文件夹,还有很多类型的文件,子文件夹里面同样可能有文件夹或者文件,使用代码进行复制;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class MyTest2 {
public static void main(String[] args) {
//首先创建一个文件夹存放复制过来的所有文件/子文件夹
File newFile = new File("D:\\桌面图标", "demo1");
if (!newFile.exists()) {
newFile.mkdirs();
}
long start = System.currentTimeMillis();
File file = new File("D:\\桌面图标\\demo");
copyFiles(file, newFile);
long end = System.currentTimeMillis();
System.out.println("总共耗时为:" + (end - start) + "毫秒");
//总共耗时为:327毫秒
}
/***
* 复制文件
* @param f 要复制的文件
* @param newFile 复制到指定的目录下
*/
private static void copyFile(File f, File newFile) {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(f);
fos = new FileOutputStream(new File(newFile, f.getName()));
byte[] bytes = new byte[1024 * 8];
int len = 0;
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes, 0, len);
fos.flush();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fis != null) {
fis.close();
}
if (fos != null) {
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/***
* 复制文件夹
* @param file 要复制的文件夹
* @param newFile 给定的目录
*/
private static void copyFiles(File file, File newFile) {
File[] files = file.listFiles();
for (File f : files) {
//判断当前文件是文件夹还是文件
//如果是文件,直接复制到当前指定的新文件夹
//如果是文件夹,递归调用该方法
if (f.isFile()) {
copyFile(f, newFile);
} else {
//封装新文件夹的路径
/*copyFiles(f, new File(newFile, f.getName()));
刚开始代码这样写出现了错误,报出来系统找不到指定路径的问题,
看结果单级文件夹复制成功,多级文件夹复制失败
后来发现,在复制多级文件夹的时候,文件可以不需要创建流会帮我们创建
但是遇到了文件夹,递归调用该方法,最初就需要遍历这个子文件夹,
如果遇到了文件,进行复制文件的操作,但是他找不到这个指定的新路径,
因为这个文件夹没有被创建,所以代码改正为:*/
File cate = new File(newFile, f.getName());
if (!cate.exists()) {
cate.mkdirs();
}
copyFiles(f, new File(newFile, f.getName()));
}
}
}
}
文件夹是创建出来的,不是复制出来的;
字符流
- 字符流只能操作文本文件;
- 字符流继承图:
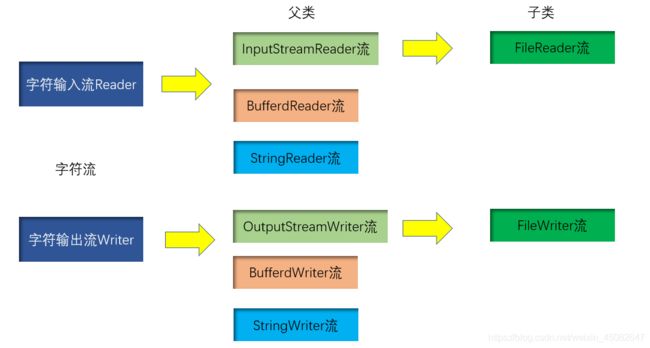
字符流的由来
- 由于字节流操作中文(会出现中文乱码的问题)不是特别方便,所以,Java就提供了字符流;
- 字符流 = 字节流 + 编码表;
- 编码表详解
编码与解码
- 编码:是指按照某种编码格式,将字符串转换为字节数组;
- 把字节数组按照某种编码方式转换为字符串;
- 代码示例:
import java.io.UnsupportedEncodingException;
import java.util.Arrays;
public class MyTest {
public static void main(String[] args) throws UnsupportedEncodingException {
String str="我爱你";
//编码:把看得懂的----->看不懂的
byte[] bytes = str.getBytes();
System.out.println(Arrays.toString(bytes));
//[-26, -120, -111, -25, -120, -79, -28, -67, -96]
//中文一个汉字大部分占3个字节,少数占4个字节
byte[] bytes1 = str.getBytes("GBK");
//解码:把看不懂的------>看得懂的
//编解码使用的编码格式不同,转换出来的结果是什么?
//编解码转换结果都是错误的
String s = new String(bytes1, "UTF-8");
System.out.println(s);
//�Ұ���
byte[] bytes2 = str.getBytes("UTF-8");
String s1 = new String(bytes2, "GBK");
System.out.println(s1);
//鎴戠埍浣�
String s2 = new String(bytes2);
System.out.println(s2);
//我爱你
//平台默认的编码解码方式都是UTF-8
String s3 = new String(bytes1, "GBK");
System.out.println(s3);
//我爱你
//前后编码格式一致,输出结果正确
}
}
1、IDEA平台默认的编码方式为:UTF-8;
2、只有编解码格式一致,才能编解出正确的字符串;
3、中文一个汉字大部分占3个字节,少数占4个字节;
4、码表就像字典一样,新华字典里面的"你"假设在75页,康熙大字典里面的"你"不一定在75页,不是一个字典,查出来的结果不一样,因此编解码出现了乱码;
5、发电报的原理就是编解码:
电报内容---->十进制----->二进制(长短音0,1)----->发送----->密码本(码表)
接收----->二进制----->十进制----->电报内容
接收者与发送者使用的是同一个密码本;
Reader与Writer流
- Reader流是一个抽象类,是所有字符输入流的父类:
public abstract class Readerextends Objectimplements Readable, Closeable
用于读取字符流的抽象类,子类必须实现的方法只有 read(char[], int, int) 和 close();
但是,多数子类将重写此处定义的一些方法,以提供更高的效率和/或其他功能;
- 同样的,Writer流也是一个抽象类,是所有字符输出流的父类:
public abstract class Writerextends Objectimplements Appendable, Closeable, Flushable
写入字符流的抽象类,子类必须实现的方法仅有 write(char[], int, int)、flush() 和 close();
但是,多数子类将重写此处定义的一些方法,以提供更高的效率和/或其他功能。
- 注意:
字节流可以不需要刷新,但是字符流写完一定要刷新,要不然你会发现内容没有写入,还停留在缓冲区;当然,流关闭本身也带有刷新的功能;
InputStreamReader与OutputStreamWriter流
- InputStreamReader流是字节流通向字符流之间的桥梁;
- OutputStreamWriter流时字符流通向字节流之间的桥梁;
- 本身它们就是一个转换的流,可以理解为包了一层外壳的字节流;
InputStreamReader流
- 构造方法:
查看文档可以发现,InputStreamReader流需要一个字节流作为参数,并且可以指定编码格式;

- 由于该类里面很多方法都是之前就已经存在的,这里不再赘述;
- 代码:
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
public class MyTest1 {
public static void main(String[] args) {
InputStreamReader in = null;
try {
//关联文件
in = new InputStreamReader(new FileInputStream("a.txt"));
int i = in.read();
//一次读取一个字符
System.out.println((char) i);
//p
char[] chars = new char[20];
int i2 = in.read(chars, 0, 10);
//读取10个字符,从0索引处开始放在字符数组里面,一次读取一个字符数组指定大小
System.out.println(i2);
//10----返回实际读取到得字符个数
System.out.println(String.valueOf(chars));
//ackage org
char[] chars1 = new char[30];
int i3 = in.read(chars1);
//一次读取一个字符数组
System.out.println(i3);
//30
System.out.println(chars1);
//.westos.demo;import java.io.Fi
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (in != null) {
in.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
OutputStreamWriter流
- 构造方法:
参数需要一个字节流,我们可以给一个子类的对象,并且同样可以指定编码格式;

- 由于很多方法和之前的流都是一样的,这里不再赘述;
- 代码:
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
public class MyTest2 {
public static void main(String[] args) throws IOException {
OutputStreamWriter out = new OutputStreamWriter(new FileOutputStream("c.txt",true));
out.write('你');
out.flush();
out.write('\n');
out.flush();
out.write("观刈麦 白居易\n");
out.flush();
out.write("你好吗?我很好,谢谢!\n", 0, 5);
out.flush();
char[] chars = {'田', '家', '少', '闲', '月', ',', '五', '月', '人', '倍', '忙','\n'};
out.write(chars);
out.flush();
out.write(chars,0,6);
out.flush();
out.close();
}
}
运行结果:
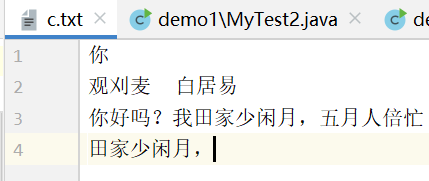
这里注意:
字符流本身的构造方法没有追加写入的功能,但是如果我我们有这样的需求,可以将追加写入的条件写在关联的字节流对象里面,灵活的应用流;
复制文本文件
import java.io.*;
public class MyTest3 {
public static void main(String[] args) {
long start = System.currentTimeMillis();
InputStreamReader in = null;
OutputStreamWriter out = null;
try {
in = new InputStreamReader(new FileInputStream("a.txt"));
out = new OutputStreamWriter(new FileOutputStream("d.txt"));
char[] chars = new char[1000];
int len = 0;
while ((len = in.read(chars)) != -1) {
out.write(chars, 0, len);
out.flush();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println("总共耗时为:" + (end - start) + "毫秒");
//总共耗时为:2毫秒
}
}
FileReader与FileWriter流
- 是InputStreamReader与OutputStreamWriter流的子类,它的存在只是因为Java觉得父类名字太长,子类做了一个简写,本质上,他们就是一样的,因此这两个流也叫做
便捷流; - 查看API发现,它们所有的方法都是继承自父类,没有一个方法是自己重写的或者独有的;
- 它的构造很简单,可以只给一个要读或者写的文件,或者文件路径的字符串;
复制文本文件
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class MyTest {
public static void main(String[] args) {
long start = System.currentTimeMillis();
FileReader in = null;
FileWriter out = null;
try {
in = new FileReader("a.txt");
out = new FileWriter("e.txt");
char[] chars = new char[1000];
int len = 0;
while ((len = in.read(chars)) != -1) {
out.write(chars, 0, len);
out.flush();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println("总共耗时为:" + (end - start) + "毫秒");
//总共耗时为:14毫秒
}
}
BufferdReader与BufferdWriter流
- 是一对高效的字符流;
BufferdReader流
- 构造方法:
public BufferedReader(Reader in)
创建一个使用默认大小输入缓冲区的缓冲字符输入流,参数需要一个字符流,因此只需要给出一个字符流的子类,上面介绍的两个字符输入流都可以用;
- 特有的方法:一次读取一行
public String readLine() throws IOException
- 读取一个文本行,通过下列字符之一即可认为某行已终止:换行 (’\n’)、回车 (’\r’) 或回车后直接跟着换行;
- 返回:包含该行内容的字符串,不包含任何行终止符,如果已到达流末尾,则返回 null ;
BufferdWriter流
- 构造方法:
public BufferedWriter(Writer out)
创建一个使用默认大小输出缓冲区的缓冲字符输出流;
- 特有的方法:写入换行
public void newLine() throws IOException
- 写入一个行分隔符,任何平台都可以使用,也就是具有平台兼容性;
- 之前我们使用write()写入换行符,不同的平台使用的换行符不同:
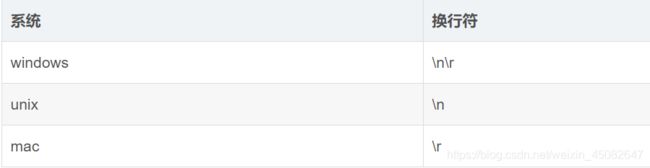
复制文本文件
import java.io.*;
public class MyTest1 {
public static void main(String[] args) throws IOException {
long start = System.currentTimeMillis();
BufferedReader in = new BufferedReader(new FileReader("a.txt"));
BufferedWriter out = new BufferedWriter(new FileWriter("f.txt"));
String len = null;
while ((len = in.readLine()) != null) {
out.write(len);
out.newLine();
out.flush();
}
in.close();
out.close();
long end = System.currentTimeMillis();
System.out.println("总共耗时为:" + (end - start) + "毫秒");
//总共耗时为:4毫秒
}
}
关于IO流的练习
把集合中的数据存储到文本文件
需求:把ArrayList集合中的字符串数据存储到文本文件;
分析:
- a: 创建一个ArrayList集合
- b: 添加元素
- c: 创建一个高效的字符输出流对象
- d: 遍历集合,获取每一个元素,把这个元素通过高效的输出流写到文本文件中
- e: 释放资源
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
public class MyTest2 {
public static void main(String[] args) {
//需求:把ArrayList集合中的字符串数据存储到文本文件
ArrayList<String> list = new ArrayList<>();
list.add("少年听雨歌楼上,红烛昏罗帐。");
list.add("壮年听雨客舟中。江阔云低、断雁叫西风。");
list.add("而今听雨僧庐下。鬓已星星也。悲欢离合总无情。一任阶前、点滴到天明。");
BufferedWriter out = null;
try {
out = new BufferedWriter(new FileWriter("b.txt"));
for (String s : list) {
out.write(s);
out.newLine();
out.flush();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (out != null) {
out.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("写入文本文件结束!");
}
}
把文本文件中的数据存储到集合中
需求:从文本文件中读取数据(每一行为一个字符串数据)到集合中,并遍历集合
分析:
- a: 创建高效的字符输入流对象、
- b: 创建一个集合对象
- c: 读取数据(一次读取一行)
- d: 把读取到的数据添加到集合中
- e: 遍历集合
- f: 释放资源
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
public class MyTest3 {
public static void main(String[] args) {
//把文本文件中的数据存储到集合中
ArrayList<String> list = new ArrayList<>();
BufferedReader in = null;
try {
in = new BufferedReader(new FileReader("b.txt"));
String len = null;
while ((len = in.readLine()) != null) {
list.add(len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (in != null) {
in.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("写入集合完成!");
for (String s : list) {
System.out.println(s);
}
}
}
输出:
写入集合完成!
少年听雨歌楼上,红烛昏罗帐。
壮年听雨客舟中。江阔云低、断雁叫西风。
而今听雨僧庐下。鬓已星星也。悲欢离合总无情。一任阶前、点滴到天明。
【解耦】:
上面两个案例是将文本文件中的数据与内存中的数据进行互相读取写入,这样做的好处就是解耦,学生的名字是数据,和你的代码分离开来,有利于后期的维护,这也是后面学习框架用到的思想;
随机获取文本文件中的姓名
需求:我有一个文本文件,每一行是一个学生的名字,请写一个程序,每次允许随机获取一个学生名称
分析:
- a: 创建一个高效的字符输入流对象
- b: 创建集合对象
- c: 读取数据,把数据存储到集合中
- d: 产生一个随机数,这个随机数的范围是 0 - 集合的长度 . 作为: 集合的随机索引
- e: 根据索引获取指定的元素
- f: 输出
- g: 释放资源
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Random;
public class MyTest4 {
public static void main(String[] args) {
//我有一个文本文件,每一行是一个学生的名字,请写一个程序,每次允许随机获取一个学生名称
ArrayList<String> list = new ArrayList<>();
BufferedReader in = null;
//将文本文件里面的名字存入集合当中
try {
in = new BufferedReader(new FileReader("name.txt"));
String name = null;
while ((name = in.readLine()) != null) {
list.add(name);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (in != null) {
in.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
Random r = new Random();
int index = r.nextInt(list.size());
System.out.println("随机获得的这个学生的姓名为:" + list.get(index));
//随机获得的这个学生的姓名为:李娜
}
}
键盘录入学生信息按照总分排序并写入文本文件
需求:键盘录入3个学生信息(姓名,语文成绩(chineseScore),数学成绩(mathScore),英语成绩(englishScore)),按照总分从高到低存入文本文件
分析:
- a: 创建一个学生类: 姓名、语文成绩(chineseScore)、数学成绩(mathScore)、英语成绩(englishScore)
- b: 因为要排序,所以需要选择TreeSet进行存储学生对象
- c: 键盘录入学生信息,把学生信息封装成一个学生对象,在把学生对象添加到集合中
- d: 创建一个高效的字符输出流对象
- e: 遍历集合,把学生的信息写入到指定的文本文件中
- f: 释放资源
import java.io.*;
import java.util.Comparator;
import java.util.TreeSet;
public class MyTest {
public static void main(String[] args) throws IOException {
//定义一个集合存放学生对象
TreeSet<Student> set = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o2.getTotalScore() - o1.getTotalScore();
}
});
//定义输入流读取键盘输入
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
for (int i = 1; i <= 3; i++) {
System.out.println("请输入第" + i + "个学生的姓名:");
String name = in.readLine();
System.out.println("请输入第" + i + "个学生的语文成绩:");
int cScore = Integer.parseInt(in.readLine());
System.out.println("请输入第" + i + "个学生的数学成绩:");
int mScore = Integer.parseInt(in.readLine());
System.out.println("请输入第" + i + "个学生的英文成绩:");
int eScore = Integer.parseInt(in.readLine());
Student student = new Student(name, cScore, mScore, eScore);
set.add(student);
}
//定义输出流将学生信息写入文本文件
BufferedWriter out = new BufferedWriter(new FileWriter("student.txt"));
out.write("姓名----------语文成绩----------数学成绩--------英语成绩");
out.newLine();
for (Student student : set) {
out.write(student.getName() + "\t\t\t" + student.getChineseScore() + "\t\t\t\t" + student.getMathScore() + "\t\t\t\t" + student.getEnglishScore());
out.flush();
out.newLine();
}
in.close();
out.close();
}
}
学生类:
public class Student {
private int chineseScore;
private int englishScore;
private int mathScore;
private String name;
public Student() {
}
public Student(String name, int chineseScore, int mathScore, int englishScore) {
this.name = name;
this.chineseScore = chineseScore;
this.mathScore = mathScore;
this.englishScore = englishScore;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getTotalScore() {
return this.getChineseScore() + this.getMathScore() + this.getEnglishScore();
}
public int getChineseScore() {
return chineseScore;
}
public void setChineseScore(int chineseScore) {
this.chineseScore = chineseScore;
}
public int getMathScore() {
return mathScore;
}
public void setMathScore(int mathScore) {
this.mathScore = mathScore;
}
public int getEnglishScore() {
return englishScore;
}
public void setEnglishScore(int englishScore) {
this.englishScore = englishScore;
}
}
结果:
- 如果要求追加写入学生信息,则需要在写入流上面增加追加写入的条件true;
- 如果要求每次都保存在一个新的文件里面,则可以每次都获取当前时间然后以该字符串作为文件名保证每次都不重复;
- 在TreeSet集合里面进行判断学生信息的时候过于简单,可以添加如果成绩一样则根据其他信息排序;

复制指定目录下指定后缀名的文件并修改名称
需求: 复制D:\demo目录下所有以.java结尾的文件到E:\demo .并且将其后缀名更改文.jad;
import java.io.*;
public class MyTest1 {
public static void main(String[] args) throws IOException {
//复制 D:\\demo目录下所有以.java结尾的文件到E:\\demo .并且将其后缀名更改文.jad
long start = System.currentTimeMillis();
File file = new File("D:\\桌面图标\\demo");
File newFile = new File("D:\\桌面图标\\demo1");
if (!newFile.exists()) {
newFile.mkdirs();
}
copyFiles(file, newFile);
long end = System.currentTimeMillis();
System.out.println("总共耗时:" + (end - start) + "毫秒");
//总共耗时:47毫秒
}
/***
* 复制文件.java文件,是文本文件
* @param f
* @param newFile
*/
private static void copyFile(File f, File newFile) throws IOException {
BufferedReader in = new BufferedReader(new FileReader(f));
File file = new File(newFile, f.getName().substring(0, f.getName().indexOf(".")).concat(".jad"));
BufferedWriter out = new BufferedWriter(new FileWriter(file));
String len = null;
while ((len = in.readLine()) != null) {
out.write(len);
out.flush();
}
in.close();
out.close();
}
/***
* 复制文件夹
* @param file 要复制的文件夹
* @param newFile 目标文件夹
*/
private static void copyFiles(File file, File newFile) throws IOException {
File[] files = file.listFiles();
for (File f : files) {
if (f.isFile() && f.getName().endsWith(".java")) {
copyFile(f, newFile);
} else if (f.isDirectory()) {
File cate = new File(newFile, f.getName());
if (!cate.exists()) {
cate.mkdirs();
}
copyFiles(f, cate);
}
}
}
}