【kubernetes】kubernetes中的Ingress使用
文章目录
-
-
- 1 Service和Endpoint
-
- 1.1 服务的转发
- 1.2 headless service及其使用场景
- 1.3 服务的类型
- 2 Ingress
- 3 ingress controller
- 4 IngressClass
- 5 nginx-ingress-controller
-
1 Service和Endpoint
k8s中运行的最小单位是Pod,如果单独运行Pod,没有用控制器进行管理,在Pod出现异常情况时,无法进行重建,因此,在部署应用时,通常会使用Deployment、StatefulSet、DaemonSet控制器而不是直接运行Pod。而由于Pod会重建,在进行Pod之间的访问时引入了Service和Endpoint资源。
Service作为一组Pod对外提供服务的载体,当外部需要访问这组Pod时只需要通过ServiceName和ServicePort进行访问,不需要关心该Service后面的Pod,而ServiceName和ServicePort是固定的,通过这种方式就将一组可变的Pod提供的业务功能变成了对ServiceName和ServicePort的访问。
创建nginx的Deployment,这里会创建三个nginx的Pod:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
tolerations:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
然后创建nginx的Service:
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx
name: nginx
spec:
ports:
- name: 5678-80
port: 5678
protocol: TCP
targetPort: 80
selector:
app: nginx
type: ClusterIP
这里需要关注两个内容:
- service.spec.selector:Service通过该选择器找到对应的Pod
- service.spec.type:Service的类型
然后再单独启动一个Pod,在该Pod中可以通过以下方式访问nginx服务:
- curl nginx:5678
- curl nginx.default.svc.cluster.local:5678
上面两种方式中,一种是直接通过ServiceName和ServicePort进行访问,另一种是通过类似域名的方式访问:当创建服务时,集群的dns服务中就会创建一条记录,将..svc.cluster.local解析为服务的IP地址,当通信的双方都处于同一个namespace中时 ,就可以直接用service-name进行访问,例如上面的第一种。
上面也说过,可以在该Pod中用ServiceName的方式访问,那在Node上是否也可以呢?答案是不行,但是,如果直接访问ServiceIp是可以的,问题其实就在域名解析上:Pod的域名解析服务器是kube-dns(位于kube-system中)这个Service的的ClusterIP,所以才能解析服务的域名。
1.1 服务的转发
当直接在Node上使用Service的ClusterIP也是可以访问的,这是因为转发规则是直接配置在宿主机上。
当Service发生变化时,例如创建和删除Service时,kube-proxy就会用Service的信息在Node上修改转发规则,也就是将Node当做一个路由器,根据数据包的头部字段直接转发给实际的Pod。
当前常用的转发机制是iptables和ipvs,通过查看kube-proxy的配置可以确认:kubectl -n kube-system get configmap kube-proxy -o yaml|grep mode,如果mode字段是空或者iptables,则使用iptables,如果mode字段是ipvs,则使用ipvs。
通过iptables-save可以查看实际的转发链:
-A FORWARD -m conntrack --ctstate NEW -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A KUBE-SERVICES -d 10.1.200.124/32 -p tcp -m comment --comment "default/nginx:5678-80 cluster IP" -m tcp --dport 5678 -j KUBE-SVC-VXA2I2E2TLP6KZO2
-A KUBE-SVC-VXA2I2E2TLP6KZO2 ! -s 10.244.0.0/16 -d 10.1.200.124/32 -p tcp -m comment --comment "default/nginx:5678-80 cluster IP" -m tcp --dport 5678 -j KUBE-MARK-MASQ
-A KUBE-SVC-VXA2I2E2TLP6KZO2 -m comment --comment "default/nginx:5678-80" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-YATDIOX3YSHSTGDE
-A KUBE-SVC-VXA2I2E2TLP6KZO2 -m comment --comment "default/nginx:5678-80" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-O7CJYK5V5E7RPY3J
-A KUBE-SVC-VXA2I2E2TLP6KZO2 -m comment --comment "default/nginx:5678-80" -j KUBE-SEP-BT3GK3DTBVAYG4PT
-A KUBE-SEP-YATDIOX3YSHSTGDE -s 10.244.0.41/32 -m comment --comment "default/nginx:5678-80" -j KUBE-MARK-MASQ
-A KUBE-SEP-YATDIOX3YSHSTGDE -p tcp -m comment --comment "default/nginx:5678-80" -m tcp -j DNAT --to-destination 10.244.0.41:80
-A KUBE-SEP-O7CJYK5V5E7RPY3J -s 10.244.0.42/32 -m comment --comment "default/nginx:5678-80" -j KUBE-MARK-MASQ
-A KUBE-SEP-O7CJYK5V5E7RPY3J -p tcp -m comment --comment "default/nginx:5678-80" -m tcp -j DNAT --to-destination 10.244.0.42:80
-A KUBE-SEP-BT3GK3DTBVAYG4PT -s 10.244.0.43/32 -m comment --comment "default/nginx:5678-80" -j KUBE-MARK-MASQ
-A KUBE-SEP-BT3GK3DTBVAYG4PT -p tcp -m comment --comment "default/nginx:5678-80" -m tcp -j DNAT --to-destination 10.244.0.43:80
从这里可以看到,如果目标是服务的IP,就将流量导入到服务的Pod的IP。
1.2 headless service及其使用场景
在服务中有一种特殊的服务:headless service,无头服务,指的是没有生成cluster-ip。
如果要创建无头服务,只需要将ClusterIP类型的服务的clusterIP字段设置为None:
apiVersion: v1
kind: Service
metadata:
name: nginx-lb
spec:
clusterIP: None
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
既然这种服务没有ServiceIp,那么通过域名得到的就不是ServiceIp,而是Service后面的Pod,也就是直接解析为Pod的IP,因此,就不需要在Node上配置转发规则,只需要生成dns记录即可:
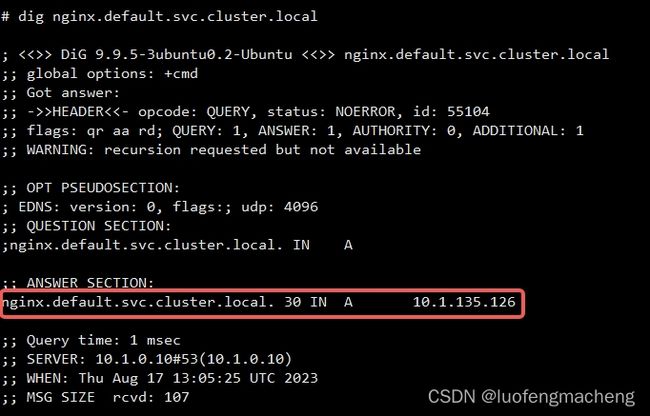
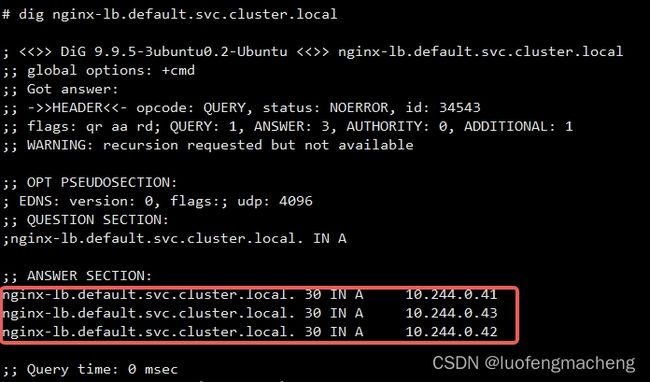
headless service的使用场景主要有两类:
- 想直接访问后端的Pod,而不是通过service进行转发
- 想访问特定的Pod,对于statefulset来说,每个Pod的名称是固定的,可以在service的前面增加Pod的名称得到固定的某个Pod
1.3 服务的类型
Service有4种类型:
- ClusterIP:默认的Service类型,服务的端口只用于做转发
- NodePort:在ClusterIp的基础上,会在每个Node上开启一个端口,就可以在集群外部通过该端口进行访问
- LoadBalancer:在NodePort的基础上,向外部的负载均衡器申请一个External-IP,当通过External-IP和NodePort就可以访问服务
- ExternalName:将集群外部的服务引入到集群内部,其实就是将外部服务的IP和端口写入Endpoint,然后通过Service进行访问
如果需要从集群外部访问服务,那么通常需要使用NodePort和LoadBalancer。
当创建NodePort类型的服务时,只需要将type字段设置为NodePort即可:
apiVersion: v1
kind: Service
metadata:
name: nginx-lb
spec:
type: NodePort
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
这里有两个端口,port:服务的端口,在集群内部可以通过service和port访问,只做映射,targetPort:目标端口,容器中的应用监听的端口。
将上面的yaml提交后,会多一个端口:nodePort,该端口是在宿主机上监听的端口,通过Node的IP和nodePort可以访问应用,可以在yaml中指定该端口,如果没有指定,会自动分配一个端口。如果每个服务都占用宿主机的一个端口,那服务的数量是很有限的,所以,实际环境中很少直接使用这种服务。
LoadBalancer类型的服务需要额外的云平台或者其他组件提供外部IP,更重要的是,这些类型的服务都只能代理4层的服务,如果要代理7层的服务,就需要用到Ingress。
2 Ingress
为了代理7层的服务,k8s提供了抽象的Ingress对象。
Ingress资源本身的字段比较少,主要的其实就是rules规则配置,也就是配置某个域名下的路径转发的后端服务。
rules:
- host: test.baidu.com
http:
paths:
- backend:
serviceName: portal
servicePort: 1234
path: /
pathType: ImplementationSpecific
当访问test.baidu.com/时,portal这个服务的Pod会收到请求。
3 ingress controller
Ingress只是定义了路由转发规则,但是需要实际的程序实现该路由转发,这就是ingress controller。由于有不同的程序都可以实现路由转发,因此,k8s自己定义了Ingress,而将ingress controller交给其他组件自己实现,当前比较流行的ingress controller有:
- 社区的基于nginx实现的nginx ingress controller
- nginx公司实现的nginx ingress controller
- Kong
- Traefik
总的来说,ingress controller就是用Deployment或者DaemonSet方式部署的负载均衡器,该负载均衡器的Pod会根据Ingress和后端Service的变化实时生成最新的配置,然后根据配置转发。例如,对于nginx ingress controller来说,当使用Deployment进行部署时,实际的Pod会根据Ingress和Service实时生成nginx.conf。
4 IngressClass
在k8s 1.18之前,只有Ingress和Ingress Controller,那么,当Ingress Controller部署完成后,会获取哪些Ingress生成转发配置呢?这时候是会获取所有的,所以单个集群就只能部署一个Ingress Controller,但是如果服务很多,或者用户希望用不同的Ingress Controller处理不同的业务,就不行了。
于是,k8s在1.18提供了IngressClass,并在1.19称为正式版本。
IngressClass作为Ingress和IngressController之间的关联关系:Ingress资源中增加ingressClassName字段,指定IngressClass,而Ingress Controller中一般也会指定IngressClass,那么,Ingress Controller就会根据Ingress Class
5 nginx-ingress-controller
从Github NginxInc Ingress下载nginx ingress的包,解压后在deploy/static/provider目录可以看到各种不同环境的安装yaml。
如果是自己安装测试,可以直接用baremetal目录下的deploy.yaml。
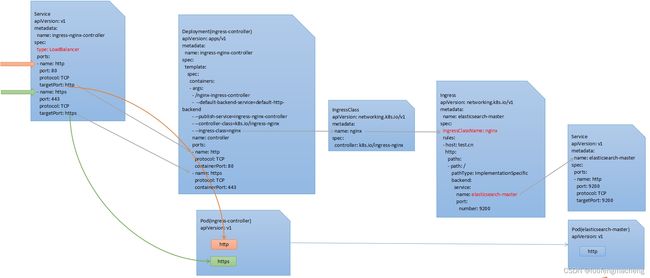
- Ingress资源中只配置路由转发规则
- nginx ingress controller以Deployment运行,可以将它理解为一个运行nginx的容器,并且它还对外暴露一个服务ingress-nginx-controller,由于ingress需要对外提供服务,因此,该服务的类型通常是LoadBalancer或者NodePort,另外,nginx运行时的参数中就有IngressClass
- ingress controller容器中运行的nginx会监听所管理的ingress资源,根据路由转发规则生成nginx的配置文件,当ingress controller的服务收到请求后,根据转发规则转发给后端的pod