Linux内存初始化(3)——pglist_data/zone初始化
Linux内存初始化
- 说明
- 重要数据结构
-
- struct pglist_data
- struct zone
- bootmem_init
-
- zone_sizes_init
-
- free_area_init_node
-
- calculate_node_totalpages
- alloc_node_mem_map
- free_area_init_core
- 总结
-
- 数据结构
- 调用关系
- 相关文章
说明
Kernel版本:4.14.111
ARM处理器,Contex-A7,四核(arm32)
接上文paging_init,对bootmem_init进行说明。
在对页表完成初始化映射后,内核就可以对内存进行管理了,但是内核并不是统一对待这些页面,而是采取none管理区块,区块zone管理各自的内存。
Linux内核使用结构体pglist_data 管理node中的内存资源。所有node的pglist_data结构地址都放在数组node_data中,node_states数组管理所有node的状态。( node指NUMA结构系统中的节点,其中:每个节点可以拥有多个CPU和内存等资源)每个node中又分别管理不同的zone
#ifndef CONFIG_NEED_MULTIPLE_NODES
struct pglist_data __refdata contig_page_data;
EXPORT_SYMBOL(contig_page_data);
#define NODE_DATA(nid) (&contig_page_data)
#endif
对于NUMA架构,存在多个内存node,一般情况下只有一个node。不同架构实现不同,arm32默认只有一个node,定义了上述全局变量contig_page_data,使用宏NODE_DATA获取不同number node,其实就是反悔了全局变量contig_page_data指针
所以在介绍bootmem_init之前,先来介绍下zone、pglist_data相关知识
重要数据结构
struct pglist_data
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
......
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page range, including holes */
int node_id;
......
unsigned long totalreserve_pages;
......
ZONE_PADDING(_pad1_)
spinlock_t lru_lock;
struct lruvec lruvec;
......
ZONE_PADDING(_pad2_)
/* Per-node vmstats */
struct per_cpu_nodestat __percpu *per_cpu_nodestats;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
} pg_data_t;
struct pglist_data是会被经常访问到的,所以这个数据结构要求L1 Cache对齐。ZONE_PADDING宏作用是让前后的成员以L1 cache分割开。分布在不同的cache line中。arm32只有1个node,NUMA架构中也不会有太多node,因此为了性能牺牲部分空间。
成员说明:
node_zones: 分别对应各个类型zone
node_zonelists: 用于分配页框时,查找从哪个zone分配
nr_zones: node_zones中有效zone的个数
node_start_pfn: node的起始物理页面的页帧号
node_present_pages: node里实际管理的页面数量
node_spanned_pages: node内存范围包含的页面数量(包括内存空洞,范围内部分内存可能无法访问)
node_id: 当前node的编号
totalreserve_pages: 总的预留页面数量
lru_lock: 用于对LRU链表并行访问时进行保护
lruveu: LRU链表集合
vmstat: node计数
struct zone
struct zone {
/* Read-mostly fields */
unsigned long watermark[NR_WMARK];
......
long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
#endif
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;
#ifndef CONFIG_SPARSEMEM
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
......
ZONE_PADDING(_pad1_)
struct free_area free_area[MAX_ORDER];
unsigned long flags;
spinlock_t lock;
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
unsigned long compact_cached_free_pfn;
unsigned long compact_cached_migrate_pfn[2];
#endif
#ifdef CONFIG_COMPACTION
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
bool compact_blockskip_flush;
#endif
bool contiguous;
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
atomic_long_t vm_numa_stat[NR_VM_NUMA_STAT_ITEMS];
}
struct zone也是会被经常访问到的,也要求L1 Cache对齐。ZONE_PADDING宏在这里也出现多次。一个内存节点最多也就几个zone,因此为了性能牺牲部分空间。
成员说明:
watermark: 每个zone在系统启动时,会计算出3个水位值,分别为WMARK_MIN, WMARK_LOW, WMARK_HIGH水位,这在页面分配器和kswapd页面回收中会用到。当该zone可用内存小于WMARK_LOW时,会触发oom回收内存。
lowmem_reserve: zone中预留的内存
zong_pgdat: 指向内存节点
pageset: 用于维护Per-CPU上的一系列页面,以减少自旋锁的争用。
pageblock_flags: 页面迁移类型数据内存指针
zone_start_pfn: zone中开始物理页面的页帧号
managed_pages: zone中被伙伴系统管理的页面数量
spanned_pages: zone包含的页面数量
present_pages: zone里实际管理的页面数量,对一些体系结构来说,其值和spanned_pages相等。
free_area: 管理空间区域的数组,包含管理链表等
lock: 并行访问时用于对zone保护的自旋锁
vm_stat: zone计数
通常情况下,内核zone分为
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
}
bootmem_init
start_kernel->setup_arch->paging_init->bootmem_init
void __init bootmem_init(void)
{
unsigned long min, max_low, max_high;
memblock_allow_resize();
max_low = max_high = 0;
find_limits(&min, &max_low, &max_high); (1)
early_memtest((phys_addr_t)min << PAGE_SHIFT,
(phys_addr_t)max_low << PAGE_SHIFT);
/*
* Sparsemem tries to allocate bootmem in memory_present(),
* so must be done after the fixed reservations
*/
arm_memory_present();
/*
* sparse_init() needs the bootmem allocator up and running.
*/
sparse_init();
/*
* Now free the memory - free_area_init_node needs
* the sparse mem_map arrays initialized by sparse_init()
* for memmap_init_zone(), otherwise all PFNs are invalid.
*/
zone_sizes_init(min, max_low, max_high); (2)
/*
* This doesn't seem to be used by the Linux memory manager any
* more, but is used by ll_rw_block. If we can get rid of it, we
* also get rid of some of the stuff above as well.
*/
min_low_pfn = min;
max_low_pfn = max_low;
max_pfn = max_high;
}
1)find_limits函数中会计算出min_low_pfn\max_low_pfn\max_pfn。
分别表示内存块开始的物理地址页帧号,normal内存结束物理地址页帧号,内存块结束物理地址页帧号。
2)zone_sizes_init,执行zone初始化操作
zone_sizes_init
start_kernel->setup_arch->paging_init->bootmem_init->zone_sizes_init
static void __init zone_sizes_init(unsigned long min, unsigned long max_low,
unsigned long max_high)
{
unsigned long zone_size[MAX_NR_ZONES], zhole_size[MAX_NR_ZONES]; (1)
struct memblock_region *reg;
/*
* initialise the zones.
*/
memset(zone_size, 0, sizeof(zone_size)); (2)
/*
* The memory size has already been determined. If we need
* to do anything fancy with the allocation of this memory
* to the zones, now is the time to do it.
*/
zone_size[0] = max_low - min; (3)
#ifdef CONFIG_HIGHMEM
zone_size[ZONE_HIGHMEM] = max_high - max_low; (4)
#endif
/*
* Calculate the size of the holes.
* holes = node_size - sum(bank_sizes)
*/
memcpy(zhole_size, zone_size, sizeof(zhole_size)); (5)
for_each_memblock(memory, reg) {
unsigned long start = memblock_region_memory_base_pfn(reg);
unsigned long end = memblock_region_memory_end_pfn(reg);
if (start < max_low) {
unsigned long low_end = min(end, max_low);
zhole_size[0] -= low_end - start;
}
#ifdef CONFIG_HIGHMEM
if (end > max_low) {
unsigned long high_start = max(start, max_low);
zhole_size[ZONE_HIGHMEM] -= end - high_start;
}
#endif
}
#ifdef CONFIG_ZONE_DMA
/*
* Adjust the sizes according to any special requirements for
* this machine type.
*/
if (arm_dma_zone_size)
arm_adjust_dma_zone(zone_size, zhole_size,
arm_dma_zone_size >> PAGE_SHIFT);
#endif
free_area_init_node(0, zone_size, min, zhole_size); (6)
}
1)定义zone类型的数组,分别表示zone的page数量,zone的空洞page数量。
2)zone_size数组初始化
3)max_low - min计算出来的实际是低端内存page数量。
4)计算高端内存page数量,如果使能了CONFIG_HIGHMEM,但是物理内存数量没有超出lowmem大小,这里计算出来是0
5)zone_size内容复制给zhole_size
6)遍历memblock的memory成员,根据zone_size page数量减去各个memory中可用的page数量,剩下的就是hole page数量了。
7)将node num(0),zone_size数组,物理内存起始页帧号,zhole_size数组,传参给free_area_init_node函数。
下面来看free_area_init_node
free_area_init_node
start_kernel->setup_arch->paging_init->bootmem_init->zone_sizes_init->free_area_init_node
void __paginginit free_area_init_node(int nid, unsigned long *zones_size,
unsigned long node_start_pfn, unsigned long *zholes_size)
{
pg_data_t *pgdat = NODE_DATA(nid); (1)
unsigned long start_pfn = 0;
unsigned long end_pfn = 0;
/* pg_data_t should be reset to zero when it's allocated */
WARN_ON(pgdat->nr_zones || pgdat->kswapd_classzone_idx);
pgdat->node_id = nid; (2)
pgdat->node_start_pfn = node_start_pfn;
pgdat->per_cpu_nodestats = NULL;
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
get_pfn_range_for_nid(nid, &start_pfn, &end_pfn);
pr_info("Initmem setup node %d [mem %#018Lx-%#018Lx]\n", nid,
(u64)start_pfn << PAGE_SHIFT,
end_pfn ? ((u64)end_pfn << PAGE_SHIFT) - 1 : 0);
#else
start_pfn = node_start_pfn; (3)
#endif
calculate_node_totalpages(pgdat, start_pfn, end_pfn, (4)
zones_size, zholes_size);
alloc_node_mem_map(pgdat); (5)
#ifdef CONFIG_FLAT_NODE_MEM_MAP
printk(KERN_DEBUG "free_area_init_node: node %d, pgdat %08lx, node_mem_map %08lx\n",
nid, (unsigned long)pgdat,
(unsigned long)pgdat->node_mem_map);
#endif
reset_deferred_meminit(pgdat);
free_area_init_core(pgdat); (6)
}
1)获取pg_data_t 全局变量指针
2)初始化pg_data_t 部分参数
3)走else分支,计算start_pfn
4)计算总的page数量
5)为所有page,申请struct page数据结构内存,管理这些页面
6)zone初始化
步骤5和6中间,内核打印级别开到最高,会打印pgdat、mem map指针地址,如:
[ 0.000000] free_area_init_node: node 0, pgdat c125fc80, node_mem_map ef6fa000
下面对4、5、6步骤展开进行进一步解释
calculate_node_totalpages
start_kernel->setup_arch->paging_init->bootmem_init->zone_sizes_init->free_area_init_node->calculate_node_totalpages
static void __meminit calculate_node_totalpages(struct pglist_data *pgdat,
unsigned long node_start_pfn,
unsigned long node_end_pfn,
unsigned long *zones_size,
unsigned long *zholes_size)
{
unsigned long realtotalpages = 0, totalpages = 0;
enum zone_type i;
for (i = 0; i < MAX_NR_ZONES; i++) {
struct zone *zone = pgdat->node_zones + i;
unsigned long zone_start_pfn, zone_end_pfn;
unsigned long size, real_size;
size = zone_spanned_pages_in_node(pgdat->node_id, i,
node_start_pfn,
node_end_pfn,
&zone_start_pfn,
&zone_end_pfn,
zones_size);
real_size = size - zone_absent_pages_in_node(pgdat->node_id, i,
node_start_pfn, node_end_pfn,
zholes_size);
if (size)
zone->zone_start_pfn = zone_start_pfn;
else
zone->zone_start_pfn = 0;
zone->spanned_pages = size;
zone->present_pages = real_size;
totalpages += size;
realtotalpages += real_size;
}
pgdat->node_spanned_pages = totalpages;
pgdat->node_present_pages = realtotalpages;
printk(KERN_DEBUG "On node %d totalpages: %lu\n", pgdat->node_id,
realtotalpages);
}
calculate_node_totalpages中,主要操作是计算各个ZONE的page数量,起始物理页面页帧号。根据这些数据对pglist_data中各个zone成员进行初始化。
将所有zone的页面数量加在一起,得到的就是总的页面数量。
内核打印级别调到最高,启动会打印node、page,1G内存非NUMA架构芯片,打印如下:
[ 0.000000] On node 0 totalpages: 262144
alloc_node_mem_map
start_kernel->setup_arch->paging_init->bootmem_init->zone_sizes_init->free_area_init_node->alloc_node_mem_map
static void __ref alloc_node_mem_map(struct pglist_data *pgdat)
{
unsigned long __maybe_unused start = 0;
unsigned long __maybe_unused offset = 0;
/* Skip empty nodes */
if (!pgdat->node_spanned_pages)
return;
#ifdef CONFIG_FLAT_NODE_MEM_MAP
start = pgdat->node_start_pfn & ~(MAX_ORDER_NR_PAGES - 1);
offset = pgdat->node_start_pfn - start;
/* ia64 gets its own node_mem_map, before this, without bootmem */
if (!pgdat->node_mem_map) {
unsigned long size, end;
struct page *map;
/*
* The zone's endpoints aren't required to be MAX_ORDER
* aligned but the node_mem_map endpoints must be in order
* for the buddy allocator to function correctly.
*/
end = pgdat_end_pfn(pgdat);
end = ALIGN(end, MAX_ORDER_NR_PAGES);
size = (end - start) * sizeof(struct page);
map = alloc_remap(pgdat->node_id, size);
if (!map)
map = memblock_virt_alloc_node_nopanic(size,
pgdat->node_id);
pgdat->node_mem_map = map + offset;
}
#ifndef CONFIG_NEED_MULTIPLE_NODES
/*
* With no DISCONTIG, the global mem_map is just set as node 0's
*/
if (pgdat == NODE_DATA(0)) {
mem_map = NODE_DATA(0)->node_mem_map;
#if defined(CONFIG_HAVE_MEMBLOCK_NODE_MAP) || defined(CONFIG_FLATMEM)
if (page_to_pfn(mem_map) != pgdat->node_start_pfn)
mem_map -= offset;
#endif /* CONFIG_HAVE_MEMBLOCK_NODE_MAP */
}
#endif
#endif /* CONFIG_FLAT_NODE_MEM_MAP */
}
重点关注#ifdef CONFIG_FLAT_NODE_MEM_MAP宏内的内容。根据pgdat中的start pfn,page数量,得到page数量,每个page需要申请一个struct page管理。那么page num*sizeof(struct page)得到的就是最终需要申请的内存大小。
pgdat->node_mem_map = map + offset;把申请管理page的struct page指针赋值给pgdat的node_mem_map指针,这样通过pgdat,就可以管理到这些page数据结构了。
开启memblock debug选项后,可以看到我手上设备,1024MB物理内存,申请的struct page内存大小打印如下(这里还是使用memblock分配内存):
[ 0.000000] memblock_virt_alloc_try_nid_nopanic: 9437184 bytes align=0x0 nid=0 from=0x0 max_addr=0x0 alloc_node_mem_map.constprop.8+0x80/0xc0
手动计算:
上文中打印的totapages:262144
手动计算page数量:1024*1024/4 = 262144
sizeof(struct page):36Byte。
需要申请总内存:36 * 262144 = 9,437,184,与打印一致。
free_area_init_core
start_kernel->setup_arch->paging_init->bootmem_init->zone_sizes_init->free_area_init_node->free_area_init_core
static void __paginginit free_area_init_core(struct pglist_data *pgdat)
{
enum zone_type j;
int nid = pgdat->node_id;
pgdat_resize_init(pgdat);
#ifdef CONFIG_NUMA_BALANCING
spin_lock_init(&pgdat->numabalancing_migrate_lock);
pgdat->numabalancing_migrate_nr_pages = 0;
pgdat->numabalancing_migrate_next_window = jiffies;
#endif
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
spin_lock_init(&pgdat->split_queue_lock);
INIT_LIST_HEAD(&pgdat->split_queue);
pgdat->split_queue_len = 0;
#endif
init_waitqueue_head(&pgdat->kswapd_wait);
init_waitqueue_head(&pgdat->pfmemalloc_wait);
#ifdef CONFIG_COMPACTION
init_waitqueue_head(&pgdat->kcompactd_wait);
#endif
pgdat_page_ext_init(pgdat);
spin_lock_init(&pgdat->lru_lock);
lruvec_init(node_lruvec(pgdat));
pgdat->per_cpu_nodestats = &boot_nodestats;
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;
unsigned long size, realsize, freesize, memmap_pages;
unsigned long zone_start_pfn = zone->zone_start_pfn;
size = zone->spanned_pages;
realsize = freesize = zone->present_pages;
/*
* Adjust freesize so that it accounts for how much memory
* is used by this zone for memmap. This affects the watermark
* and per-cpu initialisations
*/
memmap_pages = calc_memmap_size(size, realsize);
if (!is_highmem_idx(j)) {
if (freesize >= memmap_pages) {
freesize -= memmap_pages;
if (memmap_pages)
printk(KERN_DEBUG
" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else
pr_warn(" %s zone: %lu pages exceeds freesize %lu\n",
zone_names[j], memmap_pages, freesize);
}
/* Account for reserved pages */
if (j == 0 && freesize > dma_reserve) {
freesize -= dma_reserve;
printk(KERN_DEBUG " %s zone: %lu pages reserved\n",
zone_names[0], dma_reserve);
}
if (!is_highmem_idx(j))
nr_kernel_pages += freesize;
/* Charge for highmem memmap if there are enough kernel pages */
else if (nr_kernel_pages > memmap_pages * 2)
nr_kernel_pages -= memmap_pages;
nr_all_pages += freesize;
/*
* Set an approximate value for lowmem here, it will be adjusted
* when the bootmem allocator frees pages into the buddy system.
* And all highmem pages will be managed by the buddy system.
*/
zone->managed_pages = is_highmem_idx(j) ? realsize : freesize;
#ifdef CONFIG_NUMA
zone->node = nid;
#endif
zone->name = zone_names[j];
zone->zone_pgdat = pgdat;
spin_lock_init(&zone->lock);
zone_seqlock_init(zone);
zone_pcp_init(zone);
if (!size)
continue;
set_pageblock_order();
setup_usemap(pgdat, zone, zone_start_pfn, size); (1)
init_currently_empty_zone(zone, zone_start_pfn, size);
memmap_init(size, nid, j, zone_start_pfn); (2)
}
}
代码还是比较简洁的,可以概括为,初始化各个类型ZONE的数据。内核等级设置最高,内核启动可以看到Zone相关打印。如:
[ 0.000000] Normal zone: 1728 pages used for memmap
[ 0.000000] Normal zone: 0 pages reserved
[ 0.000000] Normal zone: 196608 pages, LIFO batch:31
[ 0.000000] HighMem zone: 65536 pages, LIFO batch:15
这里根据page打印,可以计算出Normal内存大小为768MB,高端内存大小为256MB。
1)计算并申请pageblock内存。内核中有一个pageblock概念,一个pageblock的大小通常为2的(MAX_ORDER-1)次方个页面。通常情况下MAX_ORDER为11。即pageblock大小为2的10次方page。1024*4KB。即4MB。
#ifndef CONFIG_FORCE_MAX_ZONEORDER
#define MAX_ORDER 11
#else
#define MAX_ORDER CONFIG_FORCE_MAX_ZONEORDER
#endif
每个pageblock有一个相应的MIGRATE_TYPES类型。zone数据结构中有一个成员指针pageblock_flags,指向存放每个pageblock的MIGRATE_TYPES类型的内存空间。
MIGRATE_TYPES在buddy系统管理中会用到,每个类型的页面对应一个链表。
enum migratetype {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
/*
* MIGRATE_CMA migration type is designed to mimic the way
* ZONE_MOVABLE works. Only movable pages can be allocated
* from MIGRATE_CMA pageblocks and page allocator never
* implicitly change migration type of MIGRATE_CMA pageblock.
*
* The way to use it is to change migratetype of a range of
* pageblocks to MIGRATE_CMA which can be done by
* __free_pageblock_cma() function. What is important though
* is that a range of pageblocks must be aligned to
* MAX_ORDER_NR_PAGES should biggest page be bigger then
* a single pageblock.
*/
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES
};
在命令行下执行cat /proc/pagetypeinfo可以看到page有很多类型,Unmovable、Movable等。实际就是migratetype。
[root@linux:/root]# cat /proc/pagetypeinfo
Page block order: 10
Pages per block: 1024
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone Normal, type Unmovable 1 1 1 0 1 1 2 0 2 2 0
Node 0, zone Normal, type Movable 0 0 1 3 3 3 5 3 5 1 178
Node 0, zone Normal, type Reclaimable 1 1 0 1 0 0 0 0 1 0 0
Node 0, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone HighMem, type Unmovable 1 0 0 1 0 1 0 1 1 1 0
Node 0, zone HighMem, type Movable 1 0 0 1 1 0 0 1 1 0 45
Node 0, zone HighMem, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone HighMem, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone HighMem, type CMA 1 1 2 2 0 2 0 0 0 1 11
Node 0, zone HighMem, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Movable Reclaimable HighAtomic CMA Isolate
Node 0, zone Normal 4 187 1 0 0 0
Node 0, zone HighMem 2 46 0 0 16 0
pageblock_flags需要的大小通过setup_usemap来计算,每个pageblock用4个bit来存放migratetype类型。
static unsigned long __init usemap_size(unsigned long zone_start_pfn, unsigned long zonesize)
{
unsigned long usemapsize;
zonesize += zone_start_pfn & (pageblock_nr_pages-1);
usemapsize = roundup(zonesize, pageblock_nr_pages);
usemapsize = usemapsize >> pageblock_order;
usemapsize *= NR_PAGEBLOCK_BITS;
usemapsize = roundup(usemapsize, 8 * sizeof(unsigned long));
return usemapsize / 8;
}
static void __init setup_usemap(struct pglist_data *pgdat,
struct zone *zone,
unsigned long zone_start_pfn,
unsigned long zonesize)
{
unsigned long usemapsize = usemap_size(zone_start_pfn, zonesize);
zone->pageblock_flags = NULL;
if (usemapsize)
zone->pageblock_flags =
memblock_virt_alloc_node_nopanic(usemapsize,
pgdat->node_id);
}
先通过usemap_size函数计算pageblock_flags需要多少字节,然后通过memblock_virt_alloc_node_nopanic申请内存。
我的设备低端内存768MB、高端内存256MB,则对应申请内存768/4/2 = 96BYTE,256/4/2 = 32BYTE。memblock debug打印如下:
[ 0.000000] memblock_virt_alloc_try_nid_nopanic: 96 bytes align=0x0 nid=0 from=0x0 max_addr=0x0 free_area_init_node+0x338/0x3b4
[ 0.000000] memblock_virt_alloc_try_nid_nopanic: 32 bytes align=0x0 nid=0 from=0x0 max_addr=0x0 free_area_init_node+0x338/0x3b4
2)初始化,标记所有页面的migratetype
void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,
unsigned long start_pfn, enum memmap_context context)
{
struct vmem_altmap *altmap = to_vmem_altmap(__pfn_to_phys(start_pfn));
unsigned long end_pfn = start_pfn + size;
pg_data_t *pgdat = NODE_DATA(nid);
unsigned long pfn;
unsigned long nr_initialised = 0;
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
struct memblock_region *r = NULL, *tmp;
#endif
if (highest_memmap_pfn < end_pfn - 1)
highest_memmap_pfn = end_pfn - 1;
/*
* Honor reservation requested by the driver for this ZONE_DEVICE
* memory
*/
if (altmap && start_pfn == altmap->base_pfn)
start_pfn += altmap->reserve;
for (pfn = start_pfn; pfn < end_pfn; pfn++) {
......
not_early:
/*
* Mark the block movable so that blocks are reserved for
* movable at startup. This will force kernel allocations
* to reserve their blocks rather than leaking throughout
* the address space during boot when many long-lived
* kernel allocations are made.
*
* bitmap is created for zone's valid pfn range. but memmap
* can be created for invalid pages (for alignment)
* check here not to call set_pageblock_migratetype() against
* pfn out of zone.
*/
if (!(pfn & (pageblock_nr_pages - 1))) {
struct page *page = pfn_to_page(pfn);
__init_single_page(page, pfn, zone, nid);
set_pageblock_migratetype(page, MIGRATE_MOVABLE); //将zone中所有页面都初始化为MIGRATE_MOVABLE类型
cond_resched();
} else {
__init_single_pfn(pfn, zone, nid);
}
}
}
总结
数据结构
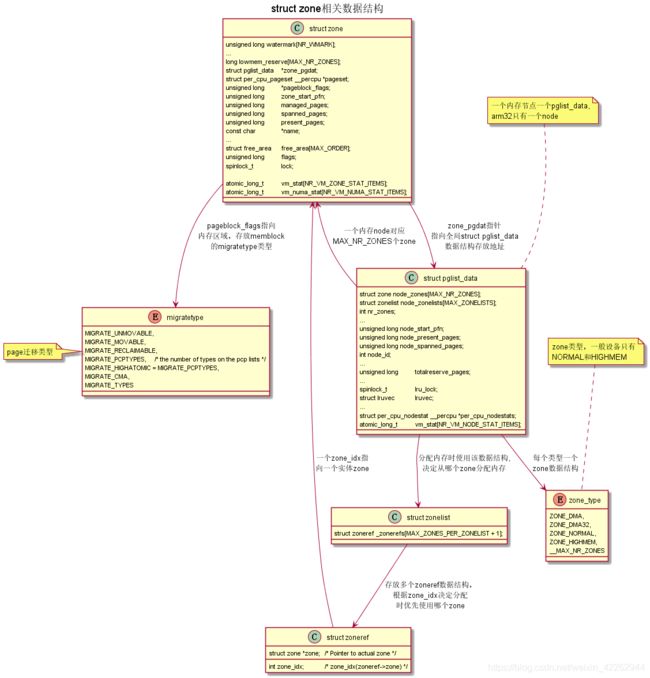
调用关系

相关文章
Linux内存初始化(1)——memblock初始化
Linux内存初始化(2)——paging_init初始化
Linux内存初始化(3)——pglist_data/zone初始化
Linux内存初始化(4)——伙伴系统(buddy)