记一次nginx负载均衡健康检查引起的事故之no live upstreams while connecting to upstream
文章目录
-
- 概要
- 一、负载均衡
-
-
- 1.1、常用指令解析
- 1.2 负载算法配置
- 1.3、反向代理
-
- 二、事故分析
- 三、小结
概要
Nginx是工作中常用的HTTP服务中间件,除了提供HTTP服务,常用的还有反向代理、限流、负载均衡等功能。
负载均衡支持七层负载均衡(HTTP)和四层负载均衡(TCP),本人项目是基于七层负载的。
这次问题发生在一个阳光明丽的上午,本来正在勤勤恳恳的码字,突然大量用户反馈502,立马查监控,发现服务器资源毫无波动,说明并不还突发流量造成的。继续查错误日志,发现遭到不明攻击,有很多伪造的攻击请求错误,继续看日志,发现Nginx一直在刷
no live upstreams while connecting to upstream错误,也就是说此时Nginx负载均衡的上游服务都不可用,那为什么呢?经检测我上游PHP服务运行的好好的,秒级响应呀。
下面我们先了解下Nginx负载均衡,这样才更好的理解问题发生的原因。
一、负载均衡
根据官网可知负载均衡算法有:轮询、加权轮询、hash、ip_hash、最少活跃连接数(least_conn)、随机(random)、最少平均响应时间和最少活跃连接数(least_time)。
另外也有第三方支持的库,常用的如fair(最少响应时间),url_hash(Nginx V1.7.2已支持了,不需要编译第三方库了)。
1.1、常用指令解析
负载均衡配置案例
http{
#负载均衡配置
upstream test_upstreams {
server 127.0.0.1:8081 weight=5 max_fails=3 fail_timeout=8s max_conns=120;
server 127.0.0.1:8082 weight=4 max_fails=3 fail_timeout=8s max_conns=80;
server 127.0.0.1:8083 weight=3 max_fails=3 fail_timeout=8s;
server 127.0.0.1:8084 backup; #备份服务
server 127.0.0.1:8084 down; #永久性不可用的服务,为啥会有这个指令呢???
#空闲连接池
keepalive 30;
keepalive_timeout 120;
keepalive_requests 2400;
}
#限流
limit_req_zone $binary_remote_addr zone=limit_one:10m rate=100r/s;
#http服务
server {
listen 80;
server_name www.test.com;
root /usr/local/web;
location / {
limit_req zone=limit_one burst=5 nodelay;#限流
proxy_pass http://test_upstreams;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_next_upstream error timeout http_500 http_502 http_503 http_504;#故障转移
proxy_next_upstream_timeout 5s;
proxy_next_upstream_tries 2;
proxy_connect_timeout 3s;
proxy_send_timeout 15m;
proxy_read_timeout 15m;
}
}
}
正如案例所现,常用的指令都列出来了,其他不常用的请移步官网。
- weight 指定当前上游服务器负载权重,值越大,分配的流量就越大,默认值是1;
- max_fails 在fail_timeout 时间内失败次数达到该值则认为当前上游服务器不可用,默认值是1;
- fail_timeout 两种作用,一种是同max_fails解释,另一种是判定当前上游服务器不可用时,经过fail_timeout时间会探测是否恢复,默认值是10s;
- max_conns 指定与上游服务最大TCP连接数,每个worker独立计数,用于限流,默认值是0,表示不限制,注意V1.11.5后免费版才支持。
- backup 备份服务,当其它上游服务都不可用时才会启用,可以作为容灾备用,
不支持hash、 ip_hash、 random三种负载算法。 - keepalive 指定每个worker进程可以缓存的最大空闲TCP连接,所以可以称之为空闲连接池,根据官网描述其并不限制最大连接数,所以值不建议过大。默认不开启。
- keepalive_timeout 空闲连接池中连接的最大存活时间,默认1h。
- keepalive_requests 空闲连接池中每个TCP连接处理的最大请求数,到达后就会被释放。默认1000,注意V1.19.10之前是100。
可以看到其实现了健康检查、故障恢复等高可用特性。
1.2 负载算法配置
1、轮询
每个请求依次分配到不同的上游服务。
upstream test_upstreams {
server 127.0.0.1:8081 max_fails=3 fail_timeout=8s max_conns=120;
server 127.0.0.1:8082 max_fails=3 fail_timeout=8s max_conns=80;
server 127.0.0.1:8083 max_fails=3 fail_timeout=8s;
}
2、加权轮询
指定轮询权重,请求分配率和weight值成正比,用于上游服务器性能不均的情况。
upstream test_upstreams {
server 127.0.0.1:8081 weight=5 max_fails=3 fail_timeout=8s max_conns=120;
server 127.0.0.1:8082 weight=4 max_fails=3 fail_timeout=8s max_conns=80;
server 127.0.0.1:8083 weight=3 max_fails=3 fail_timeout=8s;
}
3、hash
对某个key做hash 映射后进行请求转发。
如下配置,按请求url做hash,一般配合缓存命中来使用
upstream test_upstreams {
hash $request_uri;
server 127.0.0.1:8081 weight=5 max_fails=3 fail_timeout=8s max_conns=120;
server 127.0.0.1:8082 weight=4 max_fails=3 fail_timeout=8s max_conns=80;
server 127.0.0.1:8083 weight=3 max_fails=3 fail_timeout=8s;
}
4、一致性hash
upstream test_upstreams {
hash $remote_addr consistent;
server 127.0.0.1:8081 weight=5 max_fails=3 fail_timeout=8s max_conns=120;
server 127.0.0.1:8082 weight=4 max_fails=3 fail_timeout=8s max_conns=80;
server 127.0.0.1:8083 weight=3 max_fails=3 fail_timeout=8s;
}
5、ip_hash
适合需要客户端与服务端有一定粘性的场景,保证客户端每次都命中同一个上游服务。当然了,上游服务发生故障会引起转移的。
upstream test_upstreams {
ip_hash;
server 127.0.0.1:8081 weight=5 max_fails=3 fail_timeout=8s max_conns=120;
server 127.0.0.1:8082 weight=4 max_fails=3 fail_timeout=8s max_conns=80;
server 127.0.0.1:8083 weight=3 max_fails=3 fail_timeout=8s;
}
6、least_conn
考虑权重,优先将请求分配到TCP连接数最少的上游服务。一般来说连接数多的上游服务压力就大些,可以合理配请求压力。
upstream test_upstreams {
least_conn;
server 127.0.0.1:8081 weight=5 max_fails=3 fail_timeout=8s max_conns=120;
server 127.0.0.1:8082 weight=4 max_fails=3 fail_timeout=8s max_conns=80;
server 127.0.0.1:8083 weight=3 max_fails=3 fail_timeout=8s;
}
7、random
随机选择,不过可以配置可选项two,实现随机选两个上游服务,并从中选一个连接数少的一个上游服务。
least_conn也可以由least_time替换,但是least_time商业版才支持
upstream test_upstreams {
random two least_conn;
server 127.0.0.1:8081 weight=5 max_fails=3 fail_timeout=8s max_conns=120;
server 127.0.0.1:8082 weight=4 max_fails=3 fail_timeout=8s max_conns=80;
server 127.0.0.1:8083 weight=3 max_fails=3 fail_timeout=8s;
}
8、least_time
考虑最少平均响应时间和最少活跃连接数作为上游服务,更合理,奈何只有商业版才支持。
upstream test_upstreams {
least_time;
server 127.0.0.1:8081 weight=5 max_fails=3 fail_timeout=8s max_conns=120;
server 127.0.0.1:8082 weight=4 max_fails=3 fail_timeout=8s max_conns=80;
server 127.0.0.1:8083 weight=3 max_fails=3 fail_timeout=8s;
}
9、fair(第三方)
需要编译第三方代码。
看了下源码,不支持 max_conns等其他参数。
看很多文章说是按最短响应时间的优先分配,看了源码,并没有真的用到上游服务响应时间来作为分配指标,所以保留意见
核心逻辑如下:
假设来了有两个可用的上游服务A和B。现在依次来了1、2、3、4、5、6、7、8、9共九个请求。
A 处理了 1、4、5、7 四个请求,B处理了2、3、6、8、9五个请求。那么第10个请求来的时候有:
A 有已处理请求个数nreq=4,间隔请求个数req_delta=10 - 7=3;
B 有已处理请求个数nreq=5,间隔请求个数req_delta=10 - 9=1;
有一个评分函数score_func,优先分配给score_func(nreqA,req_deltaA)/weight和score_func(nreqB,req_deltaB)/weight中最小的一方。
这种算法稳定性完全取决于评分函数,但线上网络环境复杂,请慎用。
upstream test_upstreams {
fair;
server 127.0.0.1:8081 weight=5 max_fails=3 fail_timeout=8s;
server 127.0.0.1:8082 weight=4 max_fails=3 fail_timeout=8s;
server 127.0.0.1:8083 weight=3 max_fails=3 fail_timeout=8s;
}
1.3、反向代理
负载均衡是要配合反向代理使用的,如1.1小节中的案例所示。我们要特别注意 proxy_next_upstream 参数,本次线上事故就与它有关。
官网解释如下:
Specifies in which cases a request should be passed to the next server
即指定在什么情况下将请求转移给下一个上游服务。其默认值error timeout。
其参数有:
- error 与上游服务建立TCP连接、向上游服务传递请求或读取响应标头时出错;
- timeout 与上游服务建立TCP连接、向上游服务传递请求或读取响应标头超时;
- invalid_header 上游服务响应为空或无效响应;
- http_500 上游服务响应500;
- http_502 上游服务响应502;
- http_503 上游服务响应503;
- http_504 上游服务响应504;
- http_403 上游服务响应403;
- http_404 上游服务响应404;
- http_429 上游服务响应429;
支持以上10种错误情况进行请求转移到下一个上游服务,另外:
- non_idempotent 正常情况下当HTTP请求是POST, LOCK, PATCH方法时,上游失败是不会请求下一个上游服务的,需要配置上该参数就可以转移了,
所以配置时要注意接口的幂等性,重试是否会造成重复提交引起业务异常,一般来说GET、OPTIONS之类的是幂等的; - off 关闭自动转移。
所以proxy_next_upstream指令实现了高可用的另一个特性,故障转移。即如果正常请求失败了,会依次向剩余的可用上游服务进行重试,直至有一个成功或全部失败。
不过故障转移也容易造成故障扩散,本次线上故障就是这样的。
proxy_next_upstream_timeout
该参数限制了请求的总时间,默认0,表示会依次向所有可用上游服务请求一次,直至有一个成功或全部失败。
以案例所示,假设8081、8082、8083三个上游服务两秒后返回http_500。如果设置proxy_next_upstream_timeout值为3s,那么只能请求两个上游服务,即除了本来正常的请求失败后还能重试一次。
proxy_next_upstream_tries
该参数限制了请求的总次数,默认0,表示会依次向所有可用上游服务请求一次,直至有一个成功或全部失败。
以案例所示,假设8081、8082、8083三个上游服务均返回http_500。如果设置proxy_next_upstream_tries值为2,那么只会请求两个上游服务,即除了本来正常的请求失败后还能重试一次。
二、事故分析
线上事故其实也有点乌龙了,虽说是因为受到恶意攻击引起的,但主要还是前人的Nginx配置有漏洞造成的,与业务无关。
大概转发路径如下:
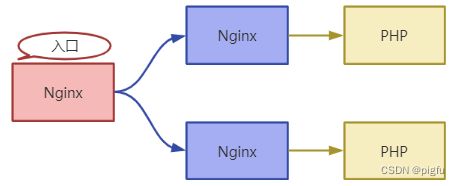
经过日志追查,发现上游的两个Nginx 有这样的配置:
error_page 405 = @405
location @405 {
proxy_pass http://localhost:80;
}
这本来是为了美化 405 错误页面的,结果不知道为什么废弃了,但Nginx配置并没有干掉,这次线上恶意攻击出大了405错误,然后转发到本机80端口,结果并没有80这个服务,就返回给入口Nginx 502了。
入口Nginx收到502,首先触发了
故障转移,请求转移到另一个上游Nginx,依旧收到502,线上恶意攻击比较高频,
接着触发健康检测阈值,导致入口Nginx认为所有上游服务都故障了,就会报no live upstreams while connecting to upstream错误,并返回客户端502,
线上恶意攻击持久且高频,导致入口Nginx的健康检测一直认为上游服务故障,无法恢复,进而正常用户也无法使用。
三、小结
经过第一章的分析,可知Nginx的负载均衡除了负载外,还有故障转移、健康检测、故障自动恢复、限流等特性。
对于健康检测,可以说其是被动检测,即需要先发请求,看从发出到收到响应整个过程的反应作为检测手段。
当然商业版ngx_http_upstream_hc_module模块也提供了主动检测的指令health_check,不差钱的可以用上。
另外淘宝技术团队也开源了一个主动检测模块,源码,有需要的可以用起来。