网络爬虫——urllib(2)
前言
❤️❤️❤️网络爬虫专栏更新中,各位大佬觉得写得不错,支持一下,感谢了!❤️❤️❤️
Python网络爬虫_热爱编程的林兮的博客-CSDN博客
前篇讲解了urllib的基本使用、一个类型六个方法与下载相关内容,这篇继续讲解urlib的其他使用方法。
4、请求对象订制
在将这个之前我们先来看看这个:

在上篇中我们去获取百度首页的源码是http 开头的,但是在最新的百度首页我们可以看到是https开头
 这个时候我们再去进行获取源码试试:
这个时候我们再去进行获取源码试试:
import urllib.request
url="https://www.baidu.com/"
response = urllib.request.urlopen(url)
content = response.read().decode("utf-8")
print(content)代码运行:
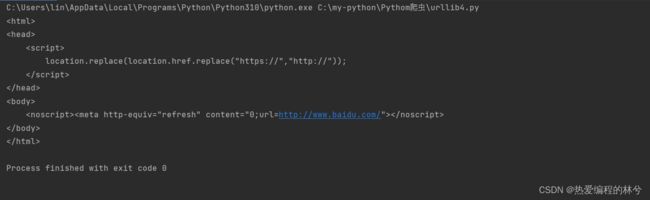
就会发现不一样,哎,为什么获取的是这个呢? 这是因为你给数据不完整,这是我们现在遇到的第一个反爬,这个时候需要先介绍一下User Agent
UA介绍:User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统 及版本、CPU 类型、浏览器及版本。浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等
UA大全:

User Agent其实无处不在:

我们可以看到这个里面包含了很多信息,比如Windows版本、浏览器版本等等的信息。
User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.36我们可以看到这是一个字典类型的数据,所以我们先要把它放在有一个字典里才能去使用,
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.36"}
然后我们添加上headers,运行代码
import urllib.request
url="https://www.baidu.com/"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.36"}
response = urllib.request.urlopen(url,headers)
content = response.read().decode("utf-8")
print(content)发现还是不可以,报错了。然后我们去点击urlopen,查看源码
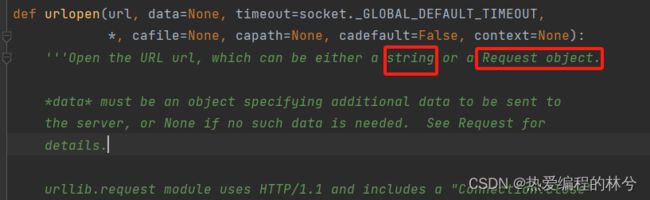
我们看上面源码, 它说可以放一个Sring字符串或者Request对象,这时候就需要请求对象的定制,回归的主题。
那我们就把它封装成一个request对象,然后运行代码
import urllib.request
url="https://www.baidu.com/"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.36"}
# 因为urlopen万法中不能存储字典 所以headers不能传递进去
# 请求对象的定制
request = urllib.request.Request(url,headers)
response = urllib.request.urlopen(request)
content = response.read().decode("utf-8")
print(content)发现还是报错了:

这是为什么呢?我们打开Request源码:

我们可以发现request中的变量是有顺序的,按照顺序我们才可以直接传值(直接写url和headers),所以我们需要进行关键字传参:
import urllib.request
url="https://www.baidu.com/"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.36"}
# 因为urlopen万法中不能存储字典 所以headers不能传递进去
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode("utf-8")
print(content)运行代码我们就成功爬取出来了:
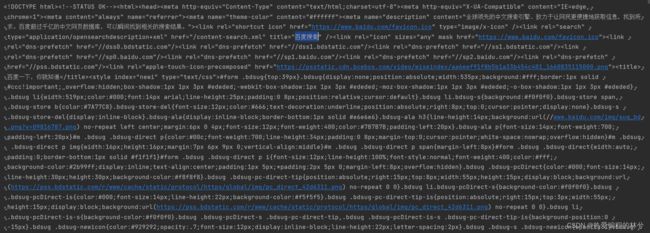
这是我们遇到的第一个反爬。
url的组成
以这个url为例: https://www.baidu.com/s?wd=周杰伦
| 协议 | 主机 | 端口号 | 路径 | 参数 | 锚点 |
|---|---|---|---|---|---|
| http或https | www.baidu.com | http 80/https 443 | s | wd=周杰伦 |
编码的由来
'''编码集的演变‐‐‐
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号, 这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。 但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突, 所以,中国制定了GB2312编码,用来把中文编进去。 你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc‐kr里, 各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。 因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。 Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。 现代操作系统和大多数编程语言都直接支持Unicode。'''
编解码
5、get请求的quote方法(字符串->Unicode编码)

我们可以看到上面的url为
https://www.baidu.com/s?wd=周杰伦但是我们复制下来就会变成Unicode编码:
https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6但是如果是其他汉字情况下,我们不可以一直通过去查询将汉字转换成Unicode编码,所以我们需要学会借助quote方法将中文字符变成对应的Unicode编码
name = urllib.parse.quote('周杰伦')
print(name)运行结果:
%E5%91%A8%E6%9D%B0%E4%BC%A6然后爬取运行这个页面源码:
import urllib.request
url = "https://www.baidu.com/?wd="
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.41"}
# 因为urlopen万法中不能存储字典 所以headers不能传递进去
# 请求对象的定制
name = urllib.parse.quote('周杰伦')
# print(name)
url = url + name
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode("utf-8")
print(content)运行结果:

6、get请求urlencode方法(多个字符串->Unicode编码)
https://www.baidu.com/s?wd=周杰伦&sex=男前面情况是当只需要转换少量字符串时 使用quote方法,当url中有很多字符串时,我们也是一个一个去转换然后进行拼接吗?
那这样效率就太慢了。
这时候我们就应该使用urlencode方法,下面我来演示一下如何使用:
import urllib.parse
# 要求参数必须以字典形式存在
data = {
'wd': '周杰伦',
'sex': '男'
}
a = urllib.parse.urlencode(data)
print(a)
运行代码:
wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7我们可以发现它自动转换并拼接起来了,这就很方便了,所以当有多个字符串(参数)时使用urlencode方法将其直接转换。
那我们来进行一个简单的爬取:
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/?'
data = {
'wd': '周杰伦',
'sex': '男'
}
data = urllib.parse.urlencode(data)
# 请求资源路径
url = url + data
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43"
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取网页源码的数据
content = response.read().decode("utf-8")
# 打印数据
print(content)
运行结果:
7、post请求方式
打开谷歌浏览器,使用英文输入:spider
打开下面对应页面,找到正确的接口:

kw对应的就是你百度翻译所输入的:
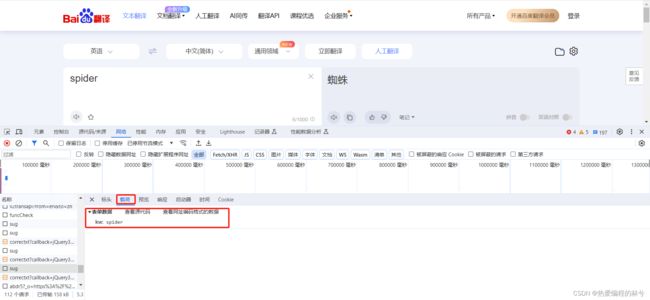
点开预览,查看完整数据:
 那开始进行爬取
那开始进行爬取
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/sug'
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43"
}
# keyword = input('请输入您要查询的单词')
data = {
'kw':'spider'
}
# post请求的参数 必须要进行编码
data = urllib.parse.urlencode(data).encode('utf‐8')
# post的请求的参数 是不会拼接在ur1的后面的而是需要放在请求对象定制的参数中
# post请求的参数必须要进行编码
request = urllib.request.Request(url=url,headers=headers,data=data)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
print(response.read().decode('utf‐8'))
我们运行发现有数据显示,但是有Unicode编码乱码问题
![]()
发现这是一个json数据,所以我们应该 将其转换成json对象然后输出
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/sug'
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43"
}
# keyword = input('请输入您要查询的单词')
data = {
'kw': 'spider'
}
# post请求的参数 必须要进行编码
data = urllib.parse.urlencode(data).encode('utf‐8')
# post的请求的参数 是不会拼接在ur1的后面的而是需要放在请求对象定制的参数中
# post请求的参数必须要进行编码
request = urllib.request.Request(url=url, headers=headers, data=data)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf‐8')
print(content)
# 查看数据类型 字符串类型
print(type(content))
# 字符串-> json对象
import json
obj = json.loads(content)
print(obj)
总结:post和get区别?
- get请求方式的参数必须编码,参数是拼接到url后面,编码之后不需要调用encode方法
- post请求方式的参数必须编码,参数是放在请求对象定制的方法中,编码之后需要调用encode方法
