大数据-玩转数据-Flink Sql 窗口
一、说明
时间语义,要配合窗口操作才能发挥作用。最主要的用途,当然就是开窗口然后根据时间段做计算了。Table API和SQL中,主要有两种窗口:分组窗口(Group Windows)和 含Over字句窗口(Over Windows)。
二、Group Windows
分组窗口(Group Windows)会根据时间或行计数间隔,将行聚合到有限的组(Group)中,并对每个组的数据执行一次聚合函数。Table API中的Group Windows都是使用.window(w:GroupWindow)子句定义的,并且必须由as子句指定一个别名。为了按窗口对表进行分组,窗口的别名必须在group by子句中,像常规的分组字段一样引用。
2.1、分组窗口中的滚动窗口
代码示例:
package com.lyh.flink12;
import com.lyh.bean.WaterSensor;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.lit;
public class Sql_Group_Windows_List {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> waterSensorStream = env.fromElements(new WaterSensor("sensor_1", 1000L, 100),
new WaterSensor("sensor_1", 1000L, 100),
new WaterSensor("sensor_1", 1000L, 100),
new WaterSensor("sensor_2", 1000L, 100),
new WaterSensor("sensor_2", 1000L, 100))
.assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((element, recordtime) -> element.getTs()));
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table table = tableEnv
.fromDataStream(waterSensorStream, $("id"), $("ts").rowtime(), $("vc"));
table
.window(Tumble.over(lit(10).second()).on($("ts")).as("w")) // 定义滚动窗口并给窗口起一个别名
.groupBy($("id"), $("w")) // 窗口必须出现的分组字段中
.select($("id"), $("w").start(), $("w").end(), $("vc").sum())
.execute()
.print();
env.execute();
}
}
运行结果:

2.2、分组窗口中的滑动窗口
.window(Slide.over(lit(10).second()).every(lit(5).second()).on($("ts")).as("w"))
运行结果:

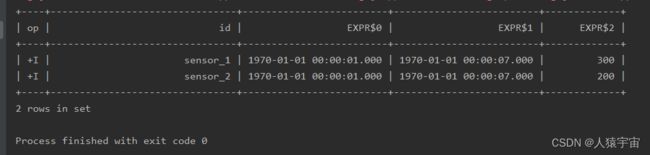
2.3、分组窗口中的会话窗口
.window(Session.withGap(lit(6).second()).on($("ts")).as("w"))
运行结果:
三、Over windows
Over window聚合是标准SQL中已有的(Over子句),可以在查询的SELECT子句中定义。Over window 聚合,会针对每个输入行,计算相邻行范围内的聚合。Table API提供了Over类,来配置Over窗口的属性。可以在事件时间或处理时间,以及指定为时间间隔、或行计数的范围内,定义Over windows。无界的over window是使用常量指定的。也就是说,时间间隔要指定UNBOUNDED_RANGE,或者行计数间隔要指定UNBOUNDED_ROW。而有界的over window是用间隔的大小指定的。
3.1、Unbounded Over Windows
代码示例:
package com.lyh.flink12;
import com.lyh.bean.WaterSensor;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Over;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import static org.apache.flink.table.api.Expressions.*;
public class Sql_Over_windows {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> waterSource = env.fromElements(new WaterSensor("sensor_1", 1000L, 100),
new WaterSensor("sensor_1", 1000L, 100),
new WaterSensor("sensor_2", 4000L, 200),
new WaterSensor("sensor_2", 2000L, 200),
new WaterSensor("sensor_2", 3000L, 200),
new WaterSensor("sensor_2", 5000L, 200),
new WaterSensor("sensor_2", 6000L, 200))
.assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner((element, stamptime) -> element.getTs()));
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table table = tableEnv.fromDataStream(waterSource, $("id"), $("ts").rowtime(), $("vc"));
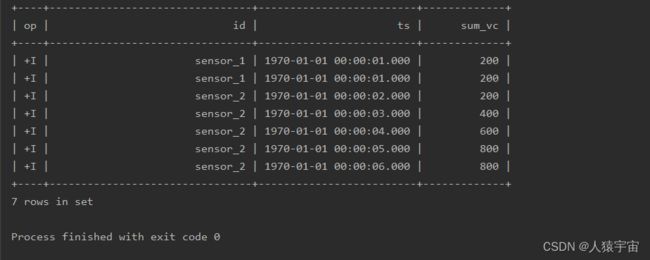
table.window(Over.partitionBy($("id")).orderBy($("ts")).preceding(UNBOUNDED_ROW).as("w"))
.select($("id"), $("ts"), $("vc").sum().over($("w")).as("sum_vc"))
.execute()
.print();
env.execute();
}
}
运行结果:

# 使用UNBOUNDED_RANGE
.window(Over.partitionBy($("id")).orderBy($("ts")).preceding(UNBOUNDED_RANGE).as("w"))

3.2、Bounded Over Windows
当事件时间向前算3s得到一个窗口
.window(Over.partitionBy($("id")).orderBy($("ts")).preceding(lit(3).second()).as("w"))
运行结果:
当行向前推算2行算一个窗口
.window(Over.partitionBy($("id")).orderBy($("ts")).preceding(rowInterval(2L)).as("w"))
四、总结
作为大数据工程师,我们最为熟悉的数据统计方式,当然就是写 SQL 了。SQL 是结构化查询语言(Structured Query Language)的缩写,是我们对关系型数据库进行查询和修改的通用编程语言。在关系型数据库中,数据是以表(table)的形式组织起来的,所以也可以认为 SQL 是用来对表进行处理的工具语言。无论是传统架构中进行数据存储的MySQL、PostgreSQL,还是大数据应用中的 Hive,都少不了 SQL 的身影;而 Spark 作为大数据处理引擎,为了更好地支持在 Hive 中的 SQL 查询,也提供了 Spark SQL 作为入口。Flink 同样提供了对于“表”处理的支持,这就是更高层级的应用 API,在 Flink 中被称为Table API 和 SQL。Table API 顾名思义,就是基于“表”(Table)的一套 API,它是内嵌在 Java、Scala 等语言中的一种声明式领域特定语言(DSL),也就是专门为处理表而设计的;在此基础上,Flink 还基于 Apache Calcite 实现了对 SQL 的支持。这样一来,我们就可以在 Flink 程序中直接写 SQL 来实现处理需求了。