ElasticSearch系列(六)springboot中使用QueryBuilders、NativeSearchQuery实现复杂查询
文章目录
-
- 一、ElasticsearchRestTemplate
- 二、NativeSearchQuery
- 三、QueryBuilders
- 3.1精确查询
- 3.2 模糊查询
- 3.3 范围查询
- 3.4 多个关键字组合查询boolQuery()
- 四、SortBuilders排序
- 五、分页
- 六、高亮显示
本文继续前面文章《ElasticSearch系列(二)springboot中集成使用ElasticSearch的Demo》,在前文中,我们介绍了使用springdata做一些简单查询,但是要实现一些高级的组合等查询,还是需要使用ES的一些原生方法。
本文介绍一些高级查询用法。需要看环境搭建的,先直接看前文。
数据准备:
es中事先插入了20多条数据,用于测试,然后title和content使用了ik_smart分词:
![]()
一、ElasticsearchRestTemplate
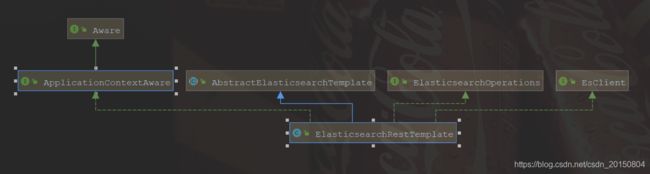
ElasticsearchRestTemplate是Spring封装ES客户端的一些原生api模板,方便实现一些查询,和ElasticsearchTemplate一样,但是目前spring推荐使用前者,是一种更高级的REST风格api。
废话不多说,先上一个demo,
@RunWith(SpringRunner.class)
@SpringBootTest
public class EsArticleControllerTest {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Test
public void test1() {
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
//查询条件
.withQuery(QueryBuilders.queryStringQuery("浦东开发开放").defaultField("title"))
//分页
.withPageable(PageRequest.of(0, 5))
//排序
.withSort(SortBuilders.fieldSort("id").order(SortOrder.DESC))
//高亮字段显示
.withHighlightFields(new HighlightBuilder.Field("浦东"))
.build();
List<ArticleEntity> articleEntities = elasticsearchRestTemplate.queryForList(nativeSearchQuery, ArticleEntity.class);
articleEntities.forEach(item -> System.out.println(item.toString()));
}
}
这个方法是根据指定的title模糊查询一个列表,其中用到了几个关键类,说明一下:
- elasticsearchRestTemplate.queryForList是查询一个列表,用的就是ElasticsearchRestTemplate的一个对象实例;
- NativeSearchQuery :是springdata中的查询条件;
- NativeSearchQueryBuilder :用于建造一个NativeSearchQuery查询对象;
- QueryBuilders :设置查询条件,是ES中的类;
- SortBuilders :设置排序条件;
- HighlightBuilder :设置高亮显示;
下面分类具体介绍下。
二、NativeSearchQuery
这是一个原生的查询条件类,用来和ES的一些原生查询方法进行搭配,实现一些比较复杂的查询。
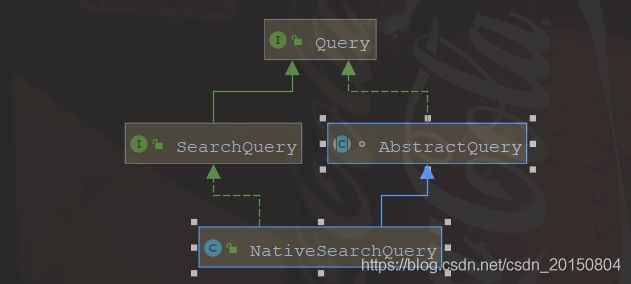
下面是NativeSearchQuery的一些内部属性,基本上都是ES的一些内部对象:
//查询条件,查询的时候,会考虑关键词的匹配度,并按照分值进行排序
private QueryBuilder query;
//查询条件,查询的时候,不考虑匹配程度以及排序这些事情
private QueryBuilder filter;
//排序条件的builder
private List<SortBuilder> sorts;
private final List<ScriptField> scriptFields = new ArrayList<>();
private CollapseBuilder collapseBuilder;
private List<FacetRequest> facets;
private List<AbstractAggregationBuilder> aggregations;
//高亮显示的builder
private HighlightBuilder highlightBuilder;
private HighlightBuilder.Field[] highlightFields;
private List<IndexBoost> indicesBoost;
上述属性的值,就像demo的写的,通过NativeSearchQueryBuilder进行构建即可,最终作为elasticsearchRestTemplate的查询条件入参。
三、QueryBuilders
QueryBuilders是ES中的查询条件构造器。下面结合一些具体的查询场景,分析其常用方法。
ES中已经有title为 “总裁关心浦东开发开放” 的数据;
ik_smart分词结果:
{
"tokens": [
{
"token": "总裁",
"start_offset": 3,
"end_offset": 6,
"type": "CN_WORD",
"position": 1
},
{
"token": "关心",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 2
},
{
"token": "浦东",
"start_offset": 8,
"end_offset": 10,
"type": "CN_WORD",
"position": 3
},
{
"token": "开发",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 4
},
{
"token": "开放",
"start_offset": 12,
"end_offset": 14,
"type": "CN_WORD",
"position": 5
}
]
}
3.1精确查询
精确,指的是查询关键字(或者关键字分词后),必须与目标分词结果完全匹配。
1.指定字符串作为关键词查询,关键词支持分词
//查询title字段中,包含 ”开发”、“开放" 这个字符串的document;相当于把"浦东开发开放"分词了,再查询;
QueryBuilders.queryStringQuery("开发开放").defaultField("title");
//不指定feild,查询范围为所有feild
QueryBuilders.queryStringQuery("青春");
//指定多个feild
QueryBuilders.queryStringQuery("青春").field("title").field("content");
2.以关键字“开发开放”,关键字不支持分词
QueryBuilders.termQuery("title", "开发开放")
QueryBuilders.termsQuery("fieldName", "fieldlValue1","fieldlValue2...")
3.以关键字“开发开放”,关键字支持分词
QueryBuilders.matchQuery("title", "开发开放")
QueryBuilders.multiMatchQuery("fieldlValue", "fieldName1", "fieldName2", "fieldName3")
3.2 模糊查询
模糊,是指查询关键字与目标关键字可以模糊匹配。
1.左右模糊查询,其中fuzziness的参数作用是在查询时,es动态的将查询关键词前后增加或者删除一个词,然后进行匹配
QueryBuilders.fuzzyQuery("title", "开发开放").fuzziness(Fuzziness.ONE)
2.前缀查询,查询title中以“开发开放”为前缀的document;
QueryBuilders.prefixQuery("title", "开发开放")
3.通配符查询,支持*和?,?表示单个字符;注意不建议将通配符作为前缀,否则导致查询很慢
QueryBuilders.wildcardQuery("title", "开*放")
QueryBuilders.wildcardQuery("title", "开?放")
注意,
在分词的情况下,针对fuzzyQuery、prefixQuery、wildcardQuery不支持分词查询,即使有这种doucment数据,也不一定能查出来,因为分词后,不一定有“开发开放”这个词;
查询总结:
| 查询关键词 | 开发开放 | 放 | 开 |
|---|---|---|---|
| queryStringQuery | 查询目标中含有开发、开放、开发开放的 | 无 | 无 |
| matchQuery | 同queryStringQuery | 无 | 无 |
| termQuery | 无结果,因为它不支持分词 | 无 | 无 |
| prefixQuery | 无结果,因为它不支持分词 | 无 | 有,目标分词中以”开“开头的 |
| fuzzyQuery | 无结果,但是与fuzziness参数有关系 | 无 | 无 |
| wildcardQuery | 开发开放*无结果 | 开*,有 | 放*,无 |
3.3 范围查询
//闭区间查询
QueryBuilders.rangeQuery("fieldName").from("fieldValue1").to("fieldValue2");
//开区间查询,默认是true,也就是包含
QueryBuilders.rangeQuery("fieldName").from("fieldValue1").to("fieldValue2").includeUpper(false).includeLower(false);
//大于
QueryBuilders.rangeQuery("fieldName").gt("fieldValue");
//大于等于
QueryBuilders.rangeQuery("fieldName").gte("fieldValue");
//小于
QueryBuilders.rangeQuery("fieldName").lt("fieldValue");
//小于等于
QueryBuilders.rangeQuery("fieldName").lte("fieldValue");
3.4 多个关键字组合查询boolQuery()
QueryBuilders.boolQuery()
QueryBuilders.boolQuery().must();//文档必须完全匹配条件,相当于and
QueryBuilders.boolQuery().mustNot();//文档必须不匹配条件,相当于not
QueryBuilders.boolQuery().should();//至少满足一个条件,这个文档就符合should,相当于or
具体demo如下:
public void testBoolQuery() {
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.boolQuery()
.should(QueryBuilders.termQuery("title", "开发"))
.should(QueryBuilders.termQuery("title", "青春"))
.mustNot(QueryBuilders.termQuery("title", "潮头"))
)
.withSort(SortBuilders.fieldSort("id").order(SortOrder.DESC))
.withPageable(PageRequest.of(0, 50))
.build();
List<ArticleEntity> articleEntities = elasticsearchRestTemplate.queryForList(nativeSearchQuery, ArticleEntity.class);
articleEntities.forEach(item -> System.out.println(item.toString()));
}
以上是查询title分词中,包含“开发”或者“青春”,但不能包含“潮头”的document;
也可以多个must组合。
四、SortBuilders排序
上述demo中,我们使用了排序条件:
//按照id字段降序
.withSort(SortBuilders.fieldSort("id").order(SortOrder.DESC))
注意排序时,有个坑,就是在以id排序时,比如降序,结果可能并不是我们想要的。因为根据id排序,es实际上会根据_id进行排序,但是_id是string类型的,排序后的结果会与整型不一致。
建议:
在创建es的索引mapping时,将es的id和业务的id分开,比如业务id叫做myId:
@Id
@Field(type = FieldType.Long, store = true)
private Long myId;
@Field(type = FieldType.Text, store = true, analyzer = "ik_smart")
private String title;
@Field(type = FieldType.Text, store = true, analyzer = "ik_smart")
private String content;
这样,后续排序可以使用myId进行排序。
五、分页
使用如下方式分页:
@Test
public void testPage() {
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("title", "青春"))
.withSort(SortBuilders.fieldSort("myId").order(SortOrder.DESC))
.withPageable(PageRequest.of(0, 50))
.build();
AggregatedPage<ArticleEntity> page = elasticsearchRestTemplate.queryForPage(nativeSearchQuery, ArticleEntity.class);
List<ArticleEntity> articleEntities = page.getContent();
articleEntities.forEach(item -> System.out.println(item.toString()));
}
注意,如果不指定分页参数,es默认只显示10条。
六、高亮显示
查询title字段中的关键字,并高亮显示:
@Test
public void test() {
String preTag = "";
String postTag = "";
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("title", "开发"))
.withPageable(PageRequest.of(0, 50))
.withSort(SortBuilders.fieldSort("id").order(SortOrder.DESC))
.withHighlightFields(new HighlightBuilder.Field("title").preTags(preTag).postTags(postTag))
.build();
AggregatedPage<ArticleEntity> page = elasticsearchRestTemplate.queryForPage(nativeSearchQuery, ArticleEntity.class,
new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> clazz, Pageable pageable) {
List<ArticleEntity> chunk = new ArrayList<>();
for (SearchHit searchHit : response.getHits()) {
if (response.getHits().getHits().length <= 0) {
return null;
}
ArticleEntity article = new ArticleEntity();
article.setMyId(Long.valueOf(searchHit.getSourceAsMap().get("id").toString()));
article.setContent(searchHit.getSourceAsMap().get("content").toString());
HighlightField title = searchHit.getHighlightFields().get("title");
if (title != null) {
article.setTitle(title.fragments()[0].toString());
}
chunk.add(article);
}
if (chunk.size() > 0) {
return new AggregatedPageImpl<>((List<T>) chunk);
}
return null;
}
@Override
public <T> T mapSearchHit(SearchHit searchHit, Class<T> type) {
return null;
}
});
List<ArticleEntity> articleEntities = page.getContent();
articleEntities.forEach(item -> System.out.println(item.toString()));
}
结果:
title=勇立潮头——总裁关心浦东开发开放40, content=外交部:望