深入了解 Linux 中的 AWK 命令:文本处理的瑞士军刀
简介
在Linux和Unix操作系统中,文本处理是一个常见的任务。AWK命令是一个强大的文本处理工具,专门进行文本截取和分析,它允许你在文本文件中查找、过滤、处理和格式化数据。本文将深入介绍Linux中的AWK命令,让你了解其基本用法和高级功能,以便更高效地处理文本数据。
什么是AWK?
AWK是一种处理文本文件的编程语言,它得名于其创始人Alfred Aho、Peter Weinberger和Brian Kernighan的姓氏首字母。AWK在命令行中使用,但更多是作为脚本来使用。AWK语言的强大之处在于它可以轻松地执行以下任务:
-
文本搜索和匹配:AWK可以在文本中搜索特定模式或关键字,并执行相应的操作。
-
数据提取和转换:它可以从文本中提取数据,并将其转换成不同的格式。
-
报告生成:AWK可以生成自定义格式的报告,适用于文本文件中的数据分析。
-
文本编辑:它可以用于编辑文本文件,添加、删除或修改文本行。
AWK命令的执行过程
基本语法
awk -v var=value '模式pattern { 动作action }' filename- awk的指令(patten+action)一定要用单引号 '... ' 括起来,动作一定要用花括号 { ... } 括起;
- 模式可以是正则表达式、条件表达式或两种组合,如果模式是正则表达式要用定界符:/ ;
- 动作之间用 ; 分开;
- 定义自定义变量var,不需要接$符号;
完整语法
awk 'BEGIN{commands}pattern{commands}END{commands}' filename
或
awk 'BEGIN {
# 初始化操作(处理数据前,执行的命令。例如,设置变量等)
}
/pattern1/ {
# 当匹配到 pattern1 时执行的操作
}
/pattern2/ {
# 当匹配到 pattern2 时执行的操作
}
END {
# 输出最终结果或进行清理操作(处理数据后,执行的命令)
}' filename
执行过程的详细解释:
- awk 命令启动,并读取 filename 中的文本文件作为输入数据。如果未提供 filename,则默认从标准输入读取数据。
- BEGIN 块中的命令会在处理输入文件之前执行一次。这通常用于初始化变量、设置选项或执行其他预处理操作。
- awk 逐行读取输入文件,并将每一行拆分成字段(默认以空格为字段分隔符,可以使用 -F 选项指定其他分隔符)。
- pattern 块中的命令会在输入行匹配指定的模式时执行。模式可以是正则表达式或其他条件。如果存在多个 pattern 块,则会根据匹配的模式按顺序执行相应的命令。
- 在 pattern 块中,您可以访问字段和执行各种操作。例如,可以对字段进行计算、打印匹配行,或根据条件执行不同的操作。
- 当 awk 处理完输入文件的所有行后,它会执行 END 块中的命令。这通常用于输出最终结果、汇总数据或执行清理操作。
- awk 完成处理后,它会将结果打印到标准输出(通常是终端),除非您在脚本中显式使用 print 命令输出结果。
基本用法
在终端中,你可以使用以下的形式运行AWK命令:
1. 最简单的形式:
awk [选项] '{ action }' file.txt这是最基本的形式,它会将 file.txt 文件的所有行都执行操作action。
选项参数有:
- -F 指定输入文件的字段分隔符,用于将输入行分割为字段。示例:
awk -F, '{ print $1 }' data.txt
在这个示例中,-F, 指定逗号 , 作为字段分隔符,然后打印每行的第一个字段。- -v 定义一个用户定义变量,可以在脚本中使用。示例:
awk -v name=John '{ print "Hello, " name "!" }' file.txt
在这个示例中,-v 选项定义了一个名为 name 的变量,并将其值设置为 "John",然后在脚本中使用它。- -f 指定包含 awk 脚本的文件,以便在执行时加载脚本。示例:
awk -f myscript.awk file.txt
在这个示例中,-f 选项指定了一个名为 myscript.awk 的脚本文件,awk 将执行其中的命令。
- -W [option]:启用某些扩展选项。示例:
awk -W version
这将显示 awk 的版本信息。awk -W help
打印全部awk选项和每个选项的简短说明。- -E:切换为扩展正则表达式(ERE)模式匹配。示例:
awk -E '/[0-9]+/ { print }' file.txt
在这个示例中,-E 选项允许使用扩展正则表达式模式,匹配包含数字的行。- -i inplace:在原始文件中进行原地编辑。示例:
awk -i inplace '{ sub("old_pattern", "new_pattern") } 1' file.txt
这将在 file.txt 中查找并替换第一个匹配的 "old_pattern" 为 "new_pattern",并将结果写回原始文件。- -n:禁用默认的自动打印行为。示例:
awk -n '/pattern/ { print }' file.txt
这将只打印包含 "pattern" 的行,不会自动打印所有行。- -FPOSIX:使用 POSIX 标准的字段分隔符。示例:
awk -FPOSIX '{ print $1 }' data.txt
这将使用 POSIX 标准的字段分隔符进行字段分割。- -Wlint:启用 lint 模式,用于检查 awk 脚本中的潜在问题。示例:
awk -Wlint -f myscript.awk file.txt
这将启用 lint 模式并检查 myscript.awk 中的潜在问题。- -Wsource=program-text:允许在命令行上直接提供 awk 脚本。示例:
awk -Wsource='{ print "Hello, World!" }' file.txt
这将在命令行上直接提供 awk 脚本,然后在 file.txt 上执行。2. 指定字段分隔符的形式:
awk -F, '{ print $1, $2 }' data.csv这个形式使用了 -F 选项来指定字段分隔符为逗号,然后打印每行的第一个和第二个字段。
3. 使用脚本文件的形式:
awk -f myscript.awk file.txt在这个形式中,awk 使用了 -f 选项,后面跟着一个包含 awk 脚本的文件 myscript.awk,并对 file.txt 文件执行该脚本中定义的操作。
4. 设置变量的形式:
awk -v var=value '{ print var, $1 }' file.txt这个形式使用了 -v 选项来设置一个变量 var,然后将其与文件中的第一个字段一起打印。
5. 条件过滤的形式:
awk 'pattern { action }' filename- pattern:是一个正则表达式或条件,用于匹配文本中的行。
- action:是在满足条件的行上执行的操作。
- filename:是要处理的文本文件的名称。
这个形式使用了正则表达式模式 /pattern/,只对文件中匹配该模式的行执行操作action。
以下是一个示例,演示了如何使用AWK命令查找并打印包含关键字的行:
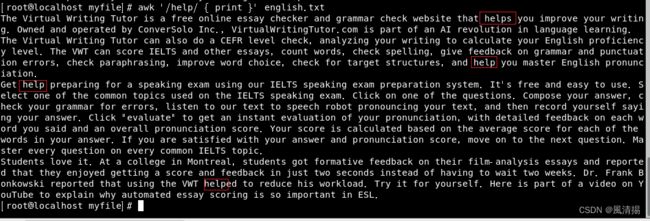
awk '/help/ { print }' english.txt
这将在名为english.txt的文件中查找包含关键字"help"的行,并将它们打印到终端。
其它
有时候,AWK命令的形式的部分会有省略,有如下几种情况,举例说明:
1. 只有模式没有动作,结果为显示$0($0 表示整行文本)
awk '/chen/' scores.txt
2. 只有动作没有模式,就直接执行动作
who | awk '{print $2}'
字段和分隔符
内置变量$1
AWK默认使用空格作为字段分隔符。在处理文本时,它将文本行分割成多个字段,你可以使用$1、$2、$3等特殊的内置变量来引用这些字段($0 表示整行文本),它们用于表示当前正在处理的输入行(或记录)的不同字段(列)的值。例如,$1代表文本中第一个字段,$2代表第二个字段,$n 表示第n个字段,以此类推。
以下是一个示例,演示如何使用AWK命令提取文本行中的第二个字段:
awk '{ print $2 }' english.txt 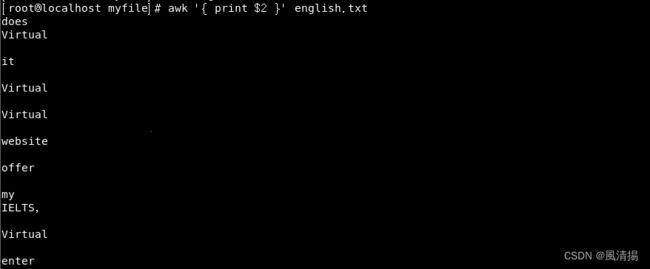
如果文本文件中的字段是以逗号、制表符或其他字符分隔的,你可以使用 -F 选项来指定分隔符。例如,如果文本以逗号分隔,您可以这样使用:
awk -F, '{ print $2 }' english.txt 
内置变量FS & OFS
AWK 命令中,用于控制字段的输入和输出分隔符的内置变量:
- 输入分隔符 FS (Field Separator):用于指定字段的输入分隔符。默认情况下,awk 使用空格作为字段分隔符,但你可以使用 -F 选项或在 BEGIN 块中设置 FS 来指定不同的字段分隔符。
- 输出分隔符 OFS (Output Field Separator):用于指定字段的输出分隔符。默认情况下,OFS 为空格,这意味着 awk 在打印输出时会在字段之间插入空格。你可以在 BEGIN 块中设置 OFS 来指定不同的输出字段分隔符。
示例 1
以下是一个示例,演示了如何在 awk 中使用 FS 和 OFS 来控制字段分隔和输出分隔:
假设有一个 CSV 文件 data.csv 包含以下内容:
Alice,90,88,92
Bob,78,85,80
Charlie,92,94,89可以使用以下 awk 命令来读取该文件,将逗号作为字段分隔符,并在输出中使用制表符作为字段分隔符:
awk 'BEGIN {
FS = ","
OFS = "\t" # 使用制表符作为输出字段分隔符
}
{
print $1, $2, $3, $4
}' data.csv命令也可以这样写入(注意:在 AWK 中,可以在同一行上包含多个命令,并使用分号来分隔它们)
awk 'BEGIN { FS = ","; OFS = "\t" } { print $1, $2, $3, $4 }' data.csv
运行此命令将输出以下内容: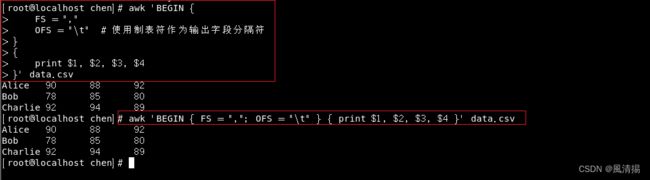
在这个示例中,BEGIN 块中设置了 FS 为逗号,表示字段分隔符是逗号。然后,OFS 被设置为制表符,表示输出字段分隔符是制表符。这样,在输出时字段之间将使用制表符分隔。
示例 2
OFS 设置为逗号,输出重定向到csv文件
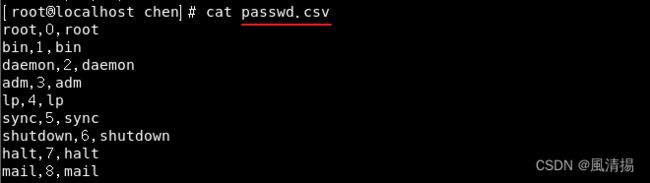
awk -F: 'OFS=","{print $1,$3,$5}' /etc/passwd > passwd.csv运行此命令将输出以下内容:
内置变量
AWK还提供了一些内置变量,用于执行更复杂的操作:
- NR:代表记录号(行号),用于跟踪处理的行数。
- NF:代表字段数,用于确定每行有多少个字段。
- FS:代表字段分隔符,用于指定字段之间的分隔符。
- RS:代表记录分隔符,用于指定记录之间的分隔符。
以下是一个示例,演示如何使用这些内置变量来执行操作:
示例1:
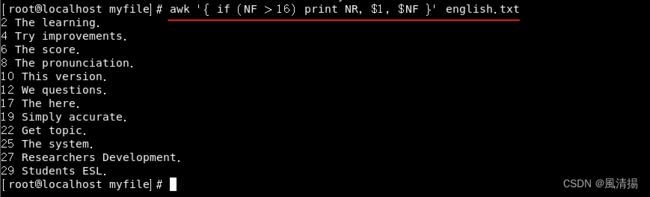
awk '{ if (NF > 16) print NR, $1, $NF }' english.txt 这将打印出那些包含16个或更多字段的行的:行号NR、第一个字段$1和最后一个字段$NF。
示例2:
awk 'NR >= 3 && NR <= 5{print NR,$0}' /etc/passwd
这个命令会打印第三到第五行的内容。使用 NR(行号)内置变量来检查每一行的行号。NR >= 3 表示行号大于等于3,NR <= 5 表示行号小于等于5。

也可以写成下面这种形式,作用结果相同。因为在 AWK 中,逗号“ , ”用于表示一个范围,其中 NR==3,NR==5 表示从行号 3 到行号 5 的范围。然后,{print NR, $0} 用于打印匹配范围内的行号和整个行内容。
awk 'NR==3,NR==5{print NR,$0}' /etc/passwdAWK 操作符
AWK 是一种强大的文本处理工具,支持各种操作符,用于执行条件检查、数学运算、字符串处理和模式匹配等操作。以下是一些常见的 AWK 操作符及其示例:
算术操作符:
+:加法操作。-:减法操作。*:乘法操作。/:除法操作。%:取模操作。
示例:这个命令计算每行中的第一个字段和第二个字段的和,并将结果打印出来。
awk '{ result = $1 + $2; print result }' data.txt关系操作符:
==:相等。!=:不相等。<:小于。>:大于。<=:小于等于。>=:大于等于。
示例:这个命令检查第三个字段是否等于 1001,如果是,则打印相应行的第一个字段。
awk '$3 == 1001 { print $1 }' data.txt逻辑操作符:
&&:逻辑与。||:逻辑或。!:逻辑非。
示例:这个命令检查第二个字段是否大于 50 ,并且第三个字段是否小于 90,如果满足条件,则打印相应行的第一个字段。
awk '$2 > 50 && $3 < 90 { print $1 }' data.txt赋值操作符:
=:赋值操作。
示例:这个命令计算每行中的第一个字段和第二个字段的和,并将结果赋值给变量 total,然后打印出总和。
awk '{ total = $1 + $2; print "Total: " total }' data.txt增量/减量操作符:
++:增量操作。--:减量操作。
示例:这个命令用于计算文件中的总行数。每次处理一行时,会将变量 count 增加 1。在处理结束时(END 部分),打印总行数。
awk '{ count++; } END { print "Total Lines: " count }' data.txt模式匹配操作符:
~:匹配模式。!~:不匹配模式。
示例:这个命令匹配第四个字段是否包含特定模式(在示例中是 "pattern")。如果匹配成功,则打印相应行的第一个字段。
awk '$4 ~ /pattern/ { print $1 }' data.txt字符串连接操作符:
"":用于连接字符串。
示例:这个命令将每行的第一个字段 $1和第二个字段 $2连接起来,形成完整的姓名,并打印出来。
awk '{ fullName = $1 " " $2; print "Full Name: " fullName }' data.txt三元条件操作符:
? ::用于条件赋值。
示例:这个命令根据第三个字段的值是否大于等于 90 来确定考试状态。如果条件成立,将 "Pass" 赋给变量 status,否则赋给 "Fail",然后打印学生的姓名和状态。
awk '{ status = ($3 >= 90) ? "Pass" : "Fail"; print $1, status }' data.txt其他应用
AWK不仅支持基本的文本处理,还可以进行其他的一些数据操作,如计算、条件语句、循环等。以下是一些应用的示例:
awk命令的引用shell变量
在 AWK 命令中引用 shell 变量可以通过 -v 选项来实现。这允许您将 shell 变量传递给 AWK 脚本,并在脚本内部使用。
下面是一个示例,演示了如何引用 shell 变量:
# 在 shell 中定义一个变量
name="John"
# 使用 AWK 命令引用 shell 变量
awk -v new_name="$name" '{ print new_name }' file.txt在这个示例中,首先在 shell 中定义了一个名为 name 的变量,并将其值设置为 "John"。然后,通过 -v 选项将 shell 变量 name 传递给了 AWK 脚本 ($ 符号用于引用 shell 变量,获取变量的值),并将其存储在 AWK 变量 name 中。在 AWK 脚本内部,我们使用 new_name 变量来引用 shell 变量的值,然后在 AWK 脚本内部使用 new_name 变量来打印相应行的值。
这样,您可以将 shell 变量的值传递给 AWK 脚本,以在 AWK 脚本中使用它们,实现更灵活的文本处理和数据操作。
补充
需注意区分以下两个命令的区别:
awk -v name=John '{ print name }' file.txt和
name="John" # 定义shell变量name
awk -v new_name="$name" '{print new_name}' file.txt这两个命令中,主要区别在于name=John和new_name="$name"这两行的定义和传递方式。
第一个命令在AWK命令行中直接定义了一个AWK变量name,并将其值设置为"John"。然后,在AWK脚本内部,直接使用name变量,不需要双引号。
第二个命令首先在shell中定义了一个shell变量name,并将其值设置为"John"。然后,使用-v选项将shell变量name的值传递给了AWK脚本,并将其存储在AWK变量new_name中。
关于双引号的问题:
new_name="$name" 中的双引号用于将shell变量$name的值传递给new_name,以确保如果name包含空格或特殊字符时,值仍然保持完整。在AWK脚本内,如果直接使用name而不是"$name",如果name包含空格或特殊字符,可能会导致意外的结果。所以,使用双引号是一种良好的做法,以确保变量值的完整性。
条件语句:
awk '{ if ($2 > 50) print $1, "Pass"; else print $1, "Fail" }' scores.txt这将根据第二个字段的值决定学生是否通过。
scores.txt文件内容:

循环:
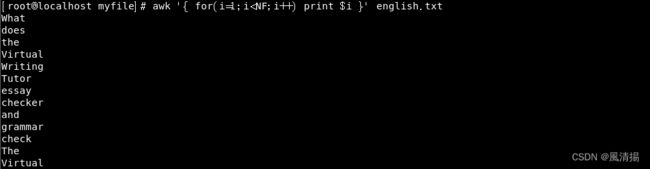
awk '{ for (i=1; i<=NF; i++) print $i }' english.txt这将遍历每一行的字段并打印它们。
总结
AWK命令是Linux中一个功能强大的文本处理工具,它可以处理文本文件的各种任务,包括搜索、提取、转换和报告生成。通过了解基本用法、字段和分隔符、内置变量以及高级功能,您可以更高效地处理文本数据。无论您是在日常系统管理中还是在数据分析中,AWK都是一个有用的工具,值得掌握。希望本文能够帮助您更深入地了解AWK命令并提高您的文本处理技能。