【BLIP/BLIP2/InstructBLIP】一篇文章快速了解BLIP系列(附代码讲解说明)
文章目录
- BLIP系列
-
- 1. BLIP
-
- 1.1 动机
- 1.2 整体架构
- 1.3 损失函数
- 1.4 Captioning and Filtering(CapFilt)
-
- 1.4.1 Why?
- 1.4.2 方法
- 2. BLIP2
-
- 2.1 Q-Former的设计
- 2.2 实现功能
-
- 2.2.1 图像文本检索(Image-Text Retrieval)
- 2.2.2 图像字幕(Image Captioning)
- 2.2.3 视觉问答(VQA)
- 2.2.4 指示的零样本图像到文本生成 (Instructed Zero-shot Image-to-Text Generation)
- 3. InstructBLIP
-
- 3.1 Dataset
- 3.2 亮点
- 3.3 Others
BLIP系列
1. BLIP
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
1.1 动机
- 从模型角度来看,大多数方法要么采用基于编码器的模型,要么采用编码器-解码器模型。编码器的模型不太容易直接迁移到文本生成的任务中,如图像标题(image captioning)等;编码器——解码器模型还没有被成功用于图像-文本检索任务。
- 从数据角度来看,大多数sota的方法,如CLIP都是对从网上收集的图像——文本对(image-text pair)进行预训练。尽管可以通过扩大数据集的规模来获得性能上的提高,但研究结果显示,有噪声的网络文本对于视觉语言学习来说只能得到次优的结果。
1.2 整体架构

为了预训练一个具有理解和生成能力的统一模型,论文提出了多模态混合编码器-解码器(Multimodal mixture of Encoder-Decoder,MED),通过一个“模型”处理多个子任务。
- 单模态编码器(Unimodal encoder),对图像和文本分别进行编码。文本编码器(text encoder)与BERT相同,在文本输入的开头附加一个[CLS]标记,以总结句子。图像编码器直接使用ViT。
- 以图像为基础的文本编码器(Image-grounded text encoder),通过在自注意力(SA)层和前馈网络(FFN)之间为文本编码器的每个Transformer块插入一个额外的交叉注意力(CA)层来注入视觉信息。一个特定任务的[Encode]标记被附加到文本上,[Encode]的输出embedding被用作图像-文本对的多模态表示。
- 以图像为基础的文本解码器(Image-grounded text decoder),用因果自注意力层(causal self-attention layer)替代编码器中的双向自注意力层。用[Decode]标记来表示一个序列的开始。
1.3 损失函数
- Image-Text Contrastive Loss (ITC) :集成 ALBEF 中的 ITC损失。通过鼓励正面图像文本对具有相似的表示,负面图像文本相反,对齐视觉变换器和文本变换器的特征空间
- 图像-文本匹配损失(Image-Text Matching Loss, ITM)激活以图像为基础的文本编码器。它的目的是学习图像-文本的多模态表示以捕捉视觉和语言之间的细粒度对齐。ITM是一个二元分类任务,模型根据多模态特征使用一个ITM头(一个线性层)来预测一个图像-文本对是positiv(匹配的)还是negative(不匹配的)。输入数据的pair对为正例,根据任务1的相似度采用多项式采样补充每个text/image的最佳负例增强训练。
- 语言建模损失(Language Modeling Loss, LM)激活了以图像为基础的文本解码器,其目的是生成给定图像的文本描述。它优化了交叉熵损失,训练模型以自回归的方式最大化文本的概率。
1.4 Captioning and Filtering(CapFilt)
1.4.1 Why?
- 有图像——文本对(Ih,Th)类似 COCO 的标注数据集较少
- CLIP中使用的网络收集的图片文本对通常不能准确地描述图像的视觉内容,这使得它们成为一个嘈杂的信号,对于学习视觉语言对齐来说是次优的。
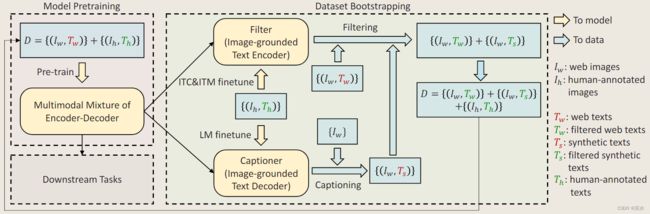
1.4.2 方法
- Captioner和Filter都是从同一个预训练的MED模型初始化的,在COCO数据集上单独进行微调。
- Captioner以LM为目标进行微调,对给定的图像进行文本解码生成caption。
- Filter以ITC和ITM的目标进行微调,以学习文本是否与图像匹配,该Filter去除原始网络文本和合成文本中的噪音文本,如果ITM头预测一个文本与图像不匹配,则该文本被认为是噪音。
- 过滤后的图像——文本对与人类注释的对相结合,形成一个新的数据集,用于预训练新的模型
2. BLIP2
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
BLIP2大概由这么几个部分组成,图像(Image)输入了图像编码器(Image Encoder),得到的结果与文本(Text)在Q-Former(BERT初始化)里进行融合,最后送入LLM模型。
2.1 Q-Former的设计

为了融合特征,引入了Learned Query。可以看到这些Query通过Cross-Attention与图像的特征交互,通过Self-Attention与文本的特征交互。这样做的好处有两个:
- 这些Query是基于两种模态信息得到的;
- 无论多大的视觉Backbone,最后都是Query长度的特征输出,大大降低了计算量。
比如在实际实验中,ViT-L/14的模型的输出的特征是257x1024的大小,最后也是32x768的Query特征。
Q-Former和BLIP-2第一阶段视觉语言表征学习目标的模型架构。共同优化了三个目标,这三个目标强制执行查询(一组可学习token),以提取与文本最相关的视觉表示。(右)控制查询文本交互的每个目标的自注意掩码策略。

为什么不让LLM认识Query,而让Query变成LLM认识呢?
(1)LLM模型的训练代价有点大;
(2)从 Prompt Learning 的观点来看,目前多模态的数据量不足以保证LLM训练的更好,反而可能会让其丧失泛化性。如果不能让模型适应任务,那就让任务来适应模型。
2.2 实现功能
2.2.1 图像文本检索(Image-Text Retrieval)
由于图像文本检索不涉及语言生成,直接对第一阶段的预训练模型进行微调,不使用LLM。
具体而言,使用与预训练相同的目标(即ITC、ITM和ITG)在COCO上与Q-Former一起微调图像编码器。ITC和ITM损失对于图像文本检索至关重要,因为它们直接学习图像文本相似性。
2.2.2 图像字幕(Image Captioning)
- 为图像字幕任务微调BLIP-2模型,该任务要求模型为图像的视觉内容生成文本描述。
- 使用提示“a photo of”作为LLM的初始输入,并在语言建模丢失的情况下训练模型生成标题。
- 在微调过程中保持LLM冻结,并与图像编码器一起更新Q-Former的参数。
from PIL import Image
import requests
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import torch
import os
import json
from tqdm import tqdm
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-6.7b-coco")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-6.7b-coco", torch_dtype=torch.float16
)
model.to(device)
root_path = "/data_1/ldw_models/BLIP/images"
captions={}
dir_or_files = os.listdir(root_path)
dir_or_files = [x for x in dir_or_files if x not in [".ipynb_checkpoints", ".DS_Store"] and ('.png' in x or '.jpg' in x)]
dir_or_files = sorted(dir_or_files)
for dir_file in tqdm(dir_or_files):
file_name=dir_file.split('.')[0]
dir_file_path = os.path.join(root_path,dir_file)
raw_image = Image.open(dir_file_path)
inputs = processor(images=raw_image, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
captions[file_name]= [generated_text]
json_str = json.dumps(captions, indent=4)
with open('/data_1/ldw_models/BLIP/images/prompts.json', 'w') as f:
lines = json_str.split('\n')
for line in lines:
f.write(line)
f.write('\n')
2.2.3 视觉问答(VQA)
- 给定带注释的VQA数据,微调了Q-Former和图像编码器的参数,同时保持LLM冻结。
- 对开放式答案生成损失进行了微调,其中LLM接收Q-Former的输出和问题作为输入,并被要求生成答案。
- 为了提取与问题更相关的图像特征,在问题上附加了Q-Former条件。具体地说,问题标记被作为输入提供给Q-Former,并通过自注意层与查询交互,这可以引导Q-Former的交叉注意层关注信息更丰富的图像区域。
训练的参数和IC任务一致,主要是Q-Former和ViT。不同的是,Q-Former和LLM都有Question作为文本输入。Q-Former的文本输入,保证了Query提取到的特征更加的精炼。
2.2.4 指示的零样本图像到文本生成 (Instructed Zero-shot Image-to-Text Generation)
使用BLIP-2模型w/ViT-g和FlanT5XXL的指示零样本图像到文本生成的精选示例,其中显示了广泛的功能,包括视觉对话、视觉知识推理、视觉共感推理、故事讲述、个性化图像到文本的生成等。

from PIL import Image
import requests
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)
model.to("cuda:1") # doctest: +IGNORE_RESULT
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "Question: how many cats are there? Answer:"
inputs = processor(images=image, text=prompt, return_tensors="pt").to(device, torch.float16)
inputs['input_ids'] = inputs['input_ids'].to('cuda:1')
inputs['attention_mask'] = inputs['attention_mask'].to('cuda:1')
inputs['pixel_values'] = inputs['pixel_values'].to('cuda:1')
print(inputs)
generated_ids = model.generate(**inputs)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
# two
3. InstructBLIP
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
3.1 Dataset
为了确保指令微调数据的多样性,作者收集了来自11种不同任务的26个数据集,并将它们转换为指令调优格式。
3.2 亮点
instruction不仅会指导LLM生成文本,同时也会指导image encoder提取不同的视觉特征。这样的好处在于对于同一张图片,根据不同的instruction,我们可以得到基于instruction偏好更强的视觉特征,同时对于两个不一样的图片,基于instruction内嵌的通用知识,可以使得模型有更好的知识迁移效果。
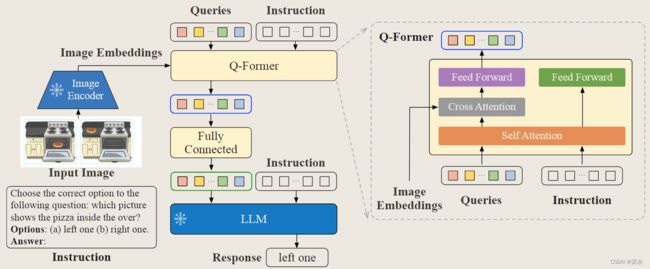
模型结构基本与BLIP2一致,Q-Former和LLM的输入多了Instruction。
3.3 Others
其他与BLIP2基本一样。