人工智能的学习算法
1956年,几个计算机科学家相聚在达特茅斯会议,提出了 “人工智能” 的概念,梦想着用当时刚刚出现的计算机来构造复杂的、拥有与人类智慧同样本质特性的机器。其后,人工智能就一直萦绕于人们的脑海之中,并在科研实验室中慢慢孵化。之后的几十年,人工智能一直在两极反转,或被称作人类文明耀眼未来的预言,或被当成技术疯子的狂想扔到垃圾堆里。直到 2012 年之前,这两种声音还在同时存在。
2012 年以后,得益于数据量的上涨、运算力的提升和深度学习的出现,人工智能开始大爆发,研究领域也在不断扩大,下图展示了人工智能研究的各个分支,包括计划调度、专家系统、多智能体系统、进化计算、模糊逻辑、机器学习、知识表示、计算机视觉、自然语言处理、推荐系统、机器感知等等1。
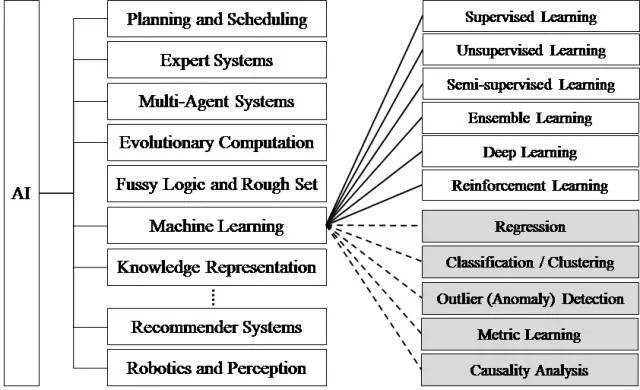
人工智能根据形态可以分为弱人工智能和强人工智能:弱人工智能通过训练让机器具备观察和感知的能力,可以做到一定程度的理解和推理;而强人工智能通过训练让机器获得自适应能力,解决一些之前没有遇到过的问题。例如科幻电影里的人工智能多半都是在描绘强人工智能,而这部分在目前的现实世界里难以真正实现;目前的科研工作主要集中在弱人工智能这部分,并且已经取得了一系列的重大突破。
人工智能领域涉及到许多学习算法,我们经常也会看到机器学习、深度学习、迁移学习、强化学习等概念,这些算法用于使计算机系统能够从数据中学习并做出决策。本文将介绍一些常见的人工智能学习算法。

目录
- 一. 传统机器学习
-
- 1. 监督学习
- 2. 无监督学习
- 3. 半监督学习
- 二. 深度学习
- 三. 强化学习
- 四. 迁移学习
- 五. 集成学习
一. 传统机器学习
弱人工智能是如何实现的,“智能” 又从何而来呢?这主要归功于一种实现人工智能的方法 —— 机器学习。机器学习的提出可以追溯到 Arthur Samuel 在 1959 年的定义:“机器学习:让计算机无需显式编程也能学习的研究领域”。Samuel 的定义很好,但可能有点太模糊。1998 年,另一位著名的机器学习研究者 Tom Mitchell 提出了一个更精确的定义:“正确提出的学习问题:如果计算机程序对于任务 T 的性能度量 P 通过经验 E 得到了提高,则认为此程序对经验 E 进行了学习”。通俗来说,机器学习就是让计算机从训练数据中学习,以便对新的、未见过的数据做出尽可能好的预测。
传统机器学习算法根据任务可以分为 分类、回归、聚类、降维、异常检测、推荐系统等。根据算法可以分为 监督学习、半监督学习、无监督学习 等,其区别在于训练数据的标签情况。
1. 监督学习
监督学习(Supervised Learning)是一种通过从 标记好的训练数据 中学习来进行预测或分类的方法,包括线性回归、逻辑回归、决策树、支持向量机、K - 最近邻算法等算法:
- 线性回归(Linear Regression)是一种解决回归问题的常见算法,用于预测连续数值输出。线性回归通过拟合一条最佳拟合直线来最小化预测值与实际值之间的误差,从而建立了输入特征与输出之间的线性关系。
- 逻辑回归(Logistic Regression)是一种解决分类问题的常见算法,用于预测样本的类别。逻辑回归通过将输入特征与 Sigmoid函数结合,将输入映射到 0 和 1 之间的概率,然后根据阈值进行分类。
- 决策树(Decision Trees)既可以解决分类问题,又可以解决回归问题。决策树根据输入特征逐步分裂数据,每次选择一个最能有效分割数据的特征,以创建一个树状结构的决策规则,从而将数据分成不同的类别或值。
- 支持向量机(Support Vector Machines, SVM)既可以解决分类问题,又可以解决回归问题。支持向量机试图找到能够最大化类别之间边界的超平面,这样的最佳超平面能够将不同类别或值分隔开,从而最小化分类错误。
- K - 最近邻算法(K-Nearest Neighbors, KNN)既可以解决分类问题,又可以解决回归问题。K - 最近邻算法根据数据点之间的距离来确定最近的 K 个邻居,并采用多数投票(对于分类问题)或平均值(对于回归问题)来决定待预测数据点的类别或值。
2. 无监督学习
无监督学习(Unsupervised Learning)是一种从 未标记的数据 中学习模式和结构的方法,主要用于解决聚类和降维等任务,包括 K 均值、层次聚类、高斯混合模型、主成分分析、自组织映射等算法:
- K 均值(K-Means)是一种解决聚类问题的常见算法,用于将数据点分成 K 个不同的簇,每个簇包含具有相似特征的数据点。K 均值算法的工作方式是随机选择 K 个初始聚类中心,然后迭代地将数据点分配到最近的中心,然后重新计算每个簇的中心,直到收敛为止。
- 层次聚类(Hierarchical Clustering)是自底向上或自顶向下构建聚类层次结构的方法。自底向上方法从每个数据点作为单独的簇开始,然后逐渐将相似的簇合并在一起,形成更大的簇;自顶向下方法从所有数据点作为一个簇开始,然后逐渐将其分成更小的簇,形成聚类层次结构。
- 高斯混合模型(Gaussian Mixture Models, GMM)既可以进行聚类,又可以建模生成新的数据点。高斯混合模型假设数据由多个高斯分布组成,每个高斯分布表示一个簇,使用最大似然估计来估计每个高斯分布的参数,并通过这些参数对数据进行建模。
- 主成分分析(Principal Component Analysis, PCA)是一种降维技术,用于减少数据的维度,同时保留尽可能多的信息。主成分分析通过找到数据中的主成分(这些主成分是数据中方差最大的方向,是特征的线性组合),来实现降维。
- 自组织映射(Self-Organizing Maps, SOM)是一种降维技术,用于将高维数据映射到低维空间,并保持数据之间的拓扑结构。自组织映射构建一个由神经元组成的网格,然后通过训练来调整神经元之间的连接权重,以最佳方式表示输入数据。
3. 半监督学习
半监督学习(Semi-Supervised Learning)结合了监督学习和无监督学习,使用 少量标记数据和大量未标记数据 进行训练,包括自训练、标签传播、半监督聚类、生成对抗网络、半监督支持向量机等算法。半监督学习利用未标记数据的信息来提高模型性能,尤其在标记数据稀缺或昂贵的情况下特别有用。
- 自训练(Self-Training)是一种简单的半监督学习方法,它使用已训练的监督模型为未标记数据分配伪标签,然后将这些伪标签数据与标记数据一起用于重新训练模型。
- 标签传播(Label Propagation)是一种图算法,它使用已知标签的数据点来传播标签信息到未知标签的数据点,从而扩展标签信息。该算法通常构建一个图,其中节点表示数据点,边表示相似性或关系,然后通过迭代传播标签。
- 半监督聚类(Semi-Supervised Clustering)将未标记数据与标记数据一起聚类,以便更好地捕捉数据分布的结构。其中一种常见的方法是 “Constrained Clustering”,它利用人工提供的约束信息(如数据点属于同一类别或不属于同一类别)来指导聚类过程。
- 生成对抗网络(Generative Adversarial Networks, GANs)是一种用于生成和改进数据的生成式算法。生成对抗网络可以使用未标记数据来改进生成器的性能,使其生成更真实的数据。
- 半监督支持向量机(Semi-Supervised Support Vector Machines)扩展了传统的 SVM,允许在模型训练中使用未标记数据。它尝试将未标记数据放置在决策边界附近,以提高分类性能。
二. 深度学习
深度学习(Deep Learning, DL)是机器学习中一种基于神经网络模型的算法,其核心思想是通过模拟人脑神经网络的结构和工作原理来训练计算机模型,以实现对数据的高级抽象和特征学习。深度学习模型通常由 多层神经网络 组成,这些网络层之间的参数通过大量数据进行自动学习和调整,以执行各种任务。深度学习的好处是可以使用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。
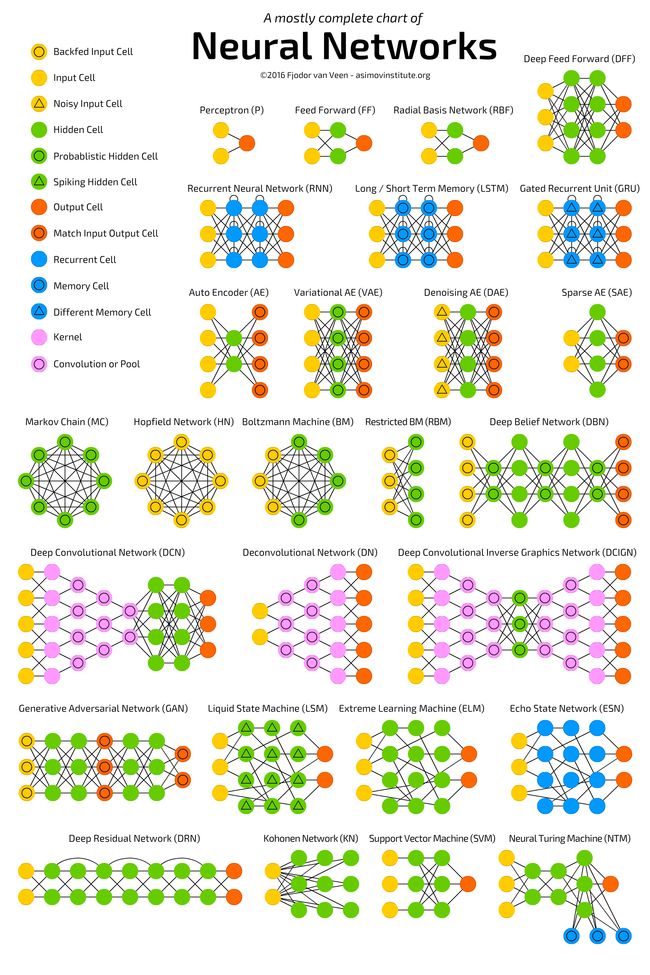
深度学习的模型有很多,目前开发者最常用的深度学习模型与架构包括卷积神经网络、深度置信网络、受限玻尔兹曼机、递归神经网络、递归张量神经网络、自动编码器、生成对抗网络等等,更多的模型可以参考下图:
三. 强化学习
强化学习(Reinforcement Learning, RL)是一种机器学习方法,旨在让智能体通过与环境的互动学习如何在特定任务中做出决策,以最大化累积的奖励或目标。在强化学习中,智能体是一个决策制定者,它通过观察环境的状态,采取行动,获得奖励,并在不断的试验中优化它的行为策略。

强化学习涵盖了多种不同的方法和算法,常见的方法包括 Q - 学习、深度 Q 网络、策略梯度方法、Actor - Critic 方法、模仿学习等:
- Q - 学习(Q-learning)是一种基于值函数的强化学习算法2,用于 离散 状态和动作空间的问题。它通过建立一个 Q 值表格,其中每个条目表示在特定状态下采取特定动作的预期回报,然后通过不断更新 Q 值来学习最佳策略。
- 深度 Q 网络(Deep Q-Networks, DQN)是 Q-learning 的深度学习扩展,适用于具有 连续 状态和动作空间的问题。它使用深度神经网络来估计 Q 值函数,并使用经验回放和目标网络来稳定训练过程。
- 策略梯度方法通过直接学习策略函数,而不是估计值函数,来解决强化学习问题。常见的策略梯度算法包括 REINFORCE、TRPO(Trust Region Policy Optimization)、PPO(Proximal Policy Optimization)等。
- Actor - Critic 方法结合了值函数估计(Critic)和策略改进(Actor)两个部分:Critic 负责估计状态值或 Q 值,Actor 则根据这些估计来改进策略。A3C(Asynchronous Advantage Actor-Critic)和 A2C(Advantage Actor-Critic)是常见的 Actor-Critic 算法。
- 模仿学习是一种通过观察专家示范来学习策略的方法,而不是通过奖励信号来训练3。常见的模仿学习算法包括行为克隆和逆强化学习。
四. 迁移学习
迁移学习(Transfer Learning)是一种机器学习方法,它利用在一个任务上学到的知识来改善在另一个相关任务上的性能。传统的机器学习方法通常要求训练数据和测试数据的分布相似,但在现实世界中,这种情况并不经常发生。迁移学习的目标是通过利用一个任务上积累的经验知识来提高另一个任务的性能,尤其是在目标任务的数据相对较少或难以获得时非常有用,这样可以避免大多数网络那样需要从零学习(Starting From Scratch)。
“在迁移学习中,我们首先在基础数据集和任务上训练一个基础网络,然后将学习到的特征重新调整或者迁移到另一个目标网络上,用来训练目标任务的数据集。如果这些特征是容易泛化的,且同时适用于基本任务和目标任务,而不只是特定于基本任务,那迁移学习就能有效进行。” 因此,迁移学习的核心思想是将从源任务学到的知识传输到目标任务中,可以通过共享模型的权重、特征表示或其他中间层来实现。在深度学习中,通常采用预训练模型(如 BERT、ResNet 等)来进行知识传输4。

举个例子,使用图像数据作为输入的预测模型问题中进行迁移学习是很常见的。 对于这些类型的问题,通常会使用预先训练好的深度学习模型来处理大型的和具有挑战性的图像分类任务。例如使用谷歌的 Inception 模型作为预训练的元模型,然后再使用少量目标任务的样本进行微调实现 ImageNet 1000 级照片分类。
五. 集成学习
集成学习(Ensemble Learning)是一种机器学习方法,通过将多个基本模型(也称为 弱学习器 或 基学习器)组合在一起,以提高整体性能和泛化能力。集成学习的核心思想是将多个弱学习器的预测结果进行组合,从而产生一个更强大的模型,以降低过拟合风险并提高预测的准确性。
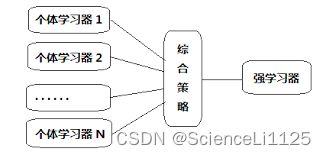
集成学习算法包括投票策略、Bagging、Boosting、随机森林等:
- 投票(Voting)策略是一种简单的集成方法,它通过让多个弱学习器投票来确定最终的预测。有硬投票(Majority Voting)和软投票(Soft Voting)两种方式,软投票考虑了每个弱学习器的置信度,硬投票只考虑得票最多的结果。
- Bagging(Bootstrap Aggregating)通过随机有放回地从训练数据集中抽取多个子样本,然后使用这些子样本来训练多个弱学习器。最后,通过对弱学习器的预测结果进行投票或平均来获得最终的预测。
- Boosting 是一种迭代的集成方法,它通过调整样本权重来关注被前一轮弱学习器分类错误的样本,从而逐渐改善模型性能。常见的 Boosting 算法包括 AdaBoost、Gradient Boosting 和 XGBoost等。
- 随机森林(Random Forests)是一种基于 Bagging 的集成方法,它使用多个决策树作为弱学习器。每个决策树都在不同的子样本和特征子集上训练,最后通过投票或平均来进行预测。
集成学习的优势在于它可以降低模型的方差,提高模型的鲁棒性,减少过拟合的风险,并在许多情况下提高了预测性能。不同的集成方法适用于不同的问题和数据集,选择合适的集成策略通常需要根据具体情况进行调整和实验。
机器学习、深度学习、强化学习、迁移学习和人工智能的联系和区别? ↩︎
Q学习(Q-learning)简单理解 ↩︎
模仿学习(Imitation Learning)概述 ↩︎
迁移学习(Transfer) ↩︎