测试面试知识总结(自用)
这里写目录标题
- 面试谈吐
- 技术栈
-
- 高级python
- 接口自动化,测试框架
- 网络知识
- 数据库相关MYSQL
- 性能测试
- 中间件
- linux
- 项目相关
面试谈吐
1、话术:
如果碰到不是很清楚的,或者不会的面试题目时,可以适当的进行话术解决:例如:
实在不好意思,这个问题我之前没碰到过,不过我试着结合自己的经验试着回答一下这个问题,如果回答的不准确的话,请多多指教
这样会给人友好,比你直接说不会,要好得多。
2、深刻的第一印象
3、语言亲和力
4、语言表达能力
技术栈
高级python
下面展示一些 内联代码片。
import copy
from time import time
a=b=c=0
a,b,c=1,2,3
a,b=1,2
a,b=a+b,b
a+=1
a-=1
a*=2
a/=2
a**=2
list_test=[1,2,3,4,5]
list_len=len(list_test)
num3=list_test[2]
num5=list_test[-1]
print('无间隔取字列表'+str(list_test[0:]))
print('有间隔'+str(list_test[0:5:2]))
print('取出最后两个'+str(list_test[-2:]))
print('倒叙'+str(list_test[-1::-1]))
list_test[0:2]=[9,8]
print('替换前两个值'+str(list_test))
list_test[:0]=[0,0]
print('在列表开头插两个数据',str(list_test))
str_test="I am a chinese"
str_test1="ff#sfdf#dfdf#"
str_test2=" go go go yes ! "
print(str_test.split())
print(str_test1.split('#'))
print(str_test2.strip())
print(str_test2.strip(' ! '))
list_test3=['1','wew','643']
print('join连接','-'.join(list_test3))
print('大小转换',str_test.upper())
print(str_test.lower())
#推导式练习
list_test=[i for i in range(5)]
print(list_test)
# list_test=(i for i in range(4) for j in range(i*4))
# print(list_test)
# enumerate 函数
# 基本介绍:enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
# enumerate(sequence, start=0)
# sequence -- 一个序列、迭代器或其他支持迭代对象。
# start -- 下标起始位置,默认为0。
for i in enumerate(list_test):
print(i)
for i,num in enumerate(list_test):
print(str(i)+":"+str(num))
str="121313"
print("dshs{0}".format(str))
dict_test={"name":"sdsd","age":11}
print("{name}的 age 是{age}".format(**dict_test))
##文件操作
# open(name, mode, buffering)
# nam为必填参数,其他选填
# with open(r'I:/dsds.txt') as f:
# content=f.read()
# print (content)
# with open(r'I:/1.txt',mode='r+') as f:
# # r+ w+ wb+
# content=f.read()
# print(content)
#全局变量
g_test=10
def sum():
global g_test #表明下方使用的变量是全局变量
g_test=4# 改变了全局变量的值
print(g_test-1)
sum()
print(g_test)
dict_test={"name":"dsd","age":"11"}
for k,v in dict_test.items():
print(k+":"+v)
for k in dict_test.keys():
print(k)
for v in dict_test.values():
print(v)
set_a={1,2,3,4}
set_b={3,4,5,6}
print('交集',set_a & set_b)
print('并集',set_a|set_b)
print('差集',set_b-set_a)
# startswith 函数
# startswith函数用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。
# 参数介绍
# startswith(str, beg,end)
str_test='test wew'
print(str_test.startswith(str_test))
# 在Python中,一边循环一边计算的机制,称为生成器(Generator)。
# 也可以这样理解,生成器就是一个可以自动迭代的对象,类似于for循环,又比for循环灵活。
def my_decorator(f):
def wrapper():
print("sdsd")
f()
print("2323")
return wrapper
def hello():
print(1)
new_hello = my_decorator(hello)
new_hello()
@my_decorator
def hello():
print("Hi,简说Python!")
hello()
def diagnostics(f):
def wrapper(*args, **kwargs):
""" 这个包装函数带参数,
*args处理多个参数,
**kwargs可以处理具名参数 """
print("Executed", f.__name__, "at", time())
value = f(*args, **kwargs)
print("Exited", f.__name__, "at", time())
print("Arguments:",args)
print("Value returned:", value, "\n")
return value
return wrapper
@diagnostics
def print_nums():
""" 不带参数,没有返回值 """
for i in range(4):
print(i, end="\t")
@diagnostics
def add_nums(a, b):
""" 带参数,有返回值 """
return a+b
# 调用经过装饰器装饰过的函数
print_nums()
print("-"*50)
add_nums(2, 3)
print("-"*50)
# sort和sorted方法的区别
# 1. 使用方法的区别
# 2.sort会改变列表本身,sorted不会改变列表本身
dict=[
('john',"A",10),
('john1',"A",15),
('john2',"A",11)
]
newlisr=sorted(dict,key=lambda a: a[2])
print(newlisr)
# return [myear for myear in range(startyear,endyear) if myear%4==0 and myear%400!=0]
# 一维的list去重可以用set(list),但是二维的list转set就会报错 unhashable type: ‘list’
# 原因是set传进来的是不可哈希的变量
plist=[1,2,2,2,3,4]
set(plist)
plist=[[1,1,2,3],[1,1,2,3],[2,3,4,4]]
# set(plist) #报错
# list 不使用 hash 进行元素的索引,自然它对存储的元素有可哈希的要求;而 set 使用 hash 值进行索引
# Python中那么哪些是可哈希元素?哪些是不可哈希元素?
# 可哈希的元素有:int、float、str、tuple
# 不可哈希的元素有:list、set、dict (这三个是可变的)
dic = set([tuple(t) for t in plist])
print(dic)
plist=[(1,1,2),(1,1,2)]
print(set(plist))
# 在集合中,创建空集合(set)必须使用函数set()。
a=set()
a.add(9)
a.add(10)
# 报错,因为此时默认生成的是字典类型,字典类型不存在add方法
# a={}
# a.add(9)
# a.pop()#随机产生一个数据 pop()方法用于从set中随机取一个元素。记住,是随机的~
# b = a.clear()
a.remove(9)
# 2、字典的key必须是可哈希的;
a=1
c=copy.copy(a)
a=3
if a==c:
print("zhi")
if id(a)==id(c):
print("dizhi")
#浅拷贝的是共用地址
d=copy.deepcopy(a)
a=2
if a==d:
print("zhi")
if id(a)==id(d):
print("dizhi")
print(a)
print(d)
# 需要先将字符串转换成浮点型,才能转换成整型。
a="1.03"
# print(int(a))
# d=float(a)
# print(d)
def function(a,*args,**kwargs):
print(type(a))
print(type(args))
print(type(kwargs))
print(a)
print(args)
print(kwargs)
function(1,[1,2,3],{"q":1})
function(1,2,3,4,c=1,d=2,e=8)
function(1,(1,2,3),{"q":1})
function([1],1,1,1)
# 注意:函数定义时,二者同时存在,一定需要将*args放在**kwargs之前
#传值的话,**kwargs 必须放在最后边,否则也会报错
# *参数收集所有未匹配的位置参数组成一个tuple对象,局部变量args指向此tuple对象
# **参数收集所有未匹配的关键字参数组成一个dict对象,局部变量kwargs指向此dict对象
# 2、可变参数,必须定义在普通参数(也称位置参数、必选参数、选中参数等名称)以及默认值参数的后面!!!!
# ,这是因为可变参数会收集所有未匹配的参数,如果定义在前面,
# 那么普通参数与默认值参数就无法匹配到传入的参数(因为都收集到可变参数中了…………)
# 调用时可以使用解包方式:*a, **a
a={"1":1}
function(1,2,**a)
b=(1,2,3)
function(1,*b,**a)
def runtime(function):
def gettime(name,*args):
print("1111")
function(name,*args)
return gettime
@runtime
def run(name,*args):
print("run")
print(name)
print(*args)
run("1",1)
# 共同点:return和yield都用来返回值;在一次性地返回所有值场景中return和yield的作用是一样的。
# 不同点:如果要返回的数据是通过for等循环生成的迭代器类型数据(如列表、元组),return只能在循环外部一次性地返回,yeild则可以在循环内部逐个元素返回。下边我们举例说明这个不同点。
# 不同点:简单一句话就是说,return会阻断程序运行,而yiel不会
# 他们的主要区别是yiled要迭代到哪个元素那个元素才即时地生成,而return要用一个中间变量result_list保存返回值,当result_list的长度很长且每个组成元素内容很大时将会耗费比较大的内存,此时yield相对return才有优
def func1():
for i in range(1,5):
return i
def func2():
for i in range(1,5):
yield i
print(func1())
print(func2())
for i in func2():
print(i)
#列表推导式
list1=[1,2,3,4]
list2=[i*i for i in list1 if i >2]
print(list2)
#集合推导式,元祖推导式
list1={1,2,3,4}
list2={i*i for i in list1 if i >2}
print(list2)
#字典推导式
list1={"key1":"value1","key2":"value2"}
list2={value:key for key,value in list1.items() if key=="key1"}
print(list2)
print(sum([i for i in range(1,101)]))
#冒泡排序: 就是相邻的数进行比较
def bubble_sort(blist):
list_count =len(blist)
for i in range(0,list_count):
for j in range(i+1,list_count):
if blist[i]>blist[j]:
blist[i],blist[j]=blist[j],blist[i]
return blist
blist=bubble_sort([1,3,2,5,4,0])
print(blist)
#快排 列表中取出第一个元素作为标准,把比第一个元素小的都放在左侧,把第一个元素大的都放在右侧,然后在进行递归,递归完成即结束
def quick_sort(blist):
if blist==[]:
return []
base=blist[0]
left=quick_sort([m for m in blist[1:] if m<base])
right=quick_sort([ n for n in blist[1:] if n>=base])
return left+[base]+right
blist=quick_sort([])
print(blist)
# Python中的map函数应用于每一个可迭代的项,返回的是一个结果list。
# 如果有其他的可迭代参数传进来,map函数则会把每一个参数都以相应的处理函数进行迭代处理
#用函数实现过滤掉集合list1=['','hello',None,'python']中的空值和空格
list1=['','hello',None,'python']
print([i for i in list1 if i!='' and i is not None ])
new_lst_2 = list(filter(None,list1))
print(new_lst_2)
list1=[1,2,3,4,5]
print(sum([i for i in list1]))
class Student:
__name = "三毛"
name_cls = "思茅"
# print(Student.__name) #私有变量不可直接访问 报没有这个属性:将__name 变成了_student__name,控制私有变量变成了一个名字而已
print(dir(Student)) #
# # 私有变量的访问
print(Student._Student__name)
### 面向对象部分
class Student():
name="三毛"
def study(self): #实例方法,实例可以操作的方法,可以操作实例变量
new_name="222"
print("学习"+self.name)
@classmethod
def eat(cls): #类方法,可以操作类变量
print("hell"+cls.name)
@staticmethod #静态方法,脱离了类儿存在的,根本调用不了self和cls的 用于写一些工具
def run():
print("run")
def __kaishi(self): #私有方法
print("开始")
s=Student()
s.study()
Student.eat()
Student.run()
s._Student__kaishi()
接口自动化,测试框架
-
接口自动化如何做的?持续集成是怎么做的?
接口自动化落地难点
1、接口文档的管理(创建与维护):
高频次与开发进行沟通
2、多测试人员协同开发时的case维护:
存储在数据库,实现共享
代码放在git仓库
推进测试人员技术成长 -
接口测试中常用的库:
requests,urllib库等
数据解析:
requests的源码:
持续集成落地过程:提高我们的工作效率 -
web自动化落地难点
1、前端代码改动大频繁户不规范导致元素不好定位
2、自动化开始,测试人员编码规范及架构设计不统一
前端代码改动大频繁户不规范导致元素不好定位
- 滚动条定位
js=window.scroll() - 时间控件定位
document.getelementByid(‘train_date’).removeAttribute(‘readonly’)
driver.find_elemebt_by_id().clear()
dirver.find_element_by_id().send_keys() - 弹框处理
alert=driver.switch_to.alert alert.accept()
alert.dismiss()
alert.send_keys(“sdsd”) - 浏览器句柄切换
- 提高元素定位成功率
强制等待:time.sleep(2)
隐形等待:driver.implicityly_wait(5) 设置最长的等待时间,只有在页面完全加载完成才执行下一步,他对这个driver周期都起作用
显性等待:WebDriverWait(driver,15,0.5).until(EC.prenvce_of_elment_laocated(By.LINKL_TEXT,‘登陆’)) 最长超时时间是15s,每0.5s进行一个元素检测是否存在
自动化开始,测试人员编码规范及架构设计不统一
web自动化框架设计PO
文件夹层次:pages(每个页面封装成一个类,有一个基类BasePage)、testcase、setting.py
网络知识
- session和cookie的区别
- 如何保证数据传输过程中不丢失
- 请求头,响应头
- OSI网络7层
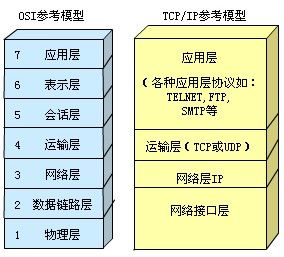
session和cookie的区别
1、cookie在客户端头信息中,session在服务端存储,文件、数据库等都可以
2、一般session的验证需要cookies带一个字段来,表示这个用户是哪一个session,所以用户禁用cookie时,session将失效
3、cookie是一小段文本,是key,value 进行存储
4、cookie的值是服务端生成,客户端保存
如何保证数据传输过程中不丢失
1、三次握手,建立连接
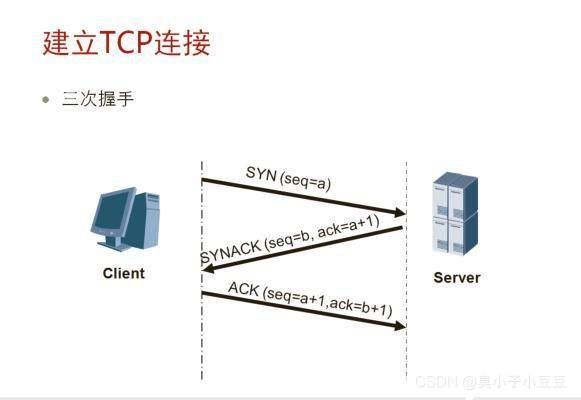
客户端给服务端请求,建立连接seq
服务端给客户端,回答可以,我知道了,
客户端给服务器在发送消息,那我开始发送消息了啊
2、四次挥手,传输数据
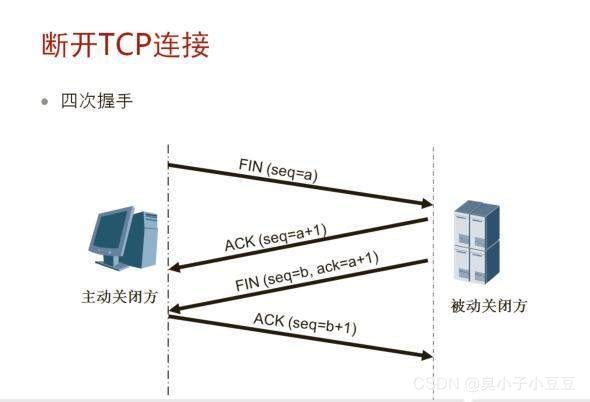
FIN,客户端告诉服务端,我传输完了
服务端告诉客户端,我接收到了
服务端告诉客户端,我给你发我的返回数据
客户端告诉服务端,我接收完了数据了
数据库相关MYSQL
- MYSqL中索引有什么用?
- 如何分析一条查询sql的效率?
- MYSQL常用存储引擎有什么?区别是什么?
什么是索引:
索引是数据表中一列或多列的值进行排序的一种结构,使用索引可以快速访问数据表中的特定信息
创建索引的目的就是加快索引表中数据的速度,也就是查询数据的速度。
1、索引的分类: 组合索引,主键索引,唯一索引,
2、索引是越多越好?
不是,索引过多的创建,会带来数据的写入的代价过高,也就是说减慢数据写入的速度。
MYISAM引擎:
数据存储有三个文件:table.frm 存储表的定义
table.MYD 存储表的数据
table.MYI 存储表的索引
inndoDB引擎:
存储文件:.frm 存储表的定义
.ibd 表的数据和索引
存储方式:共享表空间 一个表的数据可以横跨多个文件中,(推荐)
单独表空间 每一个表中数据也就是文件1的数据
索引创建过多,在MUISAM引擎会影响索引表的存储大小,,但是在inndoDB引擎的共享表空间,直接影响数据存储文件的大小更为明显
3、索引是如何工作的:
MYISAM引擎 如同看书一样,查看目录—找到内容
inndoDB引擎 如何逛超市,比如买水,先索引到饮料区,然后拿到水
inndoDB比MYISAM速度快,工作方式不一样
MySQL常用引擎的特点和区别
MYISAM引擎
1、在进行数据的备份,迁移,恢复的等操作时非常容易,只要对文件进行操作就行
2、他只支持表锁,不支持行锁
3、不支持事务安全,但每次读的操作时具有原子性的,所以不必担心脏读等情况
inndoDB引擎
1、支持事务,回滚,崩溃修复等,对数据安全性较高的业务场景都选择这个引擎
2、支持行锁,大大提高数据库并发操作能力
3、支持外键约束,保证数据的完整性(三范式设计???)
如何分析SQl效率(优化):
explain select * from peple where name=‘test’
分析select_type等字段
性能测试
- JVM ,什么是内存溢出? 为什么会内存溢出?
- jvM 的内存区域是如何划分的?
- jvm是如何进行垃圾回收的?
中间件
linux
如何动态查看文件中你关心得内容
tail -f sky.log| grep error
如何跨服务器拷贝你的文件?(搭建环境)
scp
超大文件在跨服务器拷贝过程中,经常断开,你如何解决?
rsync (断点续传)
文件查看常见命令有什么? 请讲述他们的区别?
tail 整个文件
more 几行几行查看
less
cat
如何去除文件中的重复行?
cat data.txt | sort |uniq 本文件并没有改变
cat data.txt |sort |uniq > data1.txt
如何监控命令?