Seaborn绘图库
1.Seaborn----绘制统计图形
之前已经学过Matplotlib画图库,但是其缺点是函数和参数太多,以至于使用的时候非常复杂。因此,基于Matplotlib库的Seaborn就出现了,使用它在画图时将会更加简便,图像也更加好看。但是要知道,seaborn只是对matplotlib的提高,并不能代替。
安装seaborn库,并在使用的时候import导入
pip3 install seaborn
import seaborn as sns
2.可视化数据的分布
当我们需要处理数据的时候,第一步肯定是先了解变量是如何分布的,是一维数组还是二维数组等等。对于单变量(一维数组),可以使用直方图或核密度曲线;对于双变量(二维数组),可以使用散点图、直方图、核密度估计图等。
核密度图类似概率密度曲线,曲线下的面积为1
3.Seaborn绘图
三种方式:
-
plt.style.use('seaborn') -
sns.set(context=‘notebook’, style=‘darkgrid’, palette=‘deep’, font_scale=1)style:风格,有五种默认风格**“darkgrid,whitegrid,dark,white,ticks”**sns.despine():移除边缘线context:绘图元素比例**“paper、notebook、talk、poster”**palette:分类画板“deep、muted、pastel、bright、dark、colorblind”
-
调用seaborn函数(对于复杂图)
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 第一种:
# plt.style.use('seaborn')
# 第二种:
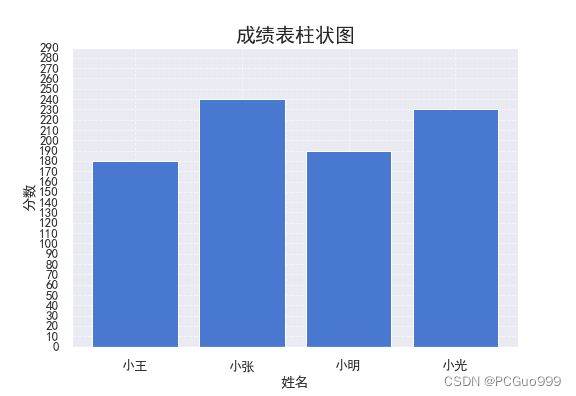
sns.set(context='notebook', style='darkgrid', palette='muted', font_scale=1.2)
# 注意,一定要把plt.style.use('seaborn')或sns.set()放在前两句的前面,否则会被覆盖!
# 设置显示中文字体
plt.rcParams['font.sans-serif'] = ["SimHei"]
# 设置正常显示符号
plt.rcParams["axes.unicode_minus"] = False
# 获取数据
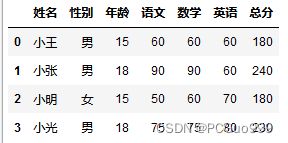
data=pd.read_csv('./data/Student_score.csv')
# 第三种
# sns.barplot(x="姓名", y="总分", data=data)
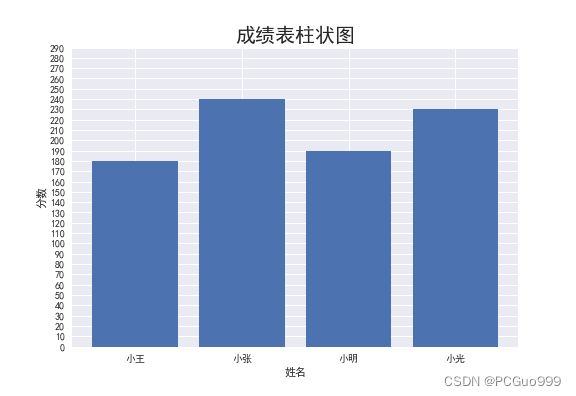
plt.bar(x="姓名", height="总分", data=data)
# 添加x,y刻度
plt.yticks(range(0,300,10))
# 添加描述信息
plt.xlabel("姓名")
plt.ylabel("分数")
plt.title("成绩表柱状图",fontsize=20)
# 保存图像
plt.savefig('./images/成绩柱状图_plt.style.use.png')
plt.show()
当使用sns.barplot(x=“姓名”, y=“总分”, data=data)时,不需要再设置x轴和y轴的描述信息,因为已经默认产生
plt.bar

(1)plt.style.use(‘seaborn’)
(2)sns.set()
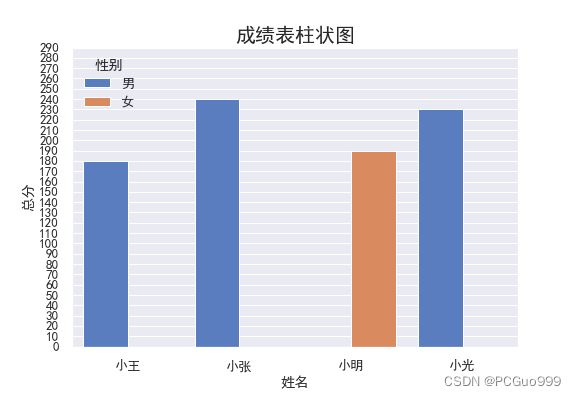
(3)seaborn函数
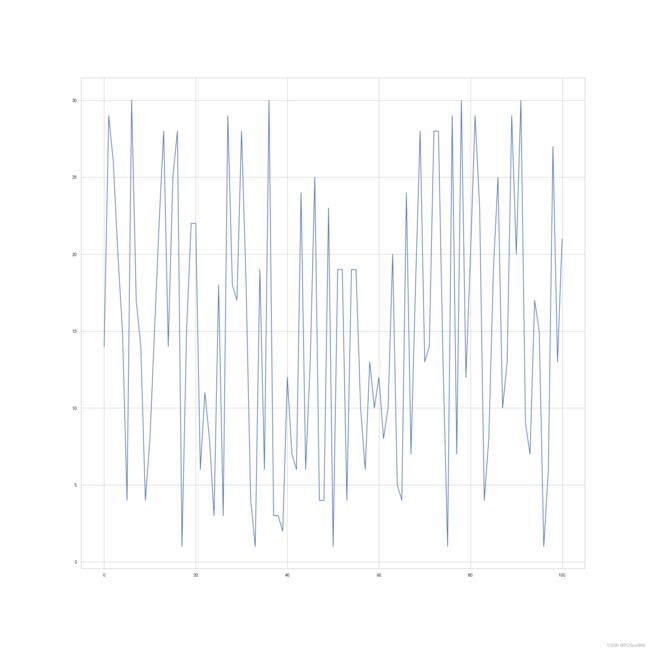
①折线图sns.lineplot(x,y)
sns.lineplot(x,y)
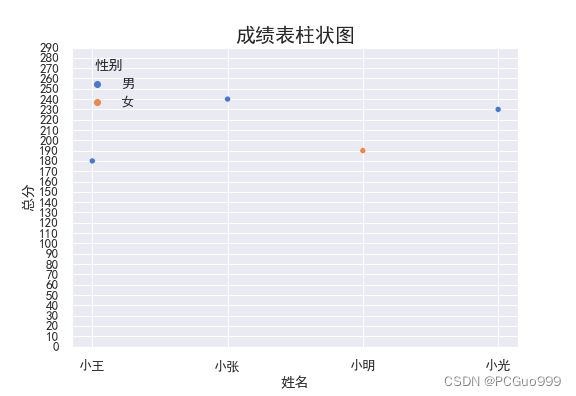
②散点图sns.scatterplot(x,y,data,hue,marker)
- data:数据
- hue:色调:分组变量,将产生不同颜色的点
- markers:标记,确定如何为对象的不同级别绘制标记“风格”的变量。设置为’ ’ True ’ '将使用默认标记
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 设置显示中文字体
plt.rcParams['font.sans-serif'] = ["SimHei"]
# 设置正常显示符号
plt.rcParams["axes.unicode_minus"] = False
# 获取数据
data=pd.read_csv('./data/Student_score.csv')
sns.scatterplot(x="姓名", y="总分",hue="性别", data=data)
# 添加x,y刻度
plt.yticks(range(0,300,10))
# 添加描述信息
plt.title("成绩表柱状图",fontsize=20)
# 保存图像
plt.savefig('./images/成绩柱状图_sns.scatterplot.png')
plt.show()
3.绘制单变量分布图sns.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None, color=None)
- a:表示要观察的数据,可以是 Series、一维数组或列表。
- bins:用于控制条形的数量。
- hist:接收布尔类型,表示是否绘制(标注)直方图。
- kde:接收布尔类型,表示是否绘制高斯核密度估计曲线。
- rug:接收布尔类型,表示是否在支持的轴方向上绘制rugplot。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
data= np.random.randn(100) # 生成随机数组
sns.distplot(a=data, bins=10, hist=True, kde=True, rug=True) # 绘制直方图
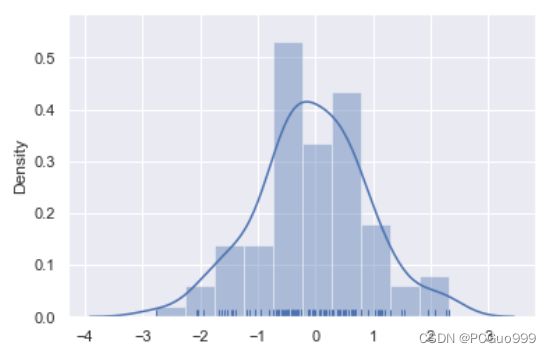
图像中x轴上小细线为核密度估计曲线
核密度估计是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,可以比较直观地看出数据样本本身的分布特征。
采用直方图可以比较直观地展现样本数据的分布情况,不过,直方图存在一些问题,它会因为条柱数量的不同导致直方图的效果有很大的差异。为了解决这个问题,可以绘制核密度估计曲线进行展现。
# 绘制核密度估计曲线,即不显示直方图
sns.distplot(a=data, bins=10, hist=False, kde=True, rug=True)
4.绘制双变量分布图sns.jointplot(x, y, data=None, kind='scatter', stat_func=None, color=None,ratio=5, space=0.2, dropna=True)
- kind:表示绘制图形的类型。
- stat_func:用于计算有关关系的统计量并标注图。
- color:表示绘图元素的颜色。
- size:用于设置图的大小(正方形)。
- ratio:表示中心图与侧边图的比例。该参数的值越大,则中心图的占比会越大。
- space:用于设置中心图与侧边图的间隔大小。
(1)散点图
import numpy as np
import pandas as pd
import seaborn as sns
# 创建DataFrame对象
data= pd.DataFrame({"x": np.random.randn(500),"y": np.random.randn(500)})
# 这样创建,会使得可以直接打印x、y轴
# 绘制散布图
sns.jointplot(x="x", y="y", data=data)

(2)二维直方图
二维直方图类似于“六边形”图,**从六边形颜色的深浅,可以观察到数据密集的程度,另外,图形的上方和右侧仍然给出了直方图。**适用于较大的数据集。
jointplot()函数时,传入参数kind="hex",就可以绘制二维直方图,具体示例代码如下。
sns.jointplot(x="x", y="y", data=data, kind="hex")
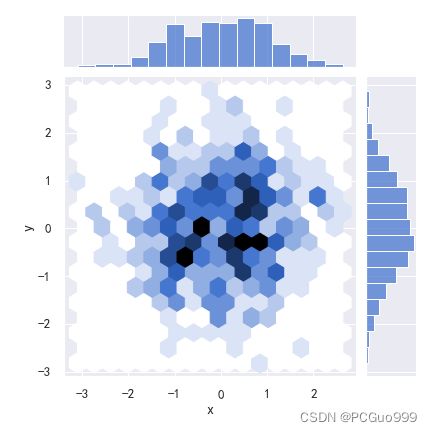
(3)核密度估计曲线
利用核密度估计同样可以查看二元分布,其用等高线图来表示。通过观等高线的颜色深浅,可以看出哪个范围的数值分布的最多,哪个范围的数值分布的最少.另外,在图形的上方和右侧给出了核密度曲线图。
jointplot()函数传入参数kind="kde",就可以绘制核密度估计曲线,具体示例代码如下。
通过
fill=True选择是否填充图像颜色,并且需要指定thresh=0是否要用颜色填充可用空间。
sns.jointplot(x="x", y="y", data=data, kind="kde",fill=True)

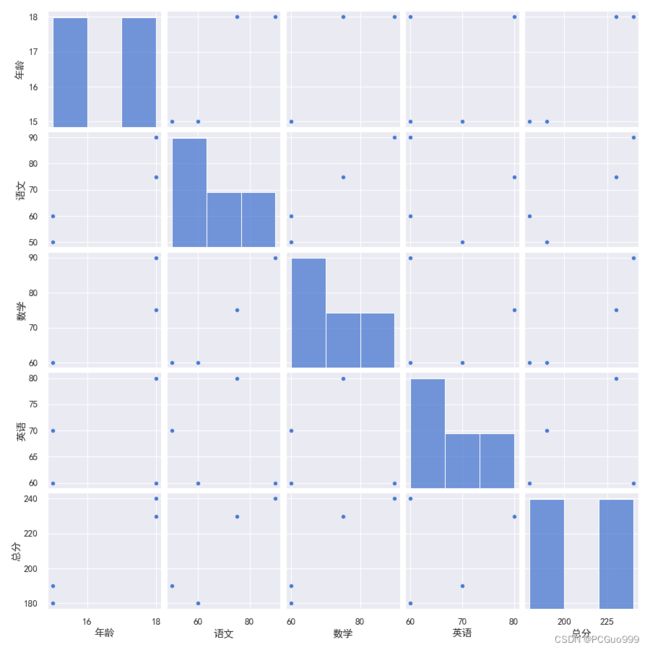
5.绘制成对双变量分布图
要想绘制多个成对的双变量分布,则可以使用pairplot(data)函数。该函数会创建一个坐标轴矩阵,并且显示Datafram对象中每对变量的关系。另外,pairplot()函数也可以绘制每个变量在对角轴上的单变量分布。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 设置显示中文字体
plt.rcParams['font.sans-serif'] = ["SimHei"]
# 设置正常显示符号
plt.rcParams["axes.unicode_minus"] = False
# 获取数据
data=pd.read_csv('./data/Student_score.csv')
sns.pairplot(data)
# # 保存图像
plt.savefig('./images/成对双变量分布图seaborn.png')
plt.show()
6.分类数据绘图
(1)分类数据散点图
① sns.stripplot(x, y, hue, data, jitter=False)
- x,y,hue:用于绘制长格式数据的输入。
- data:用于绘制的数据集。如果x和y不存在,则它将作为宽格式,否则将作为长格式。
- jitter:表示抖动的程度(仅沿类別轴)。当很多数据点重叠时,可以指定抖动的数量或者设为True使用默认值。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 设置显示中文字体
plt.rcParams['font.sans-serif'] = ["SimHei"]
# 设置正常显示符号
plt.rcParams["axes.unicode_minus"] = False
# 获取数据
data=pd.read_csv('./data/Student.csv')
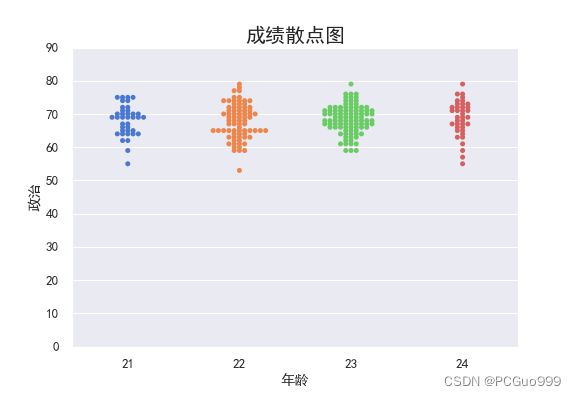
sns.stripplot(x="年龄", y="政治", data=data)
# 添加x,y刻度
plt.yticks(range(0,100,10))
# 添加描述信息
plt.title("成绩散点图",fontsize=20)
# 保存图像
plt.savefig('./images/成绩散点图seaborn.png')
plt.show()

②swarmplot(x, y, hue, data)
swarmplot函数的优点是所有的数据点都不会重叠,可以很清晰地观察到数据的分布情况
(2)分类数据的分布图
①箱型线sns.boxplot(x, y, hue, data, palette, orient,saturation=0.75, width=0.8)
- palette:用于设置不同级别色相的颜色变量。---- palette=[“r”,“g”,“b”,“y”]
- saturation:用于设置数据显示的颜色饱和度。---- 使用小数表示
又称为盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因形状如箱子而得名。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 设置显示中文字体
plt.rcParams['font.sans-serif'] = ["SimHei"]
# 设置正常显示符号
plt.rcParams["axes.unicode_minus"] = False
# 获取数据
data=pd.read_csv('./data/Student.csv')
sns.boxplot(x="年龄", y="政治", data=data,saturation=0.75, width=0.8)
# 添加x,y刻度
plt.yticks(range(0,100,10))
# 添加描述信息
plt.title("成绩箱型线图",fontsize=20)
# 保存图像
plt.savefig('./images/成绩箱型线图.png')
plt.show()
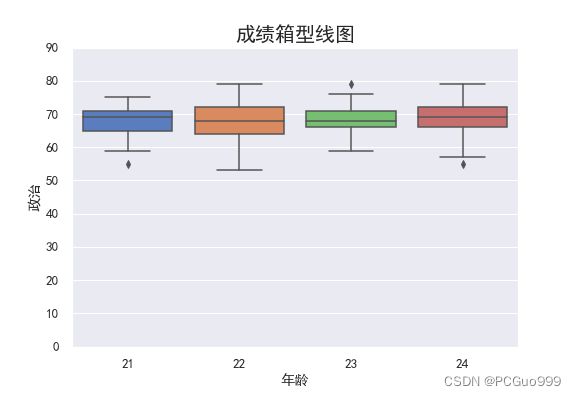
由上图可知:
- 21岁有一个数据小于60的异常值
- 23岁有一个大于70的异常值
- 24岁有一个小于60的异常值
②小提琴图sns.violinplot(x, y, hue, data)
小提琴图用于显示数据分布及其概率密度。结合了箱形图和密度图的特征,主要用来显示数据的分布形状。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 设置显示中文字体
plt.rcParams['font.sans-serif'] = ["SimHei"]
# 设置正常显示符号
plt.rcParams["axes.unicode_minus"] = False
# 获取数据
data=pd.read_csv('./data/Student.csv')
sns.violinplot(x="年龄", y="政治",hue='性别', data=data)
# 添加x,y刻度
plt.yticks(range(0,100,10))
# 添加描述信息
plt.title("成绩小提琴图",fontsize=20)
# 保存图像
plt.savefig('./images/成绩小提琴图.png')
plt.show()
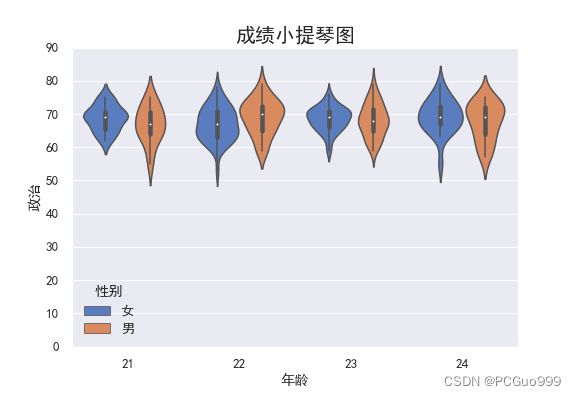
由上图可知:
- 21岁女生位于70左右的比较多
- 22岁女生位于65左右的比较多
(3)分类数据的统计估算图
①柱状图sns.barplot(x,y,hue,data,color,orient)
- hue:色调:分组变量,将产生不同颜色的点
- orient:图的显示方向(垂直
v或水平h,即横向或纵向),默认为垂直 - color:matplotlib颜色
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 设置显示中文字体
plt.rcParams['font.sans-serif'] = ["SimHei"]
# 设置正常显示符号
plt.rcParams["axes.unicode_minus"] = False
# 获取数据
data=pd.read_csv('./data/Student_score.csv')
sns.barplot(x="姓名", y="总分",hue="性别", data=data)
# 添加x,y刻度
plt.yticks(range(0,300,10))
# 添加描述信息
plt.title("成绩表柱状图",fontsize=20)
# 保存图像
plt.savefig('./images/成绩柱状图seaborn.png')
plt.show()

②点图sns.pointplot(x, y,hue, data)
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 设置显示中文字体
plt.rcParams['font.sans-serif'] = ["SimHei"]
# 设置正常显示符号
plt.rcParams["axes.unicode_minus"] = False
# 获取数据
data=pd.read_csv('./data/Student_score.csv')
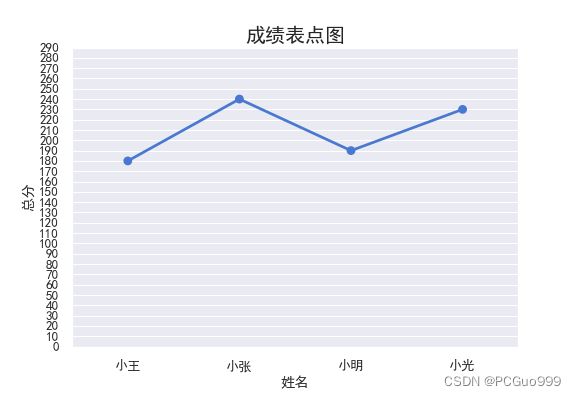
sns.pointplot(x="姓名", y="总分", data=data)
# 添加x,y刻度
plt.yticks(range(0,300,10))
# 添加描述信息
plt.title("成绩表点图",fontsize=20)
# 保存图像
plt.savefig('./images/成绩表点图seaborn.png')
plt.show()
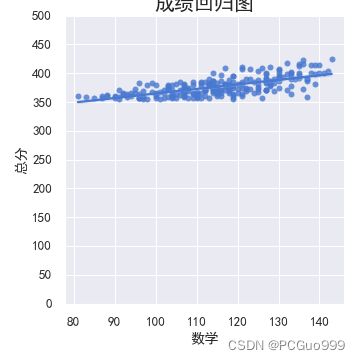
(4)回归图seaborn.lmplot(x, y, data, hue )
线性回归是最原始的回归,用来做数值类型的回归,可以利用它来构建模型并通过构件的模型来进行预测。借助可视化技术,我们可以快速判断一组数据是否属于线性回归。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 设置显示中文字体
plt.rcParams['font.sans-serif'] = ["SimHei"]
# 设置正常显示符号
plt.rcParams["axes.unicode_minus"] = False
# 获取数据
data=pd.read_csv('./data/Student.csv')
sns.lmplot(x="数学", y="总分", data=data)
# 添加x,y刻度
plt.yticks(range(0,501,50))
# 添加描述信息
plt.title("成绩回归图",fontsize=20)
# 保存图像
plt.savefig('./images/成绩回归图.png')
plt.show()