【聚类算法】谱聚类spectral clustering
every blog every motto: You can do more than you think.
https://blog.csdn.net/weixin_39190382?type=blog
0. 前言
谱聚类spectral clustering 概况
说明: 无
1. 正文
1.1 整体理解
谱聚类(Spectral Clustering)是一种基于图论的聚类方法,将带权无向图划分为两个或两个以上的最优子图。使子图内尽量相似,子图间距离尽量较远。其中的最优是指最优目标函数不同。有以下两种:
- smallest cut
- best cut
如下图所示:

1.1.1 无向图
如下图所示,由若干顶点和边组成,由于边没有方向,故称为无向图。其中,
点集合: V = { v 1 , v 2 , . . . . . , v 3 } V = \{v1,v2,.....,v3\} V={v1,v2,.....,v3}
边集合: E = { e 1 , e 2 , . . . . . , e 3 } E = \{e1,e2,.....,e3\} E={e1,e2,.....,e3}
所以,图表示为 G ( V , E ) G(V,E) G(V,E)
权重矩阵(邻接矩阵) W W W, W i j W_{ij} Wij表示 i i i和 j j j之间的权重,由于是无向图,所以
W i j = W j i W_{ij}=W_{ji} Wij=Wji

1.1.2 度和度矩阵
在数据结构中,度定义为与该点直接连接的顶点个数。
在这里,定义如下:
d i = ∑ j = 1 n W i j d_i = \sum_{j=1}^{n}W_{ij} di=j=1∑nWij
即,某行(或列)的权重和。
度矩阵为n个度构成的对角阵,如下:
[ d 1 0 ⋯ 0 0 d 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ d n ] \begin{bmatrix} {d_{1}}&{0}&{\cdots}&{0}\\ {0}&{d_{2}}&{\cdots}&{0}\\ {\vdots}&{\vdots}&{\ddots}&{\vdots}\\ {0}&{0}&{\cdots}&{d_{n}}\\ \end{bmatrix} d10⋮00d2⋮0⋯⋯⋱⋯00⋮dn
1.1.3 相似矩阵
注意: 我们可以计算两点间的距离,生成一个邻接矩阵表示我们点与点的关系(即,我们所说的图),这里的相似矩阵是在“距离矩阵”的基础上(根据距离的远近判断是否相似)根据一定的方法(下面的三种方法)进一步“筛选”
(可以粗略理解,有的点离的比较远不要了)
上述的权重矩阵 由任意两点之间的权重构成,在实际当中,我们并不能直接获得权重,只有数据点的定义,通常会通过两点之间的距离计算权重。距离远权重点,距离近权重高。通常由三种方法
(1). ϵ ϵ ϵ-邻近法(使用较少)
设置一个阈值 ϵ ϵ ϵ,计算两点之间的欧式距离并与阈值比较,
W i j = { 0 , i f s i j > ϵ ϵ , i f s i j ⩽ ϵ W_{ij}=\left\{ \begin{matrix} 0 , & if &s_{ij}>ϵ \\ ϵ, &if &s_{ij}\leqslantϵ \end{matrix} \right. Wij={0,ϵ,ififsij>ϵsij⩽ϵ
用阈值筛选距离,卡的比较死,样本之间权重之间和0,缺失很多信息
(2). k-近邻法
对于任意一点,求取与他最近的k个顶点,该顶点与k个顶点的权重由计算得到(都大于0,其余顶点距离为0),但会导致得到的相似矩阵不对称。如: i i i在 j j j的 k k k个近邻中,但 j j j可能不在 i i i的 k k k个近邻中。针对这个问题由两种解决方法:
说明: s i j s_{ij} sij表示距离
a. 方法一
宽松版
只要一个满足k近邻,则令 W i j = W j i W_{ij}=W_{ji} Wij=Wji,只有同时不满足k近邻,则为0。
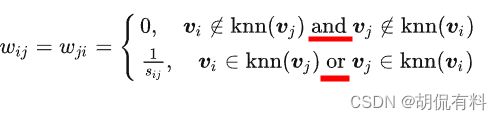
b. 方法二
严格版
两个顶点互为近邻,才计算距离,否则权重为0。

(3). 全连接
计算所有点之间的相互连接,因此权重都大于0,可以选择不同 核函数计算距离,常用的有:
- 多项式核函数
- 高斯核函数
- sigmoid核函数

1.1.4 拉普拉斯矩阵
L = D − W L = D - W L=D−W
D D D 为度矩阵, W W W为上面的邻接矩阵
1.1.5 切图,聚类
下面进入重点了,现在我们要对上面说到的无向图进行切图。
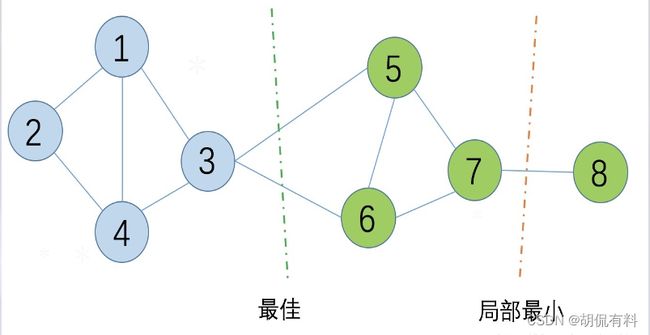
切割优化目标:
C o s t ( G 1 , . . . G 2 ) = ∑ i C ( G i , G i ^ ) Cost(G1,...G2) = \sum_{i}C(G_i,\hat{G_{i}}) Cost(G1,...G2)=i∑C(Gi,Gi^)
C ( G 1 , G 2 ) = ∑ i ∈ G 1 , j ∈ G 2 w i j C(G_1,G_2) = \sum_{i\in G_1,j\in G_2}w_{ij} C(G1,G2)=i∈G1,j∈G2∑wij
- 目标是使切割子图时间的权重和最小,即,切割的边最少。
- 切割中可能会出现局部最优,因此,根据不同的切割方法有不同的切图方法。
(1). RatioCut切图
目标: 使子图的节点数尽可能的大
R a t i o n C u t ( G 1 , . . . G 2 ) = ∑ i C ( G i , G i ^ ) ∣ G i ^ ∣ RationCut(G1,...G2) = \sum_i{C(G_i,\hat{G_i}) \over \mid \hat{G_i} \mid } RationCut(G1,...G2)=i∑∣Gi^∣C(Gi,Gi^)
分母为子图的节点个数
(2). NCut切图
目标: 考虑每个子图边的权重和
N C u t ( C 1 , . . . C k ) = ∑ i C ( G i , G I ^ ) v o l ( G i ^ ) NCut(C_1,...C_k) = \sum_i{C(G_i,\hat{G_I} )\over vol(\hat{G_i})} NCut(C1,...Ck)=i∑vol(Gi^)C(Gi,GI^)
分母为子图各边的权重和
1.2 计算流程
1.2.1 核心主要三部分:
- 相似矩阵的生成(常用:全连接方法)
- 切图方式(常用:NCut)
- 最后的聚类方法(常用:K-Means)
1.2.2 算法流程:
- 构建相似矩阵S、度矩阵D,计算拉普拉斯矩阵 L = D − W L = D - W L=D−W
- 构建标准化以后的拉普拉斯矩阵 D − 1 2 ⋅ L ⋅ D − 1 2 D^{-1 \over 2} ·L ·D^{-1 \over 2} D2−1⋅L⋅D2−1
- 计算 D − 1 2 ⋅ L ⋅ D − 1 2 D^{-1 \over 2} ·L ·D^{-1 \over 2} D2−1⋅L⋅D2−1 的最小的 k 1 k_1 k1个特征值各自对应的特征向量 f f f
- 将各自对应的特征向量 f f f组成的矩阵按行标准化,最终组成的 n ⋅ k 1 n·k_1 n⋅k1维的特征矩阵 F F F
- 对F中的每一行的作为一个 k 1 k_1 k1维的样本,共n个样本,用输入的聚类方法进行聚类,聚类维数为 k 2 k_2 k2
- 得到簇划分 C ( c 1 , c 2 , . . . c k 2 ) C(c_1,c_2,...c_{k2}) C(c1,c2,...ck2)
1.2.3 python实现
def calculate_w_ij(a,b,sigma=1):
w_ab = np.exp(-np.sum((a-b)**2)/(2*sigma**2))
return w_ab
# 计算邻接矩阵
def Construct_Matrix_W(data,k=5):
rows = len(data) # 取出数据行数
W = np.zeros((rows,rows)) # 对矩阵进行初始化:初始化W为rows*rows的方阵
for i in range(rows): # 遍历行
for j in range(rows): # 遍历列
if(i!=j): # 计算不重复点的距离
W[i][j] = calculate_w_ij(data[i],data[j]) # 调用函数计算距离
t = np.argsort(W[i,:]) # 对W中进行行排序,并提取对应索引
for x in range(rows-k): # 对W进行处理
W[i][t[x]] = 0
W = (W+W.T)/2 # 主要是想处理可能存在的复数的虚部,都变为实数
return W
def Calculate_Matrix_L_sym(W): # 计算标准化的拉普拉斯矩阵
degreeMatrix = np.sum(W, axis=1) # 按照行对W矩阵进行求和
L = np.diag(degreeMatrix) - W # 计算对应的对角矩阵减去w
# 拉普拉斯矩阵标准化,就是选择Ncut切图
sqrtDegreeMatrix = np.diag(1.0 / (degreeMatrix ** (0.5))) # D^(-1/2)
L_sym = np.dot(np.dot(sqrtDegreeMatrix, L), sqrtDegreeMatrix) # D^(-1/2) L D^(-1/2)
return L_sym
def normalization(matrix): # 归一化
sum = np.sqrt(np.sum(matrix**2,axis=1,keepdims=True)) # 求数组的正平方根
nor_matrix = matrix/sum # 求平均
return nor_matrix
W = Construct_Matrix_W(your_data) # 计算邻接矩阵
L_sym = Calculate_Matrix_L_sym(W) # 依据W计算标准化拉普拉斯矩阵
lam, H = np.linalg.eig(L_sym) # 特征值分解
t = np.argsort(lam) # 将lam中的元素进行排序,返回排序后的下标
H = np.c_[H[:,t[0]],H[:,t[1]]] # 0和1类的两个矩阵按行连接,就是把两矩阵左右相加,要求行数相等。
H = normalization(H) # 归一化处理
model = KMeans(n_clusters=20) # 新建20簇的Kmeans模型
model.fit(H) # 训练
labels = model.labels_ # 得到聚类后的每组数据对应的标签类型
res = np.c_[your_data,labels] # 按照行数连接data和labels
1.3 小结
谱聚类算法的主要优点有:
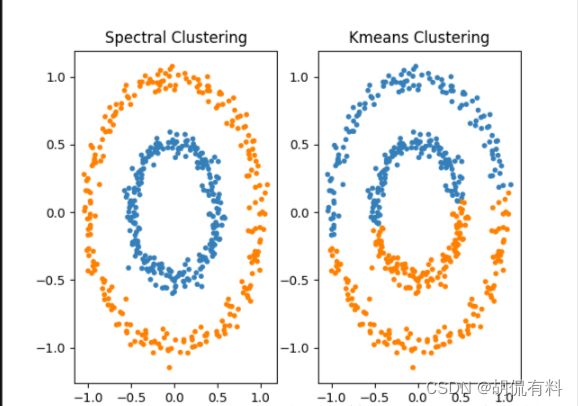
- 谱聚类只需要数据之间的相似度矩阵,因此对于处理稀疏数据的聚类很有效。这点传统聚类算法比如K-Means很难做到。
- 由于使用了降维,因此在处理高维数据聚类时的复杂度比传统聚类算法好。
谱聚类算法的主要缺点有:
- 如果最终聚类的维度非常高,则由于降维的幅度不够,谱聚类的运行速度和最后的聚类效果均不好。
- 聚类效果依赖于相似矩阵,不同的相似矩阵得到的最终聚类效果可能很不同。
参考
[1] https://zhuanlan.zhihu.com/p/387483956
[2] https://blog.csdn.net/songbinxu/article/details/80838865
[3] https://blog.csdn.net/weixin_45591044/article/details/122747024
[4] https://blog.csdn.net/yftadyz/article/details/108933660?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164345675116780264032305%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=164345675116780264032305&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_ulrmf~default-2-108933660.pc_search_insert_ulrmf&utm_term=%E8%B0%B1%E5%9B%BE%E7%90%86%E8%AE%BA&spm=1018.2226.3001.4187
[5] https://blog.csdn.net/katrina1rani/article/details/108451882
[6] https://zhuanlan.zhihu.com/p/392736238
[7] https://zhuanlan.zhihu.com/p/91154535
[8] https://www.cnblogs.com/tychyg/p/5277137.html
[9] https://www.cnblogs.com/kang06/p/9468647.html
[10] https://zhuanlan.zhihu.com/p/29849122
[11] https://www.cnblogs.com/xiximayou/p/13548514.html
[12] https://www.cnblogs.com/pinard/p/6221564.html
[13] https://zhuanlan.zhihu.com/p/54348180
[14] https://blog.csdn.net/qq_43391414/article/details/112277987
[15] https://blog.csdn.net/jxlijunhao/article/details/116443245
[16] https://zhuanlan.zhihu.com/p/368878987
[17] https://blog.csdn.net/qq280929090/article/details/103591577