Java 转 C++ 知识点
目录
-
- 配置Clion同步远程环境
- 0. 内存模型
- 1. 变量的作用域
- 2. typedef与define的区别
- 3. 类的继承范围
- 4. 常量与常函数
- 5. 传值、传引用
- 6. 友元的意义
- 7. 左移运算符重载
- 8. 析构函数
- 9. 带指针的类
- 10. 转型
- 11. 多态
- 12. 右值引用与move
- 13. 智能指针
- 14. iterator_traits特征萃取
- 15. IO(C语言)
- 16. 缓冲
- 17. 文件描述符
- 18. 钩子函数
- 19. fork、exec、wait
- 20. 守护进程
- 21. 信号
- 22. mutex和cond
- 23. 线程
- 24. select poll epoll
- 25. 闭源隐藏
- 26. 进程间通讯概要
- 27. socket
-
- 字节序问题
- 对齐问题
- 类型长度问题
- socket函数
- socket编程流程
- 28. udp丢包
- 29. 第三方包的使用
- 30. 函数指针与回调机制
- 31. 手写HTTP服务器(C)
- 99. 思维上的补充
适合具备一定基础的同学上手,都是一些个人觉得十分重要的小知识点。
解释性语句并不多,具体展开请读者自行搜索。
本人只是c++初学者,如有疏漏,敬请留言指正!
配置Clion同步远程环境

credentials是添加远程连接。
爆红Not found的,请自行在远程服务上下载好(我这里本来有cmake,但是由于版本过低,需要更新)

toolchain选择刚刚配置好的远程选项
回车确定之后,环境就跟远程同步了(windows下可以使用#include
Clion远程小工具
远程路径Depolymentpath自动创建的为临时路径,这里可以自己指定,实现映射远程项目到本地。如下图:

在clion界面右侧打开远程文件系统。如下图:
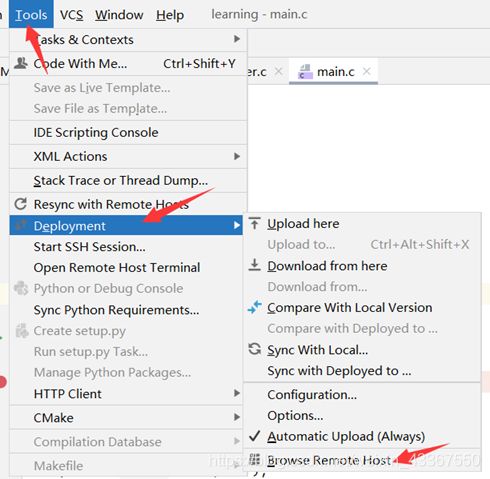
打开一个类似git的版本差异比较窗口,可以在该窗口实现向远程同步,如下图
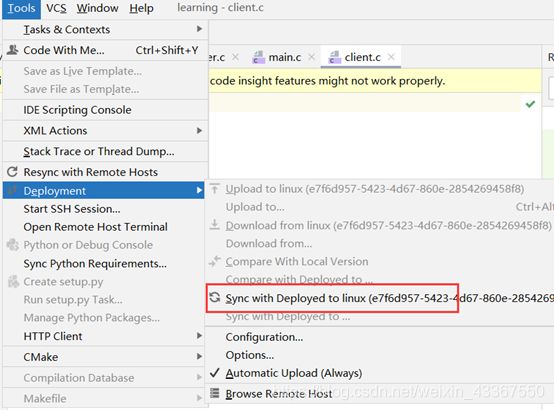
其他同步操作都在Tools中,具体操作见名知意即可。
附:更新\下载 cmake(注意clion的支持版本)
卸载旧版
sudo apt-get autoremove cmake
下载新版
cd ~
wget https://cmake.org/files/v3.19/cmake-3.19.8.tar.gz
tar xvf cmake-3.19.8.tar.gz
cd cmake-3.19.8
安装
./bootstrap --prefix=/usr
make
sudo make install
测试
cmake –version
0. 内存模型
1)stack 栈区:由编译器自动分配和释放
一般存放函数的参数值、局部变量的值等
2)heap 堆区:由程序员分配及释放。若程序员不释放,程序结束后可能由OS回收
3)register 寄存器区:用来保存栈顶指针和指令指针
4)全局区(静态区):全局变量和静态变量是存储在一起的。初始化的和未初始化的是分开的。
程序结束后由系统释放。分为data段(已初始化)和bss段(未初始化)
5)文字常量区:程序结束后由系统释放,存放常量字符串
6)text 程序代码区:存放函数体的二进制代码
与Java相比:
- c++的heap需要程序员手动分配和释放
- C++的堆和栈都可以用于存放对象,以哪种方式管理对象取决于开发人员的代码(比如栈上分配)
定义变量和数组时,Java默认初始化,C++不初始化;
在类中,方法中定义变量、动态数组时,Java默认初始化,C++不初始化
1. 变量的作用域
-
全局变量:直接在函数外部定义的,可跨文件使用(跨文件使用的地方用extern声明使用的是其他文件中的,extren还表示不能改变被修饰的对象的类型以及值),有重名风险
-
static:
- C语言:直接在函数外部定义的,但是加了static,表示仅在当前文件中全局使用(凡是加上了static的(包括函数),都不允许外部使用,相当于private),静态分配
- CPP:跟Java用法一致
2. typedef与define的区别

define仅仅是做简单的替换(或者一些运算表达式),在编译时期完成
typedef 对于类型定义提供了更丰富的支持,在运行时完成
3. 类的继承范围
类的继承范围,指的是子类改变父类数据的最高权限:如果是public继承,则改变父类数据最高到public,如果是private,则把父类继承的所有数据改为private。
4. 常量与常函数
常量只可以访问常函数,所以对于只读函数必须加上const,不然会导致常量不可调用该函数。
传引用或者传指针,可以在函数内改变该对象,为了告知调用者函数是否真的做了改变,需要通过函数参数是否加了const来辨别(尤其是一些不开源的代码,这个尤为重要)。
const是编译时检查,运行时其实是可以修改的(如const_cast)
const在号前面,则值为常量,在后面,则指针为常量。
5. 传值、传引用
传值是新建副本传过去(整包传),如果数据太大,则也会消耗较大内存。
尽量不要传值。
传引用则仅仅是传该数据的地址。
传引用跟传指针是一样的,但是传引用更方便。
为了避免传引用被改,改成传const引用即可。
返回值也尽量传引用,但是在函数内部创建的res不能返回引用,栈上分配的“内存空间”结束后直接被回收,因此直接传值,或者将返回对象作为参数传入,最后返回该引用。(栈上分配的static函数调用完毕不会被释放,因此可以返回引用(如懒加载单例))
6. 友元的意义
友元避免了通过get获取private数据,提高速度;
不过友元破坏了封装性;
此外,友元关系不可传递(A是B的朋友,B是C的朋友,但A不是C的朋友);
友元关系不可继承;
7. 左移运算符重载
左移运算符只能写为全局函数(直接全局或者先友元定义然后类外实现),因为cpp所有操作符都是作用在左值(如果写在类内,则表示obj< delete xx会被转化为两个语句: delete[] xx: 因此array new要与array delete一一对应,因为delete[] 表示会调用数组个数次析构函数,而delete仅仅是回收开辟的空间,但是析构函数只会调用一次。在析构函数中的释放动作就不会被完全执行。 带指针的类,指的是属性成员中有指针变量。 赋值重载首先考虑可能存在自我复制,其次是清空原空间。 个人理解,cpp实质上仅仅允许向上转型。 即便看起来是向下转型转型成功,其实也必须运行时是向上转型。 必须在父类方法上加virtual,才能在通过父类指针指向子类对象的时候,调用子类重写的方法。 右值只能放在右边(左值两边都能放),临时变量一定是右值。 一般情况下,只能获得左值的引用(因为右值没有名称),如果要获得右值的引用,则使用&&。 move拷贝构造,会将所有指针打断然后替换,相当于废弃原有变量(因此临时变量比较合适move)。 具备特殊功能的指针类。 内置的智能指针:用于解决内存泄露的一种指针自动回收机制(引用计数法): 每个容器都持有自己的itreator,调用iterator进行特征获取的时候,分两步走: 分为两类: 每个FILE只有一个游标,比如打开之后开始写,游标后移;这时候用读函数,也是从游标往后读,想从头读需要移动游标。 打开模式:r和r+读的对象必须存在,其他的模式不存在则会创建。 fwrite\fread返回读写成功的字节数 全缓冲:满了刷新,如文件 文件载入逻辑: 系统存在一个指针数组(ulimit查看默认长度为1024),该数组中保存着指向控制文件的一个结构体的指针,文件描述符就是指针数组的下标。其中数组的前三个0、1、2固定分别对应stdin、stdout、stderr。 该指针数组由进程独享,各自进程创建各自的。 钩子函数指的是触发某些动作的时候,调用一系列注册的函数。 fork、wait、exec简称few,基本构建了Unix世界的多进程。 fork是复制父线程为子线程。 exec是替换父线程为执行目标(一般是fork子进程后用exec将子进程替换成别的进程执行) 如果父进程在子进程结束之前结束,子进程会被init接管。如果子进程结束而父进程长期不结束,所有子进程会变成僵尸进程(僵尸进程虽然占用资源很少,但是他们占用了宝贵的进程号,进程号是有上限的),因此在子进程结束的地方,使用n个wait(NULL)来回收子进程。 脱离父进程,直到系统中所有进程都死亡的时候才消亡。(守护线程则是等到所有线程都结束才结束)。 因此,守护进程有以下特点: 当我们用ps axj查看到ppid为1,pid–pgid–sid,TTY为?的就是守护进程。 创建守护进程的步骤 信号分为两类:标准信号和实时信号。 标准信号: 实时信号: 单纯使用mut信号量,会造成忙等,结合cond(条件变量)能够等到通知再抢锁/释放锁,避免忙等。 线程取消:pthread_cancel(pthread_t) join:意思类似wait,调用join的线程会等待他创建的所有子线程执行完毕,执行完毕后对其进行收尸。 yield:极短暂的出让调度权(短暂的sleep,但不会引起调度颠簸) 线程分离:指的是抛弃与该线程的关系(本来是谁创建谁回收,分离之后就不管了) select: poll: epoll epoll_wait分为ET(边缘触发)和LT(水平触发,默认)两种模式。 应用场景: 右键打开一个文件查看他的属性,这时候只需要读取一个文件head,剩余的文件内容我们并不关心(全部舍弃),这就是ET。 不开源的手法(隐藏代码细节的手法) 详见参考:https://blog.csdn.net/zhaohong_bo/article/details/89552188 匿名管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。 命名管道FIFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。 消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。 共享存储SharedMemory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。 信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。 套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。 如何选择通信方式? 共享存储器系统 管道通信系统 消息传递系统 客户机服务器系统 socket用于不同进程或者跨主机跨网络进程之间的通信。 socket带来的问题: 字节序分为大端存储和小端存储,网络字节序一般为大端。 解决办法,通过函数实现本地字节序(host)以及网络字节序(net)的转换。 为了提高寻址效率,对于一个结构体(对象),其大小并非简单是所有对象所占字节数的总和,而是会进行对齐(比如算下来13字节的结构体会对齐为4的倍数,16字节) 比如,若int占用4字节,char占用1字节: 如果换一下顺序: 对其规则必定满足:结构体的总大小是结构体最大成员体的整数倍,此外,对齐是按照(地址%sizeof(type))是否为0来判断的,具体扩展内容请自行搜索。 在socket中解决对齐问题的思路就是取消对齐。 int、short之类的基本类型的长度实际是未定义的,在不同的机器上会表现出不同的长度,因此最好的办法是指定长度,使用int32_t, uint32_t, int64_t 之类的来显示定义。 __attributs__((packed))表示取消对齐。 int socket(int domain, int type, int protocol); domain:下层协议族 socket大致分为两类,流式套接字(如tcp)和报式套接字(如udp),由于流式面向连接,即点对点通信,因此如果要做广播、多播/组播,只能用报式套接字。 题外话:所有数据最好在声明的时候都进行初始化,即便看起来不必要。考虑这种情况:一个指针开辟的大小是16字节,这时候没有初始化,它其实指向的是内存中的一块空闲地址,是有内容的,如果不对其进行初始化(通过memset),如果后面给他赋值的时候只用了12个字节,那么剩余的4个字节依旧是脏数据,尽管我们感知不到,但在网络上传输的时候,可以通过抓包看见。这也算内存泄露。 客户端不bind的话,系统会自动分配一个端口。 相对复杂且重要的一个函数:accept。 需要注意的是,server端至少有2个socket文件描述符,其中一个socket文件描述符(由socket函数创建得到的)专门用于接收请求,其他的socket文件描述符(由accept得到的)用于与客户端通信。 client端只有一个socket文件描述符,就是socket函数创建的,用于跟server端通信。 TTL:time to life,并不是一个时间单位,而是指可以跳转的路由个数。 丢包一般是因为阻塞导致的。 阻塞往往是因为包太多了,所以要进行流控。 通过确认机制、滑动窗口进行流控。 在Java中,可以使用maven之类的构建工具,通过import关键字就可以实现第三方包的使用,但是对C/C++来说,需要自己下载编译源码包,形成静态/动态库,然后编译的时候使用。 ubuntu环境 ,以libevent为例 下载 安装 通常解压后的目录里面也有readme或者README,可以做参考。 验证安装 以编译执行hello-world.c为例 注意-levent,表示连接libevent库(去掉lib,加上l) 编译完毕之后,执行./hello 如果报错 cannot open shared object file: No such file or directory ,应该是环境变量没有配置。 当前用户环境配置: 执行hello阻塞,表示成功。 在Java中,回调的实现一般是通过传递接口参数,然后调用接口的方法实现方法回调。 在C/C++中,由于函数指针的存在,可以将函数作为参数传递,这就实现了比较特别的回调机制。 函数指针的格式:返回值(* 函数指针名称)(函数参数) 例子: 待续 在C中,会经常将返回值放在参数列表上,而返回值只返回一些成功与否的状态信息。个人理解这么做的目的是,将对象的创建与回收都交给用户(假设由方法自己返回,那么创建必定在方法内,但是回收却需要用户在外部考虑) Java有很多自动回收机制,在C中,尽量保证“谁创建谁回收,谁开启谁关闭” 写任意小模块的时候,都要有宏观思维,任何现场(状态)的改变,都要保存其原有现场(状态),结束操作后恢复其原有现场(状态),避免影响到其他模块。 全缓冲与半缓冲同时出现,或者出现线程\进程切换的时候,需要刷新缓冲 多从宏观上考虑问题,如果没有宏观上的把控,在细节上也无法做到尽善尽美,考虑周全。8. 析构函数
调用析构:~xx()
释放名称空间:free(xx)
9. 带指针的类
必须重写三个方法:
拷贝构造:避免浅拷贝(指针直接指向同一块区域导致回收时重复回收)
赋值重载:避免浅拷贝(指针直接指向同一块区域导致回收时重复回收)
析构函数:指针开辟在堆,需要回收10. 转型
比如继承链D->C->B->A (A为顶级父类)
A a=new D()
B b=dynamic_cast(a);
看起来是a向下转成了b,实质还是运行时的d向上转型成了b11. 多态
(多态是virtual的多态)12. 右值引用与move
没有名称的变量一定是右值。
如果不是临时变量,想用move拷贝构造,使用构造函数(std::move(变量))即可。
move指的是把参数当做右值使用。13. 智能指针
unique_ptr:只允许被引用一次,作用域结束后自动回收
shared_ptr:可以被共享引用,其内存在一个引用计数器,计数器为0时自动回收。
weak_ptr:类似弱引用,查看是否被回收,如果没有被回收,还能再用一次14. iterator_traits特征萃取
15. IO(C语言)
sysio:系统io,由操作系统提供,不同的操作系统sysio接口不同。
stdio:标准io,屏蔽系统接口细节,移植性好。
如果只剩5个字节,fwrite(buf,)16. 缓冲
行缓冲:遇到换行符刷新,当流涉及到一个终端时,一般是行缓冲
无缓冲:即时刷新,标准错误流是无缓冲,保证立即能够被看到17. 文件描述符
物理文件 --> inode(FCB) --> 程序打开文件产生结构体X --> X数组 --> X数组的下标就是文件描述符
如下图所示。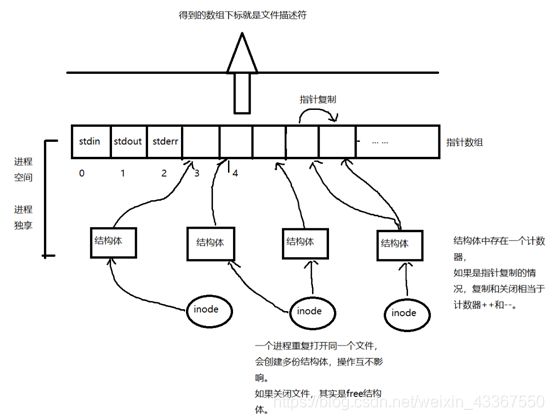
18. 钩子函数
钩子函数分两类:exit类与信号类
exit类:
exit与_exit,exit调用后还有调用各种处理逻辑如钩子函数,但是如果是一些非法异常,这会导致钩子函数的调用导致故障扩大,此时应该调用_exit(或者abort),立即终止,什么也不动。
信号类:
通过信号注册函数,实现触发信号的时候,触发对应的函数。比如SIGINT信号(ctrl+C会触发),最好关联到exit信号上,避免程序异常退出没有进行资源回收。19. fork、exec、wait
fork用于创建进程(进程复制),wait用于进程收尸,exec用于进程转换。
fork有两个返回值pid,在子线程返回值为0,在父线程非零。
调用fork之前必须fflush(NULL)刷新所有缓冲区,不然可能会导致后面的流输出异常。(同理,线程切换之前需要先刷新缓冲区)20. 守护进程
ppid为1:因为脱离了父进程,由init接管;
pid–pgid–sid:因为守护进程脱离父进程后,自己变成了leader,他单独成为了一个group,单独有一个session;
TTY为?:终端,表示没有终端
通过调用setid()使子进程成为守护进程(必须是子进程调用,因为要脱离父进程),返回一个sessionid。
通过/var/run/name.pid锁文件实现守护进程单例。创建守护进程的时候会创建该文件,该文件中保存着守护进程的进程号,当重复创建守护进程的时候会检查该文件,若存在则禁止创建。
21. 信号
kill -l查看,非SIGRTMIN开头的都是标准信号,其余都是实时信号。
两者的最大区别:对于连续的相同信号,标准信号指处理最后一个信号,而实时信号会让他们排队然后逐一执行。
pending位:存不存在标准信号(默认为0)
mask位:要不要响应标准信号(默认为1)
收到:当收到标准信号之后,修改进程的pending位,进程被打断,进入内核态,等待调度;
响应:进入用户态的时候查看mask&pending,发现标准信号具体内容,响应标准信号内容。
这就可以解释sleep之类的为什么不精准,因为这些本质上也是标准信号。
有些平台的sleep是alarm+ pause实现的,因此会跟其他alarm冲突(仅一个生效),因此避免使用sleep。
相同信号排队执行,解决了标准信号只能响应一次且响应顺序未定义的情况22. mutex和cond
23. 线程
cancel点:可能引发阻塞的系统调用都是cancel点,pthread_cancel调用后,只会在遇到cancel点之后才真正取消线程(避免突然结束导致钩子函数未执行导致资源泄露)24. select poll epoll
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
nfds:所有文件描述符中最大的那个再+1(因此处理的的文件有上限,int类型)
三个set:读事件、写事件、异常事件,事件的装载和结果集都共同这三个,会出现覆盖,以事件驱动;
timeout:超时
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
返回结果=有多少个事件
nfds类型变成了nfds_t,因此理论上没有上限;
传入结构体pollfd,因此是以文件描述符驱动事件。
pollfd中将传入事件和事件结果分开存放,不会被覆盖了。
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
一个数据包是500字节,服务端第一次只读到了400字节,第二次客户端再发过来了100字节,此时想读到剩余的100字节,就必须使用LT模式。25. 闭源隐藏
26. 进程间通讯概要
或者参考Unix网络编程
1.基于共享数据结构的通信方式
(仅适用于传递相对少量的数据,通信效率低,属于低级通信)
2.基于共享存储区的通信方式
管道是指用于连接一个读进程和一个写进程以实现它们之间通信的一个共享文件(pipe文件)
管道机制需要提供一下几点的协调能力
1.互斥,即当一个进程正在对pipe执行读/写操作时,其它进程必须等待
2.同步,当一个进程将一定数量的数据写入,然后就去睡眠等待,直到读进程将数据取走,再去唤醒。读进程与之类似
3.确定对方是否存在
1.直接通信方式
发送进程利用OS所提供的发送原语直接把消息发给目标进程
2.间接通信方式
发送和接收进程都通过共享实体(邮箱)的方式进行消息的发送和接收
1.套接字 – 通信标识型的数据结构是进程通信和网络通信的基本构件
基于文件型的 (当通信进程都在同一台服务器中)其原理类似于管道
基于网络型的(非对称方式通信,发送者需要提供接收者命名。通信双方的进程运行在不同主机环境下被分配了一对套接字,一个属于发送进程,一个属于接收进程)
2.远程过程调用和远程方法调用27. socket
socket的意义:屏蔽不同协议与不同数据传输类型的组合类型差异,全部抽象为文件来操作。字节序问题
对于 0xA1A2
大端存储:0xA1 0xA2,符合人的阅读习惯,低位地址存高位字节
小端存储:0xA2 0xA1 低位地址存低位字节
注意字节序指的是字节的顺序,所以顺序对调的最小单位是字节(而不是bit)
如:
ntohs , ntohl
htons , htonl
其中ntohs指的是net to host short,其他缩写含义类似。对齐问题
对齐也不是简单的按倍数对齐,跟结构体对象声明顺序有关。
{
int a;
int b;
char c;
char d;
}
上述对象总占用42+12 = 10,对齐为12字节。
{
int a;
char c;
int b;
char d;
}
会变成4+4+4+2=14字节,对齐为16字节。类型长度问题

name其实是一个占位符,用于构建变长结构体,因为我们不能预估名字的长度,而通常使用char*指针表示字符串,但显然不可能传递一个地址到网络上去。
这样之后,
在发送端,操作msg_st实例的时候,初始化为指针,指针指向的空间大小为malloc(sizeof(msg_st))+strlen(name)。
在接收端,接收的msg_st大小直接定义为malloc(MAX),其中MAX为可能的最大值,比如udp建议的包大小为512,那么MAX=512-udp头部 = 512-8socket函数
type:上层数据传输类型
protocol:协议(0表示使用协议族中的默认协议)
(广播和多播/组播的区别在于,广播是全网发送,所有人必须接收,多播/组播则是自己拉个群,发消息就群里大家自己看的到,但有个特殊的群224.0.0.1默认所有人都在这里面,如果往这里发消息也是广播。)
socket编程流程

int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
28. udp丢包
一般linux默认64,windows默认128,所以TTL通常来说是足够用的,不会因为TTL耗尽导致丢包。
单独的确认机制会导致大量的时间耗费在等待ack上,通过滑动窗口+累计确认+拥塞控制,能够降低这个等待时间。29. 第三方包的使用
官网https://libevent.org/下载tar.gz,上传到服务器
解压 tar zxvf xxxx.tar.gz
进入目录 cd xxx
源码包安装三步走:
1.检查环境,生成makefile ./configure
2.编译 make 生成 .o 和可执行文件
3.[sudo] make install 将必要资源拷贝到系统指定目录(/usr/local/lib)
通常源码包中都会有样例,比如libevent目录下有个sample目录,可以尝试执行sample中的样例查看是否安装成功。gcc hello-world.c -o hello -levent
临时环境变量配置:
执行语句:export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH
vim ~/.bashrc
在末尾添加:
export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH
保存退出即可30. 函数指针与回调机制
#include 31. 手写HTTP服务器(C)
99. 思维上的补充