redis从入门到精通(一)———初始redis及安装
一、初识Redis
1、简介
Redis是一款开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存也可持久化的日志型、Key-Value高性能数据库。Redis与其他Key-Value缓存产品相比有以下三个特点:
- 支持数据持久化,可以将内存中的数据保存在磁盘中,重启可再次加载使用
- 支持简单的Key-Value类型的数据,同时还提供List、Set、Zset、Hash等数据结构的存储
- 支持数据的备份,即Master-Slave模式的数据备份
同时,我们再看下Redis有什么优势:
- 读速度为110000次/s,写速度为81000次/s,性能极高
- 具有丰富的数据类型,这个上面已经提过了
- Redis所有操作都是原子的,意思是要么成功执行要么失败完全不执行,多个操作也支持事务
- 丰富的特性,比如Redis支持publish/subscribe、notify、key过期等
2、redis优点
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2) 支持丰富数据类型,支持string,list,set,sorted set,hash
(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
二、Redis安装、启动
1、安装
这次写Redis系列的文章,LZ特意去阿里云上买了一个月的服务器,操作系统是Linux,因为Redis项目本身不正式支持Windows系统。不过微软开放技术小组开发和维护了Windows版本的Redis,下载地址为https://github.com/MicrosoftArchive/redis/releases,感兴趣的可以自己去试下,LZ在自己笔记本上安装启动过,没有问题,但就不细说了。
下面说一下在Linux系统上安装并启动Redis的步骤(我的Redis安装在/data/component/redis目录下,每一步使用的命令标红加粗):
- 进入目录,cd /data/component/redis
- 下载Redis,wget http://download.redis.io/releases/redis-3.2.11.tar.gz,可以看到LZ使用的Redis版本是3.2.11,在LZ写这篇文章的时候,Redis最新版本为4.0.9,地址为http://download.redis.io/releases/redis-4.0.9.tar.gz,感兴趣的朋友也可以用这个版本
- 解压下载下来的tar包,tar -zxvf redis-3.2.11.tar.gz,解压完毕的文件夹名称为redis-3.2.11
- 进入redis-3.2.11,cd redis-3.2.11
- 由于我们下载下来的是源文件,因此使用make命令对源文件进行一个构建,构建完毕我们会发现src目录下多出了redis-benchmark、redis-check-aof、redis-check-rdb、redis-cli、redis-sentinel、redis-server几个可执行文件,这几个可执行文件后面会说到
- 由于上述几个命令在/data/component/redis/redis-3.2.11/src目录下,为了更方便地使用这几个命令而不需要指定全路径,配置一下环境变量。这里我是以非root用户进行登录的,因此配置用户变量,先执行cd命令回到初始目录,再vi ./.bash_profile,在path这一行加入PATH=PATH:PATH:HOME/.local/bin:$HOME/bin:/data/component/redis/redis-3.2.11/src,使用:wq保存并退出
- 使环境变量生效,执行source ./.bash_profile
- 使用redis-server即可启动redis,redis-server /data/component/redis/redis-3.2.11/redis.conf
不过这个时候我们的启动稍微有点问题,不是后台启动的,即ctrl+c之后Redis就停了:
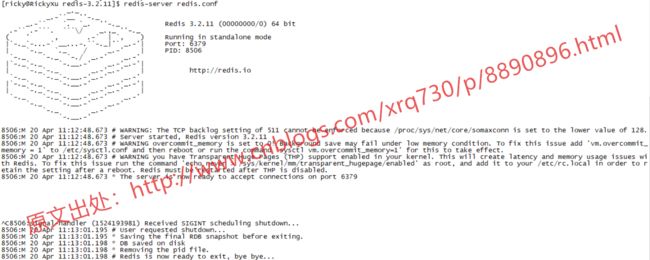
为了解决这个问题,我们需要修改一下redis.conf,将Redis设置为以守护进程的方式进行启动,打开redis.conf,找到daemonize,将其设置为yes即可:

这个时候先关闭一下再启动,Redis就在后台自动运行了,关闭Redis有两种方式:
- redis-cli shutdown,这是种安全关闭redis的方式,但这种写法只适用于没有配置密码的场景,比较不安全,配置密码下一部分会讲
- kill -9 pid,这种方式就是强制关闭,可能会造成数据未保存
重启后,我们可以使用ps -ef | grep redis,netstat -ant | grep 6379命令来验证Redis已经启动。
2、Redis登录授权
上面我们安装了Redis,但这种方式是非常不安全的,因为没有密码,这样任何连接上Redis服务器的用户都可以对Redis执行操作,所以这一部分我们来讲一下给Redis设置密码。
打开redis.conf,找到"requirepass"部分,打开原本关闭的注释,替换一下自己想要的密码即可:
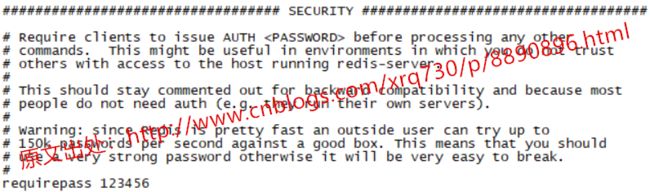
重启Redis,授权登录有两种做法:
- 连接的时候直接指定密码,redis-cli -h 127.0.0.1 -p 6379 -a 123456
- 连接后授权,redis-cli -h 127.0.0.1 -p 6379,auth 123456
在配置了密码的情况下,没有进行授权,那么对Redis发送的命令,将返回"(error) NOAUTH Authentication required."。
3、Redis配置文件redis.conf
上面两小节,设置使用守护线程启动、设置密码,都需要修改redis.conf,说明redis.conf是Redis核心的配置文件,本小节我们来看一下redis.conf中一些常用配置:
| 配置 |
作用 |
默认 |
| bind |
当配置了bind之后:
|
127.0.0.1 |
| protected-mode |
protected-mode是Redis3.2之后的新特性,用于加强Redis的安全管理,当满足以下两种情况时,protected-mode起作用:
当满足以上两种情况且protected-mode=yes的时候,访问Redis将报错,即密码未设置的情况下,无密码访问Redis只能通过安装Redis的本机进行访问 |
yes |
| port |
Redis访问端口,由于Redis是单线程模型,因此单机开多个Redis进程的时候会修改端口,不然一般使用大家比较熟悉的6379端口就可以了 |
6379 |
| tcp-backlog |
半连接队列的大小,对半连接队列不熟的可以看我以前的文章TCP:三次握手、四次握手、backlog及其他 |
511 |
| timeout |
指定在一个client空闲多少秒之后就关闭它,0表示不管 |
0 |
| tcp-keepalive |
设置tcp协议的keepalive,从Redis的注释来看,这个参数有两个作用:
|
300 |
| daemonize |
这个前面说过了,指定Redis是否以守护进程的方式启动 |
no |
| supervised |
这个参数表示可以通过upstart和systemd管理Redis守护进程,这个具体和操作系统相关,资料也不是很多,就暂时不管了 |
no |
| pidfile |
当Redis以守护进程的方式运行的时候,Redis默认会把pid写到pidfile指定的文件中 |
/var/run/redis_6379.pid |
| loglevel |
指定Redis的日志级别,Redis本身的日志级别有notice、verbose、notice、warning四种,按照文档的说法,这四种日志级别的区别是:
|
notice |
| logfile |
配置log文件地址,默认打印在命令行终端的窗口上 |
"" |
| databases |
设置Redis数据库的数量,默认使用0号DB |
16 |
| save |
把Redis数据保存到磁盘上,这个是在RDB的时候用的,介绍RDB的时候专门说这个 |
save 900 1 save 300 10 save 60 10000 |
| stop-writes-on-bgsave-error |
当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。 这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。 如果Redis重启了,那么又可以重新开始接收数据了 |
yes |
| rdbcompression |
是否在RBD的时候使用LZF压缩字符串,如果希望省点CPU,那就设为no,不过no的话数据集可能就比较大 |
yes |
| rdbchecksum |
是否校验RDB文件,在RDB文件中有一个checksum专门用于校验 |
yes |
| dbfilename |
dump的文件位置 |
dump.rdb |
| dir |
Redis工作目录 |
./ |
| slaveof |
主从复制,使用slaveof让一个节点称为某个节点的副本,这个只需要在副本上配置 |
关闭 |
| masterauth |
如果主机使用了requirepass配置进行密码保护,使用这个配置告诉副本连接的时候需要鉴权 |
关闭 |
| slave-serve-stale-data |
当一个Slave与Master失去联系或者复制正在进行中,Slave可能会有两种表现:
|
yes |
| slave-read-only |
配置Redis的Slave实例是否接受写操作,即Slave是否为只读Redis |
yes |
| slave-priority |
从站优先级是可以从redis的INFO命令输出中查到的一个整数。当主站不能正常工作时,redis sentinel使用它来选择一个从站并将它提升为主站。 |
100 |
| requirepass |
设置客户端认证密码 |
关闭 |
| rename-command |
命令重命名,对于一些危险命令例如:
作为服务端redis-server,常常需要禁用以上命令来使得服务器更加安全,禁用的具体做法是是:
也可以保留命令但是不能轻易使用,重命名这个命令即可:
这样,重启服务器后则需要使用新命令来执行操作,否则服务器会报错unknown command |
关闭 |
| maxclients |
设置同时连接的最大客户端数量,一旦达到了限制,Redis会关闭所有的新连接并发送一个"max number of clients reached"的错误 |
关闭,默认10000 |
| maxmemory |
不要使用超过指定数量的内存,一旦达到了,Redis会尝试使用驱逐策略来移除键 |
关闭 |
| maxmemory-policy |
当达到了maxmemory之后Redis如何移除数据,有以下的一些策略:
注意,当写操作且Redis发现没有合适的数据可以移除的时候,将会报错 |
关闭,noeviction |
| appendonly |
是否开启AOF,关于AOF后面再说 |
no |
| appendfilename |
AOF文件名称 |
appendonly.aof |
| appendfsync |
操作系统实际写数据到磁盘的频率,有以下几个选项:
当不确定是使用哪种的时候,官方推荐使用everysec,它是速度与数据安全之间的一种折衷方案 |
everysec |
| no-appendfsync-on-rewrite |
aof持久化机制有一个致命的问题,随着时间推移,aof文件会膨胀,当server重启时严重影响数据库还原时间,因此系统需要定期重写aof文件。 重写aof的机制为bgrewriteaof(另外一种被废弃了,就不说了),即在一个子进程中重写从而不阻塞主进程对其他命令的处理,但是这依然有个问题。 bgrewriteaof和主进程写aof,都会操作磁盘,而bgrewriteaof往往涉及大量磁盘操作,这样就会让主进程写aof文件阻塞。 针对上述问题,可以使用此时可以使用no-appendfsync-on-rewrite参数做一个选择:
|
no |
| auto-aof-rewrite-percentage |
本次aof文件超过上次aof文件该值的百分比时,才会触发rewrite |
100 |
| auto-aof-rewrite-min-size |
aof文件最小值,只有到达这个值才会触发rewrite,即rewrite由auto-aof-rewrite-percentage+auto-aof-rewrite-min-size共同保证 |
64mb |
| aof-load-truncated |
redis在以aof方式恢复数据时,对最后一条可能出问题的指令的处理方式:
|
yes |
| slowlog-log-slower-than |
Redis慢查询的最低条件,单位微妙,即查询时间>这个值的会被记录 |
10000 |
| slowlog-max-len |
Redis存储的慢查询最大条数,超过该值之后会将最早的slowlog剔除 |
128 |
| lua-time-limit |
一个lua脚本执行的最大时间,单位为ms |
5000 |
| cluster-enabled |
正常来说Redis实例是无法称为集群的一部分的,只有以集群方式启动的节点才可以。为了让Redis以集群方式启动,就需要此参数。 |
关闭 |
| cluster-config-file |
每个集群节点应该有自己的配置文件,这个文件是不应该手动修改的,它只能被Redis节点创建且更新,每个Redis集群节点需要不同的集群配置文件 |
关闭,nodes-6379.conf |
| cluster-node-timeout |
集群中一个节点向其他节点发送ping命令时,必须收到回执的毫秒数 |
关闭,15000 |
| cluster-slave-validity-factor |
如果该项设置为0,不管Slave节点和Master节点间失联多久都会一直尝试failover。 比如timeout为5,该值为10,那么Master与Slave之间失联50秒,Slave不会去failover它的Master |
关闭,10 |
| cluster-migration-barrier |
当一个Master拥有多少个好的Slave时就要割让一个Slave出来。 例如设置为2,表示当一个Master拥有2个可用的Slave时,它的一个Slave会尝试迁移 |
关闭,1 |
| cluster-require-full-coverage |
有节点宕机导致16384个Slot全部被覆盖,整个集群是否停止服务,这个值一定要改为no |
关闭,yes |
Redis性能测试
之前说过Redis在make之后有一个redis-benchmark,这个就是Redis提供用于做性能测试的,它可以用来模拟N个客户端同时发出M个请求。首先看一下redis-benchmark自带的一些参数:
| 参数 |
作用 |
默认值 |
| -h |
服务器名称 |
127.0.0.1 |
| -p |
服务器端口 |
6379 |
| -s |
服务器Socket |
无 |
| -c |
并行连接数 |
50 |
| -n |
请求书 |
10000 |
| -d |
SET/GET值的字节大小 |
2 |
| -k |
1表示keep alive,0表示重连 |
1 |
| -r |
SET/GET/INC使用随机Key而不是常量,在形式上key样子为mykey_ran:000000012456 -r的值决定了value的最大值 |
无 |
| -p |
使用管道请求 |
1,即不使用管道 |
| -q |
安静模式,只显示query/sec值 |
无 |
| --csv |
使用csv格式输出 |
无 |
| -l |
循环,无限运行测试 |
无 |
| -t |
只运行使用逗号分割的命令的测试 |
无 |
| -I |
空闲模式,只打开N个空闲线程并且等待 |
无 |
抛开配置只谈性能的都是耍流氓,说一下我买的阿里云服务器的配置:
- 单核CPU,CPU类型为Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
- 内存4G
- 带宽1M
- 操作系统为Centos7
首先我们运行最简单的redis-benchmark -q,运行结果为:
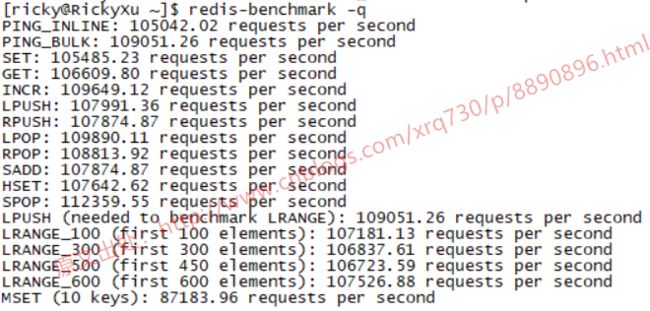
打印了每个命令的QPS,看到基本都在读写速度基本都在100000次/s以上。
接着换一个命令进行测试,因为实际场景中我们的Key和Value一定是非常丰富的,不可能是单一的Key和单一的Value,因此接着去的测试使用-r模拟value到100000且将运行次数提高到1000000次,具体命令为redis-benchmark -q -r 100000 -n 1000000,运行结果为:
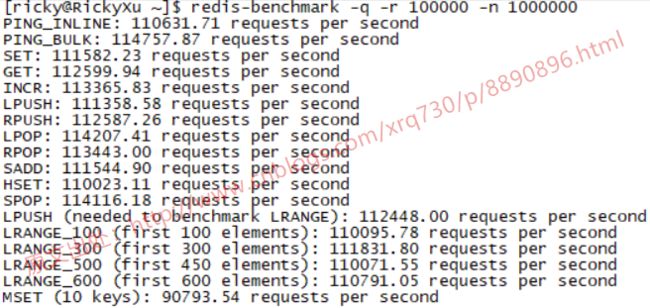
看到整个读写效率基本都在110000次/s以上,证明了读写的高效率。
简单对于Redis的性能测试就到这儿,这个测试结果看起来很美,但是实际应用却完全不是,主要体现在以下几点:
- 网络与带宽,这是现实中最主要的影响因素,上面的测试还是太过于低级,现实使用中Redis里面存一个用户信息、订单信息,几KB的大小,100000qps根本不可能大家可以算算需要多大的带宽,粗粗算一下超过1个G吧,很多线上服务的带宽根本达不到1G/s,所以Redis的吞吐量最先会被网络带宽限制住
- Redis由于是单线程模型,因此CPU性能非常重要,尤其是大缓存的快速CPU,我这里的CPU上面写过了,Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz总体还是可以的
- 客户端连接数,上面使用了默认的连接数50,实际上10W、20W甚至100W+呢?不过得益于epoll模型,整个下降的可以接受,下面有一张连接数和qps的关系,我也是网上找来的
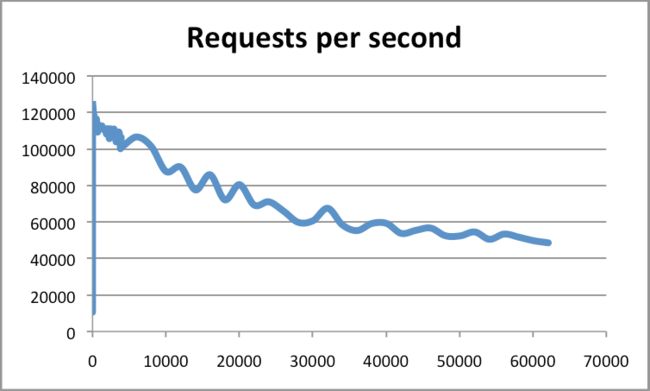
- RDB和AOF可能会对Redis造成的阻塞并未考虑进去
- 尽可能使用大内存,避免SWAP