二、机器学习基础知识:Python数据处理基础
文章目录
- 1、基本数据类型
-
- 1.1 数字类型(Number)
- 1.2 字符串类型(String)
- 1.3 列表类型(List)
- 1.4 元组类型(Tuple)
- 1.5 字典类型(Dictionary)
- 1.6 集合类型(Set)
- 2、数据文件读写
-
- 2.1 打开与关闭文件
- 2.2 读取文件内容
- 2.3 将数据写入文件
1、基本数据类型
在Python3的环境中,提供了6种基本的内置数据类型,包括数字类型(Number)、字符串类型(String)、列表类型(List)、元组类型(Tuple)、字典类型(Dictionary)以及集合类型(Set)。根据数据对象是否可变,又将它们划分为可变数据类型和不可变数据类型。
可变数据类型包括列表、字典和集合,它们在声明时会开辟一块内存空间,使用Python的内置方法对内存中的数据进行修改时,内存地址不发生变化。
不可变数据类型包括数字、字符串和元组,它们在声明时也会开辟一块内存空间,但不能改变这块内存内的数据,如果改变了变量的赋值,就会重新开辟一块内存空间。
1.1 数字类型(Number)
Python的数字类型包括int、float、bool和complex复数类型。当指定一个值时,就创建了一个数字类型的对象。

在上图实例中,使用id函数可以看到在变量a加1之后,内存地址已经发生了改变,说明a=a+1不是原有的int对象加1,而是重新创建了一个int对象,大小为a+1。
详细参考:Python程序设计基础:数值
1.2 字符串类型(String)
Python中的字符串用半角的单引号或双引号括起来,对于字符串内的特殊字符,使用反斜杠‘\’进行转义,若要获取字符串中的一部分,可以采用切片的方式,截取格式如下:
字符串变量[头下标:尾下标]
字符串的起始下标为0,正序或逆序读取均可。
字符串的赋值与访问:

详细参考:Python程序设计基础:字符串
1.3 列表类型(List)
列表使用方括号[]进行定义,数据项之间使用逗号分隔,数据项可以是数字、字符串或列表。
列表也是一种Python序列,其截取语法与字符串类似,格式如下:
列表变量[头下标:尾下标]
同样,列表的起始下标为0,正序或逆序读取均可。
列表的访问、修改与遍历:
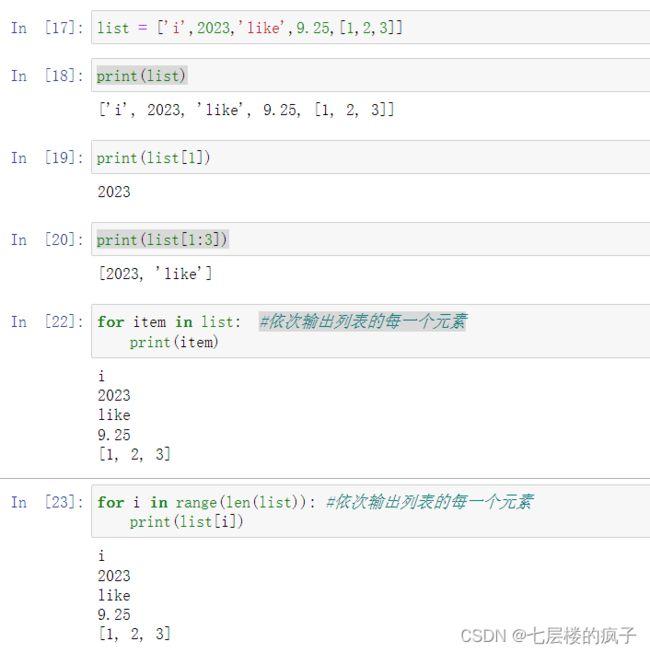
详细参考:Python程序设计基础:列表与元组(一)
1.4 元组类型(Tuple)
元组写在小括号()中,元素之间使用逗号进行分割,元素可以具有不同的类型,它与列表相似,但是元组的元素不可修改。
元组的截取语法和字符串、列表类似,起始下标为0,正序或逆序读取均可。
元组的访问:
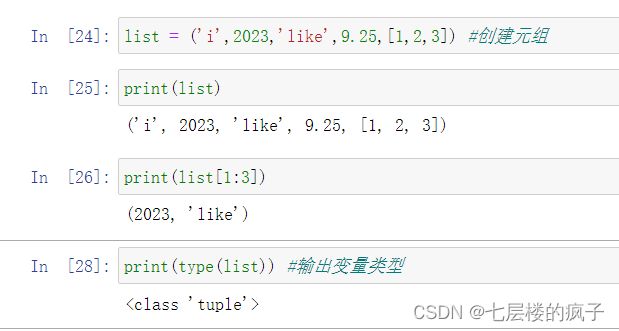
详细参考:Python程序设计基础:列表与元组(二)
1.5 字典类型(Dictionary)
字典是一种可变容器模型,可存储任意类型对象,使用大括号{}定义,格式如下:
字典名={键:值}
字典的键和值使用冒号分隔,每个键值对之间使用逗号分隔。键一般是唯一的,如果出现了重复,则后面的键值对会替换前面的键值对。值的数据及类型不限,可以是字符串、数字或元组。
字典的访问及修改:

详细参考:Python程序设计基础:字典与集合(一)
1.6 集合类型(Set)
集合是一列无序的、不重复的数据项组成,Python中的集合是可变类型。与数学中的集合概念相同,集合中每个元素都是唯一的。同时,集合不设置顺序,每次输出时元素的排序可能都不相同。
集合使用大括号表示,形式上和字典相同,但数据项不是成对的。
由于集合和字典一样都是使用大括号表示,因为在创建空集合时,必须使用set()函数进行创建。
集合的主要操作:
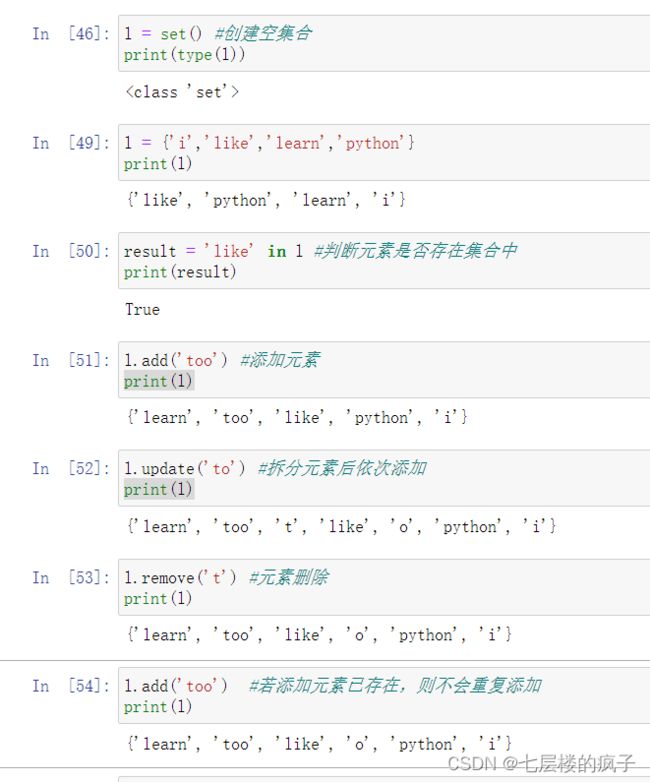
详细参考:Python程序设计基础:字典与集合(二)
2、数据文件读写
机器学习的本质是对数据进行处理,如果数据是少量的、临时的,可以使用上述数据类型变量进行存储,如果数据是大量的,则需要使用到数据文件。
2.1 打开与关闭文件
Python中打开文件的内置函数是open()函数,打开文件后会创建一个文件对象,对文件的访问都是通过这个文件对象进行,语法格式如下:
open(file_name[,access_mode][,buffering])
其中file_name为字符串类型,是要访问的文件名称;access_mode是文件的打开模式,如读取、写入或追加等,默认为r(只读模式),写数据通常使用的是w和a,表示改写和添加;buffering表示文件缓冲区的策略,当该值为0时,表示不使用缓冲区。
打开文件之后可以向文件中写入相关内容,使用write()方法,参数为要写入的字符串。
在文件操作结束后,需要关闭文件对象,释放缓存,需要使用文件对象的close()方法。
文件的打开、写入与关闭:
filename = '1.txt'
f=open(filename,'a') #打开1.txt文件并进行写操作
f.write("machine learning")
f.close
使用with语句可以调用f.close()方法就能自动关闭文件。
filename = '1.txt'
with open('1.txt','a') as f:
f.write("machine learning")
2.2 读取文件内容
常见的读取文件方法主要有三种,包括read()、readline()、readlines()。
read():默认读取整个文件,若设置了参数字节数,则读取对应字节数,返回值为字符串。
readline():从当前位置开始,读取文件中的一行,返回值为字符串。
readlines():从当前位置开始,读取文件的所有行,返回值为列表,每行为列表的一项。
使用read()读取整个文件:

使用readline()逐行读取文件:
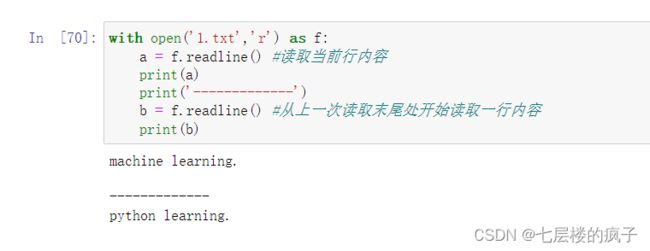
使用readlines()一次读取多行:

2.3 将数据写入文件
如果要将数据写入文件,打开方式需要选择w(写入)或者a(追加)模式,写入文件可以使用Python提供的write方法,其语法格式如下:
fileobject.write(byte)
其中byte为待写入文件的字符串或字节。
文件的写入与追加:
with open('1.txt','w') as f:
f.write("machine learning.\n") #写入相关内容,清空原文件
filename = '1.txt'
with open('1.txt','a') as f:
f.write("python learning.\n") #追加写入相关内容,不覆盖原数据
详细参考:Python程序设计基础:文件操作