机器学习 协同过滤算法
协同过滤算法
协同过滤算法是根据已有的数据来推测出未知的数据,从海量的数据中找到相似度达到指定范围的数据,而这些数据成为你的邻居,系统将会为你推荐心仪的物品。
余弦相似法

通过计算两个向量的夹角余弦值来评估它们的相似度
修正余弦相似法

中心化后再求余弦相似度
皮尔森系数法
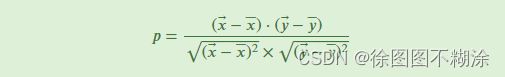
皮尔森系数和修正余弦相似度的计算是相同的,不同的是皮尔森系数的分母采用评分集是两个用户共同评分集,而修正余弦是采用两个用户各自的评分集。
具体步骤:
1、找到与目标用户兴趣相似的用户集合
2、计算相似度
3、找到这个集合中用户喜欢的,且目标用户没用的物品,推荐给用户
import math
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import pandas as pd
#创建数据
data = {"Tom":{"The Avengers":3.0,"The Martin":4.0,"Guardians of the Galaxy":3.5,"Edge of Tomorrow":5.0,"The Maze Runner":3.0},
"Jane":{"The Avengers":3.0,"The Martin":4.0,"Guardians of the Galaxy":4.0,"Edge of Tomorrow":3.0,"The Maze Runner":3.0,"Unbroken":4.5},
"Jim":{"The Martin":5.0,"Guardians of the Galaxy":4.0,"Edge of Tomorrow":1.0,"The Maze Runner":2.0,"Unbroken":4.0}}
data.get("Tom")
'''
{'The Avengers': 3.0,
'The Martin': 4.0,
'Guardians of the Galaxy': 3.5,
'Edge of Tomorrow': 5.0,
'The Maze Runner': 3.0}
'''
余弦相似法
#余弦相似法
def user_similarity_on_cosine(data,user1,user2):
#选出用户1与用户2共有的评分电影
common = [movie for movie in data[user1] if movie in data[user2]]
#movie 返回的是data[user1]的键,即为电影名
if len(common)==0:
return 0
#分子
multiply_sum = sum((data[user1][movie])*(data[user2][movie]) for movie in common)#用户1用户2的电影评分相乘相加
#分母
pow_sum1 = sum(math.pow(data[user1][movie],2) for movie in data[user1])#用户1的电影评分平方和
pow_sum2 = sum(math.pow(data[user2][movie],2) for movie in data[user2])#用户2的电影评分平方和
modified_cosine_similarity = float(multiply_sum)/math.sqrt(pow_sum1*pow_sum2)#余弦相似性系数
return modified_cosine_similarity
r1 = user_similarity_on_cosine(data,"Tom","Jane")
print('Tom与Jane的相似性:',r1)
修正余弦相似法
#修正余弦相似法
def user_similarity_on_modified_cosine(data,user1,user2):
#选出用户1与用户2共有的评分电影
common = [movie for movie in data[user1] if movie in data[user2]]
#movie 返回的是data[user1]的键,即为电影名
if len(common)==0:
return 0
#分子
average1 = float(sum(data[user1][movie] for movie in data[user1]))/len(data[user1]) #用户1的电影评分均值
average2 = float(sum(data[user2][movie] for movie in data[user2]))/len(data[user2]) #用户2的电影评分均值
#分子
#用户1和用户2的电影评分中心化后,在对应相乘相加
multiply_sum =sum((data[user1][movie]-average1)*(data[user2][movie]-average2) for movie in common)
#分母
pow_sum1 = sum(math.pow(data[user1][movie]-average1,2) for movie in data[user1])#用户1的电影评分中心化后平方和
pow_sum2 = sum(math.pow(data[user2][movie]-average2,2) for movie in data[user2])#用户2的电影评分中心化后平方和
modified_cosine_similarity = float(multiply_sum)/math.sqrt(pow_sum1*pow_sum2)#修正余弦相似性系数
return modified_cosine_similarity
r2 = user_similarity_on_modified_cosine(data,"Tom","Jane")
print('Tom与Jane的相似性:',r2)
皮尔森系数
#皮尔森系数
def similarUserWithPearson(data,user1,user2):
#选出用户1与用户2共有的评分电影
common = [movie for movie in data[user1] if movie in data[user2]]
#movie 返回的是data[user1]的键,即为电影名
if len(common)==0:
return 0
#分子
average1 = float(sum(data[user1][movie] for movie in common))/len(common) #用户1的电影评分均值
average2 = float(sum(data[user2][movie] for movie in common))/len(common) #用户2的电影评分均值
#分子
#用户1和用户2的电影评分中心化后,在对应相乘相加
multiply_sum =sum((data[user1][movie]-average1)*(data[user2][movie]-average2) for movie in common)
#分母
pow_sum1 = sum(math.pow(data[user1][movie]-average1,2) for movie in common)#用户1的电影评分中心化后平方和
pow_sum2 = sum(math.pow(data[user2][movie]-average2,2) for movie in common)#用户2的电影评分中心化后平方和
modified_cosine_similarity = float(multiply_sum)/math.sqrt(pow_sum1*pow_sum2)#修正余弦相似性系数
return modified_cosine_similarity
r3 = similarUserWithPearson(data,"Tom","Jane")
print('Tom与Jane的相似性:',r3)
可视化分析,找到相似度最高的用户
r11 = user_similarity_on_cosine(data,"Jane","Jim")
r12 = user_similarity_on_cosine(data,"Jane","Tom")
r21 = user_similarity_on_modified_cosine(data,"Jane","Jim")
r22 = user_similarity_on_modified_cosine(data,"Jane","Tom")
r31 = similarUserWithPearson(data,"Jane","Jim")
r32 = similarUserWithPearson(data,"Jane","Tom")
matplotlib.rcParams['font.family'] = 'SimHei'
plt.figure(figsize=(6,4))
r1 = [r11,r21,r31]
r2 = [r12,r22,r32]
l = len(r1)
width = 0.3#条形宽度
x1 = np.arange(l)
x2 = np.arange(l)+width#将第二种图形分开,不设置的话会重合
s = ['余弦法','修正余弦法','皮尔森法']
plt.bar(x1,r1,width=0.3,label='Jane,Jim')
plt.bar(x2,r2,width=0.3,label='Jane,Tom')
plt.xticks(x1+width,s)
plt.ylim(0,1.2)#拉长纵坐标
plt.yticks([])#取消坐标刻度
plt.ylabel(u'相似性系数值',fontproperties='SimHei')
plt.legend()#图例放到图中
plt.title('Jane与其他用户的相似系数值')

recommendation = list(set(data.get("Jane")).difference(data.get("Jim")))
print("Jane看过而Jim没看过的电影:",recommendation)#Jane看过而Jim没看过的电影: ['The Avengers']
recommendation = list(set(data.get("Jane")).difference(data.get("Tom")))
print("Jane看过而Tom没看过的电影:",recommendation)#Jane看过而Tom没看过的电影: ['Unbroken']