Go-Python-Java-C-LeetCode高分解法-第八周合集
前言
本题解Go语言部分基于 LeetCode-Go
其他部分基于本人实践学习
个人题解GitHub连接:LeetCode-Go-Python-Java-C
欢迎订阅CSDN专栏,每日一题,和博主一起进步
LeetCode专栏

本文部分内容来自网上搜集与个人实践。如果任何信息存在错误,欢迎读者批评指正。本文仅用于学习交流,不用作任何商业用途。
文章目录
- 前言
- [50. Pow(x, n)](https://leetcode.com/problems/powx-n/)
-
- 题目
- 题目大意
- 解题思路
- 代码
- Go
- Python
- Java
- Cpp
- [51. N-Queens](https://leetcode.com/problems/n-queens/)
-
- 题目
- 题目大意
- 解题思路
- 代码
- Go
- Python
- Java
- Cpp
- [52. N-Queens II](https://leetcode.com/problems/n-queens-ii/)
-
- 题目
- 题目大意
- 解题思路
- 代码
- Go
- Python
- Java
- Cpp
- [53. Maximum Subarray](https://leetcode.com/problems/maximum-subarray/)
-
- 题目
- 题目大意
- 解题思路
- 代码
- Go
- Python
- Java
- Cpp
- [54. Spiral Matrix](https://leetcode.com/problems/spiral-matrix/)
-
- 题目
- 题目大意
- 解题思路
- 代码
- Go
- Python
- Java
- Cpp
- [55. Jump Game](https://leetcode.com/problems/jump-game/)
-
- 题目
- 题目大意
- 解题思路
- 代码
- Python
- Java
- Cpp
- [56. Merge Intervals](https://leetcode.com/problems/merge-intervals/)
-
- 题目
- 题目大意
- 解题思路
- 代码
- Go
- Python
- Java
- Cpp
50. Pow(x, n)
题目
Implement pow(x, n), which calculates x raised to the power n (xn).
Example 1:
Input: 2.00000, 10
Output: 1024.00000
Example 2:
Input: 2.10000, 3
Output: 9.26100
Example 3:
Input: 2.00000, -2
Output: 0.25000
Explanation: 2-2 = 1/22 = 1/4 = 0.25
Note:
- -100.0 < x < 100.0
- n is a 32-bit signed integer, within the range [−2^31, 2^31− 1]
题目大意
实现 pow(x, n) ,即计算 x 的 n 次幂函数。
解题思路
- 要求计算 Pow(x, n)
- 这一题用递归的方式,不断的将 n 2 分下去。注意 n 的正负数,n 的奇偶性。
当然,让我们分别介绍每个版本的解题思路:
Go 版本解题思路:
-
基本情况处理:首先,检查特殊情况。如果 n 等于 0,直接返回 1,因为任何数的 0 次幂都等于 1。如果 n 等于 1,直接返回 x,因为任何数的 1 次幂都等于它本身。
-
处理负指数:如果 n 是负数,将 n 变为其绝对值,同时将 x 变为 1/x。这是因为 x 的负指数等于 1/x 的正指数。
-
递归计算:接下来,采用递归的方式计算 x 的 n/2 次幂,将结果存储在 tmp 变量中。这是因为 x^n 可以拆分为 x^(n/2) * x^(n/2)。
-
处理奇数和偶数:根据 n 的奇偶性,如果 n 是偶数,返回 tmp 的平方;如果 n 是奇数,返回 tmp 的平方再乘以 x。
Python 版本解题思路:
-
基本情况处理:同样,首先检查特殊情况。如果 n 等于 0,返回 1。如果 n 等于 1,返回 x。
-
处理负指数:如果 n 是负数,将 n 变为其绝对值,同时将 x 变为 1/x。
-
递归计算:使用递归计算 x 的 n/2 次幂,将结果存储在 tmp 变量中。
-
处理奇数和偶数:根据 n 的奇偶性,如果 n 是偶数,返回 tmp 的平方;如果 n 是奇数,返回 tmp 的平方再乘以 x。
Java 版本解题思路:
-
基本情况处理:同样,首先检查特殊情况。如果 n 等于 0,返回 1。如果 n 等于 1,返回 x。
-
处理负指数:如果 n 是负数,将 n 变为其绝对值,同时将 x 变为 1/x。
-
递归计算:使用递归计算 x 的 n/2 次幂,将结果存储在 tmp 变量中。
-
处理奇数和偶数:根据 n 的奇偶性,如果 n 是偶数,返回 tmp 的平方;如果 n 是奇数,返回 tmp 的平方再乘以 x。
C++ 版本解题思路:
-
基本情况处理:同样,首先检查特殊情况。如果 n 等于 0,返回 1。如果 n 等于 1,返回 x。
-
处理负指数:如果 n 是负数,将 n 变为其绝对值,同时将 x 变为 1/x。
-
数据类型转换:将 n 转换为 long long 类型,以避免整数溢出问题。
-
递归计算:使用递归计算 x 的 n/2 次幂,将结果存储在 tmp 变量中。
-
处理奇数和偶数:根据 n 的奇偶性,如果 n 是偶数,返回 tmp 的平方;如果 n 是奇数,返回 tmp 的平方再乘以 x。
这些是每个版本中用于解决 Pow(x, n) 问题的主要思路。它们都利用了递归来拆分问题,同时考虑了指数的正负性和奇偶性,以获得最终的结果。
代码
Go
// 时间复杂度 O(log n), 空间复杂度 O(1)
func myPow(x float64, n int) float64 {
if n == 0 {
return 1
}
if n == 1 {
return x
}
if n < 0 {
n = -n
x = 1 / x
}
// 递归计算 x 的 n/2 次幂
tmp := myPow(x, n/2)
if n%2 == 0 {
// 如果 n 为偶数,则返回 tmp 的平方
return tmp * tmp
}
// 如果 n 为奇数,则返回 tmp 的平方再乘以 x
return tmp * tmp * x
}
Python
class Solution:
def myPow(self, x: float, n: int) -> float:
if n == 0:
return 1
if n == 1:
return x
if n < 0:
n = -n
x = 1 / x
tmp = self.myPow(x, n // 2)
if n % 2 == 0:
return tmp * tmp
return tmp * tmp * x
Java
class Solution {
public double myPow(double x, long n) {
if (n == 0) {
return 1;
}
if (n == 1) {
return x;
}
if (n < 0) {
n = -n;
x = 1 / x;
}
double tmp = myPow(x, n / 2);
if (n % 2 == 0) {
return tmp * tmp;
}
return tmp * tmp * x;
}
}
Cpp
class Solution {
public:
double myPow(double x, int n) {
if (n == 0) {
return 1.0;
}
if (n == 1) {
return x;
}
long long absN = n; // 将 n 转换为 long long 类型
…};
当然,让我们逐个版本介绍并讨论所需的基础知识:
Go 版本:
-
基本的 Go 语言知识: 在编写 Go 代码之前,你需要了解 Go 语言的基本语法、数据类型、变量声明、函数定义等基础知识。
-
递归: 这个算法使用递归来计算幂函数。了解递归的概念和如何在 Go 中编写递归函数是很重要的。
-
条件语句: 代码中使用了条件语句(
if和if-else)来处理不同情况,例如 n 的正负性和奇偶性。
Python 版本:
-
Python 语言基础: 你需要了解 Python 语言的基础知识,包括变量、函数、条件语句、递归等。
-
递归: 和 Go 版本一样,Python 版本也使用递归来计算幂函数。了解递归的概念和如何在 Python 中编写递归函数很重要。
Java 版本:
-
Java 语言基础: 你需要熟悉 Java 语言的基础,包括类的定义、方法的声明、条件语句等。
-
递归: 与前两个版本一样,Java 版本也使用递归来计算幂函数。了解递归的概念以及如何在 Java 中编写递归函数是必要的。
-
数据类型转换: Java 版本中对 n 进行了数据类型转换,将 int 转换为 long。了解数据类型转换的概念在处理数据时非常重要。
C++ 版本:
-
C++ 语言基础: 你需要熟悉 C++ 语言的基础知识,包括类的定义、函数的声明、条件语句等。
-
递归: 与其他版本一样,C++ 版本也使用递归来计算幂函数。了解递归的概念以及如何在 C++ 中编写递归函数是必要的。
-
数据类型: C++ 版本中使用了 long long 数据类型来处理 n,这是为了避免整数溢出问题。了解 C++ 的数据类型和溢出问题是重要的。
这些是每个版本中需要掌握的基础知识要点。如果你对其中任何一个版本有更具体的问题或需要进一步的解释,请随时提问。
51. N-Queens
题目
The n-queens puzzle is the problem of placing n queens on an n×n chessboard such that no two queens attack each other.
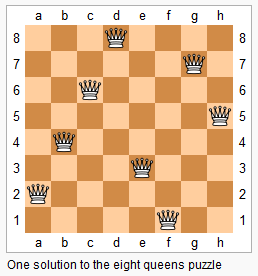
Given an integern, return all distinct solutions to then-queens puzzle.
Each solution contains a distinct board configuration of then-queens’ placement, where'Q'and'.'both indicate a
queen and an empty space respectively.
Example:
Input: 4
Output: [
[".Q..", // Solution 1
"...Q",
"Q...",
"..Q."],
["..Q.", // Solution 2
"Q...",
"...Q",
".Q.."]
]
Explanation: There exist two distinct solutions to the 4-queens puzzle as shown above.
题目大意
给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 ‘Q’ 和 ‘.’
分别代表了皇后和空位。
解题思路
- 求解 n 皇后问题
- 利用 col 数组记录列信息,col 有
n列。用 dia1,dia2 记录从左下到右上的对角线,从左上到右下的对角线的信息,dia1 和 dia2
分别都有2*n-1个。 - dia1 对角线的规律是
i + j 是定值,例如[0,0],为 0;[1,0]、[0,1] 为 1;[2,0]、[1,1]、[0,2] 为 2; - dia2 对角线的规律是
i - j 是定值,例如[0,7],为 -7;[0,6]、[1,7] 为 -6;[0,5]、[1,6]、[2,7] 为 -5;为了使他们从 0 开始,i -
j + n - 1 偏移到 0 开始,所以 dia2 的规律是i - j + n - 1 为定值。
还有一个位运算的方法,每行只能选一个位置放皇后,那么对每行遍历可能放皇后的位置。如何高效判断哪些点不能放皇后呢?这里的做法毕竟巧妙,把所有之前选过的点按照顺序存下来,然后根据之前选的点到当前行的距离,就可以快速判断是不是会有冲突。举个例子:
假如在 4 皇后问题中,如果第一二行已经选择了位置 [1, 3],那么在第三行选择时,首先不能再选 1, 3 列了,而对于第三行, 1
距离长度为2,所以它会影响到 -1, 3 两个列。同理,3 在第二行,距离第三行为 1,所以 3 会影响到列 2, 4。由上面的结果,我们知道 -1,
4 超出边界了不用去管,别的不能选的点是 1, 2, 3,所以第三行就只能选 0。在代码实现中,可以在每次遍历前根据之前选择的情况生成一个
occupied 用来记录当前这一行,已经被选了的和由于之前皇后攻击范围所以不能选的位置,然后只选择合法的位置进入到下一层递归。另外就是预处理了一个皇后放不同位置的字符串,这样这些字符串在返回结果的时候是可以在内存中复用的,省一点内存。
当然,让我们分别介绍每个版本的解题思路:
Go 版本解题思路:
-
递归回溯法:Go
版本的解决方法采用了递归回溯法。从第一行开始,尝试在每一行的每一列放置皇后,然后递归进入下一行。如果在某一行找到一个可行的皇后位置,就继续下一行的放置。如果找不到合适的位置,就回溯到上一行,尝试其他列的位置,直到找到所有可能的解。 -
布尔数组:为了确保皇后不会互相攻击,使用了布尔数组
col、dia1和dia2
来跟踪哪些列和对角线已被占用。这些数组的索引表示列号和对角线编号,值为true表示已被占用,值为false表示可用。 -
生成棋盘:在找到一个解之后,使用
generateBoard函数生成棋盘,将皇后位置标记为 ‘Q’,并将棋盘添加到结果中。
Python 版本解题思路:
-
递归回溯法:Python 版本的解决方法也采用了递归回溯法,与 Go
版本相似。从第一行开始,尝试在每一行的每一列放置皇后,然后递归进入下一行。如果在某一行找到一个可行的皇后位置,就继续下一行的放置。如果找不到合适的位置,就回溯到上一行,尝试其他列的位置,直到找到所有可能的解。 -
布尔列表:为了确保皇后不会互相攻击,使用了布尔列表
col、dia1和dia2
来跟踪哪些列和对角线已被占用。这些列表的索引表示列号和对角线编号,值为True表示已被占用,值为False表示可用。 -
生成棋盘:在找到一个解之后,使用
generateBoard函数生成棋盘,将皇后位置标记为 ‘Q’,并将棋盘添加到结果中。
Java 版本解题思路:
-
递归回溯法:Java
版本的解决方法同样采用了递归回溯法。从第一行开始,尝试在每一行的每一列放置皇后,然后递归进入下一行。如果在某一行找到一个可行的皇后位置,就继续下一行的放置。如果找不到合适的位置,就回溯到上一行,尝试其他列的位置,直到找到所有可能的解。 -
布尔数组:为了确保皇后不会互相攻击,使用了布尔数组
col、dia1和dia2
来跟踪哪些列和对角线已被占用。这些数组的索引表示列号和对角线编号,值为true表示已被占用,值为false表示可用。 -
生成棋盘:在找到一个解之后,使用
generateBoard函数生成棋盘,将皇后位置标记为 ‘Q’,并将棋盘添加到结果中。
C++ 版本解题思路:
-
递归回溯法:C++
版本的解决方法也采用了递归回溯法,与其他版本相似。从第一行开始,尝试在每一行的每一列放置皇后,然后递归进入下一行。如果在某一行找到一个可行的皇后位置,就继续下一行的放置。如果找不到合适的位置,就回溯到上一行,尝试其他列的位置,直到找到所有可能的解。 -
布尔向量:为了确保皇后不会互相攻击,使用了布尔向量
col、dia1和dia2
来跟踪哪些列和对角线已被占用。这些向量的索引表示列号和对角线编号,值为true表示已被占用,值为false表示可用。 -
生成棋盘:在找到一个解之后,使用
generateBoard函数生成棋盘,将皇后位置标记为 ‘Q’,并将棋盘添加到结果中。
这些解题思路的核心都是使用递归回溯法来尝试不同的皇后放置方式,并使用布尔数组/列表/向量来跟踪哪些位置已被占用,以确保皇后不互相攻击。同时,使用字符串处理来生成和表示棋盘。
代码
Go
// 解法一 DFS
func solveNQueens(n int) [][]string {
col, dia1, dia2, row, res := make([]bool, n), make([]bool, 2*n-1), make([]bool, 2*n-1), []int{}, [][]string{}
putQueen(n, 0, &col, &dia1, &dia2, &row, &res) // 调用putQueen函数来找到解
return res
}
// 尝试在一个n皇后问题中, 摆放第index行的皇后位置
func putQueen(n, index int, col, dia1, dia2 *[]bool, row *[]int, res *[][]string) {
if index == n { // 所有皇后都已经成功摆放,得到一个解
*res = append(*res, generateBoard(n, row)) // 生成棋盘并添加到结果集中
return
}
for i := 0; i < n; i++ {
// 尝试将第index行的皇后摆放在第i列
if !(*col)[i] && !(*dia1)[index+i] && !(*dia2)[index-i+n-1] {
*row = append(*row, i) // 在当前行的row中记录皇后位置
(*col)[i] = true // 在列col中标记为占用
(*dia1)[index+i] = true // 在对角线dia1中标记为占用
(*dia2)[index-i+n-1] = true // 在对角线dia2中标记为占用
putQueen(n, index+1, col, dia1, dia2, row, res) // 递归下一行
(*col)[i] = false // 回溯:取消占用
(*dia1)[index+i] = false // 回溯:取消占用
(*dia2)[index-i+n-1] = false // 回溯:取消占用
*row = (*row)[:len(*row)-1] // 回溯:移除上一行的皇后位置
}
}
return
}
// 生成一个N皇后问题的棋盘
func generateBoard(n int, row *[]int) []string {
board := []string{}
res := ""
for i := 0; i < n; i++ {
res += "."
}
for i := 0; i < n; i++ {
board = append(board, res) // 初始化棋盘为全"."
}
for i := 0; i < n; i++ {
tmp := []byte(board[i]) // 将当前行转换为字节切片以修改皇后位置
tmp[(*row)[i]] = 'Q' // 在皇后位置处添加"Q"表示皇后
board[i] = string(tmp)
}
return board // 返回表示棋盘的字符串切片
}
Python
class Solution:
def solveNQueens(self, n: int) -> List[List[str]]:
result = []
col = [False] * n
dia1 = [False] * (2 * n - 1)
dia2 = [False] * (2 * n - 1)
row = [0] * n
self.putQueen(n, 0, col, dia1, dia2, row, result)
return result
def putQueen(self, n, index, col, dia1, dia2, row, result):
if index == n:
result.append(self.generateBoard(n, row))
return
for i in range(n):
if not col[i] and not dia1[index + i] and not dia2[index - i + n - 1]:
row[index] = i
col[i] = True
dia1[index + i] = True
dia2[index - i + n - 1] = True
self.putQueen(n, index + 1, col, dia1, dia2, row, result)
col[i] = False
dia1[index + i] = False
dia2[index - i + n - 1] = False
def generateBoard(self, n, row):
board = []
for i in range(n):
row_str = ['.' for _ in range(n)]
row_str[row[i]] = 'Q'
board.append(''.join(row_str))
return board
Java
import java.util.ArrayList;
import java.util.List;
class Solution {
public List> solveNQueens(int n) {
List> result = new ArrayList<>();
boolean[] col = new boolean[n];
boolean[] dia1 = new boolean[2 * n - 1];
boolean[] dia2 = new boolean[2 * n - 1];
int[] row = new int[n];
putQueen(n, 0, col, dia1, dia2, row, result);
return result;
}
private void putQueen(int n, int index, boolean[] col, boolean[] dia1, boolean[] dia2, int[] row, List> result) {
if (index == n) {
result.add(generateBoard(n, row));
return;
}
for (int i = 0; i < n; i++) {
if (!col[i] && !dia1[index + i] && !dia2[index - i + n - 1]) {
row[index] = i;
col[i] = true;
dia1[index + i] = true;
dia2[index - i + n - 1] = true;
putQueen(n, index + 1, col, dia1, dia2, row, result);
col[i] = false;
dia1[index + i] = false;
dia2[index - i + n - 1] = false;
}
}
}
private List generateBoard(int n, int[] row) {
List board = new ArrayList<>();
StringBuilder sb = new StringBuilder();
for (int i = 0; i < n; i++) {
sb.append('.');
}
for (int i = 0; i < n; i++) {
char[] chars = sb.toString().toCharArray();
chars[row[i]] = 'Q';
board.add(new String(chars));
}
return board;
}
}
Cpp
class Solution {
public:
vector> solveNQueens(int n) {
vector> result;
vector col(n, false);
vector dia1(2 * n - 1, false);
vector dia2(2 * n - 1, false);
vector row(n, 0);
putQueen(n, 0, col, dia1, dia2, row, result);
return result;
}
void putQueen(int n, int index, vector& col, vector& dia1, vector& dia2, vector& row, vector>& result) {
if (index == n) {
result.push_back(generateBoard(n, row));
return;
}
for (int i = 0; i < n; i++) {
if (!col[i] && !dia1[index + i] && !dia2[index - i + n - 1]) {
row[index] = i;
col[i] = true;
dia1[index + i] = true;
dia2[index - i + n - 1] = true;
putQueen(n, index + 1, col, dia1, dia2, row, result);
col[i] = false;
dia1[index + i] = false;
dia2[index - i + n - 1] = false;
}
}
}
vector generateBoard(int n, vector& row) {
vector board(n, string(n, '.'));
for (int i = 0; i < n; i++) {
board[i][row[i]] = 'Q';
}
return board;
}
};
当然,让我们分别介绍每个版本的代码中所需要的基础知识:
Go 版本:
-
切片 (Slices):Go 使用切片来处理动态数组。在代码中,使用
[]string表示一个字符串切片,用于存储每个皇后的位置。 -
递归 (Recursion):解决 N-Queens 问题的关键是递归。代码中使用递归来尝试在每一行中放置皇后,同时进行回溯,以寻找所有可能的解。
-
布尔数组 (Boolean Arrays):使用布尔数组来跟踪哪些列和对角线已被占用,以确保皇后不互相攻击。
Python 版本:
-
列表 (Lists):Python 使用列表来处理动态数组,类似于 Go 中的切片。在代码中,使用
List[List[str]]
表示一个字符串列表的列表,用于存储棋盘的不同解。 -
递归 (Recursion):与 Go 版本类似,Python 版本也使用递归来尝试在每一行中放置皇后,并进行回溯。
-
布尔列表 (Boolean Lists):Python 使用布尔列表来跟踪哪些列和对角线已被占用,以确保皇后不互相攻击。
-
列表推导式 (List Comprehension):在生成棋盘时,使用列表推导式将字符串列表转换为包含皇后位置的字符串。
Java 版本:
-
ArrayList:Java 中使用
ArrayList来处理动态数组,类似于 Go 的切片和 Python
的列表。在代码中,使用List表示一个字符串列表的列表。 -
递归 (Recursion):与 Go 和 Python 版本类似,Java 版本也使用递归来尝试在每一行中放置皇后,并进行回溯。
-
布尔数组 (Boolean Arrays):Java 使用布尔数组来跟踪哪些列和对角线已被占用,以确保皇后不互相攻击。
-
字符串处理:Java 使用
StringBuilder来处理字符串的可变性,以便在棋盘上放置皇后。
C++ 版本:
-
向量 (Vectors):C++ 使用向量来处理动态数组,类似于 Go 的切片、Python 的列表和 Java 的
ArrayList。在代码中,使用vector表示一个字符串向量的向量。 -
递归 (Recursion):与其他版本类似,C++ 版本也使用递归来尝试在每一行中放置皇后,并进行回溯。
-
布尔向量 (Boolean Vectors):C++ 使用布尔向量来跟踪哪些列和对角线已被占用,以确保皇后不互相攻击。
-
字符串处理:C++ 使用字符串向量和字符数组来表示和处理棋盘,将皇后位置添加到合适的位置。
这些基础知识包括切片、列表、递归、布尔数组/列表、字符串处理等,是理解和编写解决 N-Queens
问题的关键要素。如果您对其中的任何概念有更具体的疑问,或者需要更深入的解释,请随时提出。
52. N-Queens II
题目
The n-queens puzzle is the problem of placing n queens on an n×n chessboard such that no two queens attack each other.

Given an integer n, return the number of distinct solutions to the n-queens puzzle.
Example:
Input: 4
Output: 2
Explanation: There are two distinct solutions to the 4-queens puzzle as shown below.
[
[".Q..", // Solution 1
"...Q",
"Q...",
"..Q."],
["..Q.", // Solution 2
"Q...",
"...Q",
".Q.."]
]
题目大意
给定一个整数 n,返回 n 皇后不同的解决方案的数量。
解题思路
- 这一题是第 51 题的加强版,在第 51 题的基础上累加记录解的个数即可。
- 这一题也可以暴力打表法,时间复杂度为 O(1)。
当然,让我们分别介绍每个版本的解题思路:
Go 版本的解题思路
Go 版本的解决方案采用深度优先搜索(DFS)和回溯法来解决 N 皇后问题。下面是解题思路的关键步骤:
-
创建并初始化用于记录列、两个对角线是否被占用的布尔数组,以及记录每行皇后位置的整数切片,还有结果的变量。
-
从第一行开始,递归尝试在每一行放置皇后,直到达到最后一行。每次放置皇后时,需要检查当前列、两个对角线是否被占用。
-
如果某一行可以放置皇后,将皇后位置记录在整数切片中,并更新列、对角线的占用情况。
-
继续递归到下一行,重复相同的过程。
-
当放置完成所有行时,计数结果加1,表示找到了一种解法。
-
回溯到上一行,撤销当前行的皇后放置,继续尝试下一列。
-
重复上述步骤,直到找到所有解法。
Python 版本的解题思路
Python 版本的解决方案也采用深度优先搜索(DFS)和回溯法来解决 N 皇后问题。解题思路与 Go 版本基本相同:
-
创建并初始化用于记录列、两个对角线是否被占用的布尔数组,以及记录每行皇后位置的整数切片。
-
从第一行开始,递归尝试在每一行放置皇后,直到达到最后一行。每次放置皇后时,需要检查当前列、两个对角线是否被占用。
-
如果某一行可以放置皇后,将皇后位置记录在整数切片中,并更新列、对角线的占用情况。
-
继续递归到下一行,重复相同的过程。
-
当放置完成所有行时,计数结果加1,表示找到了一种解法。
-
回溯到上一行,撤销当前行的皇后放置,继续尝试下一列。
-
重复上述步骤,直到找到所有解法。
Java 版本的解题思路
Java 版本的解决方案同样采用深度优先搜索(DFS)和回溯法来解决 N 皇后问题。解题思路如下:
-
创建并初始化用于记录列、两个对角线是否被占用的布尔数组,以及记录每行皇后位置的整数数组。
-
从第一行开始,递归尝试在每一行放置皇后,直到达到最后一行。每次放置皇后时,需要检查当前列、两个对角线是否被占用。
-
如果某一行可以放置皇后,将皇后位置记录在整数数组中,并更新列、对角线的占用情况。
-
继续递归到下一行,重复相同的过程。
-
当放置完成所有行时,计数结果加1,表示找到了一种解法。
-
回溯到上一行,撤销当前行的皇后放置,继续尝试下一列。
-
重复上述步骤,直到找到所有解法。
C++ 版本的解题思路
C++ 版本的解决方案也使用深度优先搜索(DFS)和回溯法来解决 N 皇后问题。以下是解题思路的关键步骤:
-
使用位运算来高效地记录列、两个对角线是否被占用。其中,列使用一个整数表示,每一位表示一列是否被占用;两个对角线也分别使用整数来表示。
-
从第一行开始,递归尝试在每一行放置皇后,直到达到最后一行。在每一行,通过位运算来检查当前列、两个对角线是否被占用。
-
如果某一行可以放置皇后,使用位运算将皇后位置标记为被占用,并继续递归到下一行。
-
当放置完成所有行时,计数结果加1,表示找到了一种解法。
-
回溯到上一行,撤销当前行的皇后放置,继续尝试下一列。
-
重复上述步骤,直到找到所有解法。
总的来说,这些版本的解题思路都涉及深度优先搜索和回溯,同时使用不同的数据结构和语言特性来实现相同的算法。理解递归、回溯以及位运算对于理解这些解决方案非常重要。
代码
Go
// 解法二,DFS 回溯法
func totalNQueens(n int) int {
// 创建并初始化用于记录列、两个对角线是否被占用的布尔数组,
// 以及记录每行皇后位置的数组,以及结果的变量
col, dia1, dia2, row, res := make([]bool, n), make([]bool, 2*n-1), make([]bool, 2*n-1), []int{}, 0
// 调用递归函数放置皇后并计算结果
putQueen52(n, 0, &col, &dia1, &dia2, &row, &res)
// 返回结果
return res
}
// 尝试在一个n皇后问题中, 摆放第index行的皇后位置
func putQueen52(n, index int, col, dia1, dia2 *[]bool, row *[]int, res *int) {
// 当摆放完成所有行时,计数结果加1
if index == n {
*res++
return
}
// 遍历当前行的每一列,尝试放置皇后
for i := 0; i < n; i++ {
// 检查当前列、两个对角线是否被占用
if !(*col)[i] && !(*dia1)[index+i] && !(*dia2)[index-i+n-1] {
// 如果没有被占用,将皇后放置在当前位置
(*row) = append((*row), i)
(*col)[i] = true
(*dia1)[index+i] = true
(*dia2)[index-i+n-1] = true
// 递归放置下一行的皇后
putQueen52(n, index+1, col, dia1, dia2, row, res)
// 回溯,撤销当前行的皇后放置,继续尝试下一列
(*col)[i] = false
(*dia1)[index+i] = false
(*dia2)[index-i+n-1] = false
(*row) = (*row)[:len(*row)-1]
}
}
return
}
Python
class Solution:
def totalNQueens(self, n: int) -> int:
# 计算可以放置皇后的列的位掩码,limit 为一个 n 位的二进制数,所有位都为 1
limit = (1 << n) - 1
# 调用 process 函数,初始时传入全0的状态,表示没有皇后被放置
return self.process(limit, 0, 0, 0)
def process(self, limit, colLim, leftDiaLim, rightDiaLim):
# 如果所有列都已经放置了皇后,表示找到了一种解法,返回 1
if colLim == limit:
return 1
mostRight = 0
# 计算当前行可以放置皇后的位置,pos 为一个二进制数,1 表示可以放置皇后的位置
pos = limit & (~(colLim | leftDiaLim | rightDiaLim))
res = 0
while pos != 0:
# 取出最右边的 1,表示在该位置放置皇后
mostRight = pos & (~pos + 1)
pos = pos - mostRight
# 递归调用 process 函数,放置下一行的皇后,并累加解的数量
res += self.process(limit, colLim | mostRight, (leftDiaLim | mostRight) << 1, (rightDiaLim | mostRight) >> 1)
# 返回总解的数量
return res
Java
class Solution {
public int totalNQueens(int n) {
boolean[] col = new boolean[n];
boolean[] dia1 = new boolean[2 * n - 1];
boolean[] dia2 = new boolean[2 * n - 1];
int[] row = new int[n];
int[] res = new int[1];
putQueen(n, 0, col, dia1, dia2, row, res);
return res[0];
}
private void putQueen(int n, int index, boolean[] col, boolean[] dia1, boolean[] dia2, int[] row, int[] res) {
if (index == n) {
res[0]++;
return;
}
for (int i = 0; i < n; i++) {
if (!col[i] && !dia1[index + i] && !dia2[index - i + n - 1]) {
row[index] = i;
col[i] = true;
dia1[index + i] = true;
dia2[index - i + n - 1] = true;
putQueen(n, index + 1, col, dia1, dia2, row, res);
col[i] = false;
dia1[index + i] = false;
dia2[index - i + n - 1] = false;
}
}
}
}
Cpp
class Solution {
public:
int totalNQueens(int n) {
// 调用 solve 函数,初始时传入全0的状态,表示没有皇后被放置
return solve(n, 0, 0, 0, 0);
}
int solve(int n, int row, int columns, int diagonals1, int diagonals2) {
// 如果已经放置了 n 个皇后,表示找到了一种解法,返回 1
if (row == n) {
return 1;
} else {
int count = 0;
// 计算当前行可用的位置,通过位运算得到一个二进制数,1 表示可以放置皇后的位置
int availablePositions = ((1 << n) - 1) & (~(columns | diagonals1 | diagonals2));
// 遍历所有可用的位置
while (availablePositions != 0) {
// 取出最低位的 1,表示在该位置放置皇后
int position = availablePositions & (-availablePositions);
// 将该位置从可用位置中移除
availablePositions = availablePositions & (availablePositions - 1);
// 递归调用 solve 函数,放置下一行的皇后,并累加解的数量
count += solve(n, row + 1, columns | position, (diagonals1 | position) << 1, (diagonals2 | position) >> 1);
}
// 返回总解的数量
return count;
}
}
};
当然,让我们分别介绍每个版本的代码以及它们所需的基础知识:
Go 版本
Go 版本的代码是一个使用深度优先搜索(DFS)和回溯法的解决方案,用于解决 N 皇后问题。以下是代码中涉及的基础知识:
-
数组和切片:Go 中的数组和切片是重要的数据结构,用于存储和处理数据。在这个问题中,使用了多个布尔数组来跟踪已占用的列和对角线,以及一个整数切片来记录每行的皇后位置。
-
递归和回溯:该解决方案使用递归来尝试放置皇后,并通过回溯来撤销不可行的解决方案。递归是解决 N 皇后问题的关键。
-
位运算:位运算用于快速检查列、对角线是否被占用,以及在哪里放置皇后。这是该算法的关键部分。
Python 版本
Python 版本的代码也是一个使用深度优先搜索(DFS)和回溯法的解决方案。以下是代码中涉及的基础知识:
-
递归和回溯:和 Go 版本一样,Python 版本也使用递归来尝试放置皇后,并通过回溯来撤销不可行的解决方案。递归是解决 N 皇后问题的关键。
-
位运算:位运算用于快速检查列、对角线是否被占用,以及在哪里放置皇后。这是该算法的关键部分。
Java 版本
Java 版本的代码也是一个使用深度优先搜索(DFS)和回溯法的解决方案。以下是代码中涉及的基础知识:
-
数组和列表:Java 中的数组和列表(ArrayList)用于存储和处理数据。在这个问题中,使用了多个布尔数组来跟踪已占用的列和对角线,以及一个整数数组来记录每行的皇后位置。
-
递归和回溯:该解决方案使用递归来尝试放置皇后,并通过回溯来撤销不可行的解决方案。递归是解决 N 皇后问题的关键。
C++ 版本
C++ 版本的代码也是一个使用深度优先搜索(DFS)和回溯法的解决方案。以下是代码中涉及的基础知识:
-
位运算:C++ 版本中使用了位运算来快速检查列、对角线是否被占用,以及在哪里放置皇后。这是该算法的关键部分。
-
递归和回溯:该解决方案使用递归来尝试放置皇后,并通过回溯来撤销不可行的解决方案。递归是解决 N 皇后问题的关键。
总的来说,无论使用哪种编程语言,解决 N 皇后问题的关键概念包括递归、回溯和位运算。理解这些概念将有助于理解和实现这些代码。
53. Maximum Subarray
题目
Given an integer array nums, find the contiguous subarray (containing at least one number) which has the largest sum and return its sum.
Example:
Input: [-2,1,-3,4,-1,2,1,-5,4],
Output: 6
Explanation: [4,-1,2,1] has the largest sum = 6.
Follow up:
If you have figured out the O(n) solution, try coding another solution using the divide and conquer approach, which is more subtle.
题目大意
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
解题思路
- 这一题可以用 DP 求解也可以不用 DP。
- 题目要求输出数组中某个区间内数字之和最大的那个值。
dp[i]表示[0,i]区间内各个子区间和的最大值,状态转移方程是dp[i] = nums[i] + dp[i-1] (dp[i-1] > 0),dp[i] = nums[i] (dp[i-1] ≤ 0)。
Go版本:
- 定义maxSubArray函数,参数为nums切片。
- 定义tmp和m变量,分别表示当前子数组之和和最大子数组之和。m初始化为nums[0]。
- 遍历nums,用tmp累加当前元素。
- 比较m和tmp,通过max函数取较大值赋给m。
- 如果tmp<0,通过max函数将tmp赋为0。
- 循环结束后返回m。
Python版本:
- 定义maxSubArray函数,参数为nums列表。
- 定义tmp和m变量,分别表示当前子数组之和和最大子数组之和。m初始化为nums[0]。
- 遍历nums,用tmp累加当前元素。
- 比较m和tmp,通过内置max函数取较大值赋给m。
- 如果tmp<0,通过max函数将tmp赋为0。
- 循环结束后返回m。
Java版本:
- 定义maxSubArray方法,参数为nums数组。
- 定义tmp和m变量,分别表示当前子数组之和和最大子数组之和。m初始化为nums[0]。
- 遍历nums,用tmp累加当前元素。
- 比较m和tmp,通过Math.max取较大值赋给m。
- 如果tmp<0,通过Math.max将tmp赋为0。
- 循环结束后返回m。
C++版本:
- 定义maxSubArray方法,参数为nums向量。
- 定义tmp和m变量,分别表示当前子数组之和和最大子数组之和。m初始化为nums[0]。
- 遍历nums,用tmp累加当前元素。
- 比较m和tmp,通过max方法取较大值赋给m。
- 如果tmp<0,通过max方法将tmp赋为0。
- 循环结束后返回m。
核心思路都是一样的,主要区别在语法细节上,利用本地语言特性进行优化。
代码
Go
// 定义一个名为 maxSubArray 的函数,接受一个整数数组 nums 作为参数,返回最大子数组和。
func maxSubArray(nums []int) int {
// 如果数组为空,直接返回 0。
if len(nums) == 0 {
return 0
}
// 初始化一个临时变量 tmp 和最大子数组和 m,初始值为数组的第一个元素。
var tmp = 0
var m = nums[0]
// 遍历整个数组。
for i := 0; i < len(nums); i++ {
// 更新临时变量 tmp,将当前元素加入其中。
tmp += nums[i]
// 更新最大子数组和 m,取当前的 m 和 tmp 的较大值。
m = max(m, tmp)
// 如果 tmp 小于 0,将 tmp 重置为 0,因为负数不会对最大子数组和产生正面影响。
tmp = max(tmp, 0)
}
// 返回最大子数组和 m。
return m
}
// 定义一个名为 max 的辅助函数,接受两个整数参数 a 和 b,返回较大的整数。
func max(a, b int) int {
// 如果 a 大于 b,返回 a,否则返回 b。
if a > b {
return a
}
return b
}
Python
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
# 如果数组为空,直接返回0。
if not nums:
return 0
# 初始化一个临时变量 tmp 和最大子数组和 m,初始值为数组的第一个元素。
tmp = 0
m = nums[0]
# 遍历整个数组。
for num in nums:
# 更新临时变量 tmp,将当前元素加入其中。
tmp += num
# 更新最大子数组和 m,取当前的 m 和 tmp 的较大值。
m = max(m, tmp)
# 如果 tmp 小于 0,将 tmp 重置为 0,因为负数不会对最大子数组和产生正面影响。
tmp = max(tmp, 0)
# 返回最大子数组和 m。
return m
Java
class Solution {
public int maxSubArray(int[] nums) {
// 如果数组为空,直接返回0。
if (nums.length == 0) {
return 0;
}
// 初始化一个临时变量 tmp 和最大子数组和 m,初始值为数组的第一个元素。
int tmp = 0;
int m = nums[0];
// 遍历整个数组。
for (int i = 0; i < nums.length; i++) {
// 更新临时变量 tmp,将当前元素加入其中。
tmp += nums[i];
// 更新最大子数组和 m,取当前的 m 和 tmp 的较大值。
m = Math.max(m, tmp);
// 如果 tmp 小于 0,将 tmp 重置为 0,因为负数不会对最大子数组和产生正面影响。
tmp = Math.max(tmp, 0);
}
// 返回最大子数组和 m。
return m;
}
}
Cpp
class Solution {
public:
int maxSubArray(vector& nums) {
// 如果数组为空,直接返回0。
if (nums.empty()) {
return 0;
}
// 初始化一个临时变量 tmp 和最大子数组和 m,初始值为数组的第一个元素。
int tmp = 0;
int m = nums[0];
// 遍历整个数组。
for (int num : nums) {
// 更新临时变量 tmp,将当前元素加入其中。
tmp += num;
// 更新最大子数组和 m,取当前的 m 和 tmp 的较大值。
m = max(m, tmp);
// 如果 tmp 小于 0,将 tmp 重置为 0,因为负数不会对最大子数组和产生正面影响。
tmp = max(tmp, 0);
}
// 返回最大子数组和 m。
return m;
}
};
基础知识
对于Go版本:
- 函数定义:Go语言中使用func关键字定义函数,括号内参数列表,大括号内函数体。
- 返回值:Go函数可以只返回一个值,使用return语句。
- 切片操作:nums []int定义一个int切片,len(nums)获取切片长度,nums[i]访问切片元素。
- if条件判断:if a > b {} else {}。
- for循环:for i := 0; i < len(nums); i++ {}。
- 变量定义:var tmp int 定义临时变量。
- 取最大值:调用max函数比较a,b大小返回较大值。
对于Python版本:
- 函数定义:使用def定义函数,参数列表中的self代表类内方法。
- 返回值:使用 return 语句返回值。
- 列表操作:nums作为列表参数,len(nums)获取长度,num遍历列表元素。
- if条件判断:if not nums: 判断空列表。
- 取最大值:调用内置max函数比较两个值。
对于Java版本:
- 方法定义:public类型说明方法访问权限,int返回值类型。
- 数组操作:nums.length获取数组长度,nums[i]访问元素。
- if条件判断:if(nums.length == 0)。
- for循环:for(初始化;条件;迭代)。
- 取最大值:Math.max(a, b)调用工具类方法。
对于C++版本:
- 方法定义:class内定义,int返回类型。
- 向量操作:nums作为向量参数,empty()判断空,num遍历。
- if条件判断:if(nums.empty())。
- for循环:for(元素类型 元素:容器)。
- 取最大值:调用max方法比较两个值。
主要就是函数/方法定义,基础数据结构的操作,流程控制语言(if/for)的使用,数值比较取最大值。掌握了这些基础语法,就可以编写出算法代码。
54. Spiral Matrix
题目
Given a matrix of m x n elements (m rows, n columns), return all elements of the matrix in spiral order.
Example 1:
Input:
[
[ 1, 2, 3 ],
[ 4, 5, 6 ],
[ 7, 8, 9 ]
]
Output: [1,2,3,6,9,8,7,4,5]
Example 2:
Input:
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9,10,11,12]
]
Output: [1,2,3,4,8,12,11,10,9,5,6,7]
题目大意
给定一个包含 m x n 个元素的矩阵(m 行, n 列),请按照顺时针螺旋顺序,返回矩阵中的所有元素。
解题思路
- 给出一个二维数组,按照螺旋的方式输出
- 解法一:需要注意的是特殊情况,比如二维数组退化成一维或者一列或者一个元素。注意了这些情况,基本就可以一次通过了。
- 解法二:提前算出一共多少个元素,一圈一圈地遍历矩阵,停止条件就是遍历了所有元素(count == sum)
Go版本:
- 定义方向向量数组spDir,表示向右、下、左、上的方向
- 使用visit矩阵标记已访问位置
- 根据round变量判断方向,初始化为向右
- 遍历矩阵,每次根据方向向量更新坐标
- 判断是否到达转角,是则round自增变换方向
- 判断坐标是否出界
- 判断该位置是否已访问,未访问则标记并添加到结果
- 根据当前方向判断周围是否访问过,是则改变方向
Python版本:
- 定义左右上下边界,表示当前遍历的范围
- 通过不断改变边界坐标实现螺旋遍历
- 从左到右遍历上边界,然后上边界下移
- 从上到下遍历右边界,然后右边界左移
- 判断边界是否相遇,相遇则结束
- 从右到左遍历下边界,然后下边界上移
- 从下到上遍历左边界,然后左边界右移
Java版本:
- 定义dr、dc数组表示四个方向
- 使用visited数组标记已访问位置
- di变量控制方向,每次遍历后自增改变方向
- 根据方向数组计算下一个遍历位置
- 如果下个位置合法且未访问过,则移动坐标
- 否则改变di继续遍历
C++版本:
- 定义方向数组dr、dc
- 使用visited向量标记已访问位置
- di变量控制方向,转角时自增di改变方向
- 根据dr、dc计算下个遍历位置
- 如果合法且未访问,移动坐标
- 否则改变方向继续遍历
代码
Go
// 定义一个螺旋遍历二维矩阵的函数
func spiralOrder(matrix [][]int) []int {
// 如果矩阵为空,直接返回空切片
if len(matrix) == 0 {
return []int{}
}
// 定义一个结果切片
res := []int{}
// 如果矩阵只有一行,直接遍历添加到结果切片
if len(matrix) == 1 {
for i := 0; i < len(matrix[0]); i++ {
res = append(res, matrix[0][i])
}
return res
}
// 如果矩阵只有一列,直接遍历添加到结果切片
if len(matrix[0]) == 1 {
for i := 0; i < len(matrix); i++ {
res = append(res, matrix[i][0])
}
return res
}
// 定义一个访问矩阵,标记已访问过的元素
visit, m, n, round, x, y, spDir := make([][]int, len(matrix)), len(matrix), len(matrix[0]), 0, 0, 0, [][]int{
[]int{0, 1}, // 向右的方向向量
[]int{1, 0}, // 向下的方向向量
[]int{0, -1}, // 向左的方向向量
[]int{-1, 0}, // 向上的方向向量
}
// 初始化访问矩阵
for i := 0; i < m; i++ {
visit[i] = make([]int, n)
}
// 标记当前位置为已访问
visit[x][y] = 1
// 将当前位置元素添加到结果切片
res = append(res, matrix[x][y])
// 开始遍历矩阵
for i := 0; i < m*n; i++ {
// 根据当前方向向量更新x、y坐标
x += spDir[round%4][0]
y += spDir[round%4][1]
// 如果遍历到转角,改变方向
if (x == 0 && y == n-1) || (x == m-1 && y == n-1) || (y == 0 && x == m-1) {
round++
}
// 检查坐标是否出界
if x > m-1 || y > n-1 || x < 0 || y < 0 {
return res
}
// 如果当前位置未访问过
if visit[x][y] == 0 {
// 标记为已访问
visit[x][y] = 1
// 添加到结果切片
res = append(res, matrix[x][y])
}
// 根据当前方向判断是否需要改变方向
switch round % 4 {
case 0: // 向右
if y+1 <= n-1 && visit[x][y+1] == 1 { // 右侧已访问过
round++ // 改变方向
continue
}
case 1: // 向下
if x+1 <= m-1 && visit[x+1][y] == 1 { // 下方已访问过
round++
continue
}
case 2: // 向左
if y-1 >= 0 && visit[x][y-1] == 1 { // 左侧已访问过
round++
continue
}
case 3: // 向上
if x-1 >= 0 && visit[x-1][y] == 1 { // 上方已访问过
round++
continue
}
}
}
// 返回结果切片
return res
}
Python
python
class Solution:
def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
# 定义左、上边界
left, top = 0, 0
# 定义右、下边界
bottom, right = len(matrix), len(matrix[0])
# 结果列表
ans = []
# 当左右边界未相遇,上下边界未相遇时
while left < right and top < bottom:
# 从左到右遍历上边界
for i in range(left, right):
ans.append(matrix[top][i])
# 上边界下移
top += 1
# 从上到下遍历右边界
for i in range(top, bottom):
ans.append(matrix[i][right - 1])
# 右边界左移
right -= 1
# 如果边界相遇,结束循环
if left >= right or top >= bottom:
break
# 从右到左遍历下边界
for i in range(right - 1, left - 1, -1):
ans.append(matrix[bottom - 1][i])
# 下边界上移
bottom -= 1
# 从下到上遍历左边界
for i in range(bottom - 1, top - 1, -1):
ans.append(matrix[i][left])
# 左边界右移
left += 1
return ans
Java
import java.util.ArrayList;
import java.util.List;
class Solution {
public List spiralOrder(int[][] matrix) {
List res = new ArrayList<>();
if(matrix.length == 0) return res;
int m = matrix.length;
int n = matrix[0].length;
boolean[][] visited = new boolean[m][n];
int[] dr = {0, 1, 0, -1}; // 右、下、左、上
int[] dc = {1, 0, -1, 0};
int r = 0, c = 0, di = 0;
for(int i = 0; i < m * n; i++) {
res.add(matrix[r][c]);
visited[r][c] = true;
int cr = r + dr[di];
int cc = c + dc[di];
if(0 <= cr && cr < m && 0 <= cc && cc < n && !visited[cr][cc]) {
r = cr;
c = cc;
}
else {
di = (di + 1) % 4; // 改变方向
r += dr[di];
c += dc[di];
}
}
return res;
}
}
Cpp
#include
using namespace std;
class Solution {
public:
vector spiralOrder(vector>& matrix) {
vector res;
if (matrix.empty()) return res;
int m = matrix.size(), n = matrix[0].size();
vector> visited(m, vector(n));
int dr[4] = {0, 1, 0, -1}; // 右、下、左、上
int dc[4] = {1, 0, -1, 0};
int r = 0, c = 0, di = 0;
for (int i = 0; i < m * n; i++) {
res.push_back(matrix[r][c]);
visited[r][c] = true;
int cr = r + dr[di], cc = c + dc[di];
if (0 <= cr && cr < m && 0 <= cc && cc < n && !visited[cr][cc]) {
r = cr; c = cc;
}
else {
di = (di + 1) % 4; // 改变方向
r += dr[di]; c += dc[di];
}
}
return res;
}
};
基础知识
- Go版本
- 使用方向向量控制遍历顺序,根据round变量控制方向
- 使用visit矩阵记录已访问位置,避免重复访问
- 注意处理边界条件,如矩阵只有一行或一列的情况
- Python版本
- 使用左右上下边界控制遍历范围
- 通过改变边界坐标实现螺旋遍历
- 注意处理边界相遇的情况
- Java版本
- 使用方向数组dr、dc控制遍历方向
- visited数组记录已访问位置
- 改变di控制方向,转角时di自增实现方向改变
- C++版本
- 与Java版本类似,使用方向数组dr、dc
- visited向量记录已访问位置
- 改变di改变方向,转角时自增di
综合来说,螺旋遍历矩阵需要注意边界处理,并通过控制方向实现螺旋遍历顺序。记录已访问位置很重要,避免重复访问。
55. Jump Game
题目
Given an array of non-negative integers, you are initially positioned at the first index of the array.
Each element in the array represents your maximum jump length at that position.
Determine if you are able to reach the last index.
Example 1:
Input: [2,3,1,1,4]
Output: true
Explanation: Jump 1 step from index 0 to 1, then 3 steps to the last index.
Example 2:
Input: [3,2,1,0,4]
Output: false
Explanation: You will always arrive at index 3 no matter what. Its maximum
jump length is 0, which makes it impossible to reach the last index.
题目大意
给定一个非负整数数组,最初位于数组的第一个位置。数组中的每个元素代表在该位置可以跳跃的最大长度。判断是否能够到达最后一个位置。
解题思路
- 给出一个非负数组,要求判断从数组 0 下标开始,能否到达数组最后一个位置。
- 这一题比较简单。如果某一个作为
起跳点的格子可以跳跃的距离是n,那么表示后面n个格子都可以作为起跳点。可以对每一个能作为起跳点的格子都尝试跳一次,把能跳到最远的距离maxJump不断更新。如果可以一直跳到最后,就成功了。如果中间有一个点比maxJump还要大,说明在这个点和 maxJump 中间连不上了,有些点不能到达最后一个位置。
当然,我来分别介绍每个版本的解题思路:
Go 版本解题思路:
- 题目要求判断是否能够从第一个位置跳跃到最后一个位置。
- 使用一个变量
maxj来表示当前能够跳到的最远位置,初始值为0。 - 遍历数组中的每个元素,对于每个元素,检查是否能够跳到当前位置(
i > maxj表示无法跳到当前位置,返回false),然后更新maxj为当前位置和当前位置能跳跃的最大距离之间的较大值。 - 如果成功遍历完整个数组,说明可以跳到最后一个位置,返回true。
Python 版本解题思路:
- 同样,题目要求判断是否能够从第一个位置跳跃到最后一个位置。
- 使用变量
max_i来表示当前能够跳到的最远位置,初始值为0。 - 使用
enumerate函数遍历列表,i表示当前位置,jump表示当前位置的跳数。 - 如果
max_i大于等于i并且i + jump大于max_i,则更新max_i为i + jump。 - 最后,判断
max_i是否大于等于最后一个位置i,如果是,则返回True,否则返回False。
Java 版本解题思路:
- 题目要求判断是否能够从第一个位置跳跃到最后一个位置。
- 使用变量
max_i来表示当前能够跳到的最远位置,初始值为0。 - 使用
for循环遍历数组,i表示当前位置。 - 如果
max_i大于等于i并且i + nums[i]大于max_i,则更新max_i为i + nums[i]。 - 最后,判断
max_i是否大于等于数组的最后一个位置,如果是,则返回True,否则返回False。
C++ 版本解题思路:
- 同样,题目要求判断是否能够从第一个位置跳跃到最后一个位置。
- 使用变量
max_i来表示当前能够跳到的最远位置,初始值为0。 - 使用
for循环遍历向量,i表示当前位置。 - 如果
max_i大于等于i并且i + nums[i]大于max_i,则更新max_i为i + nums[i]。 - 最后,判断
max_i是否大于等于向量的最后一个位置,如果是,则返回True,否则返回False。
这些解题思路都是基于贪心算法的思想,即不断更新能够跳到的最远位置,最终判断是否能够跳到最后一个位置。希望这些解题思路能够帮助您理解每个版本的解决方案。如果您有更多问题,请随时提出。
代码
func canJump(nums []int) bool {
maxj := 0 // 初始化一个变量 maxj,表示当前能够跳到的最远的位置
for i := 0; i < len(nums); i++ { // 遍历数组中的每个元素
if i > maxj { // 如果当前索引 i 大于 maxj,说明无法跳到当前位置
return false // 返回 false,表示无法跳到末尾
}
maxj = max(maxj, nums[i]+i) // 更新 maxj,取当前 maxj 和当前位置能跳到的最远位置的较大值
}
return true // 如果成功遍历完数组,说明可以跳到末尾,返回 true
}
func max(a, b int) int {
if a > b {
return a
}
return b
}
Python
class Solution:
def canJump(self, nums) :
max_i = 0 # 初始化当前能到达最远的位置,开始时为0
for i, jump in enumerate(nums): # 使用enumerate函数遍历列表,i为当前位置,jump是当前位置的跳数
if max_i >= i and i + jump > max_i: # 如果当前位置能到达,并且当前位置+跳数>最远位置
max_i = i + jump # 更新最远能到达位置
return max_i >= i # 判断最远能到达位置是否大于等于最后一个位置i,返回True或False
Java
class Solution {
public boolean canJump(int[] nums) {
int max_i = 0; // 初始化当前能到达最远的位置,开始时为0
for (int i = 0; i < nums.length; i++) {
if (max_i >= i && i + nums[i] > max_i) {
max_i = i + nums[i]; // 更新最远能到达位置
}
}
return max_i >= nums.length - 1; // 判断最远能到达位置是否大于等于最后一个位置
}
}
Cpp
class Solution {
public:
bool canJump(vector& nums) {
int max_i = 0; // 初始化当前能到达最远的位置,开始时为0
for (int i = 0; i < nums.size(); i++) {
if (max_i >= i && i + nums[i] > max_i) {
max_i = i + nums[i]; // 更新最远能到达位置
}
}
return max_i >= nums.size() - 1; // 判断最远能到达位置是否大于等于最后一个位置
}
};
当然,我可以使用中文来详细介绍每个版本的所需基础知识。
Go 版本:
-
数组和切片:了解如何声明和使用数组和切片。在Go中,数组是固定长度的,而切片是动态数组。
-
循环和迭代:理解
for循环和如何遍历切片或数组。 -
函数:熟悉如何定义和调用函数。在这个示例中,有两个函数,
canJump和max。
Python 版本:
-
列表和迭代:了解如何声明和操作Python的列表(List)数据结构。列表可以包含不同类型的元素。
-
enumerate函数:了解
enumerate函数,它用于同时遍历列表的索引和值。 -
条件语句:理解
if条件语句的使用,以及如何根据条件执行不同的操作。
Java 版本:
-
数组和循环:了解如何声明和操作Java数组。Java中数组的大小是固定的。
-
for循环:理解
for循环的使用,以及如何遍历数组。 -
条件语句:熟悉
if条件语句的使用,以根据条件执行不同的操作。
C++ 版本:
-
向量(Vector):了解如何使用C++的向量容器,它类似于动态数组。向量可以自动调整大小。
-
for循环:理解
for循环的使用,以及如何遍历向量。 -
条件语句:熟悉
if条件语句的使用,以根据条件执行不同的操作。
这些基础知识是理解和编写这些版本中的解决方案所必需的。如果您需要更详细的解释或有其他问题,请随时提出。
56. Merge Intervals
题目
Given a collection of intervals, merge all overlapping intervals.
Example 1:
Input: [[1,3],[2,6],[8,10],[15,18]]
Output: [[1,6],[8,10],[15,18]]
Explanation: Since intervals [1,3] and [2,6] overlaps, merge them into [1,6].
Example 2:
Input: [[1,4],[4,5]]
Output: [[1,5]]
Explanation: Intervals [1,4] and [4,5] are considered overlapping.
题目大意
合并给的多个区间,区间有重叠的要进行区间合并。
解题思路
Go 版本:
-
首先,通过遍历所有区间,找到它们的最大起点和最小终点,以便后续数组的初始化。
-
创建两个数组
start和end,用于统计每个起始点和结束点的出现次数。 -
第二次遍历区间列表,将每个区间的起始点和结束点在相应的数组中加一。
-
使用
prefix变量来记录当前活跃的区间数,通过prefix的值可以确定是否开始一个新的合并区间。 -
最后,根据
prefix的值,将合并后的区间加入到答案中。
Python 版本:
-
首先,通过遍历所有区间,找到它们的最大起点和最小终点,以便后续列表的初始化。
-
创建两个列表
start和end,用于统计每个起始点和结束点的出现次数。 -
第二次遍历区间列表,将每个区间的起始点和结束点在相应的列表中加一。
-
使用
prefix变量来记录当前活跃的区间数,通过prefix的值可以确定是否开始一个新的合并区间。 -
最后,根据
prefix的值,将合并后的区间加入到答案中。
Java 版本:
-
首先,通过遍历所有区间,找到它们的最大起点和最小终点,以便后续数组的初始化。
-
创建两个数组
start和end,用于统计每个起始点和结束点的出现次数。 -
第二次遍历区间列表,将每个区间的起始点和结束点在相应的数组中加一。
-
使用
prefix变量来记录当前活跃的区间数,通过prefix的值可以确定是否开始一个新的合并区间。 -
最后,将合并后的区间加入到答案数组中。
C++ 版本:
-
首先,通过遍历所有区间,找到它们的最大起点和最小终点,以便后续向量的初始化。
-
创建两个向量
start和end,用于统计每个起始点和结束点的出现次数。 -
第二次遍历区间列表,将每个区间的起始点和结束点在相应的向量中加一。
-
使用
prefix变量来记录当前活跃的区间数,通过prefix的值可以确定是否开始一个新的合并区间。 -
最后,将合并后的区间加入到答案向量中。
总的来说,这些版本的解决方案都采用了相似的核心思想:先找到区间的最大起点和最小终点,然后统计每个起始点和结束点的出现次数,最后根据这些信息进行合并操作。
代码
Go
func merge(intervals [][]int) [][]int {
MAX := math.MinInt
MIN := math.MaxInt
left := -1
prefix := 0
for _, temp := range intervals {
x := temp[0]
y := temp[1]
if x < MIN {
MIN = x
}
if y > MAX {
MAX = y
}
}
start := make([]int, MAX+1)
end := make([]int, MAX+1)
for i := 0; i < len(intervals); i++ {
x := intervals[i][0]
y := intervals[i][1]
start[x]++
end[y]++
}
var ans [][]int
size := 0
for i := MIN; i <= MAX; i++ {
if start[i] > 0 {
prefix += start[i]
if prefix == start[i] {
left = i
}
}
if end[i] > 0 {
prefix -= end[i]
if prefix == 0 {
ans = append(ans, []int{left, i})
size++
}
}
}
return ans
}
Python
class Solution:
def merge(self, intervals: List[List[int]]) -> List[List[int]]:
MAX = float('-inf')
MIN = float('inf')
left = -1
prefix = 0
for temp in intervals:
x = temp[0]
y = temp[1]
if x < MIN:
MIN = x
if y > MAX:
MAX = y
start = [0] * (MAX + 1)
end = [0] * (MAX + 1)
for i in range(len(intervals)):
x = intervals[i][0]
y = intervals[i][1]
start[x] += 1
end[y] += 1
ans = []
size = 0
for i in range(MIN, MAX + 1):
if start[i] > 0:
prefix += start[i]
if prefix == start[i]:
left = i
if end[i] > 0:
prefix -= end[i]
if prefix == 0:
ans.append([left, i])
size += 1
return ans
Java
class Solution {
static int[][] ans = new int[10001][2]; // 创建一个静态二维数组用于存储合并后的区间
public int[][] merge(int[][] intervals) {
int MAX = Integer.MIN_VALUE, MIN = Integer.MAX_VALUE, left = -1, prefix = 0;
for (int[] temp : intervals) {
int x = temp[0];
int y = temp[1];
if (x < MIN) MIN = x;
if (y > MAX) MAX = y;
}
int[] start = new int[MAX+1], end = new int[MAX+1];
// 统计每个起始点和结束点出现的次数
for (int i = 0; i < intervals.length; i++) {
int x = intervals[i][0];
int y = intervals[i][1];
start[x]++;
end[y]++;
}
int size = 0;
for (int i = MIN; i <= MAX; i++) {
if (start[i] > 0) {
prefix += start[i];
if (prefix == start[i]) {
left = i;
}
}
if (end[i] > 0) {
prefix -= end[i];
if (prefix == 0) {
ans[size++] = new int[]{left, i}; // 找到一个合并后的区间
}
}
}
return Arrays.copyOfRange(ans, 0, size); // 返回合并后的结果数组
}
}
Cpp
class Solution {
public:
vector> merge(vector>& intervals) {
int MAX = INT_MIN;
int MIN = INT_MAX;
int left = -1;
int prefix = 0;
for (const vector& temp : intervals) {
int x = temp[0];
int y = temp[1];
if (x < MIN) MIN = x;
if (y > MAX) MAX = y;
}
vector start(MAX + 1, 0);
vector end(MAX + 1, 0);
for (int i = 0; i < intervals.size(); i++) {
int x = intervals[i][0];
int y = intervals[i][1];
start[x]++;
end[y]++;
}
vector> ans;
int size = 0;
for (int i = MIN; i <= MAX; i++) {
if (start[i] > 0) {
prefix += start[i];
if (prefix == start[i]) {
left = i;
}
}
if (end[i] > 0) {
prefix -= end[i];
if (prefix == 0) {
ans.push_back({left, i});
size++;
}
}
}
return ans;
}
};
每个版本的解决方案以及所需的基础知识。
Go 版本:
这个 Go 版本的解决方案使用了以下重要的基础知识:
-
切片(Slices)和数组(Arrays): Go 中的切片和数组是用来存储多个相同类型的数据的数据结构。在这个解决方案中,切片用于存储合并后的区间。
-
循环(Loop): 使用
for循环遍历区间列表和其他数据结构。 -
条件语句(Conditional Statements): 使用条件语句来处理不同的情况,例如合并区间。
-
切片追加(Slice Append): 使用
append函数来动态扩展切片以添加合并后的区间。
Python 版本:
这个 Python 版本的解决方案使用了以下基础知识:
-
列表(Lists): 列表是 Python 中的一种数据结构,用于存储多个对象。在这个解决方案中,列表被用于存储合并后的区间。
-
循环(Loop): 使用
for循环来遍历区间列表和其他数据结构。 -
条件语句(Conditional Statements): 使用条件语句来处理不同的情况,例如合并区间。
-
列表追加(List Append): 使用
append方法来动态扩展列表以添加合并后的区间。
Java 版本:
这个 Java 版本的解决方案使用了以下基础知识:
-
类和对象(Classes and Objects): Java 是面向对象的编程语言,这个解决方案中创建了一个名为
Solution的类来解决问题。 -
数组(Arrays): 使用数组来存储合并后的区间。
-
循环(Loop): 使用
for循环来遍历区间列表和其他数据结构。 -
条件语句(Conditional Statements): 使用条件语句来处理不同的情况,例如合并区间。
-
静态数组和动态数组(Static and Dynamic Arrays): 静态数组是提前定义大小的数组,而动态数组可以根据需要动态分配大小。
C++ 版本:
这个 C++ 版本的解决方案使用了以下基础知识:
-
类和对象(Classes and Objects): C++ 是面向对象的编程语言,这个解决方案中创建了一个名为
Solution的类来解决问题。 -
向量(Vectors): 使用向量来存储合并后的区间。向量是 C++ 标准库提供的动态数组数据结构。
-
循环(Loop): 使用
for循环来遍历区间列表和其他数据结构。 -
条件语句(Conditional Statements): 使用条件语句来处理不同的情况,例如合并区间。