APScheduler框架使用
目录
- 概述
- 架构
- 重要概念
-
- Job 作业
- Trigger 触发器
- Executor 执行器
- Jobstore
- Event 事件
- 调度器
- 工作流程
- 使用
概述
APScheduler(advanceded python scheduler)基于Quartz的一个Python定时任务框架,实现了Quartz的所有功能,使用起来十分方便。提供了基于日期、固定时间间隔以及crontab类型的任务,并且可以持久化任务。基于这些功能,我们可以很方便的实现一个Python定时任务系统。
它有以下三个特点:
- 类似于 Liunx Cron 的调度程序(可选的开始/结束时间)
- 基于时间间隔的执行调度(周期性调度,可选的开始/结束时间)
- 一次性执行任务(在设定的日期/时间运行一次任务)
架构
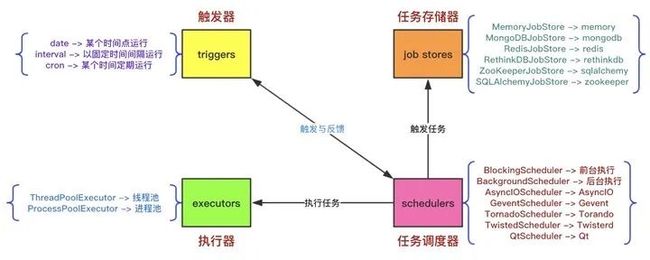
APScheduler有四种组成部分:
- 触发器(trigger) 包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行。除了他们自己初始配置意外,触发器完全是无状态的。
- 作业存储(job store) 存储被调度的作业,默认的作业存储是简单地把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据讲在保存在持久化作业存储时被序列化,并在加载时被反序列化。调度器不能分享同一个作业存储。
- 执行器(executor) 处理作业的运行,他们通常通过在作业中提交制定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。
- 调度器(scheduler) 是其他的组成部分。你通常在应用只有一个调度器,应用的开发者通常不会直接处理作业存储、调度器和触发器,相反,调度器提供了处理这些的合适的接口。配置作业存储和执行器可以在调度器中完成,例如添加、修改和移除作业。通过配置executor、jobstore、trigger,使用线程池(ThreadPoolExecutor默认值20)或进程池(ProcessPoolExecutor 默认值5)并且默认最多3个(max_instances)任务实例同时运行,实现对job的增删改查等调度控制。
重要概念
Job 作业
Job作为APScheduler最小执行单位。创建Job时指定执行的函数,函数中所需参数,Job执行时的一些设置信息。
- id:指定作业的唯一ID
- name:指定作业的名字
- trigger:apscheduler定义的触发器,用于确定Job的执行时间,根据设置的trigger规则,计算得到下次执行此job的时间, 满足时将会执行
- executor:apscheduler定义的执行器,job创建时设置执行器的名字,根据字符串你名字到scheduler获取到执行此job的 执行器,执行job指定的函数
- max_instances:执行此job的最大实例数,executor执行job时,根据job的id来计算执行次数,根据设置的最大实例数来确定是否可执行
- next_run_time:Job下次的执行时间,创建Job时可以指定一个时间[datetime],不指定的话则默认根据trigger获取触发时间
- misfire_grace_time:Job的延迟执行时间,例如Job的计划执行时间是21:00:00,但因服务重启或其他原因导致21:00:31才执行,如果设置此key为40,则该job会继续执行,否则将会丢弃此job
- coalesce:Job是否合并执行,是一个bool值。例如scheduler停止20s后重启启动,而job的触发器设置为5s执行一次,因此此job错过了4个执行时间,如果设置为是,则会合并到一次执行,否则会逐个执行
- func:Job执行的函数
- args:Job执行函数需要的位置参数
- kwargs:Job执行函数需要的关键字参数
Trigger 触发器
Trigger绑定到Job,在scheduler调度筛选Job时,根据触发器的规则计算出Job的触发时间,然后与当前时间比较确定此Job是否会被执行,总之就是根据trigger规则计算出下一个执行时间。
目前APScheduler支持触发器:
- 指定时间的DateTrigger
- 指定间隔时间的IntervalTrigger
- 像Linux的crontab一样的CronTrigger。
- 指定时间的触发器
date定时,作业只执行一次。
如下:
sched.add_job(my_job, 'date', run_date=date(2009, 11, 6), args=['text'])
sched.add_job(my_job, 'date', run_date=datetime(2019, 7, 6, 16, 30, 5), args=['text'])
- 指定间隔时间的触发器
interval间隔调度
- weeks (int) – 间隔几周
- days (int) – 间隔几天
- hours (int) – 间隔几小时
- minutes (int) – 间隔几分钟
- seconds (int) – 间隔多少秒
- start_date (datetime|str) – 开始日期
- end_date (datetime|str) – 结束日期
- timezone (datetime.tzinfo|str) – 时区
如下:
sched.add_job(job_function, 'interval', hours=2)
- crontab表达式的触发器
cron调度
- (int|str) 表示参数既可以是int类型,也可以是str类型
- (datetime | str) 表示参数既可以是datetime类型,也可以是str类型
- year (int|str) – 4-digit year -(表示四位数的年份,如2008年)
- month (int|str) – month (1-12) -(表示取值范围为1-12月)
- day (int|str) – day of the (1-31) -(表示取值范围为1-31日)
- week (int|str) – ISO week (1-53) -(格里历2006年12月31日可以写成2006年-W52-7(扩展形式)或2006W527(紧凑形式))
- day_of_week (int|str) – number or name of weekday (0-6 or
- mon,tue,wed,thu,fri,sat,sun) – (表示一周中的第几天,既可以用0-6表示也可以用其英语缩写表示)
- hour (int|str) – hour (0-23) – (表示取值范围为0-23时)
- minute (int|str) – minute (0-59) – (表示取值范围为0-59分)
- second (int|str) – second (0-59) – (表示取值范围为0-59秒)
- start_date (datetime|str) – earliest possible date/time to trigger on (inclusive) – (表示开始时间)
- end_date (datetime|str) – latest possible date/time to trigger on (inclusive) – (表示结束时间)
- timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations (defaults to scheduler timezone) -(表示时区取值)
CronTrigger可用的表达式:

示例:
# 6-8,11-12月第三个周五 00:00, 01:00, 02:00, 03:00运行
sched.add_job(job_function, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
# 每周一到周五运行 直到2024-05-30 00:00:00
sched.add_job(job_function, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2024-05-30'
Executor 执行器
Executor在scheduler中初始化,另外也可通过scheduler的add_executor动态添加Executor。每个executor都会绑定一个alias,这个作为唯一标识绑定到Job,在实际执行时会根据Job绑定的executor找到实际的执行器对象,然后根据执行器对象执行Job。
Executor的种类会根据不同的调度来选择,如果选择AsyncIO作为调度的库,那么选择AsyncIOExecutor,如果选择tornado作为调度的库,选择TornadoExecutor,如果选择启动进程作为调度,选择ThreadPoolExecutor或者ProcessPoolExecutor都可以。
Executor的选择需要根据实际的scheduler来选择不同的执行器。目前APScheduler支持的Executor:
- executors.asyncio:同步io,阻塞
- executors.gevent:io多路复用,非阻塞
- executors.pool: 线程ThreadPoolExecutor和进
- ProcessPoolExecutor
- executors.twisted:基于事件驱动
Jobstore
Jobstore在scheduler中初始化,另外也可通过scheduler的add_jobstore动态添加Jobstore。每个jobstore都会绑定一个alias,scheduler在Add Job时,根据指定的jobstore在scheduler中找到相应的jobstore,并将job添加到jobstore中。作业存储器决定任务的保存方式, 默认存储在内存中(MemoryJobStore),重启后就没有了。APScheduler支持的任务存储器有:
- jobstores.memory:内存
- jobstores.mongodb:存储在mongodb
- jobstores.redis:存储在redis
- jobstores.rethinkdb:存储在rethinkdb
- jobstores.sqlalchemy:支持sqlalchemy的数据库如mysql,sqlite
- jobstores.zookeeper:zookeeper
不同的任务存储器可以在调度器的配置中进行配置(见调度器)。
Event 事件
vent是APScheduler在进行某些操作时触发相应的事件,用户可以自定义一些函数来监听这些事件,当触发某些Event时,做一些具体的操作。常见的比如。Job执行异常事件 EVENT_JOB_ERROR。Job执行时间错过事件 EVENT_JOB_MISSED。
目前APScheduler定义的Event:
- EVENT_SCHEDULER_STARTED
- EVENT_SCHEDULER_STAR
- EVENT_SCHEDULER_SHUTDOWN
- EVENT_SCHEDULER_PAUSED
- EVENT_SCHEDULER_RESUMED
- EVENT_EXECUTOR_ADDED
- EVENT_EXECUTOR_REMOVED
- EVENT_JOBSTORE_ADDED
- EVENT_JOBSTORE_REMOVED
- EVENT_ALL_JOBS_REMOVED
- EVENT_JOB_ADDED
- EVENT_JOB_REMOVED
- EVENT_JOB_MODIFIED
- EVENT_JOB_EXECUTED
- EVENT_JOB_ERROR
- EVENT_JOB_MISSED
- EVENT_JOB_SUBMITTED
- EVENT_JOB_MAX_INSTANCES
Listener表示用户自定义监听的一些Event,比如当Job触发了EVENT_JOB_MISSED事件时可以根据需求做一些其他处理。
调度器
Scheduler是APScheduler的核心,所有相关组件通过其定义。scheduler启动之后,将开始按照配置的任务进行调度。除了依据所有定义Job的trigger生成的将要调度时间唤醒调度之外。当发生Job信息变更时也会触发调度。
APScheduler支持的调度器方式如下,比较常用的为BlockingScheduler和BackgroundScheduler:
- BlockingScheduler:适用于调度程序是进程中唯一运行的进程,调用start函数会阻塞当前线程,不能立即返回。
- BackgroundScheduler:适用于调度程序在应用程序的后台运行,调用start后主线程不会阻塞。
- AsyncIOScheduler:适用于使用了asyncio模块的应用程序。
- GeventScheduler:适用于使用gevent模块的应用程序。
- TwistedScheduler:适用于构建Twisted的应用程序。
- QtScheduler:适用于构建Qt的应用程序。
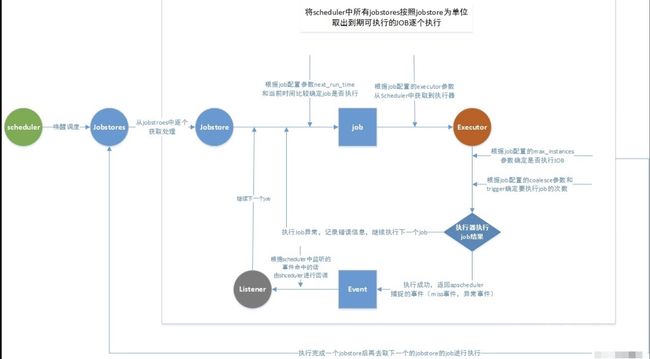
工作流程
Scheduler添加job流程:

Scheduler调度流程:
使用
一个简单的示例如下:
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
# 输出时间
def job():
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
# 创建BlockingScheduler
sched = BlockingScheduler()
# 添加任务
sched.add_job(my_job, 'interval', seconds=5, id='my_job_id')
# 启动任务
sched.start()
主要步骤如下:
- 创建调度器
sched = BlockingScheduler()
- 添加job
第一种方法是最常用的,第二种方法通过声明 job 而不修改应用程序运行时是最为方便的;add_job() 方法返回一个 apscheduler.job.Job 实例,我们可以用它来在之后修改或移除 job;我们可以随时调度 scheduler 里的 job,如果添加 job 时,scheduler 尚未运行,job 会被临时地进行排列,直到 scheduler 启动之后,它的首次运行时间才会被确切地计算出来。
注意:
① 如果你调度的 job 在一个持久化的 job store 里,当你初始化你的应用程序时,你 必须 为 job 定义一个显式的 ID 并使用 replace_existing=True ,否则每次你的应用程序重启时你都会得到那个 job 的一个新副本
② 如果想马上运行 job ,请在添加 job 时省略 trigger 参数
③ 如果我们的执行器或任务储存器是会序列化任务的,那么这些任务就必须符合:1-回调函数必须全局可用;2-回调函数参数必须也是可以被序列化的
- 移除job
当从 scheduler 中移除一个 job 时,它会从关联的 job store 中被移除,不再被执行;有两种途径可以移除 job:
① 通过 job 的 ID 以及 job store 的别名来调用 remove_job() 方法
② 对你在 add_job() 中得到的 job 实例调用 remove() 方法
后者看起来更方便,实际上它要求你必须将调用 add_job() 得到的 Job 实例存储在某个地方;而对于通过 scheduled_job() 装饰器来调度 job 的就只能使用第一种方法;
如果一个 job 完成了调度(例如它的触发器不会再被触发),它会自动被移除。
# 移除job任务
myjob.remove()
bgsched.remove_job(job_id='00001') # jobstore=None
- 暂停和恢复job
# 暂停job
myjob.pause()
# 恢复job
myjob.resume()
- 获取作业调度列表
通过get_jobs方法获取调度列表:bgsched.get_jobs()。
- 修改job
# 修改job相关信息,id不能被修改
myjob.modify(name='modity_name')
- 终止调度
默认情况下,scheduler 会终止其 job store 以及 executor,然后等待所有目前执行的 job 完成后自行终止,如果不想等待可以设置wait为False。
# 终止调度
bgsched.shutdown(wait=False)
- 启动调度
bgsched.start()
注意:有些timezone时区可能会有夏令时的问题;这个可能导致令时切换时,任务不执行或任务执行两次;避免这个问题,可以使用UTC时间,或提前预知并规划好执行的问题。
from pytz import utc
sched = BlockingScheduler(timezone=utc)
参考:
https://blog.51cto.com/u_16147578/6396384
https://zhuanlan.zhihu.com/p/491679794