stack与queue的简单封装
前言: stack与queue即栈和队列,先进后出/先进先出的特性我们早已了然于心, 在学习数据结构时,我们利用c语言实现栈与队列,从结构体写起,利用数组或指针表示他们的数据成员,之后再一个个实现他们的函数接口,简单来说我们是直接手撕栈和队列的。
但对于c++来说,c++提供了模板,提供了标准模板库,利用这些们只需要实现它的特性,然后再封装它即可。
目录
适配器
栈的简单封装
添加容器模板参数(适配器)
队列的简单封装
库中的实现
初识双端队列
在实现之前,我们再来了解一下何为适配器?
适配器
本质上是一种设计模式-适配器模式:
Adapter(适配器模式)属于结构型模式,结构性模式关注的是如何组合类与对象,以获得更大的结构,我们平常工作大部分时间都在与这种设计模式打交道。
意图:将一个类的接口转换成客户希望的另一个接口。Adapter 模式使得原本由于接口不兼容而不能在一起工作的那些类可以一起工作。
对于统一多个类的接口适配器模式就比较适用。
适配器, 在STL中扮演着转换器的角色,用于将一种接口转换成另一种接口,从而是原本不兼容的接口能够很好地一起运作。
容器、迭代器、和函数都有适配器, 适配器不提供迭代器。
栈的简单封装
一般对于我们自己来说实现一个栈,利用c++提供的STL我们可以直接封装,比如我们直接利用vector表示整个栈,出栈即尾删,入栈即尾插,获取栈顶元素即返回数组末尾元素,其他接口我们也不难实现:
template class stack
{
public:
//栈的重要接口
//入栈
viod push(cosnt T& x)
{
_container.push_back(x);//直接调用尾插
}
//出栈
void pop()
{
_container.pop_back(x);//直接调用尾删
}
//获取栈顶元素
const T& top()
{
return _container.back();//返回尾元素
}
//大小
size_t size()
{
return _container.size();
}
//判空
bool empty()
{
return _container.empty();
}
private:
//直接利用容器
vector> _container;
}; 添加容器模板参数(适配器)
对于栈我们知道本质是数组,那么直接调用数组模板即可,但对于栈的实现我们发现不仅仅直接利用数组,利用链表也是可以实现栈的,其次由于在设计标准模板库时根据泛型编程的思维,这使得接口其功能都是一样的()。
那么在实现栈的时候,不仅仅利用一种模板,而是多模板,这使得我们在设计实现栈时,可以提供一个容器模板(根据不同的容器也能实现栈),因此我们还添加了Container(容器模板),达到实现不同容器,统一接口的实现。
template class stack
{
public:
//栈的重要接口
//入栈
void push(const T& x)
{
_container.push_back(x);//直接调用尾插
}
//出栈
void pop()
{
_container.pop_back();//直接调用尾删
}
//获取栈顶元素
const T& top()
{
return _container.back();//返回尾元素
}
//大小
size_t size()
{
return _container.size();
}
//判空
bool empty()
{
return _container.empty();
}
const T& front()
{
return _container.front();
}
const T& back()
{
return _container.back();
}
private:
//直接利用容器
Container _container;
}; 对于这里的容器模板,其实就是适配器,通过参数控制不同容器适配出同样效果的数据结构(感觉这也是泛型编程的特点,不追求底层,只看当前的功能)。
队列的简单封装
通过对栈的是实现,我们也可以利用适配器这种方式来实现队列,不过需要注意的是:
我们在选用容器的时候还是要应当注意容器是否满足我们在实现某个功能时,提供所需要的接口,对于队列,这里使用vector就不行了,并不能一股脑认为是个容器都可以。
template>class queue
{
public:
//入队
void push(const T& x)
{
_con.push_back(x);
}
//出队
void pop()
{
_con.pop_front();
}
void top()
{
return _con.front();
}
size_t size()
{
return _con.size();
}
const T& front()
{
return _con.front();
}
const T& back()
{
return _con.back();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
库中的实现
利用适配器我们可以将能实现的容器集合在一起,控制参数来控制容器,那么既然是参数,我们想这里也应该可以设置缺省参数的,那么缺省参数如何设置呢?我们可以看看库中的实现:


初识双端队列
库中这里设置的缺省参数是双端队列,我们可以看看双端队列:

首先对于双端队列,我们不要认为他是一个队列,其次我们在观察它的接口:
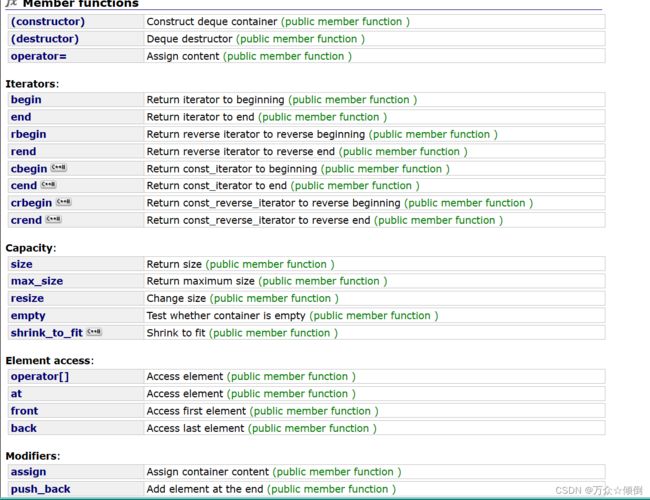
双端队列,本质上是一个顺序表,可以看到它的接口与vector和list非常相似,从功能上来说,他是将vector与list的功能集合到一起,同时具有两种结构的接口(包括尾插,尾删,头插,头删,正反向迭代器,[ ]访问元素,插入,删除等接口),可以看到非常之牛,它好像同时满足了vector和list的所有优点:
1.vector的连续地址,支持快速访问。
2.list的高效率随机位置插入。
犹如六边形战士,那么真实情况果真如此吗?事实并非如此。
我们可以了解一下他的结构,因为能支持数组随机访问,且能随机插入,那么其空间应该是连续的,但不完全连续:
即利用指针,将各个数组连接起来,指针被存放在叫中控数组的地方,存放数据的叫做buffer数组。

迭代器设计:
可以看到迭代器是由四个数据封装起来的,其中第一个位置的cur指向的是当前数组的第一个位置,第二个位置的first指向的是数组第一个位置,第三个last指向的是数组最后位置,二级指针node指向的是中控数组里的某个指针。
以这样的方式封装了begin与end这两个表示开头语结尾的迭代器。
对于双端队列,它的数据插入是从中间开始的,如若头或尾某个地方的数据已经满了,那么他会新开一个buffer数组,将数组存放起来(头部插入,放数组后面,尾部插入放数组前面),再连接起来,当然如果数据够多使得中控数组都已经插入满了,那么需要扩容中控数组,不过代价会比较低,但是对于中间插入数据,如若中间的某个位置的buffer数组已经满了,那么有两种选择方案:
扩容或者挪动数据,如何选择看你的取舍:
若果是扩容的话,因为我们[ ]访问数据对于同样大的数组访问速度会比较快,我们可以很好的计算出它的位置从而访问它(比如我们对数组的大小取余或取整,就可以知道是某个数组的第几个),若扩容,则该位置访问是比较困难的。
如果是挪动数据的话,整体后挪数据,数据量太大,那么代价就非常大了,效率会特别低。
这样一看其实是对于双端队列,我们头插尾插数据时效率是比较高的,但对于中间插入数据实在是不太行啊,这也是为什么叫双端队列,目的也是让我们去操作它的两端数据,不去中间搞事。
那么回过头来看选用双端队列用作我们的栈和队列的适配器,其实是比较不错的,只操作两端的数据,效率还是比较高的。