BIT-5数据在内存中的存储及字符函数(10000字详解)
一:整型在内存中的存储
在C语言中,整型数据使用固定长度的字节来存储。通常情况下,int类型占用4个字节(32位),其存储方式包括原码、反码和补码。
-
原码:
原码是最直观的表示方式,它将整数直接转换为二进制,并在最高位(最左边的位)上标识正负号。对于正数,最高位为0;对于负数,最高位为1。例如,整数75的原码表示为:00000000 00000000 00000000 01001011,而整数-75的原码表示为:10000000 00000000 00000000 01001011 -
反码:
反码的表示方式中,正数的反码与原码相同,而负数的反码是在原码的基础上,除了最高位之外,其它位按位取反。例如,整数75的反码表示为:00000000 00000000 00000000 01001011,对于75的反码表示为:11111111 11111111 11111111 10110100。 -
补码:
正数的补码与原码相同,而负数的补码是在反码的基础上加1。例如,整数75的补码表示为:00000000 00000000 00000000 01001011,对于-75的补码表示为:11111111 11111111 11111111 10110101。
总结:
-
对于正数来说,正数的原码,反码,补码都相同
-
对于负数来说,负数的原码,反码,补码不相同
负数的原码,反码,补码转化如图所示:

举个例子:
求一下int a = 198 和 int b = -289在内存的原码反码和补码
对于 int a = 198来说,它的原码反码和补码多相同,都是00000000 00000000 00000000 11000110
对于int b = -289来说,
原码表示为 10000000 00000000 00000001 00100001
反码表示为 11111111 11111111 11111110 11011110
补码表示为 11111111 11111111 11111110 11011111
注意:数据通过读直接写出来的是原码,但是数据在内存中存储的是补码
二:大小端介绍
- 大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
- 小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中。
那么什么是数据的地位呢?


三:浮点型在内存中的存储
在c语言中,我们对浮点型在内存中的存储采用 IEEE754标准,任意一个二进制浮点数可以表示成下面的形式:
- (-1)^S * M * 2^E
对于这个形式我们进行解释
-
(-1)^S表示符号位,当S=0,V为正数;当S=1,V为负数。
-
M表示有效数字, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。
-
^E表示指数位。
IEEE 754规定:
对于32位的浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M。

对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。(SEM)
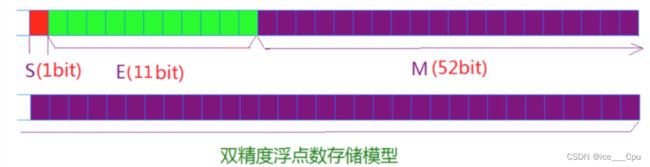
IEEE 754对有效数字M和指数E,还有一些特别规定。
数字M:
-
前面说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分。(可以认为M就说xxxxxx部分)比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字。
至于指数E,情况就比较复杂:
- 首先,E为一个无符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0~~255;如果E为11位,它的取值范围为0~2047。但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数, 对于8位的E,这个中间数 是127;对于11位的E,这个中间数是1023。
比如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即 10001001。
然后,指数E从内存中取出还可以再分成三种情况:
- E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第一位的1。比如:0.5(1/2)的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位,则为1.0*2^(-1),其阶码为-1+127=126,表示为01111110,而尾数1.0去掉整数部分为0,补齐0到23位00000000000000000000000,则其二进
制表示形式为:
0 01111110 00000000000000000000000
- E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于0的很小的数字。
- E全为1
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s);
例子:
将 20.59375转换为IEEE754二进制表达方式:
首先20转换为2进制应该是10100,接着我们对小数部分进行转换:

所以小数部分就应该是10011,所以20.59375可以转换为10100.10011 -> (-1)^0 x 1.010010011 x 2^4,即s = 0 ,e =4+127 = 131 ,m = 010010011(省略了1),所以完整的二进制应该是:
0 10000011 01001001100000000000000 ,再修改成
0100 0001 1010 0100 1100 0000 0000 0000,转成16进制表示即:
41A4C000
四:const 和assert
4.2 assert
在C语言中,assert是一个预处理宏,用于在程序中进行断言的验证。它用于检查程序中的某个条件是否为真,如果为假,则会终止程序的执行并输出相应的错误消息。
下面是assert的基本语法:
#include assert宏接受一个表达式作为参数,如果该表达式为假(即值为0),则会触发断言失败,程序会被终止,并输出包含错误信息的消息。如果表达式为真,则不会有任何影响,程序继续执行。
示例:
#include 上述代码中,如果b为0,则断言失败,程序会终止执行,并输出错误消息。
4.1 const
在C语言中,const关键字用于声明一个常量,也就是一个不可修改的变量。它可以应用于不同的上下文中,如变量声明、函数参数、函数返回类型等。
const关键字的基本语法为:const 数据类型 变量名。
示例:
const int MAX_VALUE = 100; // 声明一个常量 MAX_VALUE,并赋值为 100
int main() {
const int x = 5; // x 声明为常量,并赋值为 5
x = 10; // 错误,无法修改常量的值
const int* p = &x; // p 是指向常量的指针,无法通过 p 修改 x 的值
int* const q = &x; // q 是一个常量指针,无法 修改q的值(地址),即无法改变指针指向
return 0;
}
在上述示例中,我们声明了一个常量MAX_VALUE和一个常量x,它们的值都无法在后续代码中修改。然后我们定义了一个指向常量的指针p和一个常量指针q。无法通过指针p修改x的值,而q无法改变指向
那么,const int* p和int *const p之间有什么区别呢?
const int* p:表示p是一个指向常量的指针。指针本身可被修改,但不能通过指针修改所指向地址的值。int *const p:表示p是一个常量指针。指针本身是一个常量,不可被修改,但可以通过指针修改所指向地址的值。
简而言之,const int* p允许修改指针本身,但不能通过指针修改值;int *const p允许修改所指向地址的值,但不能修改指针本身。
五:字符函数和字符串函数
5.1 strlen strcpy strcat strcmp
当然!首先,让我们逐个介绍这些C语言中的字符串处理函数。
- strlen函数:
-
简介:strlen函数用于计算字符串的长度,即字符串中的字符数(不包括空字符 ‘\0’)。
#include#include int main() { char str[] = "Hello, World!"; int length = strlen(str); printf("字符串的长度为:%d\n", length); return 0; } -
运行结果:字符串的长度为 13。
-
注意:
- strlen(地址)括号中放的是地址
- 参数指向的字符串必须要以 ‘\0’ 结束(虽然不计算\0,但是需要\0 这个标志)
- 函数的返回值为size_t,是无符号的( 易错 )
- strcpy函数:
- 简介:strcpy函数用于将一个字符串复制到另一个字符串中,包括字符串末尾的空字符 ‘\0’。
- 示例代码:
#include#include int main() { char source[] = "Hello, World!"; char destination[20]; strcpy(destination, source); printf("复制后的字符串为:%s\n", destination); return 0; } - 运行结果:复制后的字符串为 “Hello, World!”。
注意:
- 源字符串必须以 ‘\0’ 结束。
- 会将源字符串中的 ‘\0’ 拷贝到目标空间。
- 目标空间必须足够大且可变,以确保能存放源字符串。
- strcat函数:
- 简介:strcat函数用于将一个字符串连接到另一个字符串的末尾,结果是一个新的字符串。
- 示例代码:
#include#include int main() { char str1[] = "Hello, "; char str2[] = "World!"; strcat(str1, str2); printf("连接后的字符串为:%s\n", str1); return 0; } - 运行结果:连接后的字符串为 “Hello, World!”。
注意:
- 源字符串必须以 ‘\0’ 结束。
- 目标空间必须有足够的大且可修改,能容纳下源字符串的内容。
- 不能自己给自己追加,即strcat(str, str);
- strcmp函数:
- 简介:strcmp函数用于比较两个字符串是否相等,或者判断哪个字符串的大小顺序在前。
- 示例代码:
#include#include int main() { char str1[] = "Hello"; char str2[] = "Hello"; int result = strcmp(str1, str2); if (result == 0) { printf("字符串相等\n"); } else if (result < 0) { printf("字符串1在前\n"); } else { printf("字符串2在前\n"); } return 0; } - 运行结果:字符串相等。
标准规定:
- 第一个字符串大于第二个字符串,则返回大于0的数字
- 第一个字符串等于第二个字符串,则返回0
- 第一个字符串小于第二个字符串,则返回小于0的数字
5.2 strncpy strncat strncmp
-
strncpy函数:
strncpy函数用于将一个字符串的指定长度复制到另一个字符串中。它的函数原型如下:char* strncpy(char* dest, const char* src, size_t n);dest:目标字符串,用于接收复制后的结果。src:源字符串,要复制的字符串。n:要复制的最大字符数。
strncpy函数将src中的前n个字符复制到dest中,如果src的长度小于n,则会在dest的剩余位置上用空字符填充。下面是一个使用
strncpy函数的示例:#include#include int main() { char source[] = "Hello, World!"; char destination[20]; strncpy(destination, source, 5); destination[5] = '\0'; // 手动添加字符串结束符 printf("Copied string: %s\n", destination); return 0; } 上述代码将
source字符串的前 5 个字符复制到destination字符串中,并手动在第 6 个位置添加了字符串结束符。 -
strncat函数:
strncat函数用于将一个字符串的指定长度追加到另一个字符串的末尾。它的函数原型如下:char* strncat(char* dest, const char* src, size_t n);dest:目标字符串,要追加的字符串将会添加到这里。src:源字符串,要追加的字符串。n:要追加的最大字符数。
strncat函数将src中的前n个字符追加到dest的末尾,并确保dest仍然以空字符结尾。下面是一个使用
strncat函数的示例:#include#include int main() { char destination[20] = "Hello, "; strncat(destination, "World!", 6); printf("Concatenated string: %s\n", destination); return 0; } 上述代码将
"World!"字符串的前 6 个字符追加到destination字符串的末尾。 -
strncmp函数:
strncmp函数用于比较两个字符串的指定长度。它的函数原型如下:int strncmp(const char* str1, const char* str2, size_t n);str1:要进行比较的第一个字符串。str2:要进行比较的第二个字符串。n:要比较的最大字符数。
strncmp函数按照字典顺序比较str1和str2的前n个字符。如果两个字符串相等返回 0,如果str1小于str2返回负数,如果str1大于str2返回正数。下面是一个使用
strncmp函数的示例:#include#include int main() { char str1[] = "Hello"; char str2[] = "Hey"; int result = strncmp(str1, str2, 3); if (result == 0) { printf("Strings are equal.\n"); } else if (result < 0) { printf("str1 is less than str2.\n"); } else { printf("str1 is greater than str2.\n"); } return 0; } 上述代码比较了
str1和str2的前 3 个字符,并根据比较结果输出相应的信息。
5.3strstr strtok
-
strstr 函数:
-
strstr 函数用于在一个字符串中搜索另一个子字符串的出现位置。
-
函数原型:
char *strstr(const char *str1, const char *str2) -
参数 str1 是要搜索的字符串,str2 是要查找的子字符串。
-
strstr 函数返回第一次出现 str2 的位置的指针,如果找不到则返回 NULL。
-
以下是一个代码示例:
#include#include int main() { char str1[] = "Hello, world!"; char str2[] = "world"; char *result; result = strstr(str1, str2); if (result != NULL) { printf("'%s' found at position %ld.\n", str2, result - str1); } else { printf("'%s' not found.\n", str2); } return 0; } 输出结果为:
'world' found at position 7. -
strtok 函数:
-
strtok 函数用于将一个字符串拆分成一系列子字符串,以指定的分隔符为准。
-
函数原型:
char *strtok(char *str, const char *delim) -
参数 str 是要拆分的字符串,delim 是分隔符。
-
strtok 函数第一次调用时,将传入要拆分的字符串,之后的调用传入 NULL 继续拆分原字符串。
-
strtok 函数返回每次调用的子字符串指针,如果没有更多子字符串则返回 NULL,并在原字符串中用 ‘\0’ 替换分隔符。
-
strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串
中的位置。 -
strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
以下是一个代码示例:
#include 输出结果为:

5.4 strerror perror
5.4.1 sterror
#include errno是C语言标准库中的一个全局变量,用于表示最近一次发生的错误代码。它在
当C标准库函数执行失败时,它们会将适当的错误代码存储在errno中。该错误代码可以表示不同的错误类型,比如文件操作错误、内存分配错误等。
在上述代码中,errno用于获取fopen函数执行失败时的错误代码。strerror函数用于将错误代码转换为对应的错误信息字符串。通过将errno作为参数传递给strerror函数,你可以获取到解释了错误原因的字符串。
如果文件打开失败,pFile将为NULL,并且通过使用strerror(errno),你可以将错误信息打印到控制台。
5.4.2 perror
perror函数是C语言标准库中的一个函数,用于打印与当前 errno 值关联的错误信息。它的原型如下:
#include 函数参数 s 是一个指向字符串的指针,表示自定义的错误前缀。当 perror 函数被调用时,它会根据当前的 errno 值,在标准错误流 stderr 中打印格式为 “[prefix]: [error message]” 的错误信息。
下面是一个简单的示例代码,演示了如何使用 perror 函数:
#include 在这个示例中,我们尝试打开一个不存在的文件。由于打开失败,file 的值为 NULL。接着使用 perror 函数打印错误信息,并返回 errno 值作为程序的退出码。
假设运行上述程序,输出可能类似于:
Error: No such file or directory
通过使用 perror,我们不仅能够打印出错误消息如 “No such file or directory”,而且还能自定义前缀,如 “Error”。
perror 函数内部会调用 strerror 函数来获取错误信息字符串,然后将其与自定义的前缀字符串拼接起来输出到标准错误流中。因此,perror 函数可以方便地输出带有自定义前缀的错误信息。
5.5 字符操作函数
| 函数 | 如果他的参数符合下列条件就返回真 |
|---|---|
| iscntrl | 任何控制字符 |
| isspace | 空白字符:空格‘ ’,换页‘\f’,换行’\n’,回车‘\r’,制表符’\t’或者垂直制表符’\v’ |
| isdigit | 十进制数字 0~9 |
| isxdigit | 十六进制数字,包括所有十进制数字,小写字母af,大写字母AF |
| islower | 小写字母a~z |
| isupper | 大写字母A~Z |
| isalpha | 字母az或AZ |
| isalnum | 字母或者数字,az,AZ,0~9 |
| ispunct | 标点符号,任何不属于数字或者字母的图形字符(可打印 |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图形字符和空白字符 |
5.5 memcpy memmove memset memcmp
memcpy、memmove、memset 和 memcmp这些函数都属于
memcpy函数用于将一个内存区域的内容复制到另一个内存区域。其原型如下:
void *memcpy(void *dest, const void *src, size_t n);
其中,dest 是目标内存区域的指针,src 是源内存区域的指针,n 是要复制的字节数。该函数会将源内存区域的内容复制到目标内存区域,并返回目标内存区域的指针。
下面是一个示例代码,演示了如何使用 memcpy 函数:
#include 运行结果:Copied string: Hello, world!
上述代码中,我们将源字符串 "Hello, world!" 复制到目标内存区域 destination 中,并通过 printf 输出了复制后的字符串。
memmove函数也用于将一个内存区域的内容复制到另一个内存区域,但与memcpy不同,memmove能够处理源内存区域和目标内存区域重叠的情况。其原型如下:
void *memmove(void *dest, const void *src, size_t n);
使用方法与 memcpy 类似。以下是一个示例代码:
#include 运行结果:Moved string: 1212345
上述代码将字符串 "12345" 的前两个字符移动到了末尾,并通过 printf 输出了移动后的字符串。
memset函数用于将一块内存区域的所有字节设置为指定的值。其原型如下:
void *memset(void *s, int c, size_t n);
其中,s 是要设置的内存区域的起始地址,c 是要设置的值,n 是要设置的字节数。该函数会将指定内存区域的字节全部设置为指定值,并返回起始地址。
以下是一个示例代码,演示了如何使用 memset 函数:
#include 上述代码将字符数组 str 的所有字节都设置为 'A',并通过 printf 输出了结果。
memcmp函数用于比较两个内存区域的内容。其原型如下:
int memcmp(const void *s1, const void *s2, size_t n);
其中,s1 和 s2 是要比较的两个内存区域的指针,n 是要比较的字节数。该函数以字节为单位逐个比较内存区域的内容
- 如果比较的结果相等,返回值为 0;
- 如果
s1大于s2,返回值大于 0; - 如果
s1小于s2,返回值小于 0。
以下是一个示例代码,演示了如何使用 memcmp 函数:
#include 运行结果:Strings are equal.
上述代码比较了两个字符串 str1 和 str2 的内容,并通过判断返回值是否为 0 来确定它们是否相等。
5.5.1memcpy memmove 的区别
memcpy 和 memmove 都是C语言中用于内存操作的函数,它们的作用是将一块内存区域的内容复制到另一块内存区域。它们的区别在于对于源内存区域和目标内存区域是否重叠的处理方式。
memcpy函数:
memcpy函数用于将源内存区域的内容完全复制到目标内存区域。函数原型如下:
void *memcpy(void *dest, const void * src, size_t n);
其中:
dest是目标内存区域的起始地址;src是源内存区域的起始地址;n是要复制的字节数。
如果源内存区域和目标内存区域重叠,memcpy 函数的行为是未定义的,也就是说结果是不确定的,可能会导致数据错误。
memmove函数:
memmove函数与memcpy函数的功能相似,它也用于将源内存区域的内容复制到目标内存区域。但是,memmove函数对于源内存区域和目标内存区域的重叠处理方式不同。函数原型如下:
void *memmove(void *dest, const void * src, size_t n);
同样,dest 是目标内存区域的起始地址,src 是源内存区域的起始地址,n 是要复制的字节数。
memmove 函数会先将源内存区域的内容拷贝到一个临时缓冲区,然后再从临时缓冲区中将数据复制到目标内存区域。这样,即使源内存区域和目标内存区域重叠,也不会出现数据错误的情况。
因此,如果你需要对重叠的内存区域进行复制操作,应该优先使用 memmove 函数,而不是 memcpy 函数。