Python大数据之PySpark(四)SparkBase&Core
文章目录
- SparkBase&Core
-
- 环境搭建-Spark on YARN
- 扩展阅读-Spark关键概念
- [了解]PySpark角色分析
- [了解]PySpark架构
- 后记
SparkBase&Core
- 学习目标
- 掌握SparkOnYarn搭建
- 掌握RDD的基础创建及相关算子操作
- 了解PySpark的架构及角色
环境搭建-Spark on YARN
- Yarn 资源调度框架,提供如何基于RM,NM,Continer资源调度
- Yarn可以替换Standalone结构中Master和Worker来使用RM和NM来申请资源
SparkOnYarn本质
- Spark计算任务通过Yarn申请资源,SparkOnYarn
- 将pyspark文件,经过Py4J(Python for java)转换,提交到Yarn的JVM中去运行
修改配置
思考,如何搭建SparkOnYarn环境?
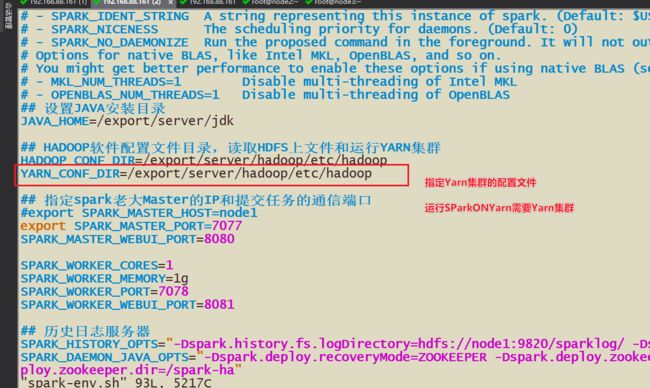
1-需要让Spark知道Yarn(yarn-site.xml)在哪里?
在哪个文件下面更改?spark-env.sh中增加YARN_CONF_DIR的配置目录
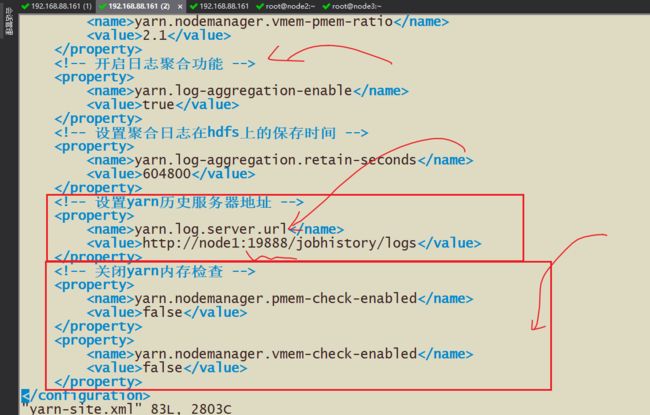
2-修改Yan-site.xml配置,管理内存检查,历史日志服务器等其他操作
修改配置文件
3-需要配置历史日志服务器
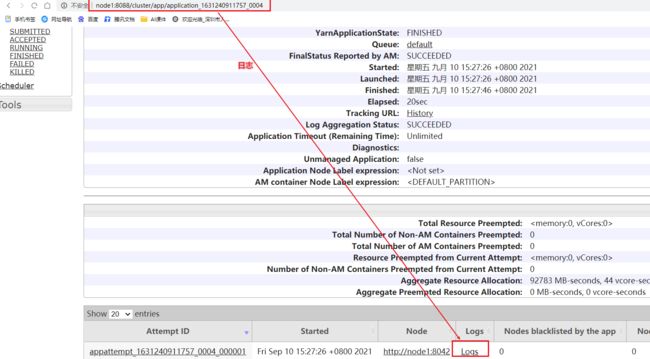
需要实现功能:提交到Yarn的Job可以查看19888的历史日志服务器可以跳转到18080的日志服务器上
因为19888端口无法查看具体spark的executor后driver的信息,所以搭建历史日志服务器跳转
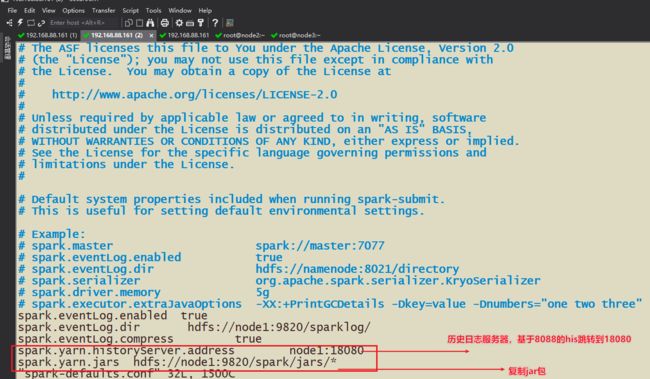
3-需要准备SparkOnYarn的需要Jar包,配置在配置文件中
在spark-default.conf中设置spark和yarn映射的jar包文件夹(hdfs)
注意,在最终执行sparkonyarn的job的时候一定重启Hadoop集群,因为更改相关yarn配置
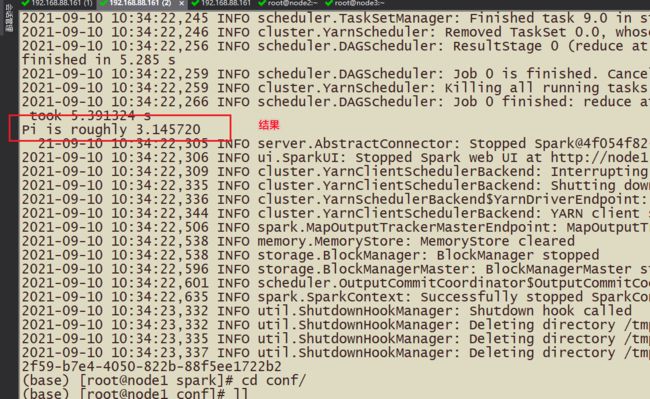
4-执行SparkOnYarn
这里并不能提供交互式界面,只有spark-submit(提交任务)
#基于SparkOnyarn提交任务 bin/spark-submit \ --master yarn \ /export/server/spark/examples/src/main/python/pi.py \ 10
小结
SparKOnYarn:使用Yarn提供了资源的调度和管理工作,真正执行计算的时候Spark本身
Master和Worker的结构是Spark Standalone结构 使用Master申请资源,真正申请到是Worker节点的Executor的Tasks线程
原来Master现在Yarn替换成ResourceManager,现在Yarn是Driver给ResourceManager申请资源
原来Worker现在Yarn替换为Nodemanager,最终提供资源的地方时hiNodeManager的Continer容器中的tasks
安装配置:
1-让spark知道yarn的位置
2-更改yarn的配置,这里需要开启历史日志服务器和管理内存检查
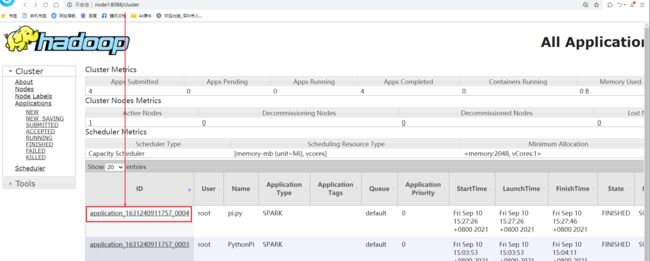
3-整合Spark的历史日志服务器和Hadoop的历史日志服务器,效果:通过8088的yarn的http://node1:8088/cluster跳转到18080的spark的historyserver上
4-SparkOnYarn需要将Spark的jars目录下的jar包传递到hdfs上,并且配置spark-default.conf让yarn知晓配置
5-测试,仅仅更换–master yarn
部署模式
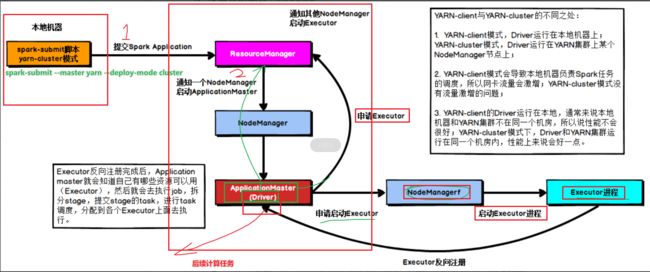
#如果启动driver程序是在本地,称之为client客户端模式,现象:能够在client端看到结果
#如果在集群模式中的一台worker节点上启动driver,称之为cluser集群模式,现象:在client端看不到结果
- client
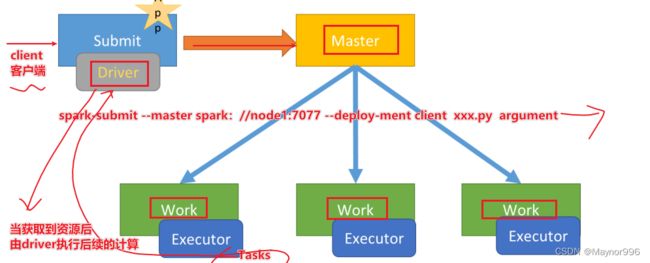
首先 client客户端提交spark-submit任务,其中spark-submit指定–master资源,指定–deploy-mode模式
由启动在client端的Driver申请资源,
交由Master申请可用Worker节点的Executor中的Task线程
一旦申请到Task线程,将资源列表返回到Driver端
Driver获取到资源后执行计算,执行完计算后结果返回到Driver端
由于Drivr启动在client端的,能够直接看到结果
实验:
#基于Standalone的脚本—部署模式client
#driver申请作业的资源,会向–master集群资源管理器申请
#执行计算的过程在worker中,一个worker有很多executor(进程),一个executor下面有很多task(线程)
bin/spark-submit
–master spark://node1:7077
–deploy-mode client
–driver-memory 512m
–executor-memory 512m
/export/server/spark/examples/src/main/python/pi.py
10
- cluster
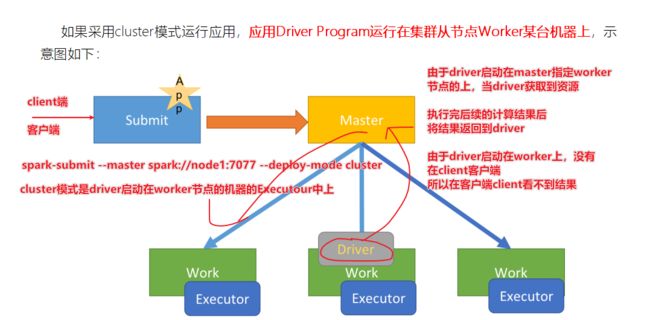
首先 client客户端提交spark-submit任务,其中spark-submit指定–master资源,指定–deploy-mode模式
由于指定cluster模式,driver启动在worker节点上
由driver申请资源,由Master返回worker可用资源列表
由Driver获取到资源执行后续计算
执行完计算的结果返回到Driver端,
由于Driver没有启动在客户端client端,在client看不到结果
如何查看数据结果?
需要在日志服务器上查看,演示
实验:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit
–master spark://node1.itcast.cn:7077,node2.itcast.cn:7077
–deploy-mode cluster
–driver-memory 512m
–executor-memory 512m
–num-executors 1
–total-executor-cores 2
–conf “spark.pyspark.driver.python=/root/anaconda3/bin/python3”
–conf “spark.pyspark.python=/root/anaconda3/bin/python3”
${SPARK_HOME}/examples/src/main/python/pi.py
10
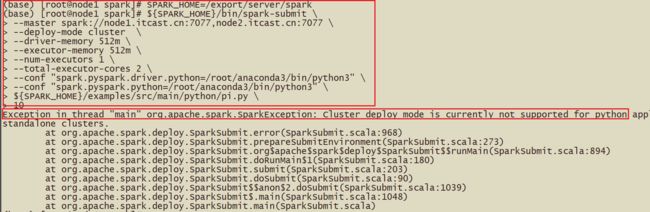
- 注意事项:

- 通过firstpyspark.py写的wordcount的代码,最终也是转化为spark-submit任务提交
- 如果是spark-shell中的代码最终也会转化为spark-submit的执行脚本
- 在Spark-Submit中可以提交driver的内存和cpu,executor的内存和cpu,–deploy-mode部署模式
Spark On Yarn两种模式
Spark on Yarn两种模式
–deploy-mode client和cluster
Yarn的回顾:Driver------AppMaster------RM-----NodeManager—Continer----Task
client模式
#deploy-mode的结构
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit
–master yarn
–deploy-mode client
–driver-memory 512m
–driver-cores 2
–executor-memory 512m
–executor-cores 1
–num-executors 2
–queue default
${SPARK_HOME}/examples/src/main/python/pi.py
10#瘦身
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit
–master yarn
–deploy-mode client
${SPARK_HOME}/examples/src/main/python/pi.py
10
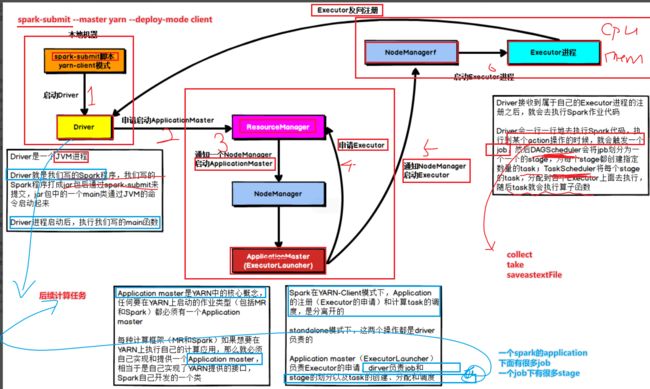
原理:
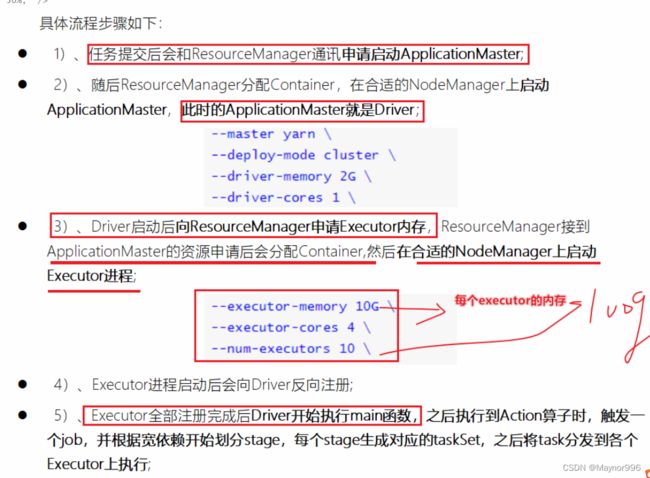
1-启动Driver
2-由Driver向RM申请启动APpMaster
3-由RM指定NM启动AppMaster
4-AppMaster应用管理器申请启动Executor(资源的封装,CPU,内存)
5-由AppMaster指定启动NodeManager启动Executor
6-启动Executor进程,获取任务计算所需的资源
7-将获取的资源反向注册到Driver
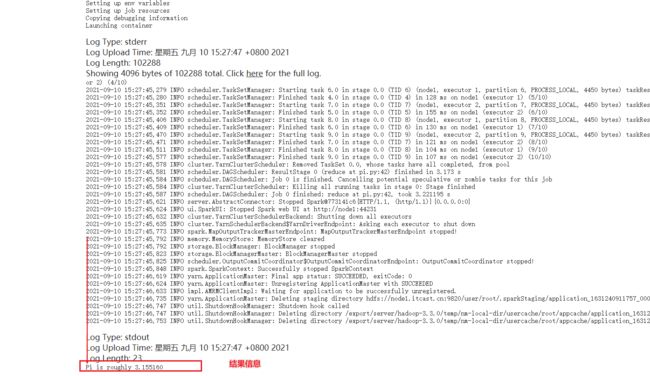
由于Driver启动在Client客户端(本地),在Client端就可以看到结果3.1415
8-Driver负责Job和Stage的划分[了解]
1-执行到Action操作的时候会触发Job,不如take
2-接下来通过DAGscheduler划分Job为Stages,为每个stage创建task
3-接下来通过TaskScheduler将每个Stage的task分配到每个executor去执行
4-结果返回到Driver端,得到结果
cluster:
作业:
${SPARK_HOME}/bin/spark-submit
–master yarn
–deploy-mode cluster
–driver-memory 512m
–executor-memory 512m
–executor-cores 1
–num-executors 2
–queue default
–conf “spark.pyspark.driver.python=/root/anaconda3/bin/python3”
–conf “spark.pyspark.python=/root/anaconda3/bin/python3”
${SPARK_HOME}/examples/src/main/python/pi.py
10
#瘦身
${SPARK_HOME}/bin/spark-submit
–master yarn
–deploy-mode cluster
${SPARK_HOME}/examples/src/main/python/pi.py
10
 >>*
>>* 

原理:

扩展阅读:两种模式详细流程
扩展阅读-Spark关键概念
扩展阅读:Spark集群角色
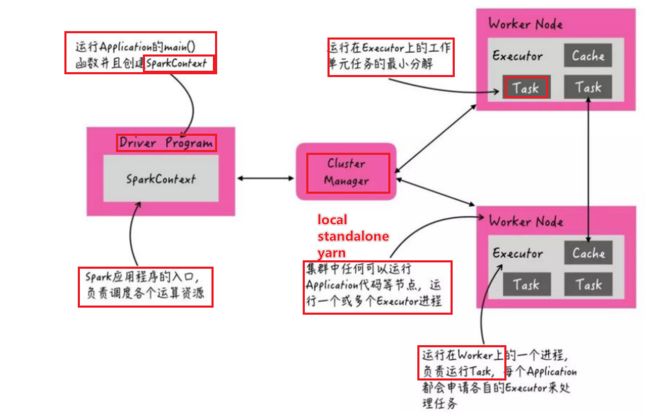
- Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算
- 也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作。
- Driver:启动SparkCOntext的地方称之为Driver,Driver需要向CLusterManager申请资源,同时获取到资源后会划分Stage提交Job
- Master:l 主要负责资源的调度和分配,并进行集群的监控等职责;
- worker:一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算
- Executor:一个Worker****(NodeManager)****上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算
- 每个Task线程都会拉取RDD的每个分区执行计算,可以执行并行计算
扩展阅读:Spark-shell和Spark-submit
bin/spark-shell --master spark://node1:7077 --driver-memory 512m --executor-memory 1g
# SparkOnYarn组织参数
–driver-memory MEM 默认1g,Memory for driver (e.g. 1000M, 2G) (Default: 1024M). Driver端的内存
–driver-cores NUM 默认1个,Number of cores used by the driver, only in cluster mode(Default: 1).
–num-executors NUM 默认为2个,启动多少个executors
–executor-cores NUM 默认1个,Number of cores used by each executor,每个executou需要多少cpucores
–executor-memory 默认1G,Memory per executor (e.g. 1000M, 2G) (Default: 1G) ,每个executour的内存
–queue QUEUE_NAME The YARN queue to submit to (Default: “default”).
bin/spark-submit --master yarn \
–deploy-mode cluster \
–driver-memory 1g \
–driver-cores 2 \
–executor-cores 4 \
–executor-memory 512m \
–num-executors 10 \
path/XXXXX.py \
10
扩展阅读:命令参数
–driver-memory MEM 默认1g,Memory for driver (e.g. 1000M, 2G) (Default: 1024M). Driver端的内存
–driver-cores NUM 默认1个,Number of cores used by the driver, only in cluster mode(Default: 1).
–num-executors NUM 默认为2个,启动多少个executors
–executor-cores NUM 默认1个,Number of cores used by each executor,每个executou需要多少cpucores
–executor-memory 默认1G,Memory per executor (e.g. 1000M, 2G) (Default: 1G) ,每个executour的内存
–queue QUEUE_NAME The YARN queue to submit to (Default: “default”).
MAIN函数代码执行

- Driver端负责申请资源包括关闭资源,负责任务的Stage的切分
- Executor执行任务的计算
- 一个Spark的Application有很多Job
- 一个Job下面有很多Stage
- 一个Stage有很多taskset
- 一个Taskset有很多task任务构成的额
- 一个rdd分task分区任务都需要executor的task线程执行计算
再续 Spark 应用
[了解]PySpark角色分析
- Spark的任务执行的流程
- 面试的时候按照Spark完整的流程执行即可
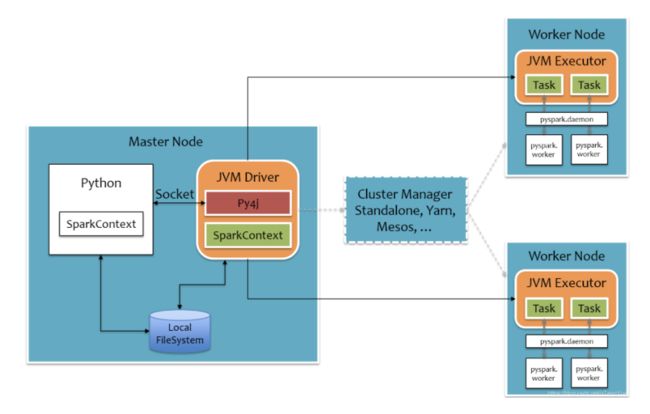
- Py4J–Python For Java–可以在Python中调用Java的方法
- 因为Python作为顶层的语言,作为API完成Spark计算任务,底层实质上还是Scala语言调用的
- 底层有Python的SparkContext转化为Scala版本的SparkContext
- ****为了能在Executor端运行用户定义的Python函数或Lambda表达****式,则需要为每个Task单独启一个Python进程,通过socket通信方式将Python函数或Lambda表达式发给Python进程执行。
[了解]PySpark架构
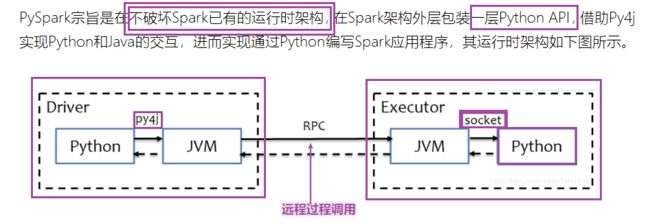
后记
博客主页:https://manor.blog.csdn.net
欢迎点赞 收藏 ⭐留言 如有错误敬请指正!
本文由 Maynor 原创,首发于 CSDN博客
感觉这辈子,最深情绵长的注视,都给了手机⭐
专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12453356.html