nginx(三十)变量终谈
一 域名和端口相关的变量
nginx变量的实现原理
最终的目的:
1)变量的含义'清晰易懂',日志中'使用'这些变量,能提取'哪些'信息?
2) 帮助我们'如何'快速定位信息?之前写的辅助理解
① $host
备注:$host是'ngx_http_core_module模块'内部的一个'变量'
++++++++++++"$host 的值解读"++++++++++++
优先级1: 如果'请求行 [Request Line]' 中有 'host name' -->"不常见"
1) 请求行形式 'GET http://example.com/ HTTP/1.1'
2) 其中'example.com'就是'$host'值
3) 可以用'telnet'模拟
优先级2:
1) 如果'请求头 [Request Header]' 内有'Host 字段'的值
2) 并且'$Host与server_name'匹配
3) 则'$host=Host请求头值'
优先级3:
1) 如果'Host头与server_name'都不匹配(包含'空值'场景)
2) 此时使用'默认'的虚拟主机,该虚拟主机的'$host'值就是该请求匹配到的'server_name'
重点:$host 总是'小写',且'值'不带'端口'号参考链接 关于nginx中的host变量
curl带一个'空'的Host请求头,会覆盖'url中主机头'的
② $http_host 请求头中Host头
$http_host 的值:其实就是'请求头'中 Host 字段的值
备注:
1) HTTP/1.0'不带'host
2) 'HTTP/1.1' 的所有请求报文中'必须包含'一个Host头字段,且只能'设置'一个![]()


1)记录常见的请求头信息
关注:
1) $http_host、$http_user_agent"场景:反爬虫"
2) $http_referer"场景:盗链"、$http_cookie
测试方式:'curl'、'浏览器'、postman测试![]()
![]()
![]()
![]()

2)客户端自定义请求头不透传
参考链接
![]()

说明:下面是'对比'访问的效果![]()

nginx策略:
1) 默认是对'请求和响应header'的key'不支持下划线("忽略"该头)',包括'cookie头中的key'
2) 需要在http|server模块'添加'如下配置来'支持':
underscores_in_headers on;
解决1:header属性名'删除'下划线,或者连接符'改'为中划线"-"
解决2:修改nginx的配置文件 nginx.conf:underscores_in_headers on; '(默认值是off)'
++++++++++++++++"分割线"++++++++++++++++
关键::nginx会拦截http请求中自定义的'(有下划线)'的请求头,'不会'透传
思考:制定更'规范'的header名称,尽量'避免'使用带下划线的内容
细节点:
1) 如果自定义的请求头有'下划线',但是需要透传给后端;
2) 则underscores_in_headers on['默认是off'];
③ $server_name 重点
说明:是最终请求'匹配到'的'server_name',请求会被'route'到该server块对应的'location'
强调:
1) 建议'日志'中增加这个'变量'
2) 一目了然的看到实际'哪个server_name'处理客户请求,与'用户预期'做对比
④ $proxy_host

+++++++++$server_port 跟$proxy_port 的'区别'+++++++++
1) 前者为客户端访问 nginx 使用的端口,也即'nginx'监听的端口,如 80
1) 后者为 '上游服务器的端口',通常会'隐藏'起来,如 8080⑤ upstream_addr

⑥ remote_addr
![]()
1: 表面含义是'客户端的'真实ip -->如果'中间层'没有代理的话,获取的是'客户端的真实ip'
2: 实际场景
1) 经过反向代理后,由于在客户端和'web服务器(nginx、apache)之类'之间增加其它'中间代理层'
2) 因此web服务器'无法直接'拿到客户端的ip
3) 通过$remote_addr变量拿到的将是'上层'反向代理服务器的ip地址
3: $remote_addr 是与nginx'建立连接'的'上游客户端'的值
++++++++++++'了解即可'++++++++++++
$remote_port '客户端'的端口
$server_name 服务器名称
$server_port 服务器'nginx'的端口号⑦ proxy_add_x_forwarded_for
含义: nginx把'$remote_addr'变量值'追加'到'XFF'头中形成'最终'的字符串
其它参考
+++++++++++"常见场景"+++++++++++
1. 一般'最原始'的客户端请求不带'XFF'请求头
2. 此时'请求'经过第一层'代理[nginx]',如果日志中使用'$proxy_add_x_forwarded_for',则记录的是'$remote_addr'的值,真实客户端的ip
3. 此时第一层'proxy'设置如下
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
含义:把'当前proxy代理的ip'追加到'XFF头'中
作用:其实就像是'链路反追踪',从客户的'真实ip'为起点,穿过'多层级'的proxy,最终到达web 服务
器,'都会'记录下来
特点:每一层代理会将'连接它的客户端'IP追加在X-Forwarded-For'右边'
4. 此时'请求'经过第二层'代理[nginx]',如果日志中使用'$proxy_add_x_forwarded_for',则记录的是'client_ip, proxy1_ip'的值
5. 依次'类推' ...
思考:变量的'数值'是'-',表示什么含义?nginx获取客户端的真实ip

二 ngx_http_upstream_module模块相关变量
参考链接
明确一点:是'nginx侧'和'后端服务器'之间'相关'数据
分析内容:传输'大小'、'字节'、'状态'① $upstream_addr
能'反映'的信息:nginx是否'转发请求'了["是否有值-->nginx是否拦截,没有转发"],nginx转发了'几次'["值是几个"]?
备注:如果返回非'2xx和3xx'-->返回'4xx'或'5xx',除了查看'nginx'日志['access.log'和error.log]、还要查看'upstream日志'
细节:'4xx'一般是'后端的问题'、'502'一般关注nginx到upstream的连接、'504'一般关注'后端'的日志
常见现象:如果'值'是'-',一般可以反映nginx'没有'转发请求到'后端',nginx'拦截'了'客户端'请求
② 相关时间轴

打印日志是在'最后'一个步骤:也就是nginx完全'响应完毕给client'后,才进行'日志'记录
++++++++++++请求的'整套'时间线++++++++++++
1、客户端------request---->nginx
2、nginx------connect---->服务端
3、服务端------connect success---->nginx
4、nginx------send data----->服务端
5、服务端------response begin----->nginx
6、服务端------response end ------>nginx
7、nginx------response----->客户端
8、nginx'记录'日志
++++++++++++捕获的'重要'信息++++++++++++
上游服务'运行(程序处理)'时间=$upstream_header_time - $upstream_connect_time
数据'从nginx'响应到'client'耗时 = $request_time - $upstream_response_time
$request_time 包含'所有'内容的时间,包含'数据返回'时间+'日志打印'时间
目的:可以通过以上各种时间,来计算'每个链路的耗时',日志记录,这个非常重要,便于后续'链路分析'图片参考来源
③ $upstream_connect_time
+++++++++++'理解'+++++++++++
1) nginx与'后端'是'http'的话,则是记录'tcp'连接的时间,也即双方从'closed'进入'established'时间
2) nginx与'后端'是'https'的话,则在前面'tcp建立连接'的基础上+'SSL握手'时间
++++++++++'关联的参数'++++++++++
语法:proxy_connect_timeout 60s;
nginx与'后端连接'的'超时'时间,单位为'秒',默认为60秒
备注:我们在nginx错误日志里面看到的'(110: Connection timed out)',就是指nginx与后端连接已经'超时'④ $upstream_response_time
理解: 后端'upstream上游'发数据到'nginx完全接收响应'所'花费'的时间
场景: 来分析'后端程序接口响应'的时候,需要在nginx的'log_format'中添加'$upstream_response_time'字段
补充: 如果数值'比较大',考虑'网络通信质量'和'发送数据量'问题

⑤ $upstream_header_time
含义:接收'后端返回数据中响应头'的时间 ⑥ $upstream_queue_time
⑥ $upstream_queue_time
++++++++++'队列(queue)理解'++++++++++
1. 如果在'处理请求'时'无法'立即选择upstream服务器,则该请求将被'放入队列'中
2. 如果队列'已满'或者在'timeout参数指定的时间段'内无法选择'将请求传递'给后端的服务器,则会将'502(错误网关)错误'返回给客户端
3. nginx的listen 指令有'参数backlog' 用来指定'队列大小',默认的值为'511'
参考链接
⑦ 性能调优探讨
重要参考
"场景1":nginx日志出现大量'超时'报警,这个时候发现$upstream_header_time'正常',但是$request_time、$upstream_response_time很大
分析:根据上面的'示意图',这个时候便反映出是'上游程序执行较慢'、或'发送数据量大',需要排查'执行程序'的相关'慢'日志
+++++++++++++'分割线'+++++++++++++
"场景2":同样是ngxin日志出现大量'超时'报警,这个时候发现'$request_time很大',但是$upstream_response_time'正常'
分析:$upstream_response_time正常,说明'程序执行完毕且正常返回',那么这个时候需要验证是'数据返回过慢[nginx到client侧]'、还是'日志打印'出现了阻塞.
可能1:数据返回慢可以通过'抓包'分析,通常来说是'用户网络原因'引起的;
可能2:日志'打印'出现阻塞,可能是'机器io(写磁盘)'出现了问题,这个一般很容易发现;
可能3:还有可能是'nginx配置'了相关参数,导致了'延迟关闭',这里只要根据问题现象一步一步排查即可.
可能4:也可能返回给客户端是https,大数据'加解密'耗时,同时参考'error.log'日志
+++++++++++++'分割线'+++++++++++++
"场景3": $upstream_connect_time很大,可能是'nginx到后端网络通信'出现了问题,一般会出现'502|504'
+++++++++++++'分割线'+++++++++++++
"场景4":$upstream_header_time很小,但是$upstream_response_time很大,可能是'数据回写(暂时缓存在nginx侧)'nginx出现了问题.
小结:不难看出,通过这些变量,便可以'快速定位'到'问题环节',而不至于'毫无头绪'的到处排查,可以说是'事半功倍'
+++++++++++++'request_time与upstream_response_time比较'+++++++++++++
[1]、一般'request_time'比upstream_response_time'大'
如果'用户端'网络状况'较差'或者'传递数据本身较大',再考虑到 当使用 POST 方式传参时 nginx 会先把 request body '缓存'起来,而这些耗时都会'累积'到 '$request_time' 头上去⑧ $upstream_bytes_sent

⑨ $upstream_bytes_received

三 nginx核心模块提供的变量
ngx_http_log_module模块
参考链接
nginx调试变量模块
① args & arg_name
![]()
![]()
$args:这个变量在'读取'时'返回当前请求行'的 URL 参数串,即请求 URL 中'问号(?)'后面的部分,如果有的话
案例: https:/www.wzj.com/a.html?name=wzj&age=18
则:$args这个变量等于请求行中'一般是GET请求'的参数,'也即'name=wzj&age=18,'专业点'叫作'查询字符串'![]()

细节点:curl 发送请求'带参数',url需要加'单引号'或"双引号"![]()

② connection相关连的三个变量
+++++++++++++"不常用,了解即可"+++++++++++++
如果'关闭'HTTP keep-alive(长连接)以'禁止'TCP连接重用,$request_time将始终'等于'$connection_time
$connection_time是http请求使用的'TCP连接'的活动时间
HTTP和HTTP/2允许'单个TCP连接'发送和接收'多个'HTTP请求/响应,所以$connection_time应该总是'大于'$request_time;
③ uri相关

![]()
![]()
+++++++++++ "$uri和$request_uri的区别"+++++++++++
1) request_uri是'浏览器发'起的'不做'任何修改的'原生URI':'不包括'协议及主机名,包含'查询'参数(中文也会原样输出,而不是编码后的),不包含'锚点'信息
2) uri这个变量指当前的请求URI,'不包括任何参数',这个变量反映任何'内部重定向'或index模块所做的修改

location嵌套
④ request相关
+++++++++++"统计客户端发过来的request信息"+++++++++++1)$request
![]()
2)$request_method
![]()
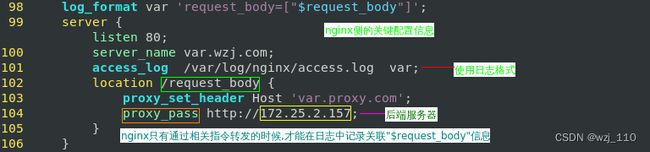
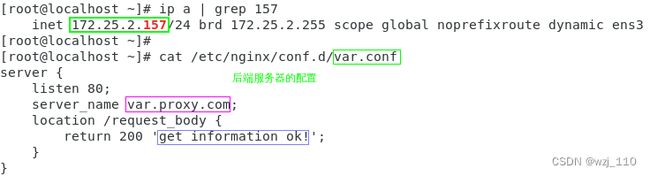
3)$request_body
限制:只有在'location'中用到'proxy_pass、fastcgi_pass、 uwsgi_pass或者scgi_pass'指令时,request body才会被'读取到内存缓冲区'中,$request_body变量才'有值'
通俗'理解':request_body在'未运行'上面所说的proxy_pass等指令配置时,'默认'会被赋值为'空'
备注:直接在'log_format中添加'$request_body,经常会得到'空值'
+++++++++++++"请求方式"+++++++++++++
[1]. 对于'GET'请求,request_body始终是"空"
[2]. 对于'POST'请求,request_body是'参数'信息
+++++++++request_body的'获取'有两种方式+++++++++
1) 使用nginx ngx_http_core模块的$request_body
2) openresty中使用'lua脚本'参考链接
4)$request_length
![]()
含义:nginx统计'cleint'发送'请求数据'长度
注意:由于$request_length是请求解析过程中'不断累加'的,如果解析请求时出现'异常'或'提前完成',则$request_length只是'已经累加部分'的长度,并'不是nginx从客户端收到的完整请求'的总字节数(包括请求行、请求头、请求体)
例如:向nginx的'静态文件'的URL POST数据,则'POST的数据(即请求体)不会计算'在内。5)案例讲解
![]()

说明:'浏览器'和'curl命令'测试'request_length'差异体现在'客户端会自带一些信息',所以'浏览器'发送请求信息会'多一点'
![]()
6)获取$request_body
POST 请求携带请求体 $request_body为什么是空
![]()
![]()
思考:为什么会出现\x22这种格式,如何增加可读性?
![]()
![]()
![]()
7)补充$request_body_file 了解

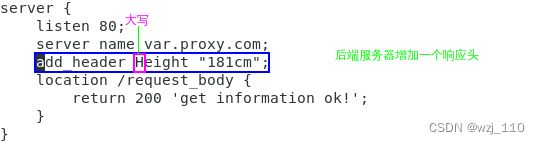
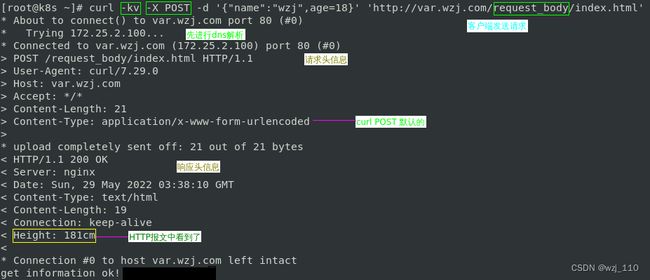
⑤ $sent_http_name
目的:'临时'调试,看后端响应头到底'透传'过来没有,是'被nginx拦截'了还是'就没发送'过来
常用:$sent_http_content_type --> nginx记录'后端返回消息主体'的编码方式


![]()
⑥ content_length content_type
$content_length

$content_length:客户端发送"Content-Length"请求头的值,'等同于'$http_content_length
含义:'nginx从客户端收到'的请求头中Content-Length字段的值,'不是nginx返回'给客户端响应中的Content-Length字段HTTP协议中的Content-Length Content-Type详解 nginx的媒体类型

⑦ $bytes_sent $body_bytes_sent
![]()
$bytes_sent含义:'真正'发送给客户端的'全部的字节数'
场景:对比'client接收数据'和'nginx接收后端数据'是否一致,client下载'中断'场景
++++++++++++"分割线"++++++++++++
$body_bytes_sent: nginx返回给客户端的'响应体'的字节数 ⑧ $request_time
⑧ $request_time
备注:$request_time包括'一次完整HTTP请求'
具体:nginx'接收'客户端请求数据的时间、后端程序'响应'给nginx的时间、nginx'发送'响应数据给客户端的时间(包含写日志的时间),看上面的'拓扑图'
![]()
⑨ 日志

msec:'1970 年 1 月 1 日'到如今的时间,单位为秒,小数点后精确到'毫秒'
time_local:以'本地时间标准'输出的当前时间,例如 14/Nov/2019:15:55:37 +0800
time_iso8601:使用 'ISO8601 标准输出'的当前时间,例如 2019-11-14T15:55:37+08:00![]()
⑩ 其它

应用场景:因此在 limit_req 和 limit_conn 中一般能够'用做 key' ![]()
nginx_version:Nginx '版本号'
pid:所属 'worker 进程'的进程 pid

![]()
![]()
反映:TCP '内核层'参数![]()

应用场景:利用'变量'可以map、可以set'自定义'、可以if'逻辑'判断⑪ $request_id
说明: 之前'没有'关注过这个变量
特点: 整个'代理'过程中,一个请求'对应'一个唯一id
细节: 在发生'内部跳转'的时候可能会'改变',建议使用'uuid',或者'客户端'传递![]()
++++++++++++++++ "生成唯一id" ++++++++++++++++
需求:在微服务架构中,多个微应用'相互'调用,'系统日志排错'显得尤为重要
通过$request_id 可是实现 '客户端->网关服务器->微服务集群A->>微服务集群B ... '实现日志串联
目的:通过trace_id回显,显示'跟踪'每次调用路由,便于'联调'分析
后续:如果日志服务器接'EFK',可通过'trace_id'快速实现单次请求,各微服务间路由日志'复盘'
1、proxy_set_header trace_id $request_id;
2、add_header trace_id $request_id;
3、同时在nginx.conf的'log_format'中加入'$request_id'变量
++++++++++++++++ 'openresty实现' ++++++++++++++++
通过'读取'文件 "/proc/sys/kernel/random/uuid"
local uuid = io.open("/proc/sys/kernel/random/uuid", "r"):read()$request_id在微服务架构中的应用 openresty实现uuid
通过读取文件 /proc/sys/kernel/random/uuid 来生成一个uuid