冯诺依曼+OS+进程+进程状态
索引
- 一.冯诺依曼理解
- 二.OS+ 进程的初步认识
-
- 1.什么是进程?
- 2.如何查看进程
- 3.父进程与子进程
- 4.进程状态
-
- 1.S阻塞态+R运行态
- 2.D阻塞(不可中断)
- 3.Z僵尸状态andX死亡状态
- 4.孤儿进程
- 5,进程死亡之后OS做了什么
- 五.状态总结:
一.冯诺依曼理解

几乎所有的计算机都采用了冯诺依曼体系结构
该结构包括五个基本部件:运算器,控制器,存储器(这里理解成内存不完全正确),输入输出设备
运算器:算术和逻辑运算
控制器:控制程序的执行流程,协调外设,什么时候将数据加载到内存,加载多少,什么时候将内存输出到外设
存储器也就是内存的作用下面详谈
存储器(内存)是什么?:
由于外设的速度非常慢,CPU的速度非常快,存储器的速度介于二者之间,当CPU需要直接进行计算时,存储器提前将数据加载到内存,数据输出时,CPU也直接将数据加载到存储器,再有存储器定期输出至输出设备上。正是有了存储器的存在,才过度平衡了CPU和外设速度不均衡的现状。
为什么要有存储器(内存)的存在?
从技术角度看的话
cpu>寄存器》L1~L3Cache>内存>外设(磁盘)>光盘磁带
成本角度:
寄存器>内存>磁盘(外设)
综上考虑:
内存在我看来就是体系结构一个大缓存,适配外设和CPU速度不均的问题
理解几个问题:
写好的程序编译完成后,在运行之前必须先加载到内存,为什么要这样做?
因为程序编译好之后,他就是磁盘上的一个文件,代码是在磁盘上的,但是cpu计算只和存储器打交道,所以编译好程序之后需要运行的话必须先加载到内存上
OS是如何加载数据的,万一位置的数据加载错了呢?如何保证数据加载到内存就会被立刻使用?
因为计算机在设计优化中有一个基本原则:局部性原理
假设我们读取的是第10行的代码,OS默认我们前后几十行的代码也会被读取,此时加载到内存即可
模拟微信发一条信息?
数据从键盘输入,先加载到内存,再由内存加载到CPU,CPU将各种信息打包,其中一份显示到自身的显示器,另一份传输到存储器,再由存储器发送到网卡,然后网卡通过网线输出到对方的网卡,对方接受到之后,也是由网卡传输到存储器然后由存储器发送到CPU,CPU进行各种解包,然后传输到存储器,再由存储器显示到显示器
二.OS+ 进程的初步认识
OS是一种系统软件,是一种搞管理的软件,可以管理软硬件资源
如何管理?
管理的本质:不是对被管理对象直接进行管理,而是只要拿到被管理对象的相关数据,我们直接对数据管理,就可以达到对对象管理。
所以管理的核心就是:先描述,再组织!!
开发阶段:OS对外表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分接口叫做系统调用
1.什么是进程?
什么是进程?
指正在运行的程序实例,是系统资源分配的基本单位,也是OS中进行任务调度和管理的基本单位。
如何管理进程?
进程本质上是一个程序,是文件,是在磁盘上,OS中可能同时有大量的进程,所以需要将进程管理起来,而管理的本质就是先描述再组织,所以Linux一定对进程用一个很大很大的结构体将进程给描述起来了,这个很大的结构体称为进程控制块PCB,无论是何种操作系统,对进程都有各自的结构体描述进程,Linux操作系统下的PCB是tack_struct
下面是Linux源码中task_struct结构展示
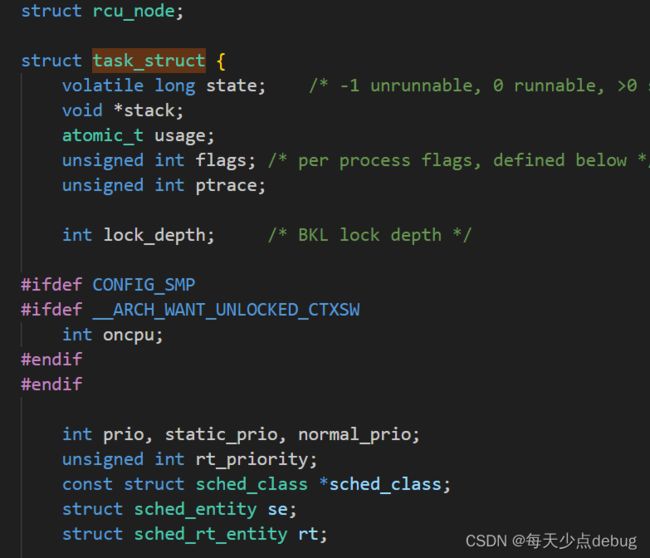
有了这个结构,可以在大体上想象出OS是如何管理进程,多个进程的管理就是将多个进程的task_struct用链表连接起来,此时就是对链表这个数据结构做管理了。
所以最后理解进程是什么?
进程 = 可执行程序 + 该进程对应的内核数据结构
task_struct内容分类
标识符:描述本进程的唯一标识符,用来区别其他进程。
状态:任务状态,退出代码,退出信号等
优先级:相对于其他进程的优先级
程序计数器:程序中即将被执行的下一条指令的地址
内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
**上下文数据:**进程执行时处理器的寄存器的数据
I/O状态信息:包括显示的I/O请求,分配给进程I/O设备和被进程使用的文件列表
等等其他信息
2.如何查看进程
#include查看进程的第一种方式

我们自己写的代码编译成可执行程序启动之后是一个进程,别人写的类似于Linux指令他们也是进程

Linux自带的命令在usr/bin目录底下,自带的命令启动后也是一个进程
理解当前路径:当前路径就是进程所在路径,进程会自己维护,并不是源代码所在路径
3.父进程与子进程

观察上述运行现象可以发现,每一次子进程的pid都会发生变化,但是ppid也就是父进程id不会发生改变,为什么呢?
几乎我们在命令行上所执行的所有指令(cmd),都是bash进程的子进程,除bash创建子进程外,我们自己还可以用代码创建子进程:fork()
fork()函数创建一个子进程
该函数有两个返回值,父进程返回子进程的pid,子进程返回0,根据返回值判断父子进程,问为什么(篇幅下面解答)?
且fork之后,父子进程会共享代码,一般会同时执行后续的代码,但根据fork之后的返回值不同条件让父子进程执行不同代码
#include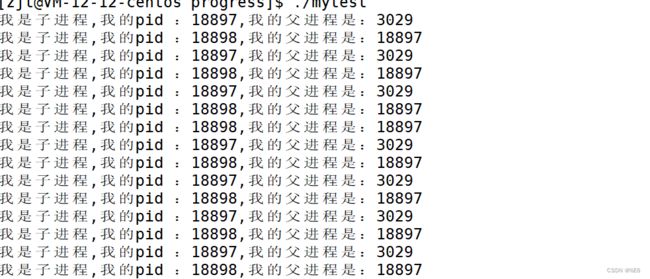
问:为什么给父进程返回子进程的pid,给子进程返回0?
因为父亲:儿子 = 1:n(n>=1)
父进程必须要有表示子进程的方案,因为父进程要能够控制子进程的退出,fork之后,给父进程返回子进程的pid,而子进程最重要的是知道自己被创建成功了,因为子进程找父进程的成本非常低,只需要getppid()就可以了
如何理解进程被运行?
进程被运行,就是OS将进程的进程控制块放到cpu调度器中等待调用,说到进程其实就是与task_struct有关。
4.进程状态
谈到进程状态,对于整体操作系统

大致有很多,但是学不清楚,下面针对Linux操作系统针对性学习状态
主要讲的是Linux下进程状态,其他操作系统类比即可
kernel源码状态定义
static const char * const task_state_array[] = {
"R (running)", /* 0 */[重点]
"S (sleeping)", /* 1 */[重点]
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */[重点]
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */[重点]
};
Linux操作系统进程状态分类
进程状态:
R:运行状态
S:睡眠状态
D:磁盘休眠状态
T:停止状态
X:死亡状态
Z:僵尸状态
在Linux下
R运行态: ,表示进程已经准备好了,随时可以调度!
T终止状态,该进程还在,只不过永远不运行罢了,随时等待释放问题:进程都终止了,为什么不立马释放对应的资源呢?而是维护一个终止态,维护资源也是要耗费资源的 释放是要花时间的,如果OS很忙,此时就没时间去释放你,只要终止的进程发出一个信号告诉操作系统不要再调度我了。
1.S阻塞态+R运行态
一个进程,使用资源的时候,可不仅仅是在CPU中申请资源的,进程可能申请更多的其他资源:如磁盘网卡,显卡,声卡等

进程被调度的时候,就是根据优先级排队形成队列的过程,只是进程被调度申请的时候CPU资源,同理,我们申请其他慢设备的资源也是需要排队的,每个慢设备自身都维护了一个运行队列,当进程访问某些资源(磁盘网卡),该资源如果暂时没有准备好,或者正在给其他进程提供服务此时
- 1 当前进程需要从runqueue中移除
- 2 将当前进程放入对应慢设备的描述结构体中的等待队列,当该资源准备就绪的时候,才会被重新放入runqueue中
当我们的进程此时在等待外部资源的时候,该进程的代码不会被执行,此时就表示成进程卡主了,也就是进程阻塞
while(1)
27 {
28 cout<<"i am a process: %d"<<getpid()<<endl;
29 sleep(1);
30 }

此时查看进程的状态显示是S,也就是阻塞状态,因为这个程序90%的情况都在等,因为显示器的外设太慢了,等显示器就绪,所以这个进程的状态处于S
while(1)
27 {
28 // cout<<"i am a process: %d"<
29 // sleep(1);
30 }

此时这个进程不访问任何外设也就不会有任何等待,此时进程的PCB就是在等待队列移来移去,此时的进程处于一种r运行状态
S状态时,等待的资源不就绪,操作系统唤醒她,由s–>R是一种前度睡眠,可以被OS随时唤醒,我们自己也可随时中断
2.D阻塞(不可中断)
服务器压力过大,OS是会终止用户进程的

D状态也叫做深度睡眠,不可被中断睡眠,OS无法杀掉进程,只能等D状态睡眠自己醒过来,也就是等磁盘读写完毕给出回应,D状态也就变成了R状态,此时kill -9无法杀死
3.Z僵尸状态andX死亡状态
Linux中一个进程退出的时候,一般不会直接进入X(死亡状态)而是进入Z(僵尸状态),因为进程被创造出来的时候一定是为了完成一个任务的,当进程退出的时候,我们无法知道进程是否完成任务了,一般要将进程的执行结果告知给父进程,所以进程退出的时候维持一个Z状态,为了维护进程的退出信息,可以放父进程或者OS系统读取,信息的读取是通过进程等待来读取的。
现在模拟一个僵尸进程
如果创建子进程,子进程退出了,父进程不退出,也不等待子进程,子进程的状态就会变成僵尸进程
using namespace std;
5 int main()
6 {
7 pid_t id = fork();
8 if(id == 0)
9 {
10 //child
11 int cnt = 5;
12 while(cnt)
13 {
14 cout<<"我是子进程,我还剩下:"<<cnt--<<"秒"<<endl;
15 sleep(1);
16 }
17 cout<<"我是子进程,我已经僵尸了,等待被检测"<<endl;
18 exit(0);
19 }
20 else
21 {
22
23 while(1)
24 {
25 cout<<"我是父进程,我永不退出"<<endl;
26 sleep(1);
27 }
28
29 }

问:长时间僵尸进程会有什么问题?
如果没有人回收子进程的僵尸,该状态会一直维持,维护状态本身也是需要数据维护的,也是属于进程的基本信息,所以保存在task_struct(PCB)中,换句话说,Z状态一直不退出,PCB就需要被维护,因此,如果一个父进程创建了很多子进程,一直不回收的话,就造成了会有内存资源的浪费也就是内存泄漏,所以如何避免呢?(后面说,涉及到进程等待和信号)
4.孤儿进程
如果父进程先退出了,子进程没有退出,此时子进程就会变成孤儿进程,一般情况下被操作系统进程init接管并回收其资源,如果系统进程init也无法回收孤儿进程资源,那么该孤儿进程就会一直存在,直到系统重启。
5,进程死亡之后OS做了什么
操作系统会维护进程资源的释放和回收,并向进程的父进程发送SIGCHLD信号通知其子进程已经死亡,如果父进程没有及时处理信号,则操作系统会维护进程的状态为僵尸进程,直到父进程回收其进程
五.状态总结:
Linux中的状态对应操作系统中的状态
