深入理解MySQL原理之一--如何提升查询SQL的性能
附:
深入理解MySQL原理之一--如何提升查询SQL的性能
深入理解MySQL原理之二--如何建立高效索引
深入理解MySQL原理之三--如何实现事务与分库分表
深入理解MySQL原理之四--如何实现高可用
深入理解MySQL原理之五--如何高效利用InnoDB存储引擎
深入理解MySQL原理之六--核心算法有哪些
深入理解MySQL原理之七--云原生时代将何去何从
一、前言
本系列博客将针对MySQL的核心技术和实现原理,结合大量实践经验进行探讨,希望对您有所帮助。
慢查询是我们开发过程中常见的问题, 也是数据库面试的必考题。本章我们将了解到以下内容:
1、查询SQL在MySQL服务端有哪些执行阶段,每个执行阶段完成哪些功能?
2、MySQL如何进行查询优化?
3、针对性能的提升,开发过程中有哪些注意事项
二、一条查询SQL的旅行史
当我们写下一条SQL(select * from userinfo where username='guest'),MySQL会将这条语句的查询结果返回给客户端,这条SQL如何在MySQL得到解析和执行的,我们总览下这条sql的旅行史。
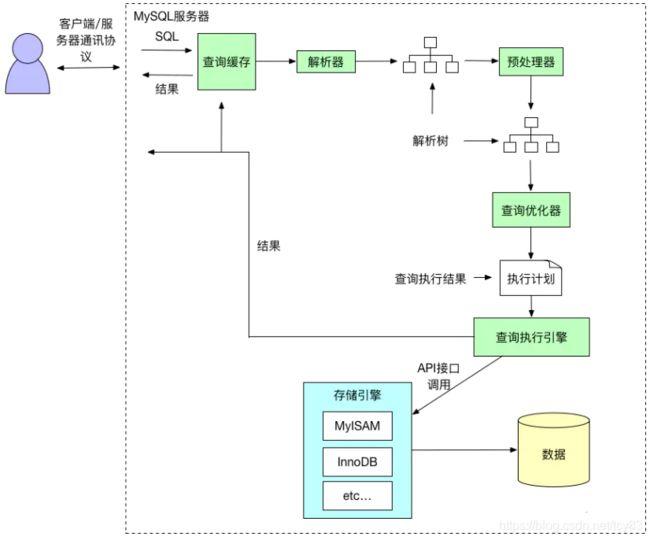
1、客户端发送一条查询SQL给服务器。
2、服务器先检查缓存,如果命中了缓存,就立刻返回存储在缓存中的结果,否则进入下一阶段。
3、服务器进行SQL解析,预处理,再由优化器生成对应的执行计划。
4、MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询。
5、存储引擎将查询的结果返回给客户端。
下面我们逐个详细分析其过程,开启神奇之旅。
三、客户端通讯
1、通讯协议
在客户端编程时,我们需要配置mysql服务器的连接url,连接用户名和密码。
url=jdbc:mysql://127.0.0.1:3306/testdb
username=root
password=password客户端使用JDBC实现与服务端建立连接,其底层采用的TCP协议与服务端的3306端口进行通讯,并支持长链和短链两种方式,短链表示操作完成后立即释放掉,频繁的创建(三次握手)和销毁(四次握手)会带来性能的损耗和延迟。
长链在操作完成后,链接依旧保持打开状态,也就可以利用该链路继续发送数据,但是维持链路状态需要消耗内存,长时间不活动(超时时间)的链接需要及时的断开,使用如下指令查看超时时间,默认是8小时。
show global variables like 'wait_timeout';在实际项目过程中,通常使用连接池来管理连接,比如常用的有DBCP,C3P0等。通过以下指令查看服务端最多能支持多少个连接。
show VARIABLES like 'max_connections'2、通讯方式
一般情况下,TCP有三种通讯方式,单工,双工,半双工。

MySQL采用的是"半双工"模式,意味着任何一个时刻,要么是由服务器向客户端发送数据,要么是由客户端向服务端发送数据,这两个动作不能同时进行。
很显然,这种方式对于MySQL来说,控制起来比较简单。但是也带来了诸多限制。
对于客户端来说,需要一次性将请求的数据发送过去,不能分割成多个块,比如插入10W条数据,后面跟着一长串内容,有可能发送包大小超限的,要调整max_allowed_packet参数,默认是4M。
show VARIABLES like 'max_allowed_packet'对于服务端来说,执行完成后,将结果一次性返回给客户端,如果执行时间长,结果集大,会存在以下问题:
(1)客户端等待时间长,在服务器执行的期间,客户端是阻塞住的,干不了任何事。
(2)传输时间长,带宽资源消耗大。
(3)全部结果集默认是需要在客户端缓存的,在客户端处理前,内存是无法得到释放。
所以,按需获取数据显得尤为重要,不要尝试一次性获取全部数据,尽量使用limit进行分页查询。
四、查询缓存
建立连接,并发送查询select请求后,MySQL首先检查缓存中是否已存在该查询的结果,如果命中,则直接返回结果,该SQL的旅行提前结束;否则则进入下一阶段。
缓存对于我们是不陌生的,比如大名鼎鼎的redis,memcache等。MySQL的缓存存放一个引用表,通过一个哈希值引用,哈希值包含如下因素:查询本身,要查询的数据库,客户端协议等。
缓存的一般作用加速读取数据,提升查询性能,但是对于MySQL来说,还真不一定。主要是存在诸多的限制。
1、sql的限制,sql中有不确定的数据,包括函数,存储变量,用户变量,临时表等,都不会被缓存;并且大小写不同,多个空格都认为是不同的sql。这样严格的限制,大大降低了命中率。
2、失效策略,只要相关的表数据发送变化,如有数据更新,增加,无论是否影响缓存的查询结果,全部失效。这点对于写操作多的情况下,影响是很大的。想象一下,一条查询结果,好不容易缓存起来(缓存操作也是有代价的),还没来的及发挥作用,此时写入导致了失效(又要付出代价),偷鸡不成蚀把米。
那么MySQL的缓存什么时候有效果呢?具体问题要具体分析,一般原则是:
1、读多写少的场景,不要频繁失效。
2、需要消耗大量资源查询的场景,比如汇总操作,复杂的select语句,比如JOIN后分页排序。
总之,专业的事交由专业的组件,Mysql的优势是数据的持久化和一致性,缓存就由ORM框架搞定,比如redis。
MySQL在默认状态下,是关闭该选项的,可以通过如下指令查看:
show variables like 'query_cache_type';五、解析器与预处理器
解析器是将sql语句,根据关键字解析并生成一颗"解析树"(SELECT_LEX),比如“select * from userinfo where username='guest”.
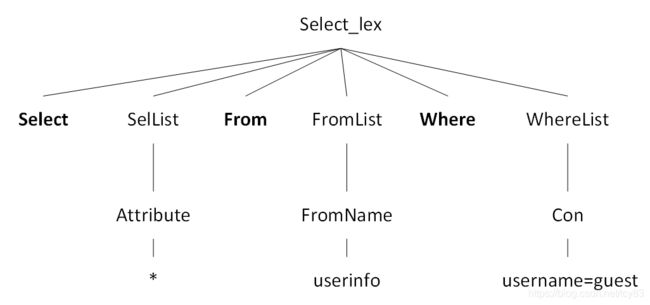
解析树类似代码的抽象语法数(AST),那么生成这么一颗树的目的是什么?主要是语法验证以及为后续的优化做准备。对于语法验证,主要校验是否使用了错误的关键字,关键字的使用顺序是否正确等等。比如一不小心写成了"select from userinfo where username='guest",执行就会报错,缺少了SelList,就是在这步检查出来的。
预处理器则是更进一步检查解析树是否合法,将检查数据表和数据列是否存在,还会解析名字和别名,检查是否有歧义。比如写错了表名“select * from user_info where username='guest'”,预处理器将会校验出来。
总之,在此阶段,将语法性、数据性错误提前暴露出来。
六、查询优化
我们写了一条合法sql查询语句,MySQL是不是就按照我们给的执行呢?答案是否定的,一条sql有很多执行方式,优化器找出一条认为最优的执行方式。查询优化是mysql引擎最核心的,也是最复杂的部分,其中包含了大量的算法。这里我们结合我们开发过程中经常遇到的场景重点介绍,算法部分参见深入理解MySQL原理之六--核心算法原理。
整个优化过程可以分为逻辑优化和物理优化。
1、逻辑优化
逻辑优化是指按照语法规则进行优化,其中包括子查询优化,等价谓词重写,条件简化等。
(1)子查询优化
经常听到抱怨mysql对于子查询支持不友好,嵌套查询效率低下,应该换成连接,在早期版本中确实是这样,但是在5.6版本之后情况大大改善了,不应该视子查询为虎了。
1、子查询的分类
从返回的结果集分类分为:
- 标量子查询,只返回一个单一值的子查询,比如:
select * from t1 where a in (select max(a) from t2);- 列子查询,结果集类型是一个列,但是很多条记录
select * from t1 where a in (select a from t2);- 行子查询,结果集类型是一条行记录,但是多个列
select * from t1 where (a,b) in (select a,b from t2 limit 1);- 表子查询,结果集类型即包含很多记录,又包含很多列
select * from t1 where (a,b) in (select a,b from t2);从与外层查询关系看分为:
- 相关子查询,子查询的执行依赖外层的某些属性值。
select * from t1 where a in (select a from t2 where t1.a = t2.a);- 不相关子查询,子查询可以独立运行结果,不依赖外层的查询值
select * from t1 where a in (select a from t2);从子查询语句出现的位置可以分为:
- 目标位置,子查询位于目标列,则只能是标量子查询。
- from子句,相当于派生表,只能是不相关的子查询,可上拉到外层查询,后面会有实例介绍。
- where子句,这种情况比较多,可以和操作符结合使用,比如<,>,=,<>等,类型是标量子查询,也可以和谓词结果,比如IN,BETWEEN,EXITS等。后面重点介绍
- join/on,join类似于from,on类似于where,处理方式也类似。
- group by,可以写在group by位置处,但没有实际意义。
- order by,可以写在order by处,但没有实际意义。
2、典型的子查询优化
下面我们看下几种典型的子查询优化
- IN子查询优化
IN的子查询是我们经常用到的,有两张表,student和teacher,先不创建主键,每张表插入一些数据(本例20条)
CREATE TABLE `student` (
`studentid` int(11) NOT NULL,
`studentname` varchar(45) NOT NULL,
`teacherid` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE TABLE `teacher` (
`teacherid` int(11) NOT NULL,
`teachername` varchar(45) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci看下执行下面的查询语句,where条件中包含一个子查询。
explain select * from student where teacherid in (select teacherid from teacher);执行计划如下:
![]()
其执行过程如下:
1)先执行子查询语句select teacherid from teacher,将结果集放入到临时表,该临时表就是子查询结果集的列,并进行去重。如果结果集不大,建立基于内存的Memory存储引擎的临时表,并建立hash索引;如果结果集非常大,超过了系统变量tmp_table_size或者max_heap_table_size,临时表会转而使用基于磁盘的存储引擎来保存结果集中的记录,索引类型也对应转变为B+树索引。
结果集记录保存到临时表的过程,称之为物化(Materialize),该临时表称之为物化表。
2)物化之后,对于student表,如表记录的teacherid值在物化表中,会记录到最终的结果集;同样对于物化表,其每个列值(teacherid)在student表能找到对应列的值,就能写到最终结果集。所以就相当于student表与物化表(materialize_table)内联。
select * from student s inner join materialized_table on s.teacherid = m_val通过临时表,并添加索引,将子查询转化为join,能提高效率,但是建立临时表也损耗了性能,能否直接使用内联呢?我们看下面两个sql
select * from student where teacherid in (select teacherid from teacher);
select * from student s inner join teacher t on s.teacherid = t.teacherid;两者非常像,但是后一种sql结果集没有去重,也不完全等价,所以MySQL使用了一个新概念半连接(semi join)
再看下优化后的sql语句(执行show warnings)
/* select#1 */ select `world`.`student`.`studentid` AS `studentid`,`world`.`student`.`studentname` AS `studentname`,`world`.`student`.`teacherid` AS `teacherid` from `world`.`student` semi join (`world`.`teacher`) where (``.`teacherid` = `world`.`student`.`teacherid`) 其sql的表现就是student与teacher进行了半连接,其意思是对于student表的记录来说,只关心在teacher表中,是否有对应的值匹配,而不关注有几条,最终只显示student的记录。
半连接是内部采用的一种优化查询方式,并没有提供给用户使用。
我们将这teacher表的teacherid设置为主键
ALTER TABLE `world`.`teacher`
ADD PRIMARY KEY (`teacherid`);
再来执行下前面的语句:
![]()
/* select#1 */ select `world`.`student`.`studentid` AS `studentid`,`world`.`student`.`studentname` AS `studentname`,`world`.`student`.`teacherid` AS `teacherid` from `world`.`teacher` join `world`.`student` where (`world`.`teacher`.`teacherid` = `world`.`student`.`teacherid`)通过设置主键,子查询结果集就已经去重了,所以就通过表上拉(Table pullout),优化成连接,从而消除了子查询。所以对于in子查询语句,建立子查询索引能提升效率。
下面几种场景的in子查询是无法优化成半连接的。
1)外层查询的WHERE条件中有其他搜索条件与IN子查询组成的布尔表达式使用OR连接起来
2) 使用NOT IN而不是IN的情况
3)子查询中包含GROUP BY、HAVING或者聚集函数的情况
4) 子查询中包含UNION的情况
- 派生表优化
我们经常会用子查询派生一些表,比如:
select * from (select studentname from world.student ) s;优化后就等同于
select studentname from world.student再来个复杂些的
select * from (select * from world.student s where s.teacherid=1) s1 inner join world.teacher t on s1.teacherid= t.teacherid;优化后等同于
select * from world.student s1 inner join world.teacher t on s1.teacherid= t.teacherid where s1.teacherid=1;以上两个实例,派生表没有单独作为查询记录临时表,而是和外层表合并,消除了派生表。同样,有些情况是无法消除的。
1)聚集函数,比如MAX()、MIN()、SUM()啥的
2)DISTINCT
3)GROUP BY
4)HAVING
5)LIMIT
6)UNION 或者 UNION ALL
7)派生表对应的子查询的SELECT子句中含有另一个子查询。
(2)等价谓词重写
MySQL对于等价谓词重写支持度较差,仅支持NOT谓词等价重写,如下:
select * from world.student where NOT(studentid>100)转化为:
/* select#1 */ select `world`.`student`.`studentid` AS `studentid`,`world`.`student`.`studentname` AS `studentname`,`world`.`student`.`teacherid` AS `teacherid` from `world`.`student` where (`world`.`student`.`studentid` <= 100)由于studentid是主键索引,所以重写为`world`.`student`.`studentid` <= 100,可以使用索引扫描,避免了全表扫描。
(3)条件简化
通过对条件的合并和简化,规范表达式,减少一些比较操作。主要包括:
- 常量的传递,比如((a5 and b=c and a=5)。
- 消除死码,比如(where 0>1 and a=6),其实就是 where false,该条件不会执行。
- 不等式转换,比如 a>10 and b=6 and a>2,改写成a>10 and b=6。
- 表达式计算,比如where a=1+2,会转换为where a=3
(4)外连接消除
MySQL常用的外连接包括左外连接(left join),右外连接(right join)。在某些场景下,消除外连接并将之转化为内连接。这样做的好处是:
- 优化器在处理外连接操作时所需要的时间和操作要多于内连接。
- 优化器在选择表连接顺序时,可以有更多更灵活的选择,从而可以选择更好的表连接顺序,加快执行的速度。
下面我们就来研究下"某些场景"是什么。
先创建两个表:
CREATE TABLE `test_1` (
`test_1_a` int(11) DEFAULT NULL,
`test_1_b` varchar(45) DEFAULT NULL,
UNIQUE KEY `test_1_a_UNIQUE` (`test_1_a`)
) ;
CREATE TABLE `test_2` (
`test_2_a` int(11) DEFAULT NULL,
`test_2_b` varchar(45) DEFAULT NULL,
UNIQUE KEY `test_2_a_UNIQUE` (`test_2_a`)
);
再分别插入一些数据:
INSERT INTO test_1 (`test_1_a`,`test_1_b`) VALUES (1,'t11');
INSERT INTO test_1 (`test_1_a`,`test_1_b`) VALUES (2,'t12');
INSERT INTO test_1 (`test_1_a`,`test_1_b`) VALUES (3,'t13');
INSERT INTO test_1 (`test_1_a`,`test_1_b`) VALUES (4,'t14');
INSERT INTO test_1 (`test_1_a`,`test_1_b`) VALUES (5,'t15');
INSERT INTO test_1 (`test_1_a`,`test_1_b`) VALUES (6,'t16');
INSERT INTO test_2 (`test_2_a`,`test_2_b`) VALUES (1,'t21');
INSERT INTO test_2 (`test_2_a`,`test_2_b`) VALUES (2,'t22');
INSERT INTO test_2 (`test_2_a`,`test_2_b`) VALUES (3,'t23');
INSERT INTO test_2 (`test_2_a`,`test_2_b`) VALUES (4,'t24');
INSERT INTO test_2 (`test_2_a`,`test_2_b`) VALUES (5,'t25');
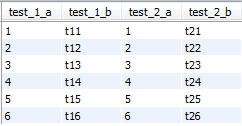
INSERT INTO test_2 (`test_2_a`,`test_2_b`) VALUES (6,'t26');我们分别看下面两个sql结果
第一条:
select * from world.test_1 t1 left join world.test_2 t2 on t1.test_1_a=t2.test_2_a;第二条:
select * from world.test_1 t1 left join world.test_2 t2 on t1.test_1_a=t2.test_2_a where t1.test_1_a=t2.test_2_a;第二条比第一条多了一个where条件,这两条sql执行的结果是一样的。
再看下优化的结果
第一条:
/* select#1 */ select `world`.`t1`.`test_1_a` AS `test_1_a`,`world`.`t1`.`test_1_b` AS `test_1_b`,`world`.`t2`.`test_2_a` AS `test_2_a`,`world`.`t2`.`test_2_b` AS `test_2_b` from `world`.`test_1` `t1` left join `world`.`test_2` `t2` on((`world`.`t2`.`test_2_a` = `world`.`t1`.`test_1_a`)) where 1
第二条:
/* select#1 */ select `world`.`t1`.`test_1_a` AS `test_1_a`,`world`.`t1`.`test_1_b` AS `test_1_b`,`world`.`t2`.`test_2_a` AS `test_2_a`,`world`.`t2`.`test_2_b` AS `test_2_b` from `world`.`test_1` `t1` join `world`.`test_2` `t2` where (`world`.`t1`.`test_1_a` = `world`.`t2`.`test_2_a`)
执行结果一样,但是优化的结果是不一样的,第二条语句由外联转化成内联,第一条依然是左联接,why?发生了什么?
我们向第一张表再插入一条数据。
INSERT INTO test_1 (`test_1_a`,`test_1_b`) VALUES (7,'t17');此时,第一条sql的执行结果
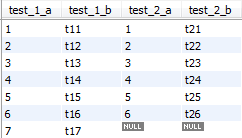
第二条sql执行结果
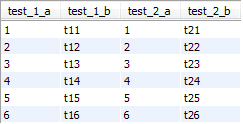
区别出来了,第一条执行结果比第二条多了一条记录,该记录中test_2的表字段值都是NULL,第二条sql由于增加了where t1.test_1_a=t2.test_2_a条件,使得这条记录不符合条件,过滤掉了。所以我们来总结下前面提到的"某些场景",就是右表不能有空值记录(不能有匹配不到的记录),就是所谓的"空值拒绝"。
第二条sql可以写成:
select * from world.test_1 t1 inner join world.test_2 t2 on t1.test_1_a=t2.test_2_a;对于右连接,也是同样的道理,一般msyql会将其从语义上转成左连接再优化。
在实际开发中,是使用左连接,还是用内连接呢?主要看业务需要,符合内联接需求就尽量使用内连接,但是如果业务不满足,比如本例中,必须要显示第7条记录,那就没有办法了。
(5)嵌套连接消除
多表连接时会存在嵌套的情况,由于业务的需求,需要有些连接先执行,这样一来连接次序固定了,无法灵活调整,从而影响求解不同连接方式的花费。但在有些情况下,嵌套是可以通过优化器消除的。
我们再增加一张表
CREATE TABLE `test_3` (
`test_3_a` int(11) DEFAULT NULL,
`test_3_b` varchar(45) DEFAULT NULL,
UNIQUE KEY `test_3_a_UNIQUE` (`test_3_a`)
)插入一些数据:
INSERT INTO test_3 (`test_3_a`,`test_3_b`) VALUES (1,'t31');
INSERT INTO test_3 (`test_3_a`,`test_3_b`) VALUES (2,'t32');
INSERT INTO test_3 (`test_3_a`,`test_3_b`) VALUES (3,'t33');
INSERT INTO test_3 (`test_3_a`,`test_3_b`) VALUES (4,'t34');
INSERT INTO test_3 (`test_3_a`,`test_3_b`) VALUES (5,'t35');
INSERT INTO test_3 (`test_3_a`,`test_3_b`) VALUES (6,'t36');看下面的sql以及其优化的结果
select * from world.test_1 t1 left join (world.test_2 t2 left join world.test_3 t3 on t2.test_2_a = t3.test_3_a) on t1.test_1_a = t2.test_2_a;/* select#1 */ select `world`.`t1`.`test_1_a` AS `test_1_a`,`world`.`t1`.`test_1_b` AS `test_1_b`,`world`.`t2`.`test_2_a` AS `test_2_a`,`world`.`t2`.`test_2_b` AS `test_2_b`,`world`.`t3`.`test_3_a` AS `test_3_a`,`world`.`t3`.`test_3_b` AS `test_3_b` from `world`.`test_1` `t1` left join (`world`.`test_2` `t2` left join `world`.`test_3` `t3` on((`world`.`t3`.`test_3_a` = `world`.`t1`.`test_1_a`))) on((`world`.`t2`.`test_2_a` = `world`.`t1`.`test_1_a`)) where 1
嵌套括号还在,没有消除。我们将左连接改成内连接
select * from world.test_1 t1 inner join (world.test_2 t2 inner join world.test_3 t3 on t2.test_2_a = t3.test_3_a) on t1.test_1_a = t2.test_2_a;/* select#1 */ select `world`.`t1`.`test_1_a` AS `test_1_a`,`world`.`t1`.`test_1_b` AS `test_1_b`,`world`.`t2`.`test_2_a` AS `test_2_a`,`world`.`t2`.`test_2_b` AS `test_2_b`,`world`.`t3`.`test_3_a` AS `test_3_a`,`world`.`t3`.`test_3_b` AS `test_3_b` from `world`.`test_1` `t1` join `world`.`test_2` `t2` join `world`.`test_3` `t3` where ((`world`.`t3`.`test_3_a` = `world`.`t2`.`test_2_a`) and (`world`.`t1`.`test_1_a` = `world`.`t2`.`test_2_a`))
嵌套消失了,所以,对于所有连接都是内连接来说,嵌套可以消除,次序可以灵活交换;连接表达式包含外连接,嵌套不可以消除,次序也不可以交换。
(6)索引排序优化(order by)
我们新建一张表
CREATE TABLE `test_4` (
`test_4_a` int(11) DEFAULT NULL,
`test_4_b` varchar(45) DEFAULT NULL,
`test_4_c` varchar(45) DEFAULT NULL,
`test_4_d` varchar(45) DEFAULT NULL,
UNIQUE KEY `test_4_a_UNIQUE` (`test_4_a`),
KEY `test_4_b_c` (`test_4_b`,`test_4_c`)
)test_4_a为唯一索引(注意:非主键索引),"test_4_b和“”test_4_c"复合索引
第一种情况:
我们执行如下的SQL
explain SELECT * FROM world.test_4 t4 order by t4.test_4_a asc;执行计划如下
![]()
type为ALL表示使用的是全表扫描,extra为using filesort,表示进行了文件排序,所以没有利用索引进行排序操作。因为涉及到回表查询,所以MySQL无法直接使用索引,这个将在深入理解MySQL原理之六--核心算法有哪些探讨。
我们再执行如下的Sql
explain SELECT test_4_a FROM world.test_4 t4 order by t4.test_4_a asc;执行计划如下:
![]()
type为index表示使用的是索引扫描,Extra为Using index,表示进行了索引排序。由此,只有对索引列查询时,才能使用索引排序。这也是为什么做索引覆盖来提升效率,
第二种情况:
将test_4_a修改为主键索引
ALTER TABLE `test_4`
MODIFY COLUMN `test_4_a` int(11) NOT NULL FIRST ,
ADD PRIMARY KEY (`test_4_a`);再执行:
explain SELECT * FROM world.test_4 t4 order by t4.test_4_a asc;执行计划
![]()
与第一种情况比较,主键索引无需回表,所以可以直接利用。
第三种情况:
执行如下SQL:
explain SELECT test_4_b,test_4_c FROM world.test_4 t4 order by t4.test_4_b,t4.test_4_c asc;执行计划如下:
![]()
查询的列为索引列,使用索引排序,没有问题。
换下排序优先级顺序,与索引的顺序不一致,再执行
explain SELECT test_4_b,test_4_c FROM world.test_4 t4 order by t4.test_4_c,t4.test_4_b asc;执行计划如下:
![]()
用到了文件排序
第四种情况:
一个使用升序,一个使用降序,执行如下SQL
explain SELECT test_4_b,test_4_c FROM world.test_4 t4 order by t4.test_4_b asc,t4.test_4_c desc;执行计划如下:
![]()
同样使用了文件排序。
下面我们总结下:
1、Mysql支持索引排序和文件排序,索引排序效率高于文件排序。
2、Mysql支持索引排序的是有条件限制的,排序字段非主键索引情况下,需要满足排序字段和查询字段同时为索引字段,一般采用覆盖索引。
3、多字段排序,排序不是按照索引的顺序,或者存在升降序并存,使用文件排序。
(7)索引分组优化(group by)
与上面一样,我们分几种情况
第一种情况
执行SQL:
explain SELECT * FROM world.test_4 t4 group by t4.test_4_a;执行计划

没有使用到索引优化,再来执行
explain SELECT t4.test_4_a FROM world.test_4 t4 group by t4.test_4_a;执行计划如下:
![]()
使用到了索引优化,由此,与排序一样,只有对索引列查询时,才能使用索引分组。
第二种情况:
多字段分组,分组字段的顺序与索引顺序不一致
explain SELECT t4.test_4_b,t4.test_4_c FROM world.test_4 t4 group by t4.test_4_c,t4.test_4_b;执行的计划
![]()
使用了临时表。
(8)索引去重优化(distinct)
执行如下sql:
explain SELECT distinct t4.test_4_b FROM world.test_4 t4 执行计划如下:
![]()
使用索引去重优化,由此,只有对索引列查询时,才能使用索引去重。
2、物理优化
逻辑优化阶段,主要是使用关系代数规则进行优化,可以认为是定性的分析。物理优化阶段,对每一个可能的执行方式进行代价评估,做定量的分析,从而得出代价最小的。
MySQL代价模型估算主要考虑io和cpu的代价,分为server层和engine层。server层主要是cpu的代价,而engine层主要是io的代价。可以通过两个系统表mysql.server_cost和mysql.engine_cost来分别配置这两个层的代价。
先看下mysql.server_cost的默认配置
- disk_temptable_create_cost(default 20),在磁盘上创建临时表的代价
- disk_temptable_row_cost(default 0.5),在磁盘上创建临时行的代价
- key_compare_cost(default 0.05),键比较的代价,例如排序
- memory_temptable_create_cost(default 1),在内存创建临时表的代价
- memory_temptable_row_cost(default 0.1),在内存创建临时行的代价
- row_evaluate_cost(default 0.1),计算符合条件的行的代价,行数越多,此项代价越大。
mysql.server_cost的默认配置
- io_block_read_cost(default 1),从磁盘读数据的代价,对innodb来说,表示从磁盘读一个page的代价
- memory_block_read_cost,从内存读取数据的代价,对innodb来说,表示从buffer pool读一个page的代价。
通过这些模型数据,计算出每种执行方式的代价值,代价最小的最优。
下面我们来看一个例子。
先创建一张表,
CREATE TABLE `t1` (
`c1` int(11) NOT NULL,
`c2` int(11) DEFAULT NULL,
`c3` int(11) DEFAULT NULL,
PRIMARY KEY (`c1`),
UNIQUE KEY `c2_UNIQUE` (`c2`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_cic1为主键,c2为唯一索引,并插入100条数据。
第一种情况
explain SELECT t.c1,t.c2 FROM world.t1 t where t.c2>10;![]()
可以看到使用的索引扫描,再看下OPTIMIZER_TRACE
"rows_estimation": [
{
"table": "`world`.`t1` `t`",
"range_analysis": {
"table_scan": {
"rows": 100,
"cost": 13.1
} /* table_scan */,
"potential_range_indexes": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "c2_UNIQUE",
"usable": true,
"key_parts": [
"c2"
] /* key_parts */
}
] /* potential_range_indexes */,
"best_covering_index_scan": {
"index": "c2_UNIQUE",
"cost": 11.109,
"chosen": true
} /* best_covering_index_scan */,
"setup_range_conditions": [
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
} /* group_index_range */,
"skip_scan_range": {
"potential_skip_scan_indexes": [
{
"index": "c2_UNIQUE",
"usable": false,
"cause": "prefix_not_const_equality"
}
] /* potential_skip_scan_indexes */
} /* skip_scan_range */,
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "c2_UNIQUE",
"ranges": [
"10 < c2"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": true,
"rows": 91,
"cost": 10.209,
"chosen": true
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */,
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "c2_UNIQUE",
"rows": 91,
"ranges": [
"10 < c2"
] /* ranges */
} /* range_access_plan */,
"rows_for_plan": 91,
"cost_for_plan": 10.209,
"chosen": true
} /* chosen_range_access_summary */
} /* range_analysis */
}
] /* rows_estimation */
全表扫描的估算代价值是13.1,索引扫描的估算代价值是10.209,所以选择的是索引扫描。
第二种情况
执行如下sql,与上面不一样的是,目标列是所有字段。
explain SELECT * FROM world.t1 t where t.c2>10;![]()
可以看到使用的是全表扫描,再看下OPTIMIZER_TRACE
"rows_estimation": [
{
"table": "`world`.`t1` `t`",
"range_analysis": {
"table_scan": {
"rows": 100,
"cost": 13.1
} /* table_scan */,
"potential_range_indexes": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "c2_UNIQUE",
"usable": true,
"key_parts": [
"c2"
] /* key_parts */
}
] /* potential_range_indexes */,
"setup_range_conditions": [
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
} /* group_index_range */,
"skip_scan_range": {
"potential_skip_scan_indexes": [
{
"index": "c2_UNIQUE",
"usable": false,
"cause": "query_references_nonkey_column"
}
] /* potential_skip_scan_indexes */
} /* skip_scan_range */,
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "c2_UNIQUE",
"ranges": [
"10 < c2"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 91,
"cost": 101.11,
"chosen": false,
"cause": "cost"
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */
} /* range_analysis */
}
] /* rows_estimation */
全表扫描的估算代价值和第一种情况是相同的,都是13.1,索引扫描的估算代价值变成了101.11,这是因为目标列不是索引覆盖范围,所以需要回表查询,导致io代价高,所以选择的是全表扫描。
所以,select * 并不是好的习惯,选择合适的目标列,尽量使用索引覆盖扫描,提升查询的性能。
七、查询执行引擎
查询优化完成后,对于服务端,执行阶段相对简单,根据执行计划的指令逐步执行,指令都是调用存储引擎的API来完成,一般称为 handler API,实际上,MySQL优化阶段为每个表都创建了一个 handler 实例,用 handler 实例获取表的相关信息(列名、索引统计信息等)。存储引擎接口有着非常丰富的功能,但是底层接口却只有几十个,这些接口像搭积木一样能够完成查询的大部分操作。
这个阶段的耗费主要是在存储引擎上,不同的引擎对于执行的消耗差别会比较大,但这个属于存储引擎的范围,我们先不表。
八、返回结果给客户端
查询执行的最后一个阶段就是将结果返回给客户端。即使查询不需要返回结果集给客户端,MySQL仍然会返回这个查询的一些信息,例如该查询影响到的行数。
MySQL将结果集返回客户端是一个增量、逐步返回的过程。一旦服务器处理完最后一个关联表,开始生成第一条结果时,MySQL就可以开始向客户端逐步返回结果集了。
这样处理有两个好处:服务端无须存储太多的结果,也就不会因为要返回太多结果而消耗太多内存。另外,这样的处理也让MySQL客户端第一时间获得返回的结果。
九、总结
本文介绍了查询sql的执行生命周期,从客户端到服务器,然后在服务器端解析并优化,生成执行计划,发送执行指令到存储引擎获取数据,并返回客户端。我们来回答下开篇提出的问题
Q:查询SQL在MySQL服务端有哪些执行阶段,每个执行阶段完成哪些功能?
A:查询缓存,检测缓存中是否以及有该查询的结果,如果有就直接返回,否则继续下一阶段。
解析阶段,将SQL语句解析成一棵树,并进行语法校验。
预处理阶段,进一步检查解析树是否合法,包括数据库名称是否存在,字段别名是否有歧义等。
查询优化,这个也是最复杂和核心的阶段,包含了大量算法和处理,主要有逻辑优化和物理优化两个阶段,生成最终的执行计划。
查询执行引擎,调用存储引擎接口,执行查询计划。
返回结果,将查询结果返回给客户端。
Q:MySQL如何进行查询优化?
A:本文用很多篇幅重点介绍了查询优化,主要包含逻辑优化和物理优化两个过程。
逻辑优化,是指按照语法规则进行优化,其中包括子查询优化,等价谓词重写,条件简化等。
物理优化,对每一个可能的执行方式进行代价评估,做定量的分析,从而得出代价最小的,代价模型估算主要考虑io和cpu的代价。
Q:针对性能的提升,开发过程中有哪些注意事项?
A:对于查询性能的提升,是个综合性的工程,包括了表结构优化,索引的设计,查询语句优化等等。本文从查询设计上介绍了相关的优化手段,最根本的思想是消除"冗余"的操作,比如检索了不需要的行,查询了不需要的列等等。