后端面经学习自测(一)
文章目录
-
- 1、MySQL-MVCC
- 2、MySQL-原子性怎么实现
- 3、MySQL-持久性怎么实现
-
- 隔离性怎么实现
- 4、操作系统-死锁产生
-
- 手写死锁
- 死锁排查
- 5、操作系统-避免死锁
-
- 死锁的四个必要条件
- 预防死锁
- 6、操作系统-pageCache是什么
-
- 零拷贝
- 7、计算机网络-TCP的可靠性和顺序性怎么实现
- 8、计算机网络-怎么进行流量控制
- 9、Redis-怎么持久化的数据
-
- RDB和AOF的区别
- 10、Redis-集群是怎么做的?就是数据怎么分片的,然后它的集群的高可用是什么?怎么部署的,这个有没有了解过?
- 11、分布式-分布式事务是什么
- 12、分布式-paxos和raft的区别
- 13、分布式-为什么就是分布式的共识算法都需要要求多数派提交才能完成它的分布式一致性?
- 14、场景题-有没有多线程编程的经验
- 15、场景题-缓存设计
1、MySQL-MVCC
是什么?解决什么问题?实现原理?
MVCC是多版本并发控制,是通过记录历史版本数据
解决读写并发冲突问题,避免了读数据时加锁,提高了事务的并发性能
MVCC的实现原理是依靠2个隐藏列、undo log日志、Read View实现的
MySQL将历史数据存储在undo log中,两个隐藏列,一个是事务ID,一个是指向历史数据undo log的指针
事务开启后,执行第一条select语句的时候,会创建ReadView,ReadView记录了当前未提交的事务,通过与历史数据的事务ID比较,可以根据可见性规则进行判断,判断这条记录是否可见,如果可见就直接将这个数据返回给客客户端,如果不可见就继续往undo log版本链查找第一个可见的数据
2、MySQL-原子性怎么实现
undo log
事务的原子性是通过 undo log 实现的,在事务还没提交前,历史数据会记录在 undo log 中,如果事务执行过程中,出现了错误或者用户执行了 ROLLBACK 语句,MySQL 可以利用 undo log 中的历史数据,将数据恢复到事务开始之前的状态,从而保证了事务的原子性。
3、MySQL-持久性怎么实现
redo log
事务的持久性是由 redo log 保证的,因为 MySQL 通过 WAL (先写日志再写数据)机制,在修改数据的时候,会将本次对数据页的修改以 redo log 的形式记录下来,这个时候更新就算完成了,Buffer Pool 的脏页会通过后台线程刷盘,即使在脏页还没刷盘的时候发生了数据库重启,由于修改操作都记录到了 redo log,之前已提交的记录都不会丢失,重启后就通过 redo log,恢复脏页数据,从而保证了事务的持久性。
隔离性怎么实现
MVCC
事务的隔离性是由 MVCC 和锁保证的。
比如,可重复读隔离级别下的快照读(普通select),是通过 MVCC 来保证事务隔离性的,当前读(update、select … for update)是通过锁来保证事务隔离性的。
4、操作系统-死锁产生
当两个或多个进程因竞争资源,而造成互相等待的现象,若无外力推进,则无法推进下去
手写死锁
public class DeadLockDemo {
public static void main(String[] args) {
final Object objectA = new Object();
final Object objectB = new Object();
new Thread(() -> {
synchronized (objectA) {
System.out.println(Thread.currentThread().getName() + "自己持A锁,希望获得B锁");
try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }
synchronized (objectB) {
System.out.println(Thread.currentThread().getName() + "成功获得B锁");
}
}
}, "A").start();
new Thread(() -> {
synchronized (objectB) {
System.out.println(Thread.currentThread().getName() + "自己持B锁,希望获得A锁");
try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }
synchronized (objectA) {
System.out.println(Thread.currentThread().getName() + "成功获得A锁");
}
}
}, "B").start();
}
}
死锁排查
方法一:控制台
jps -l查看端口号,类似linux中的ps -ef|grep xxxjstack 77860查看进程编号的栈信息

方法二:图形化界面(通用)
win` + `r` 输入`jconsole` ,打开图形化工具,打开`线程` ,点击 `检测死锁

5、操作系统-避免死锁
分配资源时,进行预先设计,使用银行家算法保证资源分配在一个安全状态下
安全状态:系统能够按照某种线程推进顺序为每个线程分配所需资源
银行家算法
死锁的四个必要条件
1、互斥:资源在同一时刻只能被一个线程所占用
2、请求保持:线程对已申请的资源保持不释放
3、不可剥夺:线程获得资源后,未使用完不能被其他线程所剥夺,只有使用完之后主动释放
4、循环等待:若干线程形成一种首尾相接的循环等待的状态
预防死锁
破坏死锁的四个必要条件之一
1、破坏请求与保持条件:一次性申请所有的资源
2、破坏不剥夺条件:如果资源申请不到,可以主动释放已占有的资源
3、破坏循环等待条件:按序申请资源
6、操作系统-pageCache是什么
页缓存,用于缓存文件的页数据,从磁盘中读取到的内容是存储在pageCache里的
零拷贝
详情可参考这篇笔记:https://blog.csdn.net/mys_mys/article/details/131647511?spm=1001.2014.3001.5502
传统IO执行流程
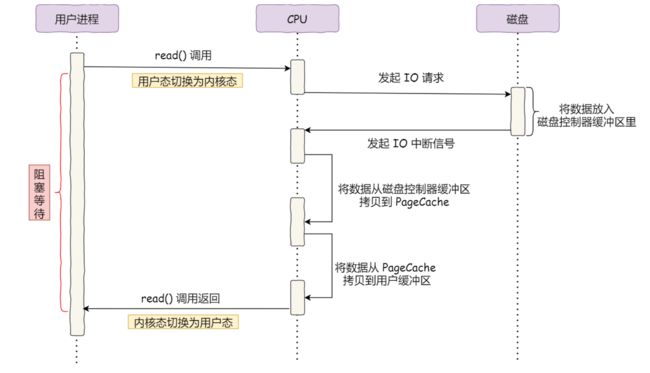
引入DMA
DMA直接内存拷贝,CPU可去处理别的事情

传统文件传输
4次拷贝,4次切换

mmap优化
3次拷贝,4次切换

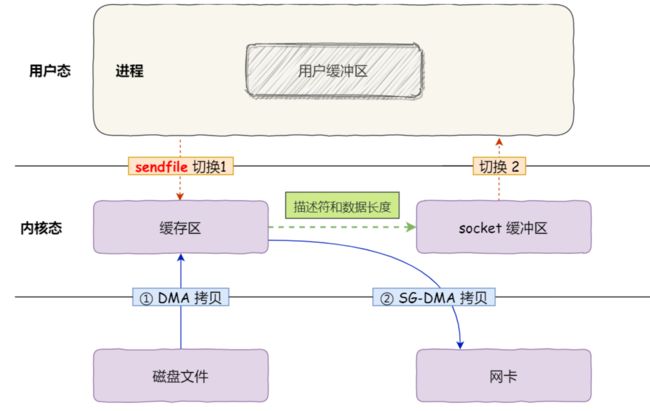
sendFile优化——零拷贝
2次DMA拷贝,2次切换
7、计算机网络-TCP的可靠性和顺序性怎么实现
参考:https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html
1、基于数据块传输
2、对失序数据包重新排序以及去重
3、校验和
4、超时重传
5、流量控制
6、拥塞控制
8、计算机网络-怎么进行流量控制
可以让发送方根据接收方的实际接收能力控制发送的数据量。
实现的方式:接收方会有一个接收缓冲区,如果内核接收到了数据,没有被应用读取的话,接收窗口就会收缩,然后会在tcp报文携带接收窗口的大小,发送发收到后,就会控制的发送流量
9、Redis-怎么持久化的数据
Redis持久化是异步进行的,有两种模式,RDB保存快照文件和AOF追加操作日志
RDB模式每隔一段时间会备份一份快照文件,从主进程Fork出一个子进程专门用于持久化,因此恢复速度快,但是容易造成数据丢失;
AOF模式是一种日志模式,记录每条命令的操作日志,重启时通过日志回放进行数据恢复,可以降低数据丢失情况。
RDB和AOF的区别
- 文件类型:RDB生成的是 二进制文件(快照),AOF生成的是 文本文件(追加日志)
- 安全性:缓存宕机时,RDB容易丢失较多的数据,AOF根据策略决定(默认的everysec可以保证最多有一秒的丢失)
- 文件恢复速度:由于RDB是二进制文件,所以恢复速度也比 AOF更快
- 操作的开销:每一次RDB保存都是一次全量保存,操作比较重,通常设置至少5分钟保存一次数据。而AOF的刷盘是一次追加操作,操作比较轻,通常设置策略为每一秒进行一次刷盘
补充相关知识点
10、Redis-集群是怎么做的?就是数据怎么分片的,然后它的集群的高可用是什么?怎么部署的,这个有没有了解过?
Redis集群中有多个主节点,每个主节点有多个从节点。当主节点发生故障时,从节点被选举为主节点,继续工作;
Redis集群使用哈希槽的方式实现数据分片存储,有固定的16384个哈希槽(计算key对应槽位置:CRC16(key)%16384)
补充