函数指针和函数指针数组
函数指针:指向函数的指针。
函数指针数组:一个数组里面存的类型是函数指针。
一、函数指针的声明和调用
1.指针声明:
函数指针顾名思义就是一个指向函数的指针。
int Add(int x,int y)
{
return x+y;
}
char* Sub(char*)
{
}
//声明函数指针并初始化
int (*Add)(int ,int ) ptr=&Add;
char* (*Sub)(char*) prt_char=⋐这里声明了两个函数指针 ptr和ptr_char指向了函数的地址,这里会发现Add取地址(&ADD),同样是原类型加上一个*,就是 int(*Add)(int,int),注意不是int *Add(int,int)。
对于一个返回指针的函数来说也是一样,Sub取地址(&Sub)原类型加上一个*,就是char*(*Sub)(char*),注意不是char* *Sub(int,int);
PS:声明指针的时候,函数的返回值和参数类型、个数都要对的上。
对于函数来说取地址Add (&Add),和直接写上本身是一样的(Add)。
所以初始化的时候也可以写成
int Add(int x,int y)
{
return x+y;
}
int (*Add)(int,int)pf=Add;
这种写法和上面等价。
2.指针函数的调用:
可以通过使用函数指针调用函数。
int Add(int x,int y){
return x+y;
}
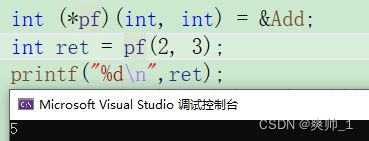
int (*pf)(int,int)=&Add;
int ret=(*pf)(2,3); //等价于int ret=Add(2,3);
printf("%d\n",ret);这里用指针调用函数的结果,跟直接使用函数的结果是一样的。
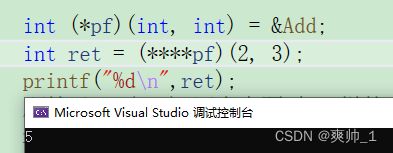
因为上面&Add和Add的地址是一样的,所以这里导致了,不管解引用了几次pf,得到的结果都是函数Add。


二、函数指针数组
声明一个数组,里面存储的类型是,指向函数的指针。
声明:
int Add(int x,int y){ //声明函数
return x+y;
}
int Sub(int x,int y){
return x-y;
}
int Mul(int x,int y){
return x*y;
}
int Div(int x,int y){
return x/y;
}
int (*pf1)(int,int)=Add; //声明初始化函数指针
int (*pf2)(int,int)=Sub;
int (*pf3)(int,int)=Mul;
int (*pf4)(int,int)=Div;
//函数指针数组
int (*pf[4])(int,int)={Add,Sub,Mul,Div}; //初始化函数指针数组
//调用
for(int i=0;i<4;i++){ //通过数组元素调用函数
pf[i](2,5);
}这里pf先跟[4]结合,说明了pf是个数组,然后去掉pf[4],剩下的int(*)(int,int)就是数组里面存储的类型,这个类型就是函数指针。通过调用数组不同的元素就能调用到不同的函数。
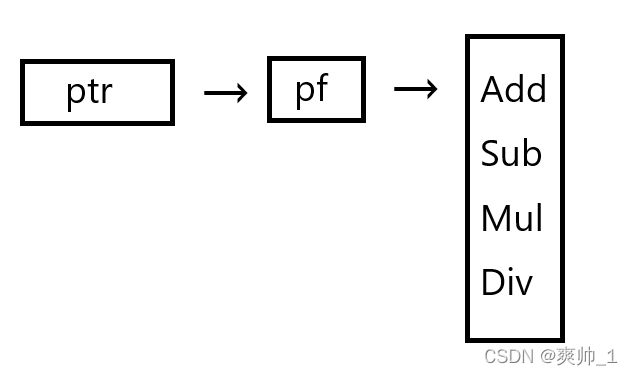
既然是个数组,当然也可以定义一个指针,指向这个数组,一个指向函数数组的指针。
类型的写法就是取地址pf (&pf),原来的类型加上一个*,就是int ( *( *pf[4] ) )(int ,int)。注意不是int* ( *pf[4] )(int,int)
int *(pf[4])(int,int);
int (*(*ptr[4]))(int,int)=&pf;PS:要注意函数指针数组取地址得到的就不是函数本身了,而是整个数组的地址。
三.回调函数
1.定义
回调函数就是利用函数指针,来在函数内部调用不同的函数。
void test()
{
printf("hehe!\n");
}
void print_hehe(void (*pfun)()) //这个函数就叫回调函数
{
if(1)
pfun();
}
int main()
{
print_hehe(test);
}print_hehe的形参是一个函数指针,只要给函数不同的函数地址实参,就能调用不同的函数。
而这里print_hehe就是一个回调函数。
2.实例:
//简单的计算器实现
int Add(int x,int y){
return x+y;
}
int Sub(int x,int y){
return x-y;
}
int Mul(int x,int y){
return x*y;
}
int Div(int x,int y){
return x/y;
}
void calc(int(*fun)(int,int))
{
int x,y;
scanf("%d%d",&x,&y);
int ret=fun(x,y);
printf("%d\n",ret);
}
int main()
{
int input=0;
scanf("%d",&input);
while(input){
switch(input){
case 1:
calc(Add);
break;
case 2:
calc(Sub);
break;
case 3:
calc(Mul);
break;
case 4:
calc(Div);
break;
}
}
return 0;
}这种写法不仅能减少函数冗余,提高代码复用性,而且每次修改和添加代码增加删减功能的时候,修改的地方少,减少了函数代码的耦合度。
函数指针数组的写法:
int Add(int x, int y) {
return x + y;
}
int Sub(int x, int y) {
return x - y;
}
int Mul(int x, int y) {
return x * y;
}
int Div(int x, int y) {
return x / y;
}
void menu()
{
printf("**** 1.加法 2.减法 ****\n");
printf("**** 3.乘法 4.除法 ****\n");
printf("**** 0.退出 ****\n");
}
int main()
{
int (*p[])(int, int) = { 0,Add,Sub,Mul,Div };
int input = 1, x = 0, y = 0;
menu();
printf("请选择:>\n");
while (input) {
scanf("%d", &input);
printf("请输入要计算的两个数:>\n");
scanf("%d %d", &x, &y);
int ret = p[input](x, y);
printf("%d\n", ret);
}
return 0;
}四.qsort 函数的解析
此函数是基于快速排序的算法来进行排序的库函数,为了能够排序各种类型的数据,在函数参数部分留了一个函数指针,给使用者来自己定义排序的规制。
函数的参数依次为数组地址,数组长度,数组元素的宽度,和函数指针。
struct stu
{
char name[20];
int age;
double score;
};
//结构体排序规则 根据年龄排序
int com_by_age(const void* e1,const void* e2)
{
return ((stu*)e1)->age - ((stu*)e2)->age;
}
//结构体排序规则 根据姓名排序
int com_by_name(const void* e1,const void* e2)
{
return strcmp(((stu*)e1)->name,((stu*)e2)->name);
}
stu arr[]={{"张三",15,88.5},{"李四",14,98.5},{"王五",18,55.5}}; //结构体数组
int sz=sizeof(arr)/sizeof(arr[0]);
qsort(arr,sz,sizeof(arr[0]),com_by_name);这里两个自定义函数里面,一个排序的规制是根据年龄来排序,一个是根据名字来排序,注意这里字符串比较要用strcmp函数。
函数默认是进行升序排序,如果要进行降序排序,改变一下定义排序规则的逻辑就可以
int com_by_age(const void* e1,const void* e2)
{
return ((stu*)e2)->age - ((stu*)e1)->age;
}
int com_by_name(const void* e1,const void* e2)
{
strcmp(((stu*)e2)->name,((stu*)e1)->name);
} 从这里可以发现,实现降序的话,调转 return ((stu*)e2)->age - ((stu*)e1)->age;
这里表达的意思就是 如果后面的元素 > 前面的元素就交换,就把两个元素交换,就把小的元素放后面了。
五.模拟qsort函数的逻辑实现一个冒泡排序函数
void Swap(char *buf1,char* buf2,width)
{
//因为这里buf1和buf2解引用是一个字节,但是把所有字节都交换位置,相当于交换了两个数
for(int i=0;i0 ){
//这里>0(升序),<0(降序) 可以改变排序规则实现降序或者升序的排序。
//但是修改了函数,建议还是在函数外边更改排序逻辑
Swap((char*)arr+(j)*width,(char*)arr+(j+1)*width,width);
}
}
}
}
int comp_int(const void* e1,const void* e2)
{
return *(int*)e1-*(int*)e2; //e1-e2>0 符合条件就会排序,把e1的元素往数组后面排
}
int main()
{
int arr[]={9,8,7,6,5,4,3,2,1};
int sz=sizeof(arr)/sizeof(arr[0]);
bubble_sort(arr,sz,sizeof(arr[0]),comp_int)
} 代码解析:
首先,因为以后要使用的时候,现在不明确具体的要排序的是什么类型的数据,这里第一个参数,用一个void*arr的指针来接受数组的首地址。因为只有void*类型才能接收各种类型的指针
因为排序要遍历数组,为了方便遍历数组,这里第二个、第三个参数传入数组的长度和数组元素的宽度
因为不知道要排序的类型,所以要把排序的规制交给使用者来定义,第四个参数给一个函数指针,int (*cmp)(const void*e1,const void*e2),这里函数指针的参数类型也是不确定的,也要用void*的指针来接收每次排序元素的地址。
这里使用这个函数来排序一个整形类型的数组,那么既然用的是void*的指针来接收数组元素,那么怎么让每次比较都是一个整形的元素呢?其实这里传入的元素的宽度的就起了作用。
首先元素的类型我们是不知道的,但是我们知道元素的宽度,那么就可以先把void*的数组arr强制转换成char*类型,因为char*类型的步长固定是一个字节。假设这里排序的int类型的元素,一个int形的元素宽度是4,那么arr每次跳过4个字节就能找到下一个元素,那么 if 的判断 就能写成
cmp((char*)arr+(j)*width,(char*)arr+(j+1)*width);这样使用自定义比较规则函数的时候就能找到 元素和下一个元素。
int comp_int(const void* e1,const void* e2)
{
return *(int*)e1-*(int*)e2;
}PS:写 比较函数 的时候,元素的类型就确定了。这里使用整形变量,把传过来的char*类型的指针强制转换成int*,再解引用,因为上面传过来的是每个元素的首地址,解引用就能找到整个元素
然后再进行元素的交换,因为不同的数据类型之间有差异,不能直接通过第三个变量来交换,并且这里也不知道具体要交换的类型。但是如果两个元素,每个字节都做了交换,就相当于这两个元素进行了交换。
那么就可以声明一个交换函Swap(char *buf1,char* buf2,width),来交换每个元素的字节,并用元素宽度来做判断。
void Swap(char *buf1,char* buf2,width)
{
for(int i=0;i这里就完成了一个基于冒泡排序算法,可以排序各种类型的排序函数。