Java 应用如何进行线上问题排查?
简介
线上故障排查,是每个程序员必备的技能,为什么这么讲呢,因为项目上线后,不是随时都有条件debug,也不是随时都能查到对应的日志文件,有时关键位置也不一定打日志,这可太令人心痛了。甚至有时个别问题转眼即逝,我们需要一个完整的线上的排查过程,才能应对这些情况。
线上故障众多,但其实也并不是无迹可循,也有一定的章法可言,一般无外乎CPU、内存、磁盘、网络、IO这几个方面的问题。所以我们的解决方案也简单:直接top、free、df等大锤开路,然后依次,jstack,jstat,jmap等小锤扣缝,最后具体问题具体分析即可。只要学会了这套流程,你遇到问题就不会开摆了。
常用命令
下面先介绍点常用的命令,之后再讲解具体的流程,免得你出了问题,jps、ps命令用一下,然后来回切目录,就不知道该干嘛了。
top命令
可以显示当前系统正在执行的进程的相关信息,包括进程ID、内存占用率、CPU占用率等。
-b 批处理
-c 显示完整的命令
-I 忽略失效过程
-s 保密模式
-S 累积模式
-d<时间> 设置间隔时间
-u<用户名> 指定用户名
-p<进程号> 指定进程
-n<次数> 循环显示的次数
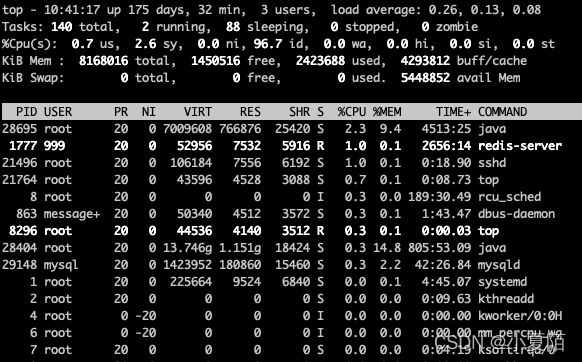
前五行是系统整体的统计信息,后面是统计信息区域,主要显示了各个进程的详细信息。
使用示例:
[root@localhost ~]# top #显示系统进程信息
[root@localhost ~]# top -b #以批处理模式显示程序信息
[root@localhost ~]# top -S #以累积模式显示程序信息
[root@localhost ~]# top -n 2 #设置信息更新次数,表示更新2次后终止更新显示
[root@localhost ~]# top -d -3 #设置信息更新时间,表示更新周期为3秒
[root@localhost ~]# top -p 1138 #显示进程号为1138的进程信息,CPU、内存占用率等
vmstat 命令
vmstat 报告虚拟内存的统计信息。
-a: 显示活跃和非活跃内存
-f: 显示从系统启动至今的fork数量
-m: 显示slabinfo
-n: 只在开始时显示一次各字段名称
-s: 显示内存相关统计信息及多种系统活动数量
-d: 显示磁盘相关统计信息
-p: 显示指定磁盘分区统计信息
-S: 使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V: 显示vmstat版本信息
使用示例:
[root@localhost ~]# vmstat 2 #每二秒显示一次系统内存的统计信息
[root@localhost ~]# vmstat 2 5 #每二秒显示一次系统内存的统计信息,总共5次
[root@localhost ~]# vmstat -d #显示磁盘信息
free命令
free 命令显示系统使用和空闲的内存情况,包括物理内存、交互区内存(swap)和内核缓冲区内存。
-b 显示内存的单位为字节
-k 显示内存的单位为 KB
-m 显示内存的单位为 M
-o 忽略缓冲区调节列
-t 总和信息
-s<时间> 每隔指定时间执行一次命令,单位为s
-h 以可读形式显示容量,需要free -V显示版本大于3.3
-V 版本信息
使用示例:
[root@localhost ~]# free -s 3 #每3秒执行一次
[root@localhost ~]# free -m #以M为单位
[root@localhost ~]# free -k #以K为单位
df命令
报告文件系统磁盘空间的使用情况。
-a 列出包括BLOCK为0的文件系统
-h 用常见的格式显示出大小(例如:1K 234M 2G)
-H 同上,但是这里的1k等于1000字节而不是1024字节
-i 用信息索引点代替块表示使用状况
-k 指定块大小等于1024字节来显示使用状况
-l 只显示本地文件系统使用状况
-m 以指定块大小等于1048576字节(1M)来显示使用状况
--no-sync 在取得使用信息前禁止调用同步 (default)
-P 使用POSIX格式输出
--sync 在取得使用信息前调用同步
-t 只显示指定类型(TYPE)的文件系统
-T 输出每个文件系统的类型
-x 只显示指定类型(TYPE)之外的文件系统.
--help 输出该命令的帮助信息并退出
--version 输出版本信息并退出
使用示例:
[root@localhost ~]# df #列出各文件系统的磁盘空间使用情况
[root@localhost ~]# df -ia #列出各文件系统ionde使用情况
[root@localhost ~]# df -T #列出文件系统的类型
[root@localhost ~]# df -h #目前磁盘空间和使用情况 以更易读的方式显示
[root@localhost ~]# df -k #以单位显示磁盘的使用情况
iostat命令
可以提供更丰富的IO性能状态数据。
-c 只显示CPU行
-d 显示设备(磁盘)使用状态
-k 以千字节为单位显示磁盘输出
-t 在输出中包括时间戳
-x 在输出中包括扩展的磁盘指标
使用示例:
[root@localhost ~]# iostat -d -k 1 10 #查看TPS和吞吐量信息
[root@localhost ~]# iostat -d -x -k 1 10 #查看设备使用率(%util)、响应时间(await)
[root@localhost ~]# iostat -c 1 10 #获取cpu部分状态值
ifstat命令
ifstat命令 就像iostat/vmstat描述其它的系统状况一样,是一个统计网络接口活动状态的工具。
-l 监测环路网络接口(lo)。
-a 监测能检测到的所有网络接口的状态信息。
-z 隐藏流量是无的接口,例如那些接口虽然启动了但是未用的
-i 指定要监测的接口,后面跟网络接口名
-s 等于加-d snmp:[comm@][#]host[/nn]] 参数,通过SNMP查询一个远程主机
-h 显示简短的帮助信息
-n 关闭显示周期性出现的头部信息
-t 在每一行的开头加一个时间戳
-T 报告所有监测接口的全部带宽
-w 用指定的列宽,而不是为了适应接口名称的长度而去自动放大列宽
-W 如果内容比终端窗口的宽度还要宽就自动换行
-S 在同一行保持状态更新(不滚动不换行)
-b 用kbits/s显示带宽而不是kbytes/s
-q 安静模式,警告信息不出现
-v 显示版本信息
-d 指定一个驱动来收集状态信息
使用示例:
[root@localhost ~]# ifstat -tT #添加具体的时间和所有监测接口的全部带宽
ps命令
-a 显示所有终端机下执行的进程,除了阶段作业领导者之外
-A 显示所有进程。
-c 显示CLS和PRI栏位。
-C<指令名称> 指定执行指令的名称,并列出该指令的进程的状况。
-d 显示所有进程,但不包括阶段作业领导者的进程。
-e 此参数的效果和指定"A"参数相同。
-f 显示UID,PPID,C与STIME栏位。
-g<群组名称> 此参数的效果和指定"-G"参数相同,当亦能使用阶段作业领导者的名称来指定
-G<群组识别码> 列出属于该群组的进程的状况,也可使用群组名称来指定。
h 不显示标题列。
-H 显示树状结构,表示进程间的相互关系。
-j 采用工作控制的格式显示进程状况。
-l 采用详细的格式来显示进程状况。
L 列出栏位的相关信息。
-m 显示所有的执行绪。
n 以数字来表示USER和WCHAN栏位。
-N 显示所有的进程,除了执行ps指令终端机下的进程之外。
-p<进程识别码> 指定进程识别码,并列出该进程的状况。
p<进程识别码> 此参数的效果和指定"-p"参数相同,只在列表格式方面稍有差异。
r 只列出现行终端机正在执行中的进程。
-s<阶段作业> 指定阶段作业的进程识别码,并列出隶属该阶段作业的进程的状况。
s 采用进程信号的格式显示进程状况。
S 列出进程时,包括已中断的子进程资料。
-t<终端机编号> 指定终端机编号,并列出属于该终端机的进程的状况。
-T 显示现行终端机下的所有进程。
-u<用户识别码> 此参数的效果和指定"-U"参数相同。
-U<用户识别码> 列出属于该用户的进程的状况,也可使用用户名称来指定。
v 采用虚拟内存的格式显示进程状况。
-V 显示版本信息。
-w 采用宽阔的格式来显示进程状况。
-x 显示所有进程,不以终端机来区分。
-y 配合参数"-l"使用时,不显示F(flag)栏位,并以RSS栏位取代ADDR栏位
使用示例:
[root@localhost ~]# ps aux --sort=-pcpu,+pmem #CPU或者内存进行排序,-降序,+升序
[root@localhost ~]# ps -e -o pid,comm,etime #显示进程运行的时间
[root@localhost ~]# ps -aux | grep named #查看named进程详细信息
jps命令
jps 可以列出本机所有Java进程的pid 。
-q 仅输出VM标识符,不包括class name,jar name,arguments in main method
-m 输出main method的参数
-l 输出完全的包名,应用主类名,jar的完全路径名
-v 输出jvm参数
-V 输出通过flag文件传递到JVM中的参数(.hotspotrc文件或-XX:Flags=所指定的文件
-Joption 传递参数到vm,例如:-J-Xms48m
使用示例:
[root@localhost ~]# jps #列出本机所有Java进程的pid
[root@localhost ~]# jps -m #列出本机所有Java进程的pid和main method
jstack
jstack是java虚拟机自带的一种堆栈跟踪工具。jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息。
-F 当进程挂起,执行jstack 命令没有任何输出后,将强制转储堆内的线程信息
-m 在混合模式下,打印 java 和 native c/c++ 框架的所有栈信息
-l 长列表。打印关于锁的附加信息,例如属于 java.util.concurrent 的 ownable synchronizers 列表
-h 打印帮助信息
使用示例:
[root@localhost ~]# jstack -m 88888 >1.txt #将 java 和 native c/c++ 框架的所有栈信息输出到文件
[root@localhost ~]# jstack -l 88888 >1.txt #将堆栈信息输出到文件
jstat
利用JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控。
–class 监视类装载、卸载数量、总空间及类装载所耗费的时间
–gc 监视Java堆状况,包括Eden区、2个Survivor区、老年代、永久代等的容量
–gccapacity 监视内容与-gc基本相同,但输出主要关注Java堆各个区域使用到的最大和最小空间
–gcutil 监视内容与-gc基本相同,但输出主要关注已使用空间占总空间的百分比
–gccause 与-gcutil功能一样,但是会额外输出导致上一次GC产生的原因
–gcnew 监视新生代GC的状况
–gcnewcapacity 监视内容与-gcnew基本相同,输出主要关注使用到的最大和最小空间
–gcold 监视老年代GC的状况
–gcoldcapacity 监视内容与-gcold基本相同,输出主要关注使用到的最大和最小空间
–gcpermcapacity 输出永久代使用到的最大和最小空间
–compiler 输出JIT编译器编译过的方法、耗时等信息
–printcompilation 输出已经被JIT编译的方法
使用示例:
[root@localhost ~]# jstat -class 15224 1000 10 -class #显示加载class的数量,及所占空间等信息
[root@localhost ~]# jstat -gcutil 5061 1000 2000 -gcutil #统计gc信息
jmap
jmap命令可以获得运行中的jvm的堆的快照,从而可以离线分析堆,以检查内存泄漏等问题。
-dump 输出jvm的heap信息
-finalizerinfo 打印正等候回收的对象的信息.
-heap 打印heap的概要信息,GC使用的算法,heap的配置及wise heap的使用情况.
-histo[:live] 打印每个class的实例数目,内存占用,类全名信息
-permstat 打印classload和jvm heap长久层的信息.
-F 强迫.在pid没有相应的时候使用-dump或者-histo参数. 在这个模式下,live子参数无效.
-h 打印辅助信息
-J 传递参数给jmap启动的jvm.
使用示例:
[root@localhost ~]# jmap -histo 4939 #打印每个class的实例数目,内存占用,类全名信息
jinfo命令
可以打印出java进程的配置信息:包括jvm参数,系统属性等。
no option 打印命令行参数和系统属性
-flags 打印命令行参数
-sysprops 打印系统属性
-h 帮助
使用示例:
[root@localhost ~]# jinfo xxxx #打印命令行参数和系统属性
[root@localhost ~]# jinfo -flags xxxx #打印命令行参数
解决思路
现在我们来讲一下出现问题的解决思路,现在有一个Java服务崩了,但没完全崩的情况下,你进入服务器终端,应该会卡,或者慢。这时,我们即需要在系统层面排查一次,还要在Java应用方向再排查一次,最后对症下药。
- 系统层面的排查主要有:CPU、内存、磁盘、网络、IO
用到的命令主要有:top、vmstat、free、df、iostat、ifstat、ps,这些命令都查一遍,你就知道是以上哪个方向出问题了,再用Java自带的命令做进一步分析。 - Java应用方向主要有:死循环、频繁gc、上下文切换过多 、OOM、Stack Overflow 、内存泄漏 等
用到的命令主要有:jps、jstack、jstat、jmap、jinfo,主要结果系统层面的问题,再做进一步的分析。
相对系统层面,Java应用方向的问题比较多,且杂,但我们可以确定一点的是:不管是什么应用层问题,只要威胁到我们的系统,它一定会表现在CPU、内存、磁盘、网络、IO上。 比如, “死循环” 、 “频繁gc” 和 “上下文切换过多” 会导致CPU压力过大,“OOM”、“Stack Overflow”、“内存泄漏” 会导致内存压力过大,而其它的一些问题会影响到磁盘、网络和IO问题,比如日志太多,磁盘堆满,带宽占用过多,导致网络卡顿等。
示例:CPU占用过高检查过程
- 通过top、free、df、iostat、ifstat命令发现,其它资源占用不多,但CPU占用过多,爆满,怀疑是CPU占用过高问题。
- 通过 top 命令找到 CPU 消耗最高的进程,并记住该进程 ID。
- 再次通过 top -Hp [进程 ID] 找到 CPU 消耗最高的线程 ID,并记住线程 ID。
- 通过 JDK 提供的 jstack 工具 dump 线程堆栈信息到指定文件中。具体命令:jstack -l [进程 ID] > jstack.log。
- 由于刚刚的线程 ID 是十进制的,而堆栈信息中的线程 ID 是16进制的,因此我们需要将10进制的转换成16进制的,并用这个线程 ID 在堆栈中查找。使用 printf “%x\n” [十进制数字] ,可以将10进制转换成16进制。
- 通过刚刚转换的16进制数字从堆栈信息里找到对应的线程堆栈。就可以从该堆栈中看出端倪,接下来改成就是Java代码层面的事了。