Python爬虫——爬虫基础模块和类库(附实践项目)
一、简单介绍
Python爬虫是使用Python编程语言开发的一种自动化程序,用于从互联网上获取信息。通过模拟浏览器的行为,爬虫可以访问网页、解析网页内容,并提取所需的数据。
python的爬虫大致可以分为通用爬虫和专用爬虫:
通用爬虫是一种能够自动化地从互联网上抓取信息的程序,它可以根据用户的需求,爬取各种类型的网页内容,并将其保存或进行进一步处理。通用爬虫通常具有以下特点:
-
灵活性:通用爬虫可以爬取各种类型的网页,包括新闻、论坛、博客等,因此具有较高的灵活性。
-
自动化:通用爬虫可以通过编程实现自动化的抓取过程,无需人工干预。
-
大规模爬取:通用爬虫可以处理大量的网页,并将其保存到本地或进行进一步的分析和处理。
专用爬虫是一种针对特定网站或特定类型的网页进行定制化开发的爬虫程序,它具有以下特点:
-
高度定制化:专用爬虫针对特定网站或特定类型的网页进行开发,可以根据网站的结构和特点进行优化,提高爬取效率和准确性。
-
速度较快:由于专用爬虫只需要处理特定类型的网页,因此可以针对性地进行优化,提高爬取速度。
-
数据质量较高:专用爬虫可以根据特定网站的要求进行数据抓取和处理,因此可以保证数据的准确性和完整性。
1.1 运行原理
爬虫通过模拟服务器发送请求并获取对应的信息:
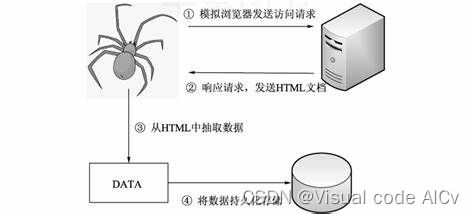 爬虫运行原理(取自bing图库)
爬虫运行原理(取自bing图库)
步骤介绍:
-
发送请求:爬虫首先向目标网站发送HTTP请求,请求获取页面内容。可以使用Python的第三方库如requests发送HTTP请求。
-
获取页面内容:目标网站接收到爬虫的请求后,返回相应的页面内容。爬虫通过解析HTTP响应,获取页面内容。可以使用Python的第三方库如BeautifulSoup或者正则表达式进行页面内容的解析和提取。
-
解析页面内容:爬虫根据需要的数据类型,对页面内容进行进一步的解析和提取。可以使用XPath、CSS Selector或者正则表达式等方式进行页面内容的解析。
-
存储数据:爬虫将解析提取到的数据存储到本地文件或者数据库中。可以使用Python的第三方库如pandas、csv、MySQLdb等进行数据的存储。
-
遍历链接:如果需要爬取多个页面,爬虫会根据页面中的链接,递归地发送请求和解析页面,实现对多个页面的遍历。
-
反爬虫机制:为了防止被网站屏蔽或者限制,爬虫需要处理一些反爬虫机制,如设置请求头、使用代理IP、降低请求频率等。
二、python爬虫库
按照爬虫爬取网络信息到最终展示数据分析结果的过程,我总结了以下常用的python第三方库
2.1 获取网页信息(requests库)
requests是一个Python的第三方库,用于发送HTTP请求。它是基于urllib3库开发的,比urllib更加方便和简洁。
使用requests库进行爬虫可以实现以下功能:
- 发送GET和POST请求
- 设置请求头和Cookies
- 设置请求参数和URL编码
- 处理响应结果,包括获取状态码、响应头和响应内容等
- 保存下载的文件
- 处理重定向和代理
- 使用会话保持会话状态
常用函数:
1.发送请求
| requests.get(url, params=None, **kwargs) | 发送GET请求,参数url为请求的URL,params为请求中的查询参数 |
| requests.post(url, data=None, json=None, **kwargs) | 发送POST请求,参数url为请求的URL,data为请求中的表单数据,json为请求中的JSON数据。 |
| requests.put(url, data=None, **kwargs) | 发送PUT请求,参数url为请求的URL,data为请求中的数据。 |
| requests.patch(url, data=None, **kwargs) | 发送PATCH请求,参数url为请求的URL,data为请求中的数据。 |
| requests.delete(url, **kwargs) | 发送DELETE请求,参数url为请求的URL。 |
| requests.head(url, **kwargs) | 发送HEAD请求,参数url为请求的URL。 |
| requests.options(url, **kwargs) | 发送OPTIONS请求,参数url为请求的URL。 |
| requests.request(method, url, **kwargs) | 发送任意类型的HTTP请求,参数method为请求的方法,url为请求的URL。 |
| requests.session() | 创建一个Session对象,用于保持会话状态 |
| requests.get(url, params=None, **kwargs) | 发送GET请求,参数url为请求的URL,params为请求中的查询参数。 |
2.获得响应
| response = requests.get(url, params=None, **kwargs) | 发送GET请求并返回响应对象,可以通过该对象获取响应的内容、状态码等信息。 |
| response.text | 获取响应的文本内容。 |
| response.content | 获取响应的二进制内容。 |
| response.status_code | 获取响应的状态码。 |
| response.json() | 将响应的JSON内容解析为Python对象。 |
| response.headers | 获取响应的头部信息。 |
| response.cookies | 获取响应的Cookies信息 |
| response.url | 获取响应的URL。 |
拓展
可以发送HTTP请求的库不只于requests库,还有上面提到的urllib等库。综合来看,requests库使用起来最为便捷,但是在一些特定的领域使用其他的库可能会有更好的效果:
- urllib:一系列用于操作URL的功能。
- selenium:自动化测试工具。一个调用浏览器的 driver,通过这个库你可以直接调用浏览器完成某些操作,比如输入验证码。
- aiohttp:基于 asyncio 实现的 HTTP 框架。异步操作借助于 async/await 关键字,使用异步库进行数据抓取,可以大大提高效率。
2.2 解析网页结构,提取数据(BeautifulSoup4)
BeatifulSoup4是用于解析网页结构的库,它的作用是将获取到的网页HTML和XML文档进行分解。从而定位到我们需要获取的特定信息在网页中的位置。
当使用BeautifulSoup4库解析HTML或XML文件时,它会根据指定的解析器(如html.parser、lxml等)将文件转换为文档树的形式。文档树由节点(Node)组成,每个节点代表文件中的一个元素(标签、文本等)。这些节点之间通过父子关系、兄弟关系等连接在一起,形成了树状结构。
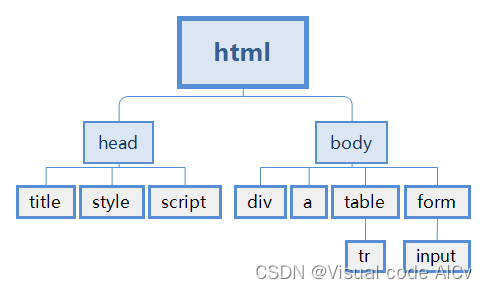 html树状图(取自bing图库)
html树状图(取自bing图库)
以下是BeautifulSoup4常用的方法和模块:
| BeautifulSoup | 这是BeautifulSoup4库的主要类,用于解析HTML和XML文件。可以通过指定解析器(如html.parser、lxml等)来创建一个BeautifulSoup对象,并对解析后的内容进行操作。 |
| find_all() | 这是BeautifulSoup对象的一个方法,用于查找所有符合指定条件的标签。可以根据标签名、类名、属性等进行查找,并返回一个包含所有匹配标签的列表。 |
| find() | 与find_all()类似,但只返回第一个匹配的标签。 |
| select() | 这是BeautifulSoup对象的另一个方法,用于通过CSS选择器语法来查找标签。可以根据标签名、类名、属性等进行查找,并返回一个包含所有匹配标签的列表 |
| get_text() | 这是标签对象的方法,用于获取标签内的文本内容。 |
| attrs | 这是标签对象的属性,用于获取标签的所有属性和属性值。 |
| prettify() | 这是BeautifulSoup对象的方法,用于美化解析后的内容,使其更易读。 |
BeautifulSoup4可以结合正则表达式和CSS选择器使用,以便更加精确地解析网页结构
拓展
BeautifulSoup4功能比较全面,简单易用,因此较为常用;但在一些特殊的领域,使用一些其他的库可以达到更好的效果:
- pyquery:jQuery 的 Python 实现,能够以 jQuery 的语法来操作解析 HTML 文档,易用性和解析速度都很好。
- lxml:支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。
- tesserocr:一个 OCR 库,在遇到验证码(图形验证码为主)的时候,可直接用 OCR 进行识别。
2.3 数据分析(不包含数据可视化)
Python数据分析这一块内容丰富,常用的库非常多,一篇文章写不完。
以下是一些常用的库:
-
NumPy:NumPy是一个用于科学计算的基础库,提供了维数组对象和一组用于操作数组的函数。
-
Pandas:Pandas是用于数据处理和分析的强大库,提供了高性能的数据结构和数据分析工具,如DataFrame和Series。
-
SciPy:SciPy是一个用于科学计和技术计算的库,提供了许数学、科学和工程计算功能,如数值积分、化、线性代数等。
-
Scikit-learn:Scikit-learn是一个用于机器学习和数据挖掘的库,提供了各种机器学习算法和工具,用于分类、回归、聚类等任务。
-
StatsModels:Models是一个用于统计建模和计量经学的库,提供了各种统计模型和统计分析工具。
-
TensorFlow:TensorFlow是一个用于机器学习和深度习的库,提供了各种机器学习算法和神经网络模型的实现。
2.4 数据可视化(Matplotlib)
Matplotlib是一个广泛使用的绘图库,提供了许多函数和方法用于创建各种类型的图表。
Matplotlib提供了丰富的绘图功能,包括线图、散点图、柱状图、饼图、3D图形等。它还支持自定义图形的颜色、样式、标签和图例等属性。Matplotlib还可以在Jupyter Notebook中以交互方式显示图形。
Matplotlib的基本用法包括创建图形对象、添加子图、设置图形属性、绘制数据等。它还提供了一系列的函数和方法来控制坐标轴、刻度、网格、标签、标题等。
常用的绘图模块为pyplot模块,使用前应先导入
import matplotlib.pyplot as plt以下是Matplotlib.pyplot常用的函数:
| plt.plot(x, y, …) | 绘制折线图,可以指定x轴和y轴的数据。 |
| plt.scatter(x, y, …) | 绘制散点图,可以指定x轴和y轴的数据。 |
| plt.bar(x, y, …) | 绘制柱状图,可以指定x轴和y轴的数据。 |
| plt.hist(x, …) | 绘制直方图,可以指定一维数据数组。 |
| plt.pie(x, labels, …) | 绘制饼图,可以指定饼图的数据和标签。 |
| plt.boxplot(x, …) | 绘制箱线图,可以指定一维或二维数据数组。 |
| plt.imshow(image, …) | 显示图像,可以指定图像的像素数据。 |
| plt.contour(x, y, z, …) | 绘制等高线图,可以指定x轴、y轴和z轴的数据。 |
| plt.plot_surface(x, y, z, …) | 绘制三维曲面图,可以指定x轴、y轴和z轴的数据。 |
| plt.xlabel(label) | 设置x轴标签。 |
| plt.ylabel(label) | 设置y轴标签。 |
| plt.title(title) | 设置图表标题。 |
| plt.legend() | 显示图例。 |
| plt.grid() | 显示网格线。 |
| plt.xlim(xmin, xmax) | 设置x轴的显示范围。 |
| plt.ylim(ymin, ymax) | 设置y轴的显示范围。 |
除了matplotlib.pyplot模块之外,Matplotlib还包括其他一些模块,用于不同的功能和任务。以下是一些常用的Matplotlib模块:
-
matplotlib.figure:该模块提供了Figure类,用于创建和管理图形对象。Figure类是图形的顶级容器,可以包含多个子图。 -
matplotlib.axes:该模块提供了Axes类,用于绘制图表的坐标轴和图形元素。Axes类是图表的子图,用于在图形对象中放置图表元素。 -
matplotlib.axis:该模块提供了Axis类,用于管理坐标轴的属性和刻度。Axis类负责绘制坐标轴和刻度线,并提供了一些方法用于设置刻度标签和刻度范围。 -
matplotlib.patches:该模块提供了各种形状的Patch类,用于绘制图形元素,如矩形、圆形、多边形等。这些图形元素可以添加到Axes对象中。 -
matplotlib.lines:该模块提供了Line2D类,用于绘制线条和曲线。Line2D类可以用于绘制折线图、曲线图等。 -
matplotlib.text:该模块提供了Text类,用于在图表中添加文本标注。Text类可以用于添加标题、标签、注释等文本内容。
了上述模块之外,还有其他一些模块用于特定的任务,如matplotlib.colors(颜色处理)、matplotlib.colorbar(颜色条处理)、matplotlib.ticker(刻度处理)等。
三、项目实践
介绍
从豆瓣上挖取2022年250个经典电影的名单并绘制成词云图
代码
import requests
from bs4 import BeautifulSoup
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 用于绘制词云图的列表
title_list = []
#设置请求头,避免网页出现418问题
head = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47',
'referer': 'https://movie.douban.com/subject/33447633/?from=showing'
}
# 逐页爬取
for start_num in range(0, 250, 25):
context = requests.get(f'https://movie.douban.com/top250?start={start_num}', headers=head).text
soup = BeautifulSoup(context, 'html.parser')
# 获取标签span中class为title的对象
all_titles = soup.findAll("span", attrs={'class': 'title'})
# 将内容输入绘制词云图使用的列表
for title in all_titles:
title_string = title.string
if "/" not in title_string:
# print(title_string)
title_list.append(title_string)
# print(title_list)
text = ' '.join(title_list)
wc = WordCloud('C:\Windows\Fonts\Microsoft YaHei UI\msyh.ttc', background_color='white', width=600,
height=400, max_words=50).generate(text)
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
注:上面的print语句为调试节点,用于中途检查获取的内容和列表。
运行结果
