【推荐系统】多任务学习模型
介绍一些多任务学习模型了解是如何处理多任务分支的。
ESSM, Entire Space Multi-Task Model
阿里提出的ESSM全称Entire Space Multi-Task Model,全样本空间的多任务模型,有效地解决了CVR建模(转化率预估)中存在的两个非常重要的问题:样本选择偏差(SSB,sample selection bias)和数据稀疏。
 ESSM网络结构
ESSM网络结构
ESMM的整体网络结构如图所示,能够看到ESMM的两个特点:
- CTR与CVR这两个塔,共享底座embedding。 因此CVR样本数量太少了,也就是存在开头提到的两个问题中的数据稀疏问题,所以很难充分训练学到好的embedding表达,但是CTR样本很多,这样共享底座embedding,有点transfer learning的味道,帮助CVR的embedding向量训练的更充分,更准确。
- CVR这个塔其实个中间变量,他没有自己的损失函数也就意味着在训练期间没有明确的监督信号,在ESMM训练期间,主要训练的是CTR和CTCVR这两个任务,这一点从ESMM的loss函数设计也能看出来。

MMoE, Multi-gate Mxture-of-Experts
谷歌的MMoE,全称Multi-gate Mixture-of-Experts。ESMM模型中,两个塔有明确的依赖关系,性能显著。但如果这些塔之间关联性很小时,性能会很差,甚至出现【跷跷板】现象,即一个task的性能提升是通过损害另一个task性能作为代价换来的。
 MMoE网络结构
MMoE网络结构
- (a)展示了传统的MTL模型结构,即多个task共享底座(一般都是embedding向量),
- (b)是论文中提到的一个gate的Mixture-of-Experts模型结构,
- (c)则是论文中的MMoE模型结构。
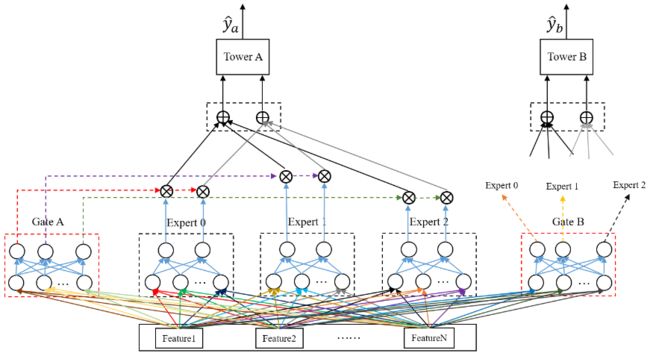 MMoE模型细节版
MMoE模型细节版

PLE, Progressive Layered Extraction model
腾讯的PLE模型,全称Progressive Layered Extraction model。缓解了多任务学习的两大问题:负迁移(negative transfer)现象和跷跷板(seesaw phenomenon)。
- 负迁移(negative transfer):MTL提出来的目的是为了不同任务,尤其是数据量较少的任务可以借助transfer learning(通过共享embedding,当然你也可以不仅共享embedding,再往上共享基层全连接网络等等这些很常见的操作)。但当两个任务之间的相关性很弱或者非常复杂时,往往发生负迁移,即共享之后效果反而很差。
- 跷跷板现象:当两个task之间相关性很弱或者很复杂时,往往出现的现象是:一个task性能的提升是通过损害另一个task的性能做到的。

 PLE网络结构
PLE网络结构
相比MMoE,PLE做了较大的创新,MMoE把不同task通过gate网络共享相同的expert,而PLE中则把expert分为两种:共享的expert(即上图中的experts Shared)和每个task单独的expert(task-specific experts)。因此,这种设计既保留了transfer learning(通过共享expert)能力,又能够避免有害参数的干扰(避免negative transfer)。
 PLE简化版
PLE简化版

DSSM, Deep Structured Semantic Models
微软的DSSM模型,全称Deep Structured Semantic Models。
 推荐领域常用DSSM模型结构
推荐领域常用DSSM模型结构
模型结构非常简单,主要包括两部分:user侧一个塔,item侧一个塔。user侧特征和item侧特征分别经过各自的DNN(一般情况下,两个DNN结构是一样的)后得到user embedding和item embedding,需要保证输出维度一样,也就是最后一层全连接层隐藏单元个数相同,需要保证user embedding和item embedding的维度相同,因为下一步要做相似度计算(常用内积或者cosine)。损失函数部分则是常用的二分类交叉熵损失,y_true为真实label 0或者1,y_pred为相似度结果。
DSSM模型的缺点:无法使用user#item的交叉特征。
GateNet
新浪微博的GateNet。依据Gate网络施加位置的不同,分为了两种类型:embedding层Gate(Feature Embedding Gate)和 隐藏层Gate(Hidden Gate)。
embedding层Gate就是把Gate网络施加在embedding层,隐藏层Gate就是把Gate网络施加在MLP的隐藏层.
两种gate都具体分为两种:bit-wise和vector-wise。bit-wise就是每一个特征的embedding向量的每一个元素(bit)都会有一个对应的Gate参数,而vector-wise则是一个embedding向量只有一个Gate参数。假设样本有两个特征,每个特征embedding维度取3,用图来形象的对比下bit-wise和vector-wise的gate的区别:

论文中关于gate网络参数是否共享提出了两个概念:
- field private: 就是每个特征都有自己的一个gate(意味着gate数量等于特征个数),这些gate之间参数不共享,都是独立的。图1、图2中gate的方式就是这种。
- field sharing: 与field private相反,不同特征共享一个gate,只需要一个gate即可。优点就是参数大大减少,缺点也是因为参数大大减少了,性能不如field private。
论文中给出的实验表明,field private方式的模型效果要好于field sharing方式。
- 问题1:gate参数field private方式与field sharing方式那个效果好?实验结果表明,field private方式的模型效果优于field sharing方式。
- 问题2:gate施加方式 bit-wise与vector-wise哪个效果好?在Criteo数据集上,bit-wise的效果比vector-wise的好,但在ICME数据集上得不到这样的结论。
- 问题3:gate施加在embedding层和隐藏层哪个效果好?论文中没有给出结论,但从给出的数据来看在隐藏层的比在embedding层效果好。此外,两种方式都用的话,相比较只用一种,效果提升不大。
- 问题4:gate网络用哪个激活函数好?embedding层是linear,隐藏层是tanh。
GemNN, Gating-Enhanced Multi-Task Neural Networks
百度的GemNN,全称Gating-Enhanced Multi-Task Neural Networks。
 GemNN中gate
GemNN中gate
关于GemNN中gate如图所示,有三个显著的特点:
- gate的位置在embedding层到MLP全连接层之间。
- 没有对每个feature单独做gate,而是把所有feature拼接(concatenation)后,再做gate。
- gate的方式是bit-wise的。

链路上相同的特征embedding会被shared的,这里的shared不是训练时share,而是类似于预训练热启。结合图来说,就是user-ad ranking模型、ad-mt matching模型、user-ad-mt模型一些公共的特征会被共享。

参考
推荐系统(十四)多任务学习:阿里ESMM(完整空间多任务模型)_essm属于多场景吗?-CSDN博客
推荐系统(十五)多任务学习:谷歌MMoE(Multi-gate Mixture-of-Experts )-CSDN博客
推荐系统(十六)多任务学习:腾讯PLE模型(Progressive Layered Extraction model)_天泽28的博客-CSDN博客
推荐系统(十七)双塔模型:微软DSSM模型(Deep Structured Semantic Models)_双塔模型英文-CSDN博客
推荐系统(十八)Gate网络(一):新浪微博GateNet-CSDN博客
推荐系统(十九)Gate网络(二):百度GemNN(Gating-Enhanced Multi-Task Neural Networks)-CSDN博客