推荐系统(十四)多任务学习:阿里ESMM(完整空间多任务模型)
推荐系统(十四)多任务学习:阿里ESMM(完整空间多任务模型)
推荐系统系列博客:
- 推荐系统(一)推荐系统整体概览
- 推荐系统(二)GBDT+LR模型
- 推荐系统(三)Factorization Machines(FM)
- 推荐系统(四)Field-aware Factorization Machines(FFM)
- 推荐系统(五)wide&deep
- 推荐系统(六)Deep & Cross Network(DCN)
- 推荐系统(七)xDeepFM模型
- 推荐系统(八)FNN模型(FM+MLP=FNN)
- 推荐系统(九)PNN模型(Product-based Neural Networks)
- 推荐系统(十)DeepFM模型
- 推荐系统(十一)阿里深度兴趣网络(一):DIN模型(Deep Interest Network)
- 推荐系统(十二)阿里深度兴趣网络(二):DIEN模型(Deep Interest Evolution Network)
- 推荐系统(十三)阿里深度兴趣网络(三):DSIN模型(Deep Session Interest Network)
这篇发表在SIGIR’2018上的文章,虽然是个short paper,但其在业界影响力巨大,可谓阿里妈妈盖坤团队的又一力作。如果说2010-2015这5年广告领域技术是被谷歌、百度统治的,那么在2015年之后,谷歌依然有大量经典影响力的技术输出,国内的大旗则逐渐由阿里扛起,产出了大量有影响力的工作,这其中阿里妈妈盖坤团队功不可没。
ESMM整个模型结构非常符合我个人的审美:简单、优美。ESSM全称Entire Space Multi-Task Model,也就是全样本空间的多任务模型,该模型有效地解决了CVR建模(转化率预估)中存在的两个非常重要的问题:样本选择偏差(SSB,sample selection bias)和数据稀疏。当然CVR领域还存在其他一些比较重要的问题,比如转化延迟反馈问题,这个不在这篇paper也不在本博客讨论范围之内,后面会写一些这方面的博客。
本文将从以下几个方面来介绍ESMM:
- 动机
- ESMM模型结构细节
一、动机
先补充一下目前工业界商业公司流量变现的逻辑背景,一条流量为公司创造商业收入的路径为:请求 → \to → 广告曝光 → \to → 广告点击 → \to → 广告转化。 在这条路径中涉及到非常复杂繁多的算法与博弈,典型的,(1)在【请求 → \to → 广告曝光】阶段涉及到流量(算力)在线分配、沉重复杂的检索、广告填充率预估PVR、竞价博弈以及计费策略;(2)在【广告曝光 → \to → 广告点击】阶段就是必备的点击率预估PCTR;(3)在【广告点击 → \to → 广告转化】阶段则是经典的转化率预估CVR。以上每一个环节的工程及策略优化都会为公司的商业收入带来巨大的提升,当然最终目的还是为了能够在用户,平台,广告主三者博弈之间达到全局最优三者皆赢的均衡状态。
以上,与本文相关的为PCVR,即转化率的预估,而在CVR预估中存在我在开头提到的两个问题:样本选择偏差和数据稀疏。因此,ESMM就是为了解决上面提出的两个问题,当然对于SSB问题,个人认为只是减轻了,并没有解决。
2.1 样本选择偏差(SSB,sample selection bias)
目前业界在训练转化率(CVR)预估模型时,所采用数据集的正负样本分别为:点击未转化为负样本,点击转化为正样本。也就是整个样本集都是在有点击的样本上构建的。但在做在线infer时,是对整个样本空间进行预估,这就导致了样本选择偏差问题(即在离线样本空间有gap)。By the way,首先说明一点是因为我对电商业务不了解,所以下面这段话的判断可能是错误的,希望有经验的大佬们在评论区给出解答。
阿里这篇ESMM论文中描述在线infer时样本空间为有曝光的广告,个人对有曝光的这个空间持异议。在线阶段,通常,当一条流量请求来到,整个检索端需要进行 召回 → \to →粗排 → \to →精排,在精排阶段做ctcvr,此时无论是cvr还是ctr面向的样本空间都是整个样本空间,而不是【有曝光的样本空间】。尤其在联盟广告场景下,你最终精排rank出去的广告还要经过ADX竞价,你根本不知道能不能曝光。
不过相比较单独的只用有点击的样本训练CVR模型,ESMM还是往前进了一大步。至少打平了ctr任务,变成了在整个有曝光的样本空间上进行训练。
2.2 数据稀疏
这个就比较好理解了,用于cvr训练的都是有点击的样本,这部分样本实在是太少了,对于广告而言,大盘的点击率也就在2%左右,其中能够转化的更加少之又少(正样本)。所以在DL流行起来之前,这点样本量,基本上一个xbg之类的也就够了,后来有了DL之后,最多也就是用下MTL,也就是ctr和cvr共享底座embedding,这样cvr的embedding相对学习的比较充分。
这一点上,ESMM倒没有什么创新,也是通过共享底座embedding的方式也减缓这种情况。
二、ESMM模型结构细节
CVR模型的目的很明确,就是预估广告被点击之后的转化率(Post-Click Conversion Rate),
因此,cvr模型训练的时候只能用有点击的样本,这也直接导致了在离线的样本选择偏差(SSB)。如果我们想在训练的时候把样本空间扩大到整个有曝光的样本,那么需要怎么办呢?现在很明确的是CTR任务是用全部有曝光的样本,ESMM这里巧妙的做了转换,即训练CTCVR和CTR这两个任务,那么CTCVR和CTR、CVR之间的关系如何呢?下面就来看一下:
广告从 曝光 → \to → 点击 → \to → 转化 这条路面是有序的,假设我们用 x x x, y y y, z z z来分别表示样本,是否点击,是否转化。那么,我们可以用公式形式化的表达为:
p ( y = 1 , z = 1 ∣ x ) ⏟ p C T V R = p ( y = 1 ∣ x ) ⏟ p C T R × p ( z = 1 ∣ y = 1 , x ) ⏟ p C V R (1) \underset{pCTVR}{\underbrace{p(y=1,z=1 | x)}} = \underset{pCTR}{\underbrace{p(y=1|x)}} \times \underset{pCVR}{\underbrace{p(z=1|y=1, x)}} \tag{1} pCTVR p(y=1,z=1∣x)=pCTR p(y=1∣x)×pCVR p(z=1∣y=1,x)(1)
公式(1)清楚的表达了CTCVR与CTR、CVR之间的关系,有了这个关系就好办了,ESMM的出发点就是:既然CTCVR和CTR这两个任务训练是可以使用全部有曝光样本的,那我们通过这学习两个任务,隐式地来学习CVR任务。

- CTR与CVR这两个塔,共享底座embedding。 因此CVR样本数量太少了,也就是存在开头提到的两个问题中的数据稀疏问题,所以很难充分训练学到好的embedding表达,但是CTR样本很多,这样共享底座embedding,有点transfer learning的味道,帮助CVR的embedding向量训练的更充分,更准确。
- CVR这个塔其实个中间变量,他没有自己的损失函数也就意味着在训练期间没有明确的监督信号,在ESMM训练期间,主要训练的是CTR和CTCVR这两个任务,这一点从ESMM的loss函数设计也能看出来。
ESMM的损失函数如下:
L ( θ c v r , θ c t r ) = ∑ i = 1 N l ( y i , f ( x i ; θ c t r ) ) ⏟ C T R + ∑ i = 1 N l ( y i & z i , f ( x i ; θ c t r × f ( x i ; θ c v r ) ) ⏟ C T C V R (2) L(\theta_{cvr}, \theta_{ctr}) = \underset{CTR}{\underbrace{\sum_{i=1}^N l(y_i, f(x_i; \theta_{ctr}))}} + \underset{CTCVR}{\underbrace{\sum_{i=1}^N l(y_i\&z_i, f(x_i; \theta_{ctr} \times f(x_i; \theta_{cvr}))}} \tag{2} L(θcvr,θctr)=CTR i=1∑Nl(yi,f(xi;θctr))+CTCVR i=1∑Nl(yi&zi,f(xi;θctr×f(xi;θcvr))(2)
用交叉熵的形式把上面的损失函数细致的描述下:
L ( θ c v r , θ c t r ) = ∑ i = 1 N l ( y i , f ( x i ; θ c t r ) ) ⏟ C T R + ∑ i = 1 N l ( y i & z i , f ( x i ; θ c t r × f ( x i ; θ c v r ) ) ⏟ C T C V R = − 1 N ∑ i = 1 N ( y i l o g y i ^ + ( 1 − y i ) l o g ( 1 − y i ^ ) ) + − 1 N ∑ i = 1 N ( y i & z i l o g ( y i ^ × z i ^ ) + ( 1 − y i & z i ) l o g ( 1 − y i ^ × z i ^ ) ) (3) \begin{aligned} L(\theta_{cvr}, \theta_{ctr}) &= \underset{CTR}{\underbrace{\sum_{i=1}^N l(y_i, f(x_i; \theta_{ctr}))}} + \underset{CTCVR}{\underbrace{\sum_{i=1}^N l(y_i\&z_i, f(x_i; \theta_{ctr} \times f(x_i; \theta_{cvr}))}} \\ &= -\frac{1}{N}\sum_{i=1}^{N}(y_ilog\hat{y_i} + (1-y_i)log(1-\hat{y_i})) + -\frac{1}{N}\sum_{i=1}^{N}(y_i\& z_ilog(\hat{y_i}\times\hat{z_i}) + (1-y_i\& z_i)log(1-\hat{y_i}\times\hat{z_i})) \end{aligned}\tag{3} L(θcvr,θctr)=CTR i=1∑Nl(yi,f(xi;θctr))+CTCVR i=1∑Nl(yi&zi,f(xi;θctr×f(xi;θcvr))=−N1i=1∑N(yilogyi^+(1−yi)log(1−yi^))+−N1i=1∑N(yi&zilog(yi^×zi^)+(1−yi&zi)log(1−yi^×zi^))(3)
我们在实现的时候,上面 y i & z i y_i\&z_i yi&zi,实际上就是转化的label,因为有转化的必然有点击。
下面来看下paddle关于上面这个loss的实现:
def forward(self, inputs):
emb = []
# input feature data
for data in inputs:
feat_emb = self.embedding(data)
feat_emb = paddle.sum(feat_emb, axis=1)
emb.append(feat_emb)
# 1. 共享的embedding底座
concat_emb = paddle.concat(x=emb, axis=1)
# 2. ctr塔
ctr_output = concat_emb
for n_layer in self._ctr_mlp_layers:
ctr_output = n_layer(ctr_output)
ctr_out = F.softmax(ctr_output)
# 3. cvr塔
cvr_output = concat_emb
for n_layer in self._cvr_mlp_layers:
cvr_output = n_layer(cvr_output)
cvr_out = F.softmax(cvr_output)
# 4. ctcvr计算
ctr_prop_one = paddle.slice(ctr_out, axes=[1], starts=[1], ends=[2])
cvr_prop_one = paddle.slice(cvr_out, axes=[1], starts=[1], ends=[2])
# ctr * cvr = ctcvr
ctcvr_prop_one = paddle.multiply(x=ctr_prop_one, y=cvr_prop_one)
ctcvr_prop = paddle.concat(
x=[1 - ctcvr_prop_one, ctcvr_prop_one], axis=1)
return ctr_out, ctr_prop_one, cvr_out, cvr_prop_one, ctcvr_prop, ctcvr_prop_one
# loss的计算,对应公式(2)和(3)
def loss(self):
# ctr loss
loss_ctr = paddle.nn.functional.log_loss(
input=ctr_out_one, label=paddle.cast(
ctr_clk, dtype="float32"))
# ctcvr loss
loss_ctcvr = paddle.nn.functional.log_loss(
input=ctcvr_prop_one,
label=paddle.cast(
ctcvr_buy, dtype="float32"))
# add
cost = loss_ctr + loss_ctcvr
avg_cost = paddle.mean(x=cost)
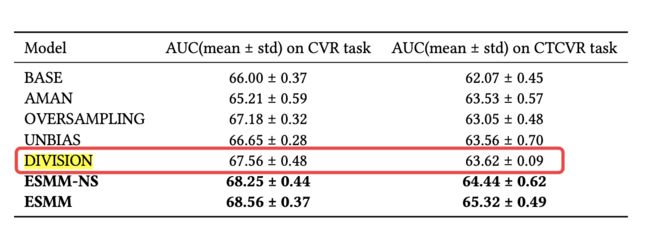
从公式(1)能够看出,ESMM中用的连乘,那么理论上也可以用除法,即 pCVR = pCTCVR / pCTR ,这只需分别训练一个CTCVR模型和一个CTR模型。这种在实际应用中会遇到比较大的问题,真实场景预测出来的pCTR和pCTCVR值都比较小,因此,如果用“除”的方式会出现pCVR大于1的情况,这显然是有问题的。ESMM在实验中也比较了这种方式,实验效果是没有连乘好的,具体实验结果如下表所示:
参考文献
- Ma X, Zhao L, Huang G, et al. Entire space multi-task model: An effective approach for estimating post-click conversion rate[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018: 1137-1140.