java异常以及工具体系
Java异常以及工具类体系
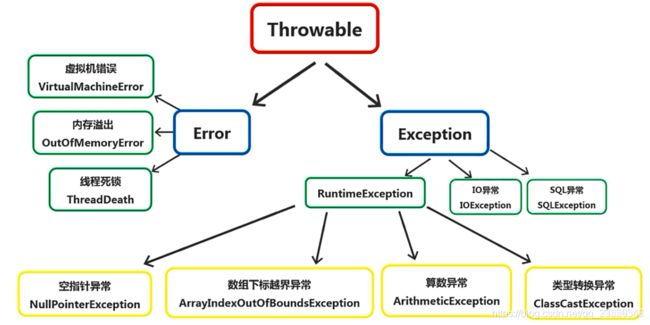
RuntimeException与非RuntimeException
- RuntimeException:不可预知,比如空指针异常数组越界异常这些
- 非RuntimeException:可预知,写代码的时候编译器校验的时候会标红
ERROR与Exception的区别
Throwable: 有两个重要的子类:Exception(异常)和 Error(错误),二者都是 Java 异常处理的重要子类,各自都包含大量子类。
- 异常能被程序本身可以处理,错误是无法处理。
- 从责任角度看,错误属于JVM本身出现了问题,内存溢出,死锁等,虚拟机自己出问题,自己当然无法处理;异常属于程序出了问题,可以被JVM处理,例如可以跳过,抛出,中断等。
常见异常分类
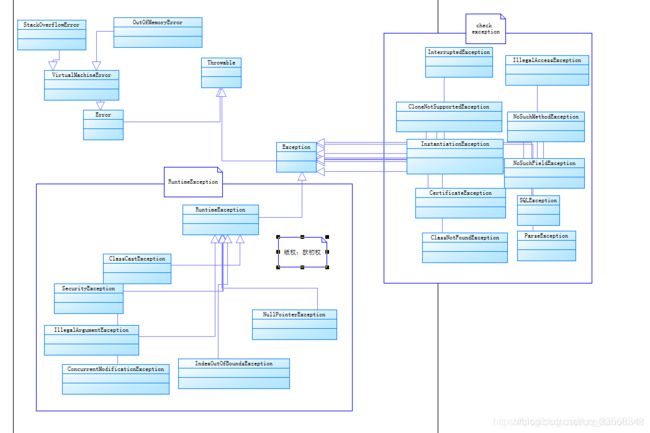

对于NoClassDefFoundError错误,进行一下补充:
在类加载的时候出现了异常(例如静态代码块执行中除了问题),就会导致加载失败,以后再次使用,就会出现问题
OOM相关知识点
- java.lang.OutOfMemoryError: Java heap space ------>java堆内存溢出,此种情况最常见,一般由于内存泄露或者堆的大小设置不当引起。对于内存泄露,需要通过内存监控软件查找程序中的泄露代码,而堆大小可以通过虚拟机参数-Xms,-Xmx等修改。
- java.lang.OutOfMemoryError: PermGen space ------>java永久代溢出,即方法区溢出了,一般出现于大量Class或者jsp页面,或者采用cglib等反射机制的情况,因为上述情况会产生大量的Class信息存储于方法区。此种情况可以通过更改方法区的大小来解决,使用类似-XX:PermSize=64m -XX:MaxPermSize=256m的形式修改。另外,过多的常量尤其是字符串也会导致方法区溢出。
- java.lang.StackOverflowError ------> 在没有设置栈空间限制的情况下不会抛OOM error,但也是比较常见的Java内存溢出。JAVA虚拟机栈溢出,一般是由于程序中存在死循环或者深度递归调用造成的,栈大小设置太小也会出现此种溢出。可以通过虚拟机参数-Xss来设置栈的大小。
oom排查:见jvm调优帖
Java异常处理机制
- 抛出异常:创建异常对象,交由运行时系统处理
- 捕获异常:寻找合适的异常处理器处理异常,否则终止
抛出异常最多可以被一个catch块所捕获,尽量不要捕获exception这种通用异常
public class ExceptionHandleMechanism {
public static void doWork() {
try {
int i = 10 / 0; //会抛出异常
System.out.println("i=" + i);
} catch (ArithmeticException e) {
//捕获 Exception
System.out.println("ArithmeticException: " + e);
} finally {
System.out.println("Finally");
}
}
public static void main(String[] args) {
doWork();
System.out.println("Mission Complete");
}
}


JVM无法判断,并且对于保存的堆栈需要进行快照,消耗资源

Collection 体系
将集合中的功能不断向上抽取,实现了集合体系结构

LIST与SET

ArrayList:基于数组
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
grow方法,申请一个新的数组,并且进行赋值
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
Vector:加入动态锁
主要方法加入了同步锁
public synchronized boolean addAll(Collection<? extends E> c) {
modCount++;
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityHelper(elementCount + numNew);
System.arraycopy(a, 0, elementData, elementCount, numNew);
elementCount += numNew;
return numNew != 0;
}
Linkedlist:基于链表
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
操作 数组 链表
随机访问 O(1) O(N)
头部插入 O(N) O(1)
头部删除 O(N) O(1)
尾部插入 O(1) O(1)
尾部删除 O(1) O(1)
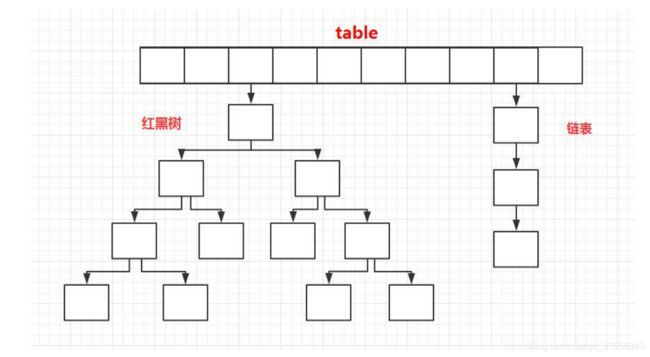
HashMap
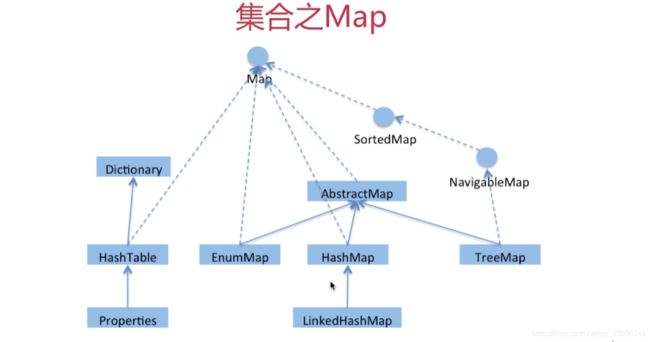
数组和链表组成,兼具二者优点
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
通过哈希值决定寻址,哈希值相同的就以链表的形式存储,put方法基本逻辑

Hashmap返回哈希值的方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
插入元素的方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//算出键值对在tab里的具体位置
tab[i] = newNode(hash, key, value, null);
//如果没有元素,则new一个
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
//如果已经树化
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果没有树化
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
//更新值得操作
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
//进行扩容
afterNodeInsertion(evict);
return null;
}
获取元素得方法
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
扰动函数,大范围的扰动空间,40亿的映射空间,难以出现碰撞
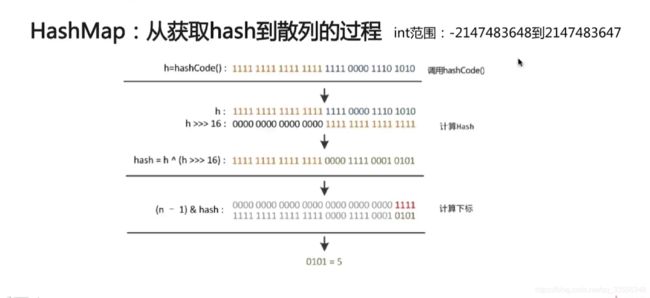

如何有效减少hashmap得碰撞

public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
将传入得大小找到最近的2的n次方的值

HashMap、Hashtable、ConccurentHashMap
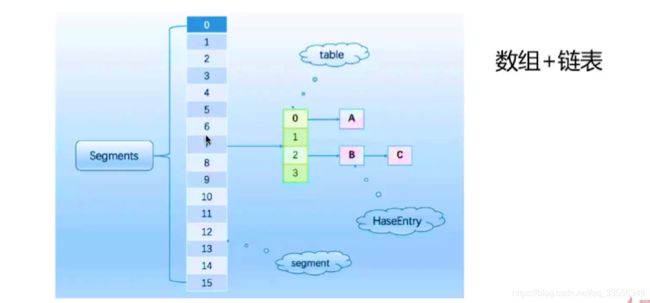
如何优化Hashtable?
- 早期CHM通过锁细粒度化,将整锁拆解成多个锁进行优化
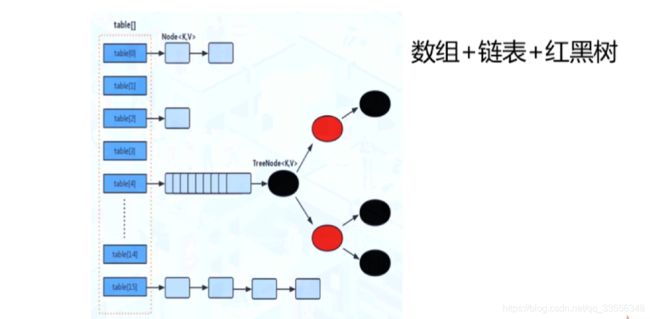
- 当前的CHM:CAS+synchronized使锁更细化
只锁定首节点,只要hash不冲突即可
用于做大小控制的标识符(volatile)
private transient volatile int sizeCtl;
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
//尝试使用CAS进行添加
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}



JUC
常见面试题
介绍Collection框架的结构
集合是Java中的一个非常重要的一个知识点,主要分为List、Set、Map、Queue三大数据结构。它们在Java中的结构关系如下:
Collection接口是List、Set、Queue的父级接口。
Set接口有两个常用的实现类:HashSet和TreeSet。List接口的常用接口有ArrayList和Vector接口。
Map接口有两个常用的实现类:Hashtable和HashMap。
Collection框架中实现比较要实现什么接口
要实现比较有两种方式:第一种,实体类实现Comparable接口,并实现 compareTo(T t) 方法,我们称为内部比较器。第二种,创建一个外部比较器,这个外部比较器要实现Comparator接口的 compare(T t1, T t2)。
Comparable与Comparator
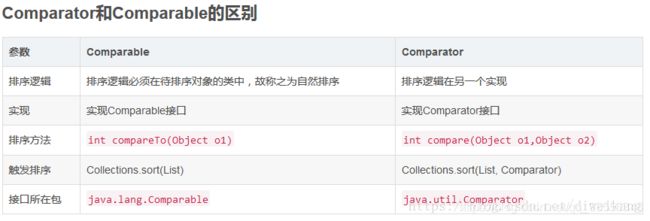
Comparable可以认为是一个内比较器,实现了Comparable接口的类有一个特点,就是这些类是可以和自己比较的,至于具体和另一个实现了Comparable接口的类如何比较,则依赖compareTo方法的实现,compareTo方法也被称为自然比较方法。如果开发者add进入一个Collection的对象想要Collections的sort方法帮你自动进行排序的话,那么这个对象必须实现Comparable接口,implements Comparable并且**@Override**。
Comparator可以认为是是一个外比较器,个人认为有两种情况可以使用实现Comparator接口的方式:
1、一个对象不支持自己和自己比较(没有实现Comparable接口),但是又想对两个对象进行比较
2、一个对象实现了Comparable接口,但是开发者认为compareTo方法中的比较方式并不是自己想要的那种比较方式
iterator与iterable
public interface Iterable<T> {
Iterator<T> iterator();
}
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}
Iterable用于返回一个具体的迭代器,而Iterator就是那个具体的迭代器
例如LinkedList中的ListItr和DescendingIterator两个内部类,就分别实现了双向遍历和逆序遍历。通过返回不同的Iterator实现不同的遍历方式,这样更加灵活。如果把两个接口合并,就没法返回不同的Iterator实现类了。
ArrayList和Vector的区别(是否有序、是否重复、数据结构、底层实现)
ArrayList和Vector都实现了List接口,他们都是有序集合,并且存放的元素是允许重复的。它们的底层都是通过数组来实现的,因此列表这种数据结构检索数据速度快,但增删改速度慢。
而ArrayList和Vector的区别主要在两个方面:
第一,线程安全。Vector是线程安全的,而ArrayList是线程不安全的。因此在如果集合数据只有单线程访问,那么使用ArrayList可以提高效率。而如果有多线程访问你的集合数据,那么就必须要用Vector,因为要保证数据安全。
第二,数据增长。ArrayList和Vector都有一个初始的容量大小,当存储进它们里面的元素超过了容量时,就需要增加它们的存储容量。ArrayList每次增长原来的0.5倍,而Vector增长原来的一倍。ArrayList和Vector都可以设置初始空间的大小,Vector还可以设置增长的空间大小,而ArrayList没有提供设置增长空间的方法。
HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,并且都是key-value的数据结构。它们的不同点主要在三个方面:
第一,Hashtable是Java1.1的一个类,它基于陈旧的Dictionary类。而HashMap是Java1.2引进的Map接口的一个实现。
第二,Hashtable是线程安全的,也就是说是线程同步的,而HashMap是线程不安全的。也就是说在单线程环境下应该用HashMap,这样效率更高。
第三,HashMap允许将null值作为key或value,但Hashtable不允许(会抛出NullPointerException)。
List 和 Map 区别?(数据结构,存储特点)
这个要从两个方面来回答,一方面是List和Map的数据结构,另一方面是存储数据的特点。在数据结构方面,List存储的是单列数据的集合,而Map存储的是key、value类型的数据集合。在数据存储方面,List存储的数据是有序且可以重复的,而Map中存储的数据是无序且key值不能重复(value值可以重复)。
List、Map、Set三个接口,存取元素时,各有什么特点?
List与Set具有相似性,它们都是单列元素的集合,所以,它们有一个功共同的父接口,叫Collection。Set里面不允许有重复的元素,所谓重复,即不能有两个相等(注意,不是仅仅是相同)的对象 ,即假设Set集合中有了一个A对象,现在我要向Set集合再存入一个B对象,但B对象与A对象equals相等,则B对象存储不进去。所以,Set集合的add方法有一个boolean的返回值,当集合中没有某个元素,此时add方法可成功加入该元素时,则返回true,当集合含有与某个元素equals相等的元素时,此时add方法无法加入该元素,返回结果为false。Set取元素时,没法说取第几个,只能以Iterator接口取得所有的元素,再逐一遍历各个元素。
List表示有先后顺序的集合, 注意,不是那种按年龄、按大小、按价格之类的排序。当我们多次调用add(Obj e)方法时,每次加入的对象就像火车站买票有排队顺序一样,按先来后到的顺序排序。有时候,也可以插队,即调用add(int index,Obj e)方法,就可以指定当前对象在集合中的存放位置。一个对象可以被反复存储进List中,每调用一次add方法,这个对象就被插入进集合中一次,其实,并不是把这个对象本身存储进了集合中,而是在集合中用一个索引变量指向这个对象,当这个对象被add多次时,即相当于集合中有多个索引指向了这个对象,如图x所示。List除了可以以Iterator接口取得所有的元素,再逐一遍历各个元素之外,还可以调用get(index i)来明确说明取第几个。
Map与List和Set不同,它是双列的集合,其中有put方法,定义如下:put(obj key,obj value),每次存储时,要存储一对key/value,不能存储重复的key,这个重复的规则也是按equals比较相等。取则可以根据key获得相应的value,即get(Object key)返回值为key 所对应的value。另外,也可以获得所有的key的结合(map.keySet()),还可以获得所有的value的结合(map.values()),还可以获得key和value组合成的Map.Entry对象的集合(map.entrySet())。
List 以特定次序来持有元素,可有重复元素。Set 无法拥有重复元素,内部排序。Map 保存key-value值,value可多值。
为何Map接口不继承Collection接口?
尽管Map接口和它的实现也是集合框架的一部分,但Map不是集合,集合也不是Map。因此,Map继承Collection毫无意义,反之亦然。
如果Map继承Collection接口,那么元素去哪儿?Map包含key-value对,它提供抽取key或value列表集合的方法,但是它不适合“一组对象”规范。
hashCode()和equals()方法有何重要性?
HashMap使用Key对象的hashCode()和equals()方法去决定key-value对的索引。当我们试着从HashMap中获取值的时候,这些方法也会被用到。如果这些方法没有被正确地实现,在这种情况下,两个不同Key也许会产生相同的hashCode()和equals()输出,HashMap将会认为它们是相同的,然后覆盖它们,而非把它们存储到不同的地方。同样的,所有不允许存储重复数据的集合类都使用hashCode()和equals()去查找重复,所以正确实现它们非常重要。equals()和hashCode()的实现应该遵循以下规则:
(1)如果o1.equals(o2),那么o1.hashCode() == o2.hashCode()总是为true的。
(2)如果o1.hashCode() == o2.hashCode(),并不意味着o1.equals(o2)会为true。
Collections类是什么?
Java.util.Collections是一个工具类仅包含静态方法,它们操作或返回集合。它包含操作集合的多态算法,返回一个由指定集合支持的新集合和其它一些内容。这个类包含集合框架算法的方法,比如折半搜索、排序、混编和逆序等。
队列和栈是什么,列出它们的区别?
栈和队列两者都被用来预存储数据。java.util.Queue是一个接口,它的实现类在Java并发包中。队列允许先进先出(FIFO)检索元素,但并非总是这样。Deque接口允许从两端检索元素。
栈与队列很相似,但它允许对元素进行后进先出(LIFO)进行检索。Stack是一个扩展自Vector的类,而Queue是一个接口。