零代码爬虫神器 — Web Scraper 的使用
经常会遇到一些简单的需求,需要爬取某网站上的一些数据,但这些页面的结构非常的简单,并且数据量比较小,自己写代码固然可以实现,但杀鸡焉用牛刀?
目前市面上已经有一些比较成熟的零代码爬虫工具,比如说八爪鱼,有现成的模板可以使用,同时也可以自己定义一些抓取规则。但我今天要介绍的是另外一个神器 – Web Scraper,它是 Chrome 浏览器的一个扩展插件,安装后你可以直接在F12调试工具里使用它。
1. 安装 Web Scraper
有条件的同学,可以直接在商店里搜索 Web Scraper 安装它

没有条件的同学,可以来这个网站(crxdl.com/)下载 crx 文件,再离线安装,具体方法可借助搜索引擎解决

安装好后,需要重启一次 Chrome, 然后 F12 就可以看到该工具
2. 基本概念与操作
在使用 Web Scraper 之前,需要讲解一下它的一些基本概念:
sitemap
直译起来是网站地图,有了该地图爬虫就可以顺着它获取到我们所需的数据。
因此 sitemap 其实就可以理解为一个网站的爬虫程序,要爬取多个网站数据,就要定义多个 sitemap。
sitemap 是支持导出和导入的,这意味着,你写的 sitemap 可以分享给其他人使用的。
从下图可以看到 sitemap 代码就是一串 JSON 配置
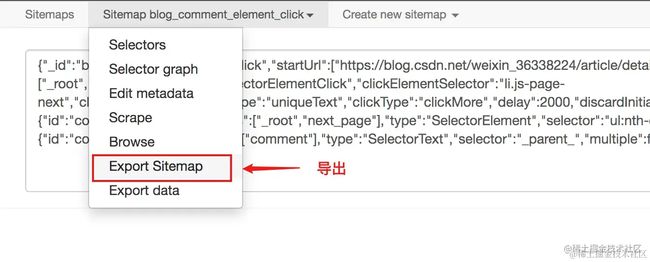
只要拿到这个配置你就可以导入别人的 sitemap

Selector
直译起来是选择器,从一个布满数据的 HTML 页面中去取出数据,就需要选择器去定位我们的数据的具体位置。
每一个 Selector 可以获取一个数据,要取多个数据就需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本篇文章只介绍几种使用频率最高,覆盖范围最广的 Selector,了解了一两种之后,其他的原理大同小异,私下再了解一下很快就能上手。

Web Scraper 使用的是 CSS 选择器来定位元素,如果你不知道它,也无大碍,在大部分场景上,你可以直接用鼠标点选的方式选中元素, Web Scraper 会自动解析出对应的 CSS 路径。
Selector 是可以嵌套的,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是有了这种无穷无尽的嵌套关系,才让我们可以递归爬取整个网站的数据。
如下就是后面我们会经常放的 选择器拓扑,利用它可以直观的展示 Web Scraper 的爬取逻辑

数据爬取与导出
在定义好你的 sitemap 规则后,点击 Scrape 就可以开始爬取数据。
爬取完数据后,不会立马显示在页面上,需要你再手动点击一下 refresh 按钮,才能看到数据。
最后数据同样是可以导出为 csv 或者 xlsx 文件。

3. 分页器的爬取
爬取数据最经典的模型就是列表、分页、详情,接下来我也将围绕这个方向,以爬取 CSDN 博客文章去介绍几个 Selector 的用法。
分页器可以分为两种:
- 一种是,点 下一页 就会重新加载一个页面
- 一种是:点 下一页 只是当前页面的部分内容重新渲染
在早期的 web-scraper 版本中,这两种的爬取方法有所不同。
- 对于需要重新加载页面的,需要 Link 选择器
- 对于不需要重新加载页面的,可以使用 Element Click 选择器
对于某些网站的确是够用了,但却有很大的局限性。
经过我的试验,第一种使用 Link 选择器的原理就是取出 下一页 的 a 标签的超链接,然后去访问,但并不是所有网站的下一页都是通过 a 标签实现。
像下面这样用 js 监听事件然后跳转的,就无法使用 Link 选择器 。
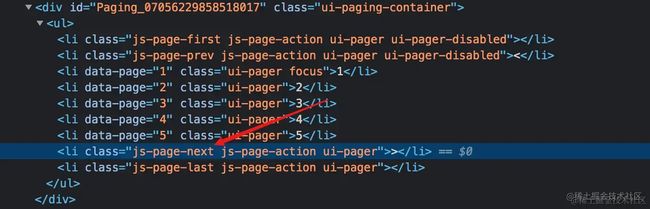
而在新版的 web scraper ,对导航分页器提供了特别的支持,加了一个 Pagination 的选择器,可以完全适用两种场景,下面我会分别演示。
不重载页面的分页器爬取
点入具体一篇 CSDN 博文,拉到底部,就能看到评论区。
如果你的文章比较火,评论的同学很多的时候,CSDN 会对其进行分页展示,但不论在哪一页的评论,他们都隶属于同一篇文章,当你浏览任意一页的评论区时,博文没有必要刷新,因为这种分页并不会重载页面。
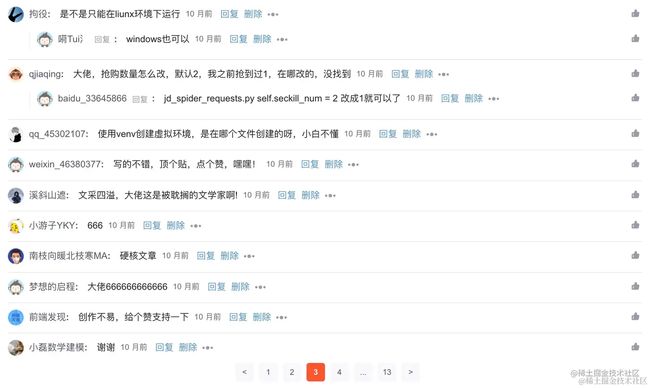
对于这种不需要重载页面的点击,完全可以使用 Element Click 来解决。
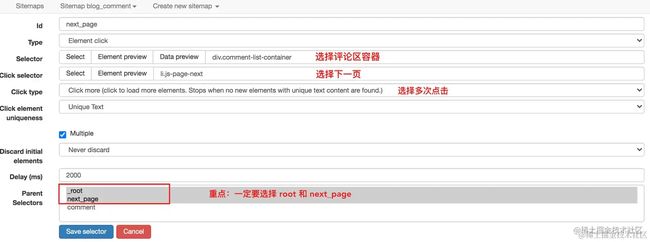
其中最后一点千万注意,要选择 root 和 next_page,只有这样,才能递归爬取

最后爬取的效果如下

使用 Element Click 的 sitemap 配置如下,你可以直接导入我的配置进行研究(配置文件下载:wwe.lanzoui.com/iidSSwghkch…

当然啦,对于分页这种事情,web scraper 提供了更专业的 Pagination 选择器,它的配置更为精简,效果也最好
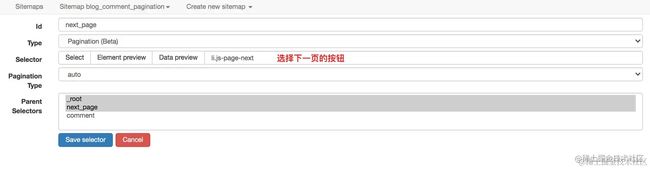
对应的 sitemap 的配置如下,你可以直接导入使用 (配置文件下载:wwe.lanzoui.com/iidSSwghkch…

要重载页面的分页器爬取
CSDN 的博客文章列表,拉到底部,点击具体的页面按钮,或者最右边的下一页就会重载当前的页面。

而对于这种分页器,Element Click 就无能为力了,读者可自行验证一下,最多只能爬取一页就会关闭了。
而作为为分页而生的 Pagination 选择器自然是适用的
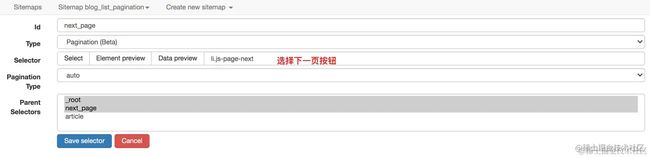
爬取的拓扑与上面都是一样的,这里不再赘述。

对应的 sitemap 的配置如下,你可以直接导入去学习(配置文件下载:wwe.lanzoui.com/iidSSwghkch…

4. 二级页面的爬取
CSDN 的博客列表列表页,展示的信息比较粗糙,只有标题、发表时间、阅读量、评论数,是否原创。
想要获取更多的信息,诸如博文的正文、点赞数、收藏数、评论区内容,就得点进去具体的博文链接进行查看

web scraper 的操作逻辑与人是相通的,想要抓取更多博文的详细信息,就得打开一个新的页面去获取,而 web scraper 的 Link 选择器恰好就是做这个事情的。
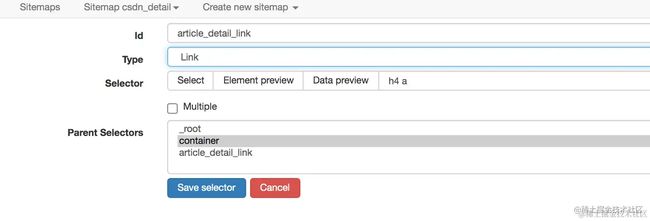
爬取路径拓扑如下

爬取的效果如下

sitemap 的配置如下,你可以直接导入使用(配置文件下载:wwe.lanzoui.com/iidSSwghkch…

5. 写在最后
上面梳理了分页与二级页面的爬取方案,主要是:分页器抓取和二级页面抓取。
只要学会了这两个,你就已经可以应对绝大多数的结构性网页数据了。
例如你可以爬取自己发表在 CSDN 上的所有博文信息,包括:标题、链接、文章内容、阅读数,评论数、点赞数,收藏数。
当然想要用好 web scraper 这个零代码爬取工具,你可能需要有一些基础,比如:
- CSS 选择器的知识:如何抓取元素的属性,如何抓取第 n 个元素,如何抓取指定数量的元素?
- 正则表达式的知识:如何对抓取的内容进行初步加工?
受限于篇幅,我尽量讲 web scraper 最核心的操作,其他的基础内容只能由大家自行充电学习了。
题外话
在此疾速成长的科技元年,编程就像是许多人通往无限可能世界的门票。而在编程语言的明星阵容中,Python就像是那位独领风 骚的超级巨星, 以其简洁易懂的语法和强大的功能,脱颖而出,成为全球最炙手可热的编程语言之一。

Python 的迅速崛起对整个行业来说都是极其有利的 ,但“人红是非多”,导致它平添了许许多多的批评,不过依旧挡不住它火爆的发展势头。
如果你对Python感兴趣,想要学习pyhton,这里给大家分享一份Python全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取
CSDN大礼包:全网最全《Python学习资料》免费分享(安全链接,放心点击)

1️⃣零基础入门
① 学习路线
对于从来没有接触过Python的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~

③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

2️⃣国内外Python书籍、文档
① 文档和书籍资料

3️⃣Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!

②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!

③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!

4️⃣Python面试题
我们学会了Python之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


5️⃣Python兼职渠道
而且学会Python以后,还可以在各大兼职平台接单赚钱,各种兼职渠道+兼职注意事项+如何和客户沟通,我都整理成文档了。

上述所有资料 ⚡️ ,朋友们如果有需要的,可以扫描下方二维码免费领取