多线程经典代码案例及手动实现
目录
一.线程和多线程
二. 多线程的经典的代码案例
1.单例模式
2.阻塞队列
(1)概念介绍
(2)生产者消费者模型
(3)手动实现阻塞队列
(4)代码解释及问题分析
3.定时器
(1)概念介绍
(2)思路分析
(3)手动实现定时器
(4)代码解释及问题分析
问题一:优先级
问题二 :忙等
问题三 :加锁
4.线程池
(1)概念介绍
(2)具体分析
(3)手动实现线程池
(4)代码解释及问题分析
问题一:变量捕获
问题二:线程数量
三. 总结——保证线程安全的思路
一.线程和多线程
1. 创建一个新线程的代价要比创建一个新进程小得多2. 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多3. 线程占用的资源要比进程少很多4. 能充分利用多处理器的可并行数量5. 在等待慢速 I/O 操作结束的同时,程序可执行其他的计算任务6. 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现7. I/O 密集型应用,为了提高性能,将 I/O 操作重叠。线程可以同时等待不同的 I/O 操作。
因此我们在实际开发中,经常采用多线程编程.
而多线程有几个经典的代码案例
- 单例模式
- 阻塞队列
- 定时器
- 线程池
记下来我们就进行具体分析.
二. 多线程的经典的代码案例
1.单例模式
单例模式在我的另一篇博文中已经进行了介绍
工厂模式和单例模式
2.阻塞队列
(1)概念介绍
当队列满的时候, 继续入队列就会阻塞 , 直到有其他线程从队列中取走元素 .当队列空的时候 , 继续出队列也会阻塞 , 直到有其他线程往队列中插入元素 .
(2)生产者消费者模型
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等 待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取.
- 阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力.
- 阻塞队列也能使生产者和消费者之间 解耦.
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.LinkedBlockingDeque;
public class ThreadDemo19 {
public static void main(String[] args) throws InterruptedException {
BlockingDequequene=new LinkedBlockingDeque<>();
//阻塞队列的核心方法,主要有两个
//1.put 入队列
quene.put("hello1");
quene.put("hello2");
quene.put("hello3");
quene.put("hello4");
quene.put("hello5");
//2.take 出队列
String result=null;
result=quene.take();
System.out.println(result);
result=quene.take();
System.out.println(result);
result=quene.take();
System.out.println(result);
result=quene.take();
System.out.println(result);
result=quene.take();
System.out.println(result);
result=quene.take();
System.out.println(result);
}
}
运行结果如下:

而基于阻塞队列实现的"生产者消费者模型"代码如下:
import java.util.concurrent.*;
import java.util.concurrent.BlockingQueue;
//基于阻塞队列写生产者-消费者模型
public class ThreadDemo20 {
public static void main(String[] args) {
BlockingQueue blockingQueue=new LinkedBlockingQueue<>();
//生产者
Thread t1=new Thread(()->{
while (true){
try {
int value=blockingQueue.take();
System.out.println("消费元素:"+value);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t1.start();
//消费者
Thread t2=new Thread(()->{
int value=0;
while (true){
try {
blockingQueue.put(value);
value++;
Thread.sleep(1000);
System.out.println("消费元素:"+value);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t2.start();
}
}
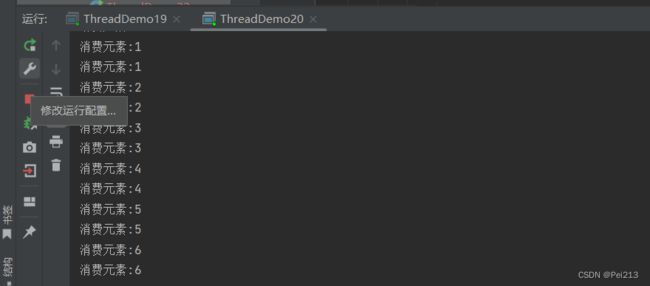
运行结果如下:
(3)手动实现阻塞队列
class MyBlockingQueue{
private int[] item =new int[1000];
//约定[head,tail)队列的有效元素
volatile private int head=0;
volatile private int tail=0;
volatile private int size=0;
//入队列
synchronized public void put(int elem) throws InterruptedException {
while(size== item.length){
//队列满了,插入失败
//return;
this.wait();
}
//把新元素放在tail所在的位置上
item[tail]=elem;
tail++;
//万一tail达到末尾,就需要让tail从头再来
if(tail==item.length){
tail=0;
}
//tail=tail%item.length //可以但不推荐
size++;
this.notify();
}
//出队列
synchronized public Integer take() throws InterruptedException {
while(size==0){
//return null;
this.wait();
}
int value=item[head];
head++;
if(head==item.length){
head=0;
}
size--;
this.notify();
return value;
}
}
- 通过 "循环队列" 的方式来实现.
- 使用 synchronized 进行加锁控制.
- put 插入元素的时候, 判定如果队列满了, 就进行 wait. (注意, 要在循环中进行 wait. 被唤醒时不一
- 定队列就不满了, 因为同时可能是唤醒了多个线程).
- take 取出元素的时候, 判定如果队列为空, 就进行 wait. (也是循环 wait)
(4)代码解释及问题分析

接下来,我们就来做出解释:

但是Java官方并不建议这么使用wait,我们点进wait的源码来看看

而我们写的代码很有可能在别的部分中暗中 interrupt,把 wait 给提前唤醒了,明明条件还没满足(队列非空),但是 wait 唤醒之后就继续往下走了.
当然,我们当前的这个简单的实例代码中,没有 interrupt,但是一个更复杂的项目,就不能保证没有了.
更稳妥的做法是在 wait 晚醒之后,再判定一次条件.
wait 之前,发现条件不满足,开始 wait,然后等到 wait 被唤醒了之后,再确认一下条件是不是满足.如果不满足,还可以继续 wait .
这个时候,我们就可以将判定条件改成while来进行判定,就可以使代码更完善了.
3.定时器
(1)概念介绍
定时器是一种实际开发中非常常用的组件 .比如网络通信中 , 如果对方 500ms 内没有返回数据 , 则断开连接尝试重连 .比如一个 Map, 希望里面的某个 key 在 3s 之后过期 ( 自动删除 ).类似于这样的场景就需要用到定时器 .
- 标准库中提供了一个 Timer 类. Timer 类的核心方法为 schedule .
- schedule 包含两个参数. 第一个参数指定即将要执行的任务代码, 第二个参数指定多长时间之后执行 (单位为毫秒).
//定时器
import java.util.Timer;
import java.util.TimerTask;
public class ThreadDemo22 {
public static void main(String[] args) {
Timer timer=new Timer();
timer.schedule(new TimerTask(){
@Override
public void run() {
System.out.println("hello2");
}
},2000);
System.out.println("hello1");
}
}
- 这里的TimerTask()本质上就是Runnable()
- 而打印hello2的执行是靠Timer内部的线程在时间到了之后执行的.即2秒之后执行run方法
既然定时器的应用这么多,那我们该如何自己实现一个定时器呢?
(2)思路分析
首先,我们来进行分析
- 定时器,内部管理的不仅仅是一个任务,它可以管理很多任务.
所以我们的核心数据结构就是使用堆.
- 而且,虽然任务可能有很多,他们的触发的时闻是不同的,只需要有一个/一组工作线程,每次都找到这些任务中最先到达时间的任务.一个线程先执行最早的任务,做完了之后再执行第二早的... 时间到了就执行,没到就等待.
正因如此,我们就要使用带优先级的阻塞队列PriorityQueue来实现.
同时,定时器里可能会有多个线程在执行shedule方法,因此我们也希望在多线程下操作优先级队列也能保证线程安全.
(3)手动实现定时器
代码如下:
/**
* 定时器的构成:
* 一个带优先级的阻塞队列
* 队列中的每个元素是一个 Task 对象.
* Task 中带有一个时间属性, 队首元素就是即将
* 同时有一个 t 线程一直扫描队首元素, 看队首元素是否需要执行
*/
import java.util.concurrent.PriorityBlockingQueue;
class MyTask implements Comparable{
public Runnable runnable;
public long time;
public MyTask(Runnable runnable,long delay){
this.runnable=runnable;
//取当前时刻的时间戳+delay作为该任务实际执行的时间戳
this.time=System.currentTimeMillis()+delay;
//这里的currentTimeMillis是ms级别的时间戳,是当前时刻和基准时刻的ms数之差
}
@Override
public int compareTo(MyTask o) {
return (int)(this.time-o.time);
}
}
class MyTimer{
//这个结构,带有优先级的阻塞队列,核心数据结构
private PriorityBlockingQueue quene=new PriorityBlockingQueue<>();
//手动封装
//创建个例,表示两方面信息
//1.执行的任务是什么
//2.任务什么时候开始执行
private Object Locker=new Object();
//schedule 包含两个参数. 第一个参数指定即将要执行的任务代码, 第二个参数指定多长时间之后
执行 (单位为毫秒).
public void schedule(Runnable runnable,long delay){
//根据参数,构造MyTask,插入队列即可
MyTask myTask=new MyTask(runnable,delay);
quene.put(myTask);
synchronized (Locker){
Locker.notify();
}
}
//构造线程,负责执行具体任务
public MyTimer() {
Thread t=new Thread(()->{
while(true){
// synchronized (Locker){
try {
//阻塞队列,只有阻塞的入队列和阻塞的出队列,没有阻塞的查看队首元素
MyTask myTask=quene.take();
long CurTime=System.currentTimeMillis();
if(myTask.time<=CurTime){
//时间到了,可以执行任务了
myTask.runnable.run();
}else {
//时间还没到
//把刚才取出的任务,重新塞回队列中
quene.put(myTask);
synchronized (Locker){
Locker.wait(myTask.time-CurTime);
}
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
// }
});
t.start();
}
}
public class ThreadDemo23 {
public static void main(String[] args) {
// System.out.println(System.currentTimeMillis());
MyTimer myTimer=new MyTimer();
myTimer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("hello4");
}
},4000);
myTimer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("hello3");
}
},3000);
myTimer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("hello2");
}
},2000);
myTimer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("hello1");
}
},1000);
System.out.println("hello0");
}
}
- Timer 类提供的核心接口为 schedule, 用于注册一个任务, 并指定这个任务多长时间后执行.
- Task 类用于描述一个任务(作为 Timer 的内部类). 里面包含一个 Runnable 对象和一个 time(毫秒时间戳)
这个对象需要放到 优先队列 中 . 因此需要实现 Comparable 接口 .
- Timer 实例中, 通过 PriorityBlockingQueue 来组织若干个 Task 对象.
通过 schedule 来往队列中插入一个个 Task 对象.
- Timer 类中存在一个 t 线程, 一直不停的扫描队首元素, 看看是否能执行这个任务.
(4)代码解释及问题分析
而这段代码里,有几个值得我们思索的问题:
问题一:优先级
1.当前队列里的 MyTask 元素是按照什么规则来表示优先级的?
按照我们的分析
因为阻塞队列中的任务都有各自的执行时刻 (delay). 最先执行的任务一定是 delay 最小的.
因此我们比较时间来进行排序
static class Task implements Comparable {
private Runnable command;
private long time;
public Task(Runnable command, long time) {
this.command = command;
// time 中存的是绝对时间, 超过这个时间的任务就应该被执行
this.time = System.currentTimeMillis() + time;
}
public void run() {
command.run();
}
@Override
public int compareTo(Task o) {
// 谁的时间小谁排前面
return (int)(time - o.time);
}
}
} 问题二 :忙等
2.当前这个代码中存在一个严重的问题, 就是 while (true) 转的太快了, 造成了无意义的 CPU 浪费. 也就是忙等.
比如第一个任务设定的是 1 min 之后执行某个逻辑 . 但是这里的 while (true) 会导致每秒钟访问队 首元素几万次. 而当前距离任务执行的时间还有很久呢 .
那么该如何解决呢?
class Timer {
// 存在的意义是避免 t 线程出现忙等的情况
private Object Locker = new Object();
}public void run() {
while (true) {
try {
Task task = queue.take();
long curTime = System.currentTimeMillis();
if (task.time > curTime) {
// 时间还没到, 就把任务再塞回去
queue.put(task);
// [引入 wait] 等待时间按照队首元素的时间来设定.
synchronized (Locker) {
// 指定等待时间 wait
Locker.wait(task.time - curTime);
}
} else {
// 时间到了, 可以执行任务
task.run();
}
} catch (InterruptedException e) {
e.printStackTrace();
break;
}
}
}(2)修改 Timer 的 schedule 方法, 每次有新任务到来的时候唤醒一下 t 线程. (因为新插入的任务可能是需要马上执行的).
public void schedule(Runnable runnable,long delay){
MyTask myTask=new MyTask(runnable,delay);
quene.put(myTask);
// [引入 notify] 每次有新的任务来了, 都唤醒一下 t 线程, 检测下当前是否有新任务
synchronized (Locker){
Locker.notify();
}
}
这里使用wait来等待而不是sleep,因为wait方便随时提前唤醒.
wait的参数是"超时时间",时间达到一定数值之后,还没有被notify就不再等待,如果时间还没到就被notify,就立即返回.
问题三 :加锁
3.synchronized()的使用范围.
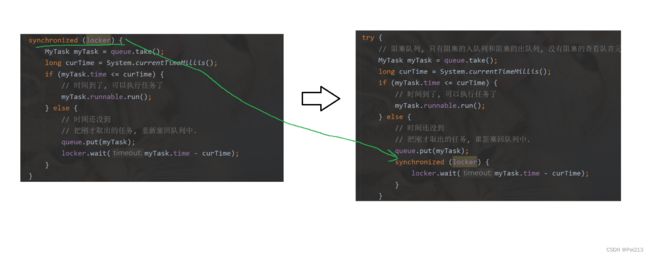 这里为什么将加锁位置改到了这里而不是全部加锁?
这里为什么将加锁位置改到了这里而不是全部加锁?
我们知道,加锁后可以使某部分代码变成具有原子性的代码.这里假如我们为全部这部分代码加锁,假如在中间插入一个新的线程,那么有没有可能发生特殊情况呢?
当然是有的.

这是一种矛盾的状态,因此是有bug的,所以我们把代码进行了修改.我们把锁加在wait外面.

此时它的take和wait操作就都是原子的了.我们再进行分析.
 因此,把锁加在wait外面才是更安全的.
因此,把锁加在wait外面才是更安全的.
4.线程池
(1)概念介绍
想象这么一个场景:在学校附近新开了一家快递店,老板很精明,想到一个与众不同的办法来经营。店里没有雇人, 而是每次有业务来了,就现场找一名同学过来把快递送了,然后解雇同学。这个类比我们平时来 一个任务,起一个线程进行处理的模式。很快老板发现问题来了,每次招聘 + 解雇同学的成本还是非常高的。老板还是很善于变通的,知 道了为什么大家都要雇人了,所以指定了一个指标,公司业务人员会扩张到 3 个人,但还是随着业务逐步雇人。于是再有业务来了,老板就看,如果现在公司还没 3 个人,就雇一个人去送快递,否则只是把业务放到一个本本上,等着 3 个快递人员空闲的时候去处理。这个就是我们要带出的线程池的模式。
线程池最大的好处就是减少每次启动、销毁线程的损耗.
因为从线程池取线程,是纯用户态操作,不涉及到和内核的交互.
- 使用 Executors.newFixedThreadPool(10) 能创建出固定包含 10 个线程的线程池.
- 返回值类型为 ExecutorService
- 通过 ExecutorService.submit 可以注册一个任务到线程池中.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadDemo24 {
public static void main(String[] args) {
//线程池
ExecutorService pool= Executors.newFixedThreadPool(10);
pool.submit(new Runnable(){
@Override
public void run() {
System.out.println("hello");
}
});
}
}(2)具体分析
我们来分析给出的文档:


同样,标准库里也提供了四种拒绝策略
(3)手动实现线程池
接下来,我们就来尝试自己手动实现线程池.
代码如下:
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
class MyThreadPool{
//产生一个阻塞队列
private BlockingQueue queue=new LinkedBlockingQueue<>();
//submit相当于一个生产者,往阻塞队列里面添加任务
public void submit(Runnable runnable) throws InterruptedException {
queue.put(runnable);
}
//相当于消费者,不断地取任务,然后进行执行
public MyThreadPool(int n){
for(int i=0;i{
try {
while (true){
//此处需要让线程内部有个while循环,不断地取任务
Runnable runnable= queue.take();
runnable.run();
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
t.start();
}
}
}
public class ThreadDemo25 {
public static void main(String[] args) throws InterruptedException {
MyThreadPool pool=new MyThreadPool(10);//创建出10个线程
//每次循环都是创建一个新number,没有人修改该number
for (int i = 0; i < 1000; i++) {
int number=i;//直接用i不行,用number是因为匿名内部类需要捕获外部的变量,这里要求变量是final的,而此处的i是不断地被修改的
// 因此我们需要创建另一个变量,把它变成事实final,就可以被捕获了
pool.submit(new Runnable() {
@Override
public void run() {
System.out.println("HELLO"+number);
}
});
}
}
}
运行代码如下:

此处可以看到,线程池中任务执行的顺序和添加顺序不一定相同的.
这非常正常,因为这些线程是无序调度的.
(4)代码解释及问题分析
接下来,我们来分析代码中的一些要点.
问题一:变量捕获
1.这里为什么要用number来接收,直接使用i不可以吗?

直接用i不行,用number是因为匿名内部类需要捕获外部的变量,这里要求变量是final的,而此处的i是不断地被修改的.
因此我们需要创建另一个变量,把它变成事实final,就可以被捕获了.
问题二:线程数量
2. 当前代码中,我们创建了个十个线程的线程池.那么实际开发中,一个线程池的线程数量,设置成几是比较合适的?
我们之前说,线程不是越多越好,因为线程本质上还是要在CPU上执行调度.
网上有很多说法.比如假设 cpu 核心数是 N,线程池的数目,设置成 N,N + 1,2N,15N.... 有很多个说法的版本.
但是实际上,不同的程序,线程做的工作也不一样.
- CPU密集型任务.主要做一些计算工作.要在 cpu 上运行的
- I/O 密集型任务.主要是等待 IO 操作(等待读硬盘,读写网卡)
⌛极端情况,如果你的线程全是使用 cpu,线程数就不应该超过 cpu 核心数
⌛如果你的线程全是使用I/O,线程数就可以设置很多, 远远超出 cpu 核心数⌛然而实践中很少有这么极端的情况,具体要通过测试的方式来确定.取一个执行效率比较高并且占用资源也合适的数量.
三. 总结——保证线程安全的思路
使用没有共享资源的模型适用共享资源只读,不写的模型
- 不需要写共享资源的模型
- 使用不可变对象
直面线程安全
- 保证原子性
- 保证顺序性
- 保证可见性