6.Linux中vi/vim编辑器详解
文章目录
- 前言
- 一.vim/vi 介绍
- 二.vi/vim学习图(初级)
- 三.文本编辑(状态)概览
- 四.使用vi打开文本的方式
- 五.命令模式
-
- 1.进入插入模式(进行文本编辑)
- 2.从插入模式切换为命令行模式
- 3.移动光标
- 4.删除内容
- 5.复制
- 6.查找
- 7. 编辑更改
- 8.跳至指定的行
- 9. 撤销和恢复
- 六.底行模式(last line mode)
-
- 1. 保存退出
- 2. 多文件操作
- 3. 查找和替换
- 4. 列出和跳转行号
- 5. 内容处理
- 七.执行命令
-
- 1. 跳出vi执行命令
- 2.将命令输入到文本
- 3. 选定范围作为命令的输入
- 4. 将指定的行调换顺序
- 总结
- 友情链接
前言
这一节会深入讲解如何在linux当中进行文本编辑一.vim/vi 介绍
在使用 Linux 系统过程中,很多软件的编辑接口都会默认调用 Vim 文件编辑器,例如 crontab、Visudo、edquota等命令;Vim具有编辑程序的能力,例如c c++等,会主动利用不同的字体颜色辨别语法的正确性,为了方便程序编写涉及,需要安装一些插件。
Linux 命令会默认调用 Vim 作为编辑数据的接口,所以建议学习文本编辑的时候,一定要掌握vim/vi的使用。
VIM安装:yum install vim
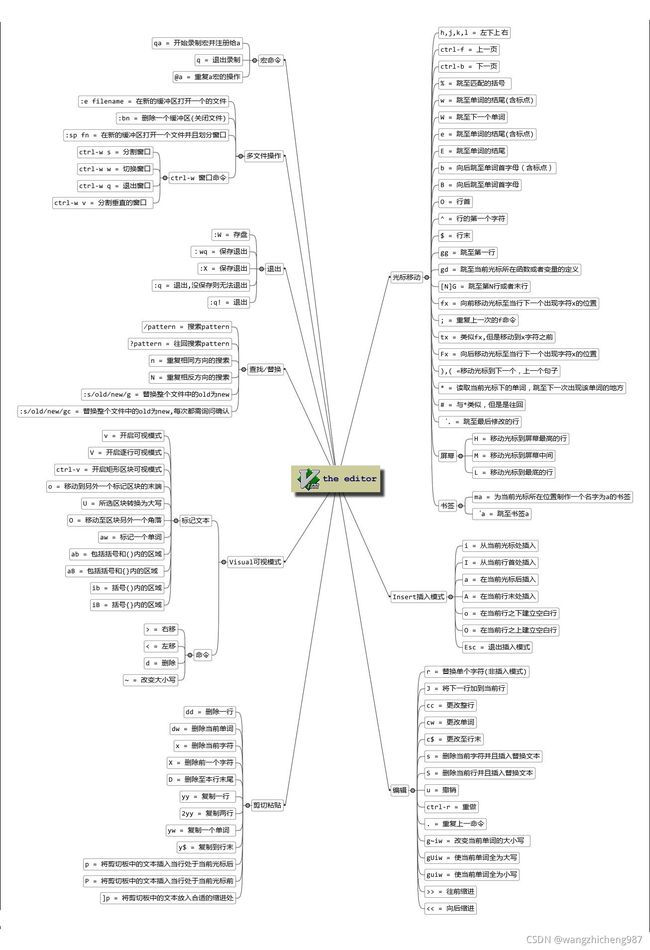
二.vi/vim学习图(初级)
文本编辑可以参照下图,进行学习。
三.文本编辑(状态)概览
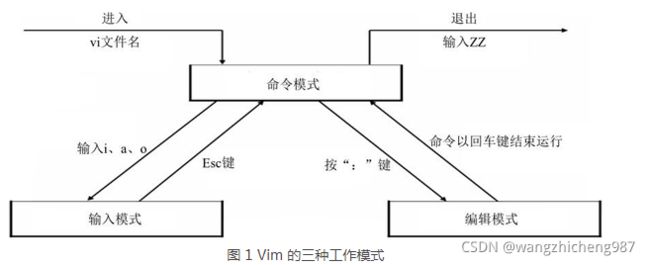
1.状态概览
可以分为三种状态,分别是 命令模式(command mode)、输入/插入模式(Insert mode)和编辑/底行模式(last line mode),各模式的功能区分如下:
- 命令模式command mode)
打开vi的初始状态就是命令模式,用于控制屏幕光标的移动;字符、字或行的删除/移动复制;按i等字符可以进入Insert mode下,按:可以进入 last line mode。 - 插入模式/插入模式(Insert mode)
只有在Insert mode下,才可以做文字输入,按「ESC」键可回到命令模式(command mode)。 - 底行模式(last line mode)
将文件保存或退出vi,也可以设置编辑环境,如寻找字符串、列出行号等,底行模式必须先要到命令模式才能跳转过来。
2.进入vi
在系统提示符号输入vi及文件名称后,就进入vi全屏幕编辑画面:
$ vi file
不过有一点要特别注意,就是您进入vi之后,是处于「命令行模式(command mode)」,您要切换到「插入模式(Insert mode)」才能够输入文字
3.切换至插入模式(Insert mode)编辑文件
在「命令行模式(command mode)」下按一下字母「i」就可以进入「插入模式(Insert mode)」,这时候你就可以开始输入文字了。
4.Insert 的切换
您目前处于「插入模式(Insert mode)」,您就只能一直输入文字,如果您发现输错了字!想用光标键往回移动,将该字删除,就要先按一下「ESC」键转到「命令行模式(command mode)」再删除文字。
5.退出vi及保存文件
在「命令行模式(command mode)」下,按一下「:」冒号键进入「Last line mode」,例如:
: w filename (输入 「w filename」将文章以指定的文件名filename保存)
: wq (输入「wq」,存盘并退出vi)
: q! (输入q!, 不存盘强制退出vi)
四.使用vi打开文本的方式
使用vi打开文本的方式
vi filename :打开或新建文件,并将光标置于第一行首
vi +n filename :打开文件,并将光标置于第n行首
vi + filename :打开文件,并将光标置于最后一行首
vi +/pattern filename:打开文件,并将光标置于第一个与pattern匹配的串处
vi -r filename :在上次正用vi编辑时发生系统崩溃,恢复filename
vi filename....filename :打开多个文件,依次编辑
五.命令模式
1.进入插入模式(进行文本编辑)

i :在光标前
I :在当前行首
a:光标后
A:在当前行尾
o:在当前行之下新开一行
O:在当前行之上新开一行
r:替换当前字符
R:替换当前字符及其后的字符,直至按ESC键
s:从当前光标位置处开始,以输入的文本替代指定数目的字符
S:删除指定数目的行,并以所输入文本代替之
ncw或nCW:修改指定数目的字
nCC:修改指定数目的行
2.从插入模式切换为命令行模式
按「ESC」键。
3.移动光标
可以直接用键盘上的光标来上下左右移动,但有的unix操作系统只能用小写英文字母「h」、「j」、「k」、「l」,分别控制光标左、下、上、右移一格。

按「ctrl」+「b」:屏幕往"后"移动一页。
按「ctrl」+「f」:屏幕往"前"移动一页。
按「ctrl」+「u」:屏幕往"后"移动半页。
按「ctrl」+「d」:屏幕往"前"移动半页。
space:光标右移一个字符
Backspace:光标左移一个字符
Enter :光标下移一行
w或W :光标右移一个字至字首
b或B :光标左移一个字至字首
e或E :光标右移一个字j至字尾
) :光标移至上一行行首
( :光标移至下一行行首
}:光标移至段落开头
{:光标移至段落结尾
G:光标移动到文档最末位
gg: 光标移动到文档最开始位置
n+:光标下移n行
n-:光标上移n行
n$:光标移至第n行尾
H :光标移至屏幕顶行
M :光标移至屏幕中间行
L :光标移至屏幕最后行
0:(注意是数字零)光标移至当前行首
$:光标移至当前行尾
4.删除内容
#x:例如,「6x」表示删除光标所在位置的"后面"6个字符。
#X:例如,「20X」表示删除光标所在位置的"前面"20个字符。
dd:删除光标所在行。
ndw或ndW:删除光标处开始及其后的n-1个字
d0:删至行首
d$:删至行尾
ndd:删除当前行及其后n-1行
x或X:删除一个字符,x删除光标后的,而X删除光标前的
Ctrl+u:删除输入方式下所输入的文本
5.复制
yw:将光标所在之处到字尾的字符复制到缓冲区中。
nyw:复制n个字到缓冲区
yy:复制光标所在行到缓冲区。
yy:例如,6yy表示拷贝从光标所在的该行"往下数"6行文字。
y$: 复制到行位
p:将缓冲区内的内容插入当前光标后。
P: 将缓冲区内的内容插入当前光标前。
]p: 将缓冲区内的内容插入到合适的缩放处
6.查找
/pattern:从光标开始处向文件尾搜索pattern
?pattern:从光标开始处向文件首搜索pattern
n:在同一方向重复上一次搜索命令
N:在反方向上重复上一次搜索命令
7. 编辑更改

cw:更改光标所在处的单词
c#w:例如,c3w表示更改3个单词
r:替换掉当前光标内容,插入
J: 将当前光标所在下一行与本行进行合并后,进入插入模式
cc: 删掉整行,进入插入模式
c$: 删除光标到句尾的内容,进入插入模式
s: 删除当前字符,进入插入模式
S: 删除当前行,进入插入模式
guu: 使当前单词全部变为小写
gUU: 使当前单词全部变为大写
g~~: 改变单词的大小写(大写变成小写,小写变成大写)
~: 改变光标字母的大小写
<<:往前缩进
>>: 往后缩进
8.跳至指定的行
ctrl+g列出光标所在行的行号。
nG:例如,15G,表示移动光标至文章的第15行行首。
9. 撤销和恢复
编辑文件内容时,对文件内容做了修改之后,却发现整个修改过程是错误或者没有必要的,想将内容恢复到修改之前的样子;将文件内容恢复之后,经过仔细考虑,又感觉还是刚才修改过的内容更好,想撤销之前做的恢复操作。基于这 2 种需求,便有了撤销和恢复撤销的快捷键。

以上三个快捷键必须在 Vim 编辑器处于命令模式时才能使用。
例子:输入www.zaishu.cn
然后按“Esc”键,使 Vim 由输入模式转为命令模式,并使用 yy 命令将这一行文本复制到剪贴板中,将光标调整到第一行最后一个字符处,连续按三次 p 命令(粘贴 3 次),则此时文本中的内容变为:
[root@zaishu ~]# vi zaishu.txt
www.zaishu.cn
www.zaishu.cn
www.zaishu.cn
www.zaishu.cn
~
1. u
u(小写)命令就可以使文本内容恢复到上一次做粘贴操作之前的样子,其中“上一次”的含义是,恢复操作是可以叠加的,即按一次就会在现有基础上做一次恢复操作。
比如,继续操作 zaishu.txt 文件,按一次 u,会发现其文本内容变为:
[root@zaishu ~]# vi zaishu.txt
www.zaishu.cn
www.zaishu.cn
www.zaishu.cn
再按一次 u,文本内容继续恢复为:
[root@zaishu ~]# vi zaishu.txt
www.zaishu.cn
www.zaishu.cn
2. ctrl+r
恢复撤销的操作和撤销操作是相对应的,通过按 Ctrl+r组合键,可以撤销之前所做的一次恢复操作。
按一次 Ctrl+r,会发现其文本内容恢复为:
[root@zaishu ~]# vi zaishu.txt
www.zaishu.cn
www.zaishu.cn
www.zaishu.cn
再按一次 Ctrl+R,文本内容又恢复为:
[root@zaishu ~]# vi zaishu.txt
www.zaishu.cn
www.zaishu.cn
www.zaishu.cn
www.zaishu.cn
3. U
大写U的功能,它的作用是 撤销或恢复撤销 对光标所在行文本所做的全部操作。
[root@zaishu ~]# vi zaishu.txt
www.zaishu.cn
www.zaishu.cn
www.ishu.n //将这一行的a和c去掉
www.zaishu.cn
~
按U 全部被恢复了:
[root@zaishu ~]# vi zaishu.txt
www.zaishu.cn
www.zaishu.cn
www.zaishu.cn
www.zaishu.cn
再 U(大写),则又会恢复之前对第 3 行文本的全部操作:
[root@zaishu ~]# vi zaishu.txt
www.zaishu.cn
www.zaishu.cn
www.ishu.n
www.zaishu.cn
六.底行模式(last line mode)
在使用last line mode之前,请记住先按ESC键确定您已经处于command mode下后,再按:冒号即可进入last line mode。
1. 保存退出

w:在冒号输入字母w就可以将文件保存起来。
x:保存当前文件并退出等同于wq
q:按q就是退出,如果无法离开vi,可以在q后跟一个!强制退出。
qw:一般建议离开时,搭配w一起使用,这样在退出的时候还可以保存文件。
q! : 强制退出,做的任何修改不做保存退出。
2. 多文件操作

e file: 打开新的文件进行编辑
sp file: 打开新的文件,并且划分窗口。
ctrl-w: 多窗口操作。通过多个窗口打开多个文件,还可以对窗口进行操作。常用的会使用
ctrl-w w: 切换窗口(切换不同的文本进行编辑)
ctrl-w q: 退出窗口(退出当前文本窗口的编辑)
3. 查找和替换

/pattern:从光标开始处向文件尾搜索内容
?pattern:从光标开始处向文件首搜索内容
n:在同一方向重复上一次搜索命令
N:在反方向上重复上一次搜索命令
:s/old/new/g:将当前行中所有old均用new替代
:n1,n2s/old/new/g:将第n1至n2行中所有old均用new替代
:%s/old/new/g:将文件中所有old均用new替换
4. 列出和跳转行号
set nu:会显示文本当中的行号。
n:n表示一个数字,在冒号后输入一个数字,例如输入109,则光标会跳转到109行。
5. 内容处理
:n1,n2 co n3:将n1行到n2行之间的内容拷贝到第n3行下
:n1,n2 m n3:将n1行到n2行之间的内容剪切到第n3行下
:n1,n2 d :将n1行到n2行之间的内容删除
七.执行命令
在此编辑器中,还可以直接使用 Linux 命令来进一步提高文件编辑的效率,由于 Vim 编辑器中支持直接执行 Linux 命令,可以将一个命令的输出结果存入正在编辑的文件。

常见用法:
:!command:执行shell命令command
:n1,n2 w!command:将文件中n1行至n2行的内容作为command的输入并执行之,若不指定n1,n2,则表示将整个文件内容作为command的输入[. 代表当前光标位置,$ 表示到文档结尾 g表示到行位]
:r!command:将命令command的输出结果放到当前行的下面。
1. 跳出vi执行命令
[root@zaishu web]# vi shu2
1a
2b
3c
4d
5e
6f
7g
~
~
:! ls -l
效果,跳出vi界面,得到ls -l的结果
[root@zaishu web]# vi shu2
total 4
-rw-r--r-- 1 root root 21 Oct 25 17:02 shu2
Press ENTER or type command to continue
total 4
-rw-r--r-- 1 root root 21 Oct 25 17:02 shu2
Press ENTER or type command to continue
[root@zaishu web]# vi shu2
total 4
-rw-r--r-- 1 root root 21 Oct 25 17:02 shu2
Press ENTER or type command to continue
2.将命令输入到文本
输入ls -l命令,将命令的输出内容放到当前光标下面
[root@zaishu ~]# vi zaishu.txt
1a
2b
3c
4d //光标所在位置
5e
6f
7g
:r! ls-l
执行后,结果如下:
[root@zaishu ~]# vi zaishu.txt
1a
2b
3c
4d
total 4
-rw-r--r-- 1 root root 21 Oct 25 17:02 shu2
5e
6f
3. 选定范围作为命令的输入
[root@zaishu ~]# vi shu2
1a
2b
3c
4d
5e //光标当前位置
6f
7g
:.,$!sort -nr -k1 //从光标当前位置到文档结尾,进行降序排序
:.!表示操作文本的范围,其中 . 表示从光标所在行开始,! 表示后续会执行 Linux 命令,执行结果将插入到文本,并且将操作的文本范围内容覆盖。
[root@zaishu ~]# vi shu2
1a
2b
3c
4d
7g
6f
5e
4. 将指定的行调换顺序
将4,5行按降序调换
[root@zaishu ~]# vi shu2
1a
2b
3c
4d
5e
6f
7g
:4,5$! sort -nr -k1
[root@zaishu ~]# vi shu2
1a
2b
3c
5e
4d
6f
7g
总结
本小节详细介绍vi/vim编辑器的使用,对于小白或者linux运维人员已经完全够用,后续对于文本编辑器其他使用方法,例如插件的使用,vimrc文件的配置,利用vim制作自己的开发工具等高级功能可参照后面的文档。友情链接
MySQL性能优化_原理_实战
1、MySQL在金融互联网行业的企业级安装部署
| 目录 | 章节 |
|---|---|
| 版本说明 | 版本说明 |
| 安装MySQL规范 | 1 安装方式 2 安装用户 3 目录规范 |
| MySQL 5.7 安装部署 | 1 操作系统配置 2 创建用户 3 创建目录 4 安装 5 配置文件 6 安装依赖包 7 配置环境变量 8 初始化数据库 9 重置密码 |
| MySQL8 安装 | MySQL8 安装 |
| 源码安装 | 1 安装依赖包 2 生成源码包 3 创建用户 4 编译安装 5 配置数据库 6 连接mysql |
| 多实例部署及注意事项 | 1 多实例概念 2 多实例安装 3 mysqld_multi(多实例第二种安装方式) |
2、mysql启动关闭原理和实战_及常见错误排查
| 目录 | 章节 |
|---|---|
| 生产中MySQL启动方式 | 1、 启动原理 2、参数文件默认位置及优先级 3、 以server方式启动 4、 mysqld_safe方式 5、 mysqld 方式 6、 systemctl 方式 |
| 关库 | 1、相关参数innodb_fast_shutdown 2、相关参数innodb_force_recovery 3、关闭mysql多种方式 |
| 常见MySQL启动失败案例 | 1.、目录权限 2、参数问题 3、配置文件 4、端口占用 5、误删二进制文件 6、undo表空间异常 7、binlog缓冲异常 |
| MySQL启动失败排查方法 | MySQL启动失败排查方法 |
| 连接MySQL数据库的方式 | 连接MySQL数据库的方式 |
| MySQL数据库用户安全策略 | 1、初始化数据库 2、修改密码 3、删除无用的用户 4、mysql_secure_installation |
| 找回丢失的用户密码 | 找回丢失的用户密码 |
3、MySQL字符集和校对规则
| 目录 | 章节 |
|---|---|
| MySQL字符集和校验规则 | MySQL字符集和校验规则 |
| 查看字符集方法 | 1、查看mysql支持的字符集 2、查看字符集的校对规则 3、查看当前数据库的字符集 4、查看当前数据库的校对规则 |
| MySQL字符集设置 | 1、字符集设置层级关系 2、设置MySQL服务器级别字符集 3、设置创建对象的字符集 |
| 字符集案例 | 1、常用字符集每个汉字占用字节多少 2、大小案例 |
| 插入中文乱码解决 | 插入中文乱码解决 |
| 数据库常见字符集及如何选择字符集 | 数据库常见字符集及如何选择字符集 |
| 生产中如何彻底避免出现乱码 | 生产中如何彻底避免出现乱码 |
4、史上最详细的Mysql用户权原理和实战_生产案例
| 目录 | 章节 |
|---|---|
| 访问控制 | 1、连接验证(阶段一) 2、允许的连接 3、连接优先级 4、请求验证(阶段二) |
| 用户管理 | 1、新增用户 2、修改用户 3、删除用户 4、查看用户 |
| 密码管理 | 1、密码修改 2、密码过期设置 3、set password 4、密码过期策略 5、密码插件 |
| MySQL用户权限管理 | 1、权限粒度 2、显示账户权限 3、显示账户非权限属性 4、库级权限 5、表级权限 6、列级权限 7、权限回收 |
| 资源限制 | 1、用户创建指定配额 2、修改配额 |
| MySQL用户权限案例 | 1、断掉已清理的用户 2、忘记密码 3、如何禁止一个ip段的某个用户登录 4、创建开发账号 5、创建复制账号 6、创建管理员账号 |
5、InnoDB引擎原理和实战_通俗易懂
| 目录 | 章节 |
|---|---|
| 缓冲池 | 1、默认引擎 2、设置缓冲池大小 3、优化缓冲池 4、管理缓冲池 5、数据页类型 |
| 线程 | 1、IO线程 2、主线程 |
| index page | index page |
| insert buffer page | insert buffer page |
| 重做日志 | 重做日志 |
| 回滚日志 | 回滚日志 |
| checkpoint,刷写脏页check point | checkpoint |
| 关键特性 | 1、插入缓冲 2、数据写入可靠性提升技术-doublewrite 3、自适应哈希索引-AHI |
| innodb预读预写技术 | 预读写 |
6、MySQL文件详解_物理结构_逻辑结构_原理和案例
| 目录 | 章节 |
|---|---|
| 参数和配置文件 | 1、文件位置 2、查找参数 3、参数类型 4、参数修改 5、示例一 6、示例二 7、注意事项 |
| 错误日志文件 | 错误日志 |
| 通用日志 | 通用日志 |
| 慢查询日志 | 慢日志 |
| binlog | 1、记录什么 2、用途 3、开启和参数配置 4、日志查看 5、日志刷新 6、删除日志 7、日志分析(mysqlbinlog) 8、利用二进制日志文件恢复误删的表 |
| InnoDB存储引擎表空间文件 | 表空间文件 |
| 主从同步相关文件 | 主从同步文件 |
| 套接字文件 | 套接字文件 |
| pid 文件 | pid 文件 |
| redo log | 1、redo初识 2、日志组 3、与oracle redo的区别 4、相关参数 5、和binlog的区别 6、redo 缓冲区(innodb_flush_log_at_trx_commit) |
| InnoDB存储引擎逻辑结构 | 1、表空间 2、段 3、区 4、页 |
| 表碎片清理 | 1、判断是否有碎片 2、整理碎片 |
| 表空间文件迁移 | 1、需求 2、操作 |
7、SQL编程开发与优化事项
| 目录 | 章节 |
|---|---|
| 常用语句 | 1、导入数据 2、库操作 3、表操作 4、数据操作 5、use性能影响 6、delete、truncate、drop的区别 7、SQL语句分类 |
| 数据类型与性能 | 1、整型 2、浮点型 3、字符串类型 4、日期类型 |
| MySQL约束 | 1、unsigned/signed 2、not null 3、count(*) 为什么慢 4、default 5、unique 6、 auto_increment 7、primary key |
| SQL编程高级 | 1、查询Syntax 2、查询列 3、where子句 4、group by … having子句 5、order by子句 6、limit子句(分页) 7、聚合函数 8、合并查询 9、多表查询 10、子查询 |
| 表的元数据库管理 | 1、统计应用库哪些表没有使用innodb存储引擎 2、如何查看表中是否有大对象 3、统计数据库大小 4、统计表的大小 |
8、MySQL索引原理和案例
| 目录 | 章节 |
|---|---|
| MySQL索引与二分查找法 | 1、什么是索引 2、索引的优缺点 3、索引的最大长度 4、二分查找法:折半查找法 5、mysql一张表存多少数据后,索引性能就会下降? |
| 剖析b+tree数据结构 | 1、B和B+树的区别 2、索引树高度 3、非叶子节点 4、指针 5、叶子节点 6、双向指针 7、b+tree插入操作 8、b+tree删除操作 |
| 相辅相成的聚集索引和辅助索引 | 1、聚集索引 2、聚集索引特点 3、聚集索引的优势 4、辅助索引 |
| 覆盖索引与回表查询 | 1、回表查询 2、覆盖索引 |
| 创建高性能的主键索引 | 1、主键索引创建的原则 2、主键索引的特点 3、为什么建议使用自增列作为主键 |
| 唯一索引与普通索引的性能差距 | 1、唯一索引特点 2、普通索引特点 3、唯一索引与普通索引的性能差距 |
| 前缀索引带来的性能影响 | 1、作用 2、坏处 |
| 如何使用联合索引 | 1、什么是联合索引 2、创建原则 3、排序 |
| Online DDL影响数据库的性能和并发 | 1、5.6版本之前 2、新版本 3、online ddl语法 4、相关参数 5、示例 6、影响 |
| pt-ocs原理与应用 | 1、安装pt-osc 2、pt-osc语法 3、案例 4、pt-osc原理 |
| 生产中索引的管理 | 1、建表时创建索引 2、建表后创建索引 3、查看索引 |
| SQL语句无法使用索引的情况 | 1、where条件 2、联合索引 3、联表查询 4、其他情况 |
9、information_schema和sys中性能查看
| 目录 | 章节 |
|---|---|
| 最常用的STATISTICS和TABLES | 1、STATISTICS:用于存放索引的信息 2、TABLES:用于存放库表的元数据信息 |
| 判断索引创建是否合理 | 1、选择性 2、索引创建的建议 |
| 检查联合索引创建是否合理 | 1、联合索引创建是否合理 2、有了联合索引(a,b),还需要单独创建a索引吗? |
| 如何查找冗余索引 | 查找冗余索引 |
| 查找产生额外排序的sql语句 | 额外排序的sql语句 |
| 查找产生临时表的sql语句 | 临时表的sql语句 |
| 全表扫描的sql语句 | 全表扫描的sql语句 |
| 统计无用的索引 | 无用的索引 |
| 索引统计信息 | 1、存储索引统计信息 2、如何查看索引统计信息 |
10、MySQL优化器算法与执行计划
| 目录 | 章节 |
|---|---|
| 简单嵌套查询算法-simple nested-loop join | simple nested-loop join |
| 基于索引的嵌套查询算法-index nested-loop join | index nested-loop join |
| 基于块的嵌套查询算法- block nested-loop join | block nested-loop join |
| Multi-Range Read | MRR |
| bached key access join | BKA |
| mysql三层体系结构 | 体系结构 |
| Index Condition Pushdown | 索引条件下推 |
| 一条查询SQL语句是怎样运行的 | 查询SQL语句 |
| 一条更新SQL语句是怎样运行的 | 更新SQL语句 |
| MySQL长连接与短连接的选择 | 1、相关参数 2、断开连接 |
| 执行计划explain | 1、语法 2、执行计划解析 |
11、MySQL查询优化
| 目录 | 章节 |
|---|---|
| MySQL查询优化技术 | 概览 |
| 子查询优化 | 1、优化器自动优化 2、优化措施:子查询合并 3、优化措施:子查询上拉技术 |
| 外连接消除 | 外连接消除 |
| 生产环境不使用join联表查询 | 不使用join |
| group by分组优化 | 1、group by执行流程 2、为什么group by要创建临时表 |
| order by排序优化 | 排序优化 |
| MySQL性能抖动问题 | 性能抖动问题 |
| count(*)优化 | count(*)优化 |
| 磁盘性能基准测试 | 1、安装sysbench 2、生成文件 3、测试文件io 4、清除文件 |
| MySQL基准测试 | 1、生成数据 2、测试(读) 3、测试(写) 4、清理数据 |
12、事务原理和实战
| 目录 | 章节 |
|---|---|
| 认识事务 | 认识事务 |
| 事务控制语句 | 1、开启事务 2、事务提交 3、事务回滚 |
| 事务的实现方式 | 1、原子性 2、一致性 3、隔离性 4、持久性 |
| purge thread线程 | purge thread线程 |
| 事务统计QPS与TPS | 1、QPS 2、TPS |
| 事务隔离级别 | 1、隔离级别 2、查看隔离级别 3、设置隔离级别 4、不同隔离级别下会产生什么隔离效果 |
| 事务组提交group commit | 组提交 |
| 事务两阶段提交 | 两阶段提交 |
| MVCC多版本并发控制 | 1、MVCC原理 2、MVCC案例 |
13、锁的原理和应用
| 目录 | 章节 |
|---|---|
| 认识锁 | 1、锁的作用 2、加锁的过程 3、锁对象:事务 |
| innodb行锁 | 1、行锁类型 2、共享锁(S锁) 3、排他锁(X锁) |
| 索引对行锁粒度的影响 | 1、行锁粒度有哪些 2、在RC隔离级别下不同索引产生的锁的范围 3、RR隔离级别下不同索引产生锁的范围 |
| FTWRL全局读锁 | FTWRL全局读锁 |
| innodb表锁 | innodb表锁 |
| innodb意向锁与MDL锁 | 1、意向锁 2、意向锁作用 3、意向锁冲突情况 4、MDL锁 |
| 自增锁 | 自增锁 |
| 插入意向锁 | 插入意向锁 |
| 死锁 | 1、什么是死锁 2、相关参数 3、避免死锁 4、锁的状态 |
| 两阶段锁协议 | 两阶段锁协议 |
14、慢查询原理和实战_快速优化方法_优化工具
| 目录 | 章节 |
|---|---|
| 1. 系统状态 | show status |
| 2. 慢查询 | 2.1 慢查询开启 2.2 简单示例 2.3 数据准备 |
| 3. mysqldumpslow | 3.1 语法 3.2 常见用法 |
| 4. pt-query-digest | 4.1 安装 4.2 语法选项 4.3 报告解读 4.4 用法示例 |
| 5. 优化工具(soar) | 5.1 安装配置 5.2 添加数据库 5.3 语句优化 |
15、备份恢复原理和实战_逻辑备份_物理备份_金融行业备份还原脚本
| 目录 | 章节 |
|---|---|
| 1.生产中备份方式 | 1.1 物理备份与逻辑备份 1.2 联机与脱机备份 1.3 完整备份与增量备份 1.4 常用命令 |
| 2.mysqldump备份 | 2.1 相关参数 2.2 备份所有数据库 2.3 备份指定数据库 2.4 备份指定表 2.6 只导出结构 2.7 只导出数据 2.8 --tab(生成文本,类似load) 2.8 mysqldump原理 2.9 binlog异步备份 2.10 利用mysqldump全备及binlog恢复数据 |
| 3.xtrabackup | 3.1 Xtrabackup安装 3.2 原理 3.2 备份过程 3.4 恢复原理 3.3 相关参数 3.4 xtrabackup相关文件 3.5 备份示例 3.6 还原示例 |
| 4.binlog备份和恢复(数据库恢复) | 4.1 找到恢复时间点 4.2 增量恢复 |
| 5. 生产环境的备份恢复实战 | 5.1 实施部署 5.1.1 环境清单 5.1.2 备份目的 5.1.3 备份说明 5.1.4 实施步骤 5.1.5 全备脚本 5.1.6 差异备份脚本 5.2 实施部署备份还原 5.2.1 Xtraback还原全量/差异备份 5.2.2 故障点数据恢复 5.2.3 增量恢复 |
16、主从复制,gtid,并行复制_半同步复制_实操案例_常用命令_故障处理
| 目录 | 章节 |
|---|---|
| 1.认识主从复制 | 1.1 主从复制原理深入讲解 1.2 主从复制相关参数 1.3.主从复制架构部署 1.4从库状态详解 1.5 .过滤复制 |
| 2 .gtid复制 | 2.1 什么是GTID? 2.2 GTID主从配置 2.5 gtid维护 2.4 GTID的特点 2.3 工作原理 2.4 gtid相关状态行和变量 |
| 3. 并行复制 | 3.1 延迟的原因 3.2 并行复制设置 3.3 查看并行复制 |
| 4. 增强半同步复制 | 4.1 异步复制 4.2 半同步复制 4.3 增强半同步复制 4.4 配置增强半同步 |
| 5. 案例 | 5.1 主库删除操作导致sql线程关闭案例 5.2 主从复制中断解决方案及案例 5.3 延迟复制 5.4 主库drop误操作利用延迟复制恢复案例 |
| 6 常用命令 | 6.1 启动线程 6.2 关闭线程 6.3 查看 6.4 重置 6.5 主从数据一致性校验 |
17、MySQL高可用和读写分离架构
MHA
| 目录 | 章节 |
|---|---|
| MHA | 介绍 |
| 架构和相关组件 | 架构和相关组件 |
| 工作流程 | 工作流程 |
| MHA高可用架构部署 | 1、环境准备 2、软件安装 3、创建软链接 4、配置各节点互信 5、节点免密验证 6、mha管理用户 7、配置文件 8、状态检查 9、开启MHA |
| 主库宕机故障模拟及处理 | 主库宕机故障模拟及处理 |
| MHA VIP自动切换 | VIP自动切换 |
| MHA主从数据自动补足 | MHA主从数据自动补足 |
Atlas
| 目录 | 章节 |
|---|---|
| Atlas读写分离高性能架构 | 介绍 |
| 安装配置 | 安装配置 |
| 配置注解 | 配置注解 |
| 启动和关闭 | 启动和关闭 |
| 读写分离架构应用 | 读写分离架构应用 |
| 创建应用用户 | 创建应用用户 |
| Atlas在线管理 | Atlas在线管理 |
| 读写分离避坑指南 | 读写分离避坑指南 |
18、MySQL分库分表_原理实战
| 目录 | 章节 |
|---|---|
| 1.MyCAT分布式架构入门及双主架构 | 1.1 主从架构 1.2 MyCAT安装 1.3 启动和连接 1.4 配置文件介绍 |
| 2.MyCAT读写分离架构 | 2.1 架构说明 2.2 创建用户 2.3 schema.xml 2.4 连接说明 2.5 读写测试 2.6 当前是单节点 |
| 3.MyCAT高可用读写分离架构 | 3.1 架构说明 3.3 schema.xml(配置) 3.4 文件详解 3.4.1 schema标签 3.4.2 table标签 3.4.3 dataNode标签 3.4.4 dataHost 3.4 读写测试 3.5 故障转移 |
| 4.MyCAT垂直分表 | 4.1 架构 4.2 新建表 4.3 配置mycat 4.4 验证 |
| 5 MyCAT水平分表-范围分片 | 5.1 新建表 5.2 schema.xml 5.2 rule.xml 5.3 autopartition-long.txt 5.4 验证 |
| 6. MyCAT水平分表-取模分片 | 取模分片 |
| 7. MyCAT水平分表-枚举分片 | 枚举分片 |
| 8. MyCAT全局表与ER表 | 全局与ER表 |
| 8.1 全局表 | 8.1.1 特性 8.1.2 建表 8.1.3 配置 8.1.4 验证 8.1.5 分析总结(执行计划) |
| 8.2 ER表 | 8.2.1 特性 8.2.2 建表 8.2.3 配置 8.2.4 测试验证,子表是否跟随父表记录分片 8.2.5 分析总结(执行计划) |
19、基准性能测试_sysbench
| 目录 | 章节 |
|---|---|
| 1. sysbench | 1.1 用途 1.2 安装 1.3 版本 1.4 查看帮助 1.5 测试过程阶段 |
| 2 CPU 性能测试 | 2.1 测试原理 2.2 查看帮助 2.3 测试 |
| 3. 内存性能测试 | 3.1 查看帮助信息 3.2 测试过程 |
| 4.磁盘性能基准测试 | 4.1 查看帮助 4.2 生成文件(prepare) 4.3 测试文件io(run) 4.4 结果分析 4.5 清除文件(cleanup) |
| 5. 线程测试 | 5.1 查看帮助信息 5.2 测试过程 |
| 6. MySQL基准测试 | 6.1 语法参数 6.2 生成数据 6.3 测试(读) 6.4 测试(写) 6.5 清理数据 |