tf2.0做LSTM情感分析(二分类、2020李宏毅hw4)
前言
这段时间在做李宏毅ML/DL网课的第四次作业(2020),李老师讲得真的很棒,如果想自学的话我把课程链接放在这儿李宏毅2020网课,里面所有作业的数据集也放在这里:所有作业数据集,提取码:akti,都是这个up主整理的,挺良心的,为这个up主点赞。
写这篇blog主要是为了总结最近几天的学习,以及日后用到模型可以及时拐回来复习。这次的模型在测试集上的准确率有64%左右,并不是特别高,有些过拟合,日后有提高精度的方法我会再去试试。下面写的很多东西都是我自己的理解,可能会有不准确的地方,观看时请带着批判性思维。
数据介绍
这次用的数据集是从twitter上爬下来的评论,标记好情感正负了,共20w条,长这个样子:
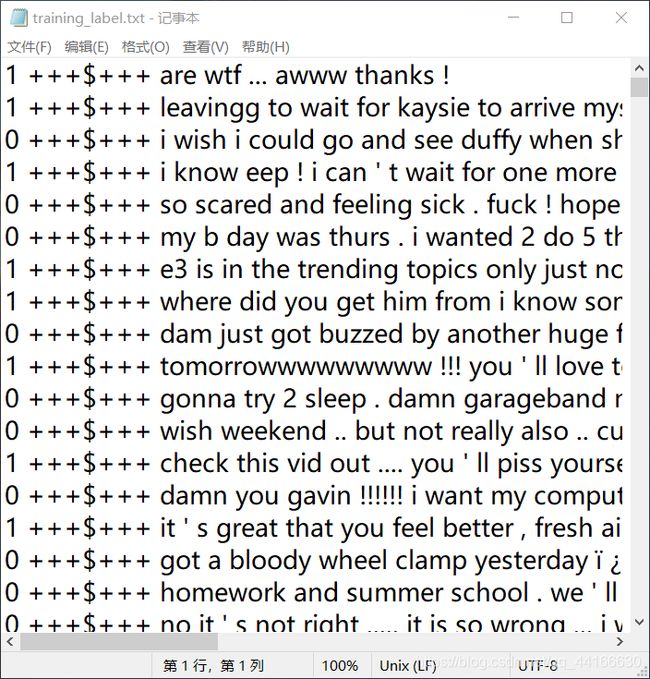
前面是标记,后面是文本。我的想法是把训练集按3:1分为训练集和测试集,然后让模型用训练集来训练,用测试集来测试。(因为作业中的数据并没有提供带标记的训练集)
在训练模型时当然是数据越多越好,更多的数据可以减轻过拟合。其实我这个模型应该就有些过拟合了,但我并没有用全部20w条数据来训练,而是只用了7500条训练,2500条测试,这是为什么呢?
因为在构造LSTM模型时,神经网络的第一层肯定得是Embedding对吧,但很奇怪,只要我在神经网络模型中添加了Embedding层,我的电脑就开始用CPU而不是GPU来跑模型了,20w条数据用CPU跑实在是太慢了。。。但又不能不用Embedding层,所以我就减少了数据量。这应该是最后准确率才64%的一个原因。
代码与分析
1 对文本进行预处理
首先我们将文本中的标点符号给去掉,因为标点符号对我们分辨一个句子的情感用处不大
txt = open("E:/Machine Learning/data/data1/hw4/training_label_short1.txt", 'r', encoding="UTF-8").read()
punctuation = "`~!@#$%^&*()_-=/<>,.?:;[]|\{}"
for ch in punctuation:
txt = txt.replace(ch, ' ')
with open("E:/Machine Learning/data/data1/hw4/training_label_short1_no_punctuation.txt", 'w', encoding="UTF-8") as f:
f.write(txt)
处理后的文本就长这样了:
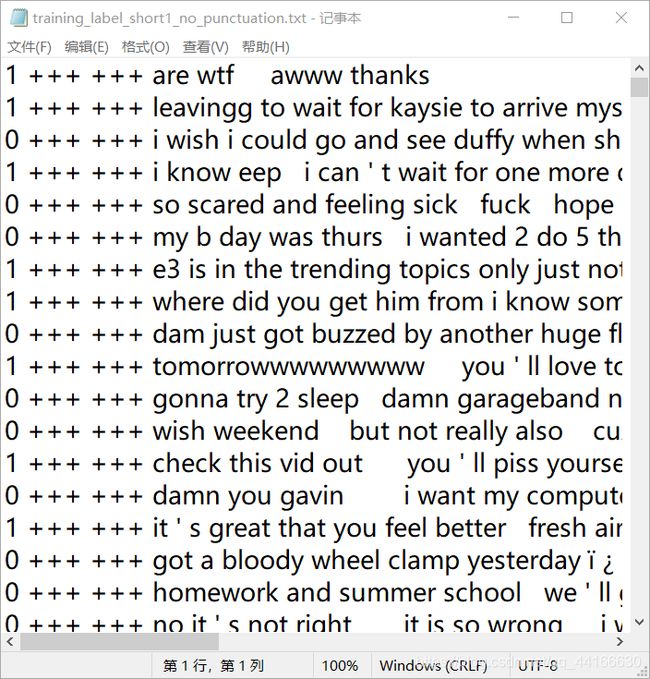
然后我们读取数据并作简单处理
#读取并简单处理数据
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
def load_training_data(path='E:/Machine Learning/data/data1/hw4/training_label_short1_no_punctuation.txt'):
if 'training_label' in path:
with open(path, 'r', encoding='UTF-8') as f:
lines = f.readlines()
lines = [line.strip('\n').split(' ') for line in lines]
x = [line[3:] for line in lines]
y = [line[0] for line in lines]
return x, y
else:
with open(path, 'r', encoding='UTF-8') as f:
lines = f.readlines()
x = [line.strip('\n').split(' ') for line in lines]
return x
print("loading training data ...")
x_train, y_train = load_training_data()
x_train, x_test, y_train, y_test = train_test_split(x_train, y_train, random_state=0)
print(x_train, '\n', y_train)
这里我们把一个句子存到一个list中,list中的一个元素就是一个词语,处理后的x_train和y_train长这样:


2 文本数据—>数值数据
文本数据是一类较为特殊的数据,我们的模型显然没法直接将文本作为输入,所以我们需要把文本数据转换成计算机可以处理的数值数据,比如最简单常用的one-hot编码,但one-hot编码不能体现词与词之间的关系,比如对于“番茄”、“西红柿”、“土豆”三个词来讲,“番茄”的one-hot是[1,0,0],"西红柿"是[0,1,0],“土豆”是[0,0,1]。这三个向量间的距离都一样,但我们凭直觉就能觉得这不太合理,“番茄”和“西红柿”间应该相关性更高才合理吧。所以就有了word embedding,比如很火的一种就是word2vec(注意,word2vec是word embedding的一种)。word embedding就是把一个词语变成一个词向量,词向量间可以体现上下文等信息。(我这个模型用的不是word2vec,而是tf,keras中自带的word embedding)
我们先构建一个词典:
#构造词典
sentence_all = x_train + x_test
index_from = 1
word_index = {} #构造词典,key:word, value:index
for sen in sentence_all:
for i, word in enumerate(sen):
word_index[word] = len(word_index) + index_from + 1
word_index["" ] = 0
word_index["" ] = 1
这个词典的key是word,value是每个word对应的一个整数,比如‘are’对应一个整数23,这样就可以把“I am handsome”这个文本数据变成了“25 75 89”这样的数值数据形式了。
这里说明一点,我们可以看到我们在词典中加入了"PAD"和“UNK”两个单词,我们这样处理是有目的的:因为每个句子长短不一,但我们模型的输入必须是长度一样的,所以加入我们规定每句话的最长长度是30,如果这句话长度大于30,我们就截取前30个word,如果小于30,我们就在句子的后面补充“PAD”这个单词让这个句子的长度为30。至于“UNK”,是说如果我们的词典中没有出现过这个词,比如我们的词典如果没有“wtf”这个词对应的整数,我们就把这个词作为“UNK”,即这个词对应的整数就是1。
词典构造好了,然后我们就遍历一遍所有的句子把每个word转换为词典中对应的整数,代码如下:
#根据上面构造的词典,把句子变成向量
#把单个句子转化为向量
import numpy as np
def transform_wordlist_ids(wordlist, word_index_dict):
word_ids = []
for word in wordlist:
word_ids.append(word_index_dict.get(word, 1)) #如果没找到就
return word_ids
#把整个语料库中的所有句子转化为向量
def transform_sentence_list_id_list(sentence_list, word_index_dict):
id_list = []
for wordlist in sentence_list:
id_list.append(transform_wordlist_ids(wordlist, word_index_dict))
return np.array(id_list)
train_data = transform_sentence_list_id_list(x_train, word_index)
train_labels = np.array(y_train, dtype=np.int32)
test_data = transform_sentence_list_id_list(x_test, word_index)
test_labels = np.array(y_test, dtype=np.int32)
print(train_data.shape, train_labels.shape, test_data.shape, test_labels.shape)
注意,我们这样处理后的词语并没有变成词向量的形式,只是把原来的词语以整数代替了,也就是说变成了计算机可以处理的形式了。其实我个人的感觉上面的代码就像是做了个one-hot,只不过维度很低罢了,因为这样处理后的词语虽然可以作为模型的输入,但同样没有体现词语间的关联和上下文等信息,我们待会再把用一个整数表示的词语变成向量的形式(即词向量)。
这样处理过后每个句子还不是等长的,我们要把每个句子处理成长度都为30的:
import tensorflow as tf
max_length = 30
#使每一个句子向量的长度都为30,大于30截去,小于五十补0
train_data = tf.keras.preprocessing.sequence.pad_sequences(train_data,
maxlen=max_length,
value=word_index['' ],
padding='post')
test_data = tf.keras.preprocessing.sequence.pad_sequences(test_data,
maxlen=max_length,
value=word_index['' ],
padding='post')
print(train_data.shape, train_labels.shape)
print(train_data, train_labels)
# print(test_data, test_labels)
我们可以看下处理后的文本变成什么样了:

我们可以看到,x_train是个7500×30的二维ndarray数组,7500表示总共有7500个句子,30表示每个句子有30个word。(因为我们前面把每个word都表示成了一个整数嘛,所以这里的一个整数元素就代表一个word,应该不难理解)
构造LSTM
接下来我们构造LSTM模型,直接上代码,然后我做简单说明:
#Model
vocab_size = 7500*30
embedding_dim = 30
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=max_length))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.LSTM(units=30))
model.add(tf.keras.layers.Dense(units=256, activation=tf.nn.relu))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(units=1, activation=tf.nn.sigmoid))
model.summary()
模型长这样:

这里说明一下tf.keras.layers.Embedding()中的参数是什么意思:
input_dim:这个参数在我们这里设为7500*30,就是你的输入维度,很好理解,因为我们有7500个句子,一个句子长度为30
.
output_dim:这个参数用来设置词向量的长度,就是原来我们一个词是用一个整数表示对吧,现在我们用一个向量来表示这个词,这个参数就是用来设置这个向量的长度的,这里我们设置成30,就是把这个词语变成一个长度为30的向量。
.
input_length:每个句子的最大长度,我们之前设置的是30
这个Embedding层就是把你的输入数据由一个2维的numpy数组变成一个3维的numpy数组,你可以这么理解:
我们原来的数据是7500×30的二维数组,现在把里面的每个整数变成了一个长度为30的向量,这么做的好处是原来用整数不能体现word间的关联行和上下文等信息,换成向量就可以体现这些信息了!所以经过一个Embedding层后我们的数据变成了7500×30×30的三维数组了。
我刚刚说的其实可以从上面的图片中看出来,你看那个Embedding层是不是(None, 30, 30),至于为什么是None,因为第一维表示数据量嘛,我们给的是7500个句子,但测试集不一定也给7500个句子啊,但每个句子肯定是30×30的。(句子长度是30,每个词的词向量长度为30,所以是30×30)
配置训练过程并训练
这就不多解释了,直接上代码
#配置训练过程
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=['accuracy']
)
#训练模型
model.fit(train_data, train_labels, epochs=8, batch_size=500)
#评估模型
print(model.evaluate(test_data, test_labels))
看看准确率如何:
训练集的准确率:
![]()
测试集的准确率:
![]()
准确率分析
可以看出,有些过拟合了。我这里在训练集的准确率只有76%,其实只要增加训练的epoch数(我这里训练了8个epoch)就可以提高训练集上的准确率,但没有什么必要因为我们要的是测试集的准确率,毕竟过拟合了所以我让模型提前训练停止了,减少一些过拟合。
前面我也说了,我只用了很少一部分数据来训练,增大数据量应该可以很好的减轻过拟合,但因为上面说的原因我并没有做尝试。
END