【JavaEE】_HTTP请求与HTTP响应
目录
1. HTTP协议
2. HTTP请求
2.1 HTTP请求首行
2.2 URL
2.3 HTTP方法
2.3.1 GET请求
2.3.2 POST请求
2.3.3 GET与POST的区别
2.3.4 其他方法
2.4 请求报头header
2.4.1 Host:
2.4.2 Content-Length与Content-Type:
2.4.3 User-Agent(简称UA)
2.4.4 Referer
2.4.5 Cookie
2.5 请求正文body
3. HTTP响应
3.1 响应首行
3.2 报头header
3.3 空行
3.4 正文body
1. HTTP协议
1. HTTP协议一般被称为“超文本传输协议”,即不止可以传输文本,还可以传输图片、音频、视频等二进制数据,是一个应用层协议。
2. 浏览器获取到网页就是基于HTTP,可以将HTTP理解为浏览器与服务器之间的交互桥梁,最常见的是HTTP1.1。
3. 应用层协议需要基于传输层协议向上层提供服务,HTTP就是基于TCP协议实现的。
4. 当我们在浏览器中输入一个网址(URL)时,其实就是浏览器给该网址的服务器发送了一个HTTP请求,然后该网址的服务器返回一个HTTP响应,浏览器再把得到的HTML等数据显示出来,即进行渲染;
5. HTTP协议是一个行文本协议(文本与二进制对应),可以直接用记事本等文本编辑器直接打开查看的;
6. HTTP协议报文格式可以借助一些第三方工具查看,这些工具称为“抓包”工具,如:fiddler,打开后可在左栏查看到当前电脑上某个程序使用HTTP和服务器交互的过程:
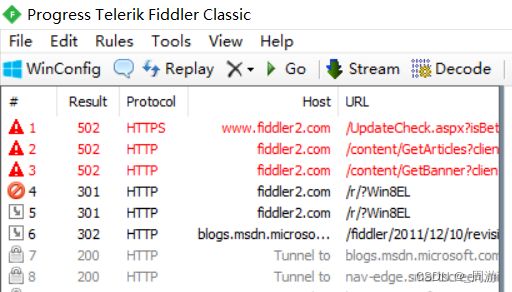
注:(1)fiddler本质是一个代理程序,可能会与别的代理程序冲突,故而在使用fiddler时需要关闭其他的代理程序,包括一些浏览器插件;
代理分为正向代理与反向代理,其中代表着客户端的代理称为正向代理,代表着服务器的代理称为反向代理;
(2)要想正确抓包还需要开启https功能,https是基于http的进化版协议,当下互联网上绝大部分的服务器都是https的,fiddler默认不能抓包https的包,需要手动启用https并安装证书;
2. HTTP请求
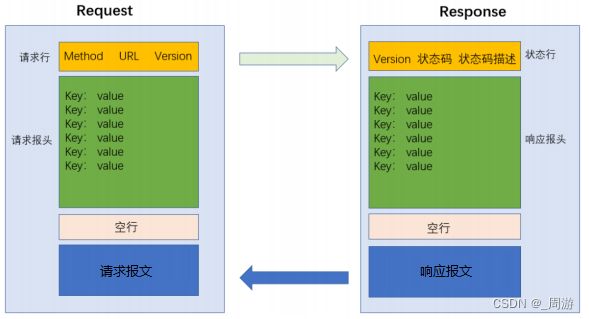
HTTP请求包括四个部分:
(1)首行; (2)请求头(header); (3)空行; (4)正文(body);
如果是GET请求,没有body;如果是POST请求,一般有body;
2.1 HTTP请求首行
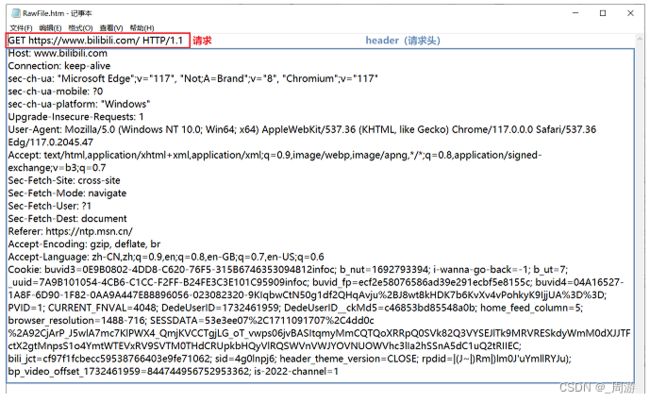
以在浏览器中访问bilibili为例,抓包结果中,首行内容如下:

首行包括三个部分:
(1)GET:是HTTP的方法;
(2)中间部分是URL(唯一资源定位符,标识互联网上唯一的资源的位置),即俗称的网址;
注:URI是唯一资源标识符,是一个身份标识,为了和别的资源区分开,实际上URL也可以起到身份标识的效果,故而URL也可以视为是一个URI;
(3)HTTP/1.1:是HTTP的版本号;
2.2 URL
因特网标准RFC1738规定URL的详细情况如下:

即: 协议名称://ip:端口号/路径?查询字符串
注:(1)TCP、IP、UDP等协议格式都是RFC系列文档规定的;
(2)URL不是HTTP专属的,很多协议都可以使用URL;
(3)URL中某些部分是可以省略的,以在浏览器页面访问bilibili为例,抓包到的url如下:

① 其中服务器端口号就被省略了,在端口号被省略时,浏览器会提供默认端口,
对于http来说,默认端口是80;
对于https来说,默认是443,
即访问https://www.bilibili.com与访问https://www.bilibili.com:443是相同的;
② / 也是目录,只是非常简短,代表HTTP服务器的根目录,/管理的根目录可以是系统上的任何一个目录;
(可以理解为HTTP服务器是系统上的一个进程,委托这个服务器管理系统上的一个特定目录,这个目录里的资源都可以让外部进行访问)
2.3 HTTP方法
常用的HTTP方法如下:
| 方法 | 说明 |
| GET | 获取资源 |
| POST | 传输实体主体 |
| PUT | 传输文件 |
| HEAD | 获得报文首部 |
| DELETE | 删除文件 |
| OPTIONS | 询问支持的方法 |
| TRACE | 追踪路径 |
| CONNECT | 要求用隧道协议连接代理 |
| LINK | 建立和资源之间的联系 |
| UNLINE | 断开连接关系 |
注:(1)方法描述了这次请求的语义,即要进行的操作;
(2)GET方法最常用,其次是POST方法,其余方法使用频率都远小于这两中方法;
2.3.1 GET请求
1. 在浏览器地址栏里直接输入URL或点击收藏夹就会触发GET请求;
2. HTML中的link标签,script标签,img标签以及a标签等也会触发GET请求;
3. 通过JS也可以构造GET请求;
仍以访问网页版bilibili为例:
2.3.2 POST请求
1. 登录操作进行跳转时会涉及到POST;
2. 上传文件时也会使用到POST;
注:(1)POST的body部分的内容与格式都是程序员自行定义的;
2.3.3 GET与POST的区别
1.信息存放差异:
GET也可以给服务器传递一些信息,GET传递的信息一般都是放在query string,POST传递消息则是通过body;
2. 语义差异(数据流动方向差异):
GET请求一般用于从服务器获取数据,POST请求一般用于给服务器提交数据;
3. GET通常会被设计成幂等的,但POST则不要求幂等;
4. GET是可以被缓存的,POST一般不能被缓存;
注:① 以上区别只是习惯用法,GET也可以有body,POST也可以有query string,GET也可以给服务器提交数据,POST也可以从服务器获取数据等等;
② 其实GET和POST就没有本质区别,在大部分场景下彼此之间都可以彼此替代,但在使用习惯上会有差异;
③ 幂等可以理解为相同的输入得到的结果也是确定的;
④ 缓存即保存请求的结果,方便下次请求直接取缓存结果从而节省时间;
2.3.4 其他方法
(1)PUT和POST相似,只是具有幂等特性,一般用于更新;
(2)DELETE删除服务器指定资源;
(3)OPTIONS返回服务器所支持的请求方法;
(4)HEAD类似于GET,只不过响应体不返回,只返回响应头;
(5)TRACE回显服务器端收到的请求,测试的时候会使用到该方法;
2.4 请求报头header
header的整体格式是“键值对”结构,一行是一个键值对,这些键值对都是HTTP事先定义好,有特殊含义的。
常见的报头种类有:
2.4.1 Host:
Host表示服务器主机的地址和端口;
注:此处的地址和端口是用来描述最重要访问的目标,大概率与URL相同,但也有可能不同
2.4.2 Content-Length与Content-Type:
Content-Length:表示body中的数据长度;
Content-Type:表示请求的body中的数据格式;
常见选项:
1. Content-Type:application/json;charset=UTF-8,数据为json格式,body格式形如:
{"username":"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16
a861fa2bddfdcd15"}2.Content-Type:application/x-www-form-urlencoded;charset=UTF-8,form标签构造的body格式就是该种类型,body格式如下:
title=test&content=hello注:如果是GET请求,没有body,则请求中没有以上两个字段;
如果是POST请求,有body,则请求中必须有该两个字段;
2.4.3 User-Agent(简称UA)
1. 表示用户浏览器或操作系统的版本(属性);
2. 如今的UA主要用于区分PC和移动;
2.4.4 Referer
1. 表示当前页面的来源,即当前页面是由哪个页面跳转过来的;
2. 不一定有,如果是直接通过地址栏输入地址,或者直接点击收藏夹等进行访问,就没有Referer;
2.4.5 Cookie
1. Cookie本质是浏览器给网页提供的本地存储数据的机制;
为了保证安全,网页默认是不允许访问计算机硬盘的。
Cookie即对浏览器访问硬盘做出了明确的限制;
2. Cookie是通过键值对方式组织数据的,故而也可以使用Cookie存储少量数据;
3. Cookie中具体存储的内容是程序员自定义的部分;
4. Cookie中的数据来自于服务器,服务器会通过HTTP响应的报头部分(Set-Cookie字段)。
即服务器决定浏览器的Cookie要存什么;
5. Cookie可以认为是存在于浏览器中的,本质上是存在于硬盘上;
Cookie在存储的时候,是按照浏览器+域名 的维度来进行细分的,即不同的浏览器存各自的Cookie,同一个浏览器不同的域名也对应着不同的Cookie;
Cookie中的内容不只有键值对,还有过期时间,过期则删除,比如一些网站,在第一次登录之后,定期自动记录登录状态,若超过其设定的过期时间,则删除;
6. Cookie最终要回到服务器:
同一时刻存在很多客户端,客户端会通过Cookie来保存客户使用的中间状态,当客户端访问浏览器时,就会自动把Cookie内容带入到请求中,服务器就可以获取到当前客户端的状态了;
2.5 请求正文body
正文中的内容格式和header中的Content-Type密切相关,常见的正文类型有:
(1)application/x-www.form-urencoded:类似于query string的键值对组织方式;
(2)multipart/form-data;
(3)application/json:最为常见的数据格式;
3. HTTP响应
响应也是由四个部分构成的:
3.1 响应首行
响应首行:版本号+状态码+状态码描述;
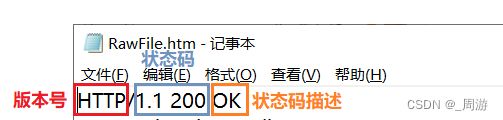
HTTP状态码描述了这次响应的结果(比如成功、失败,以及失败原因等);
1. HTTP状态码有:

(来源:搜狗百科)
2. 常见HTTP状态码有:
(1)200 OK, 表示访问成功:

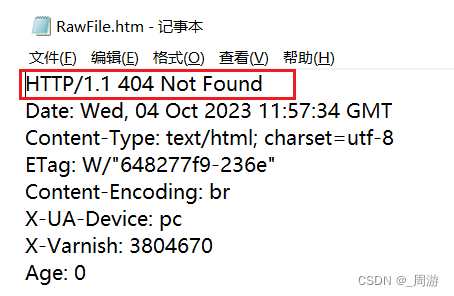
(2)404 Not Found, 表示访问的资源不存在,在服务器上查询无果:
如访问:

页面显示:
也可在fiddler中查看:
(3)403 Forbidden:无访问权限,访问被拒绝:
(4)302 Move temporarily:重定向:
重定向类似于呼叫转移,在登录页面302非常常见,用于实现登陆成功后自动跳转到主页;
302这样的响应报文中会在header中带有一个Location属性,通过这个属性来描述要跳转到哪个新的地址;
注:注意区别重定向与请求转发:

① 请求转发是servlet/spring里提供的机制;重定向是HTTP里提供的机制;
② 请求转发只能在该服务器内部的资源之间转发,重定向可以重定向到外部资源,即可跳转到别的网站;
③ 请求转发只有一次交互,更高效;重定向需要进行两次交互;
(5)500系列:服务器内部错误,
如:504 gateway timeout:请求超时等等;
注:gateway即网关,是一个网络的出入口,通常也用来指代一个机房的入口服务器,192.168.1.1这种ip一般是网关ip;
可总结如下:
| 类别 | 原因短语 | |
| 1XX | Informational(信息性状态码) | 接受的请求正常处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
注:HTTP状态码是RFC标准明确规定的,不允许自定义;
3.2 报头header
HTTP响应的报头也是键值对格式
3.3 空行
与HTTP请求相同,空行是header的结束标记;
3.4 正文body
HTML的页面内容;
HTTP请求与响应总结如下: