hive 修改cluster by算法_Hive入门实战(二)DDL数据定义
一、数据仓库--DDL数据定义
1、创建数据库
(1)创建一个数据库,数据库在HDFS上的默认存储路径是/user/hive/warehouse/*.db。
hive (default)> create database db_hive;
OK
Time taken: 0.123 seconds
hive (default)> 
(2)创建数据表
hive (default)> create table db_hive.test(id int);
OK
Time taken: 0.18 seconds
hive (default)> 刷新后:

若不想创建数据库放在默认的路径的话,想指定别的目录我们可以这样操作
hive (default)> create database db_hive1 location '/db_hive1.db';
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: hdfs://hadoop101:9000./db_hive1.db)
hive (default)>
//注意:若已经存在的数据文件,将会创建失败,如上。
//正确创建
hive (default)> create database db_hive1 location '/db_hive1.db';
OK
Time taken: 0.067 seconds
(3)创建数据库db_hive1的表
hive (default)> create table db_hive1.test(id int);
OK
Time taken: 0.268 seconds
hive (default)> 
2、查询数据库
(1)显示数据库
hive (default)> show databases;
OK
database_name
db_hive
db_hive1
default
Time taken: 0.111 seconds, Fetched: 3 row(s)
hive (default)>
// 创建数据库的另一种写法:
//不存在才创建数据库,只需要在sql语句添加if not exists的判断
hive (default)> create database if not exists db_hive;
OK
Time taken: 0.125 seconds
hive (default)>
//过滤显示查询的数据库
hive (default)> show databases like 'db_hive*';
OK
database_name
db_hive
db_hive1
Time taken: 0.073 seconds, Fetched: 2 row(s)
hive (default)>
//查看数据库详情信息
hive (default)> desc database db_hive;
OK
db_name comment location owner_name owner_type parameters
db_hive hdfs://hadoop101:9000/user/hive/warehouse/db_hive.db root USER
Time taken: 0.058 seconds, Fetched: 1 row(s)
hive (default)>
//显示数据库详细信息,extended
hive (default)> desc database extended db_hive;
OK
db_name comment location owner_name owner_type parameters
db_hive hdfs://hadoop101:9000/user/hive/warehouse/db_hive.db root USER
Time taken: 0.035 seconds, Fetched: 1 row(s)
hive (default)>
以上,由于显示数据库信息与显示数据库详细信息,查询出来的数据是相同,是因为没有添加额外信息
//切换当前数据库
hive (default)> use db_hive;3、修改数据库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息。数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。
//改数据库(增加了属性)
hive (default)> alter database db_hive set dbproperties('createtime'='20170830');
OK
Time taken: 0.162 seconds
hive (default)>
//在hive中查看修改结果
hive (default)> desc database extended db_hive;
OK
db_name comment location owner_name owner_type parameters
db_hive hdfs://hadoop101:9000/user/hive/warehouse/db_hive.db root USER {createtime=20170830}
Time taken: 0.051 seconds, Fetched: 1 row(s)
hive (default)> 4、删除数据库
//删除空数据库
hive (default)> drop database db_hive1;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database db_hive1 is not empty. One or more tables exist.)
以上:报错提示,说明数据库里面没有数据才报错
注意:只要数据库里面没有数据表,当删除都会报错
//可以采用cascade命令,强制删除(级联删除)
hive (default)> drop database db_hive cascade;
OK
Time taken: 0.881 seconds
hive (default)>
//如果删除的数据库不存在,最好采用 if exists判断数据库是否存在,不然将会报错
hive (default)> drop database if exists db_hive;
OK
Time taken: 0.02 seconds
hive (default)> 5、创建表
(1)建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path](2)字段解释说明
(1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
(2)EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释。===
(4)PARTITIONED BY创建分区表
(5)CLUSTERED BY创建分桶表
(6)SORTED BY不常用
(7)ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, …)]
用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化。
(8)STORED AS指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
(9)LOCATION :指定表在HDFS上的存储位置。
(10)LIKE允许用户复制现有的表结构,但是不复制数据。
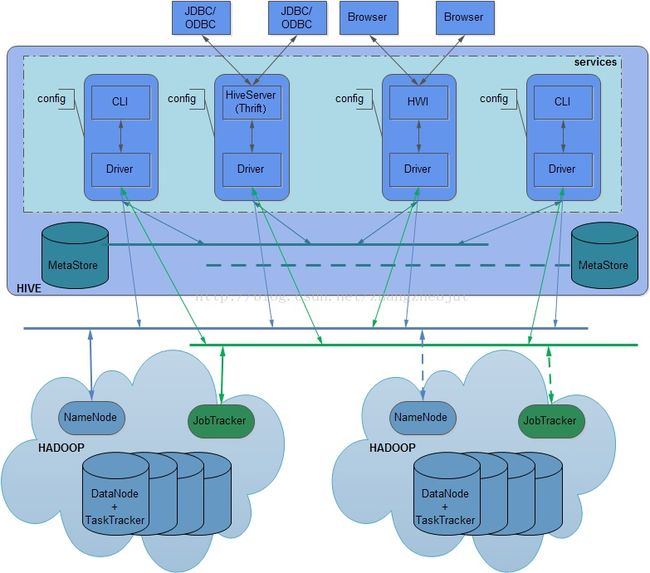
6、HiveJDBC访问
(1)开启JDBC服务
//首先,执行启动hiveserver2 服务
[root@hadoop101 module]# cd hive-1.2.1/bin/
[root@hadoop101 bin]# ./hiveserver2
//接着,再开另一个窗口,开启beeline 服务
[root@hadoop101 ~]# cd /usr/local/hadoop/module/hive-1.2.1/bin/
[root@hadoop101 bin]# ./beeline
beeline>
//beeline 的帮助命令
beeline> help
!addlocaldriverjar Add driver jar file in the beeline client side.
!addlocaldrivername Add driver name that needs to be supported in the beeline
client side.
!all Execute the specified SQL against all the current connections
!autocommit Set autocommit mode on or off
!batch Start or execute a batch of statements
!brief Set verbose mode off
!call Execute a callable statement
!close Close the current connection to the database
!closeall Close all current open connections
!columns List all the columns for the specified table
!commit Commit the current transaction (if autocommit is off)
!connect Open a new connection to the database.
!dbinfo Give metadata information about the database
!describe Describe a table
!dropall Drop all tables in the current database
!exportedkeys List all the exported keys for the specified table
!go Select the current connection
!help Print a summary of command usage
!history Display the command history
!importedkeys List all the imported keys for the specified table
!indexes List all the indexes for the specified table
!isolation Set the transaction isolation for this connection
!list List the current connections
!manual Display the BeeLine manual
!metadata Obtain metadata information
!nativesql Show the native SQL for the specified statement
!nullemptystring Set to true to get historic behavior of printing null as
empty string. Default is false.
!outputformat Set the output format for displaying results
(table,vertical,csv2,dsv,tsv2,xmlattrs,xmlelements, and
deprecated formats(csv, tsv))
!primarykeys List all the primary keys for the specified table
!procedures List all the procedures
!properties Connect to the database specified in the properties file(s)
!quit Exits the program
!reconnect Reconnect to the database
!record Record all output to the specified file
!rehash Fetch table and column names for command completion
!rollback Roll back the current transaction (if autocommit is off)
!run Run a script from the specified file
!save Save the current variabes and aliases
!scan Scan for installed JDBC drivers
!script Start saving a script to a file
!set Set a beeline variable
!sh Execute a shell command
!sql Execute a SQL command
!tables List all the tables in the database
!typeinfo Display the type map for the current connection
!verbose Set verbose mode on
Comments, bug reports, and patches go to ???
beeline>
//使用beeline连接jdbc
beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000: root
Enter password for jdbc:hive2://localhost:10000:
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000>
//连接beeline的jdbc之后,显示jdbc当前的数据库
0: jdbc:hive2://localhost:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| db_hive1 |
| default |
+----------------+--+
2 rows selected (2.181 seconds)
0: jdbc:hive2://localhost:10000>
//使用default的数据库,显示当前数据库的表
0: jdbc:hive2://localhost:10000> use default;
No rows affected (0.125 seconds)
0: jdbc:hive2://localhost:10000> show tables;
+-------------+--+
| tab_name |
+-------------+--+
| db_hive1 |
| hive_test |
| sqoop_test |
| student |
| test |
+-------------+--+
5 rows selected (0.11 seconds)
0: jdbc:hive2://localhost:10000>
//查询student表
0: jdbc:hive2://localhost:10000> select * from student;
+-------------+---------------+--------------+--+
| student.id | student.name | student.age |
+-------------+---------------+--------------+--+
| 1001 | zhangshan | NULL |
| 1002 | lishi | NULL |
| 1003 | zhaoliu | NULL |
+-------------+---------------+--------------+--+
3 rows selected (1.74 seconds)
0: jdbc:hive2://localhost:10000>
//之后,会发现进程hiveserver2服务报错信息
FAILED: ParseException line 1:10 mismatched input '' expecting EXTENDED near 'table' in show statement 解决问题:关闭服务,重新连接hiveserver2服务
注意的是:当重新连接hiveserver2服务,beeline 服务也需要关闭重新连接,重新操作!
7、数据定义–内部表(管理表)
(1)理论
默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive会(或多或少地)控制着数据的生命周期。Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。 当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
(2)操作步骤
//首先,显示当前所有数据
hive (default)> show tables;
OK
tab_name
db_hive1
hive_test
sqoop_test
student
test
Time taken: 0.163 seconds, Fetched: 5 row(s)
hive (default)>
//查询test表数据
hive (default)> select * from test;
OK
test.name test.friends test.children test.address
songsong ["bingbing","lili"] {"xiao song":18,"xiaoxiao song":19} {"street":"hui long guan","city":"beijing"}
yangyang ["caicai","susu"] {"xiao yang":18,"xiaoxiao yang":19} {"street":"chao yang","city":"beijing"}
Time taken: 0.255 seconds, Fetched: 2 row(s)
hive (default)>
//删除test表
hive (default)> drop table test;
OK
Time taken: 0.837 seconds
hive (default)>
//再查询当前所有数据
hive (default)> show tables;
OK
tab_name
db_hive1
hive_test
sqoop_test
student
Time taken: 0.037 seconds, Fetched: 4 row(s)
hive (default)>
说明test表数据没有了,同时HDFS分布式文件的test也会没有的
当然,我们也可以使用另一种方式创建表,同时也将会把数据给复制过来的,执行如下:
hive (default)> create table student1 as select * from student;
Query ID = root_20191231013137_74305e99-4485-4f32-95e4-a75ecaee3de9
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1577715694305_0001, Tracking URL = http://hadoop101:8088/proxy/application_1577715694305_0001/
Kill Command = /usr/local/hadoop/module/hadoop-2.7.2/bin/hadoop job -kill job_1577715694305_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2019-12-31 01:32:08,597 Stage-1 map = 0%, reduce = 0%
2019-12-31 01:32:21,388 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.48 sec
MapReduce Total cumulative CPU time: 1 seconds 480 msec
Ended Job = job_1577715694305_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://hadoop101:9000/user/hive/warehouse/.hive-staging_hive_2019-12-31_01-31-37_390_2456736349393130958-1/-ext-10001
Moving data to: hdfs://hadoop101:9000/user/hive/warehouse/student1
Table default.student1 stats: [numFiles=1, numRows=3, totalSize=48, rawDataSize=45]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.48 sec HDFS Read: 2895 HDFS Write: 120 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 480 msec
OK
student.id student.name student.age
Time taken: 47.631 seconds
hive (default)>
//此时,我们对student1数据表进行查询
hive (default)> select * from student1;
OK
student1.id student1.name student1.age
1001 zhangshan NULL
1002 lishi NULL
1003 zhaoliu NULL
Time taken: 0.183 seconds, Fetched: 3 row(s)
hive (default)> 方式二:创建表(只有表数据,没有表结构)
//创建,执行命令:
hive (default)> create table student2 like student;
OK
Time taken: 0.23 seconds
hive (default)>
hive (default)> show tables;
OK
tab_name
db_hive1
hive_test
sqoop_test
student
student1
student2
Time taken: 0.045 seconds, Fetched: 6 row(s)
hive (default)>
//只有表数据,没有表结构,执行命令如下:
hive (default)> desc student;
OK
col_name data_type comment
id int
name string
age int
Time taken: 0.179 seconds, Fetched: 3 row(s)
hive (default)>
//查看表信息
hive (default)> desc extended student;
OK
col_name data_type comment
id int
name string
age int
Detailed Table Information Table(tableName:student, dbName:default, owner:root, createTime:1577672971, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:name, type:string, comment:null), FieldSchema(name:age, type:int, comment:null)], location:hdfs://hadoop101:9000/user/hive/warehouse/student, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{field.delim= , serialization.format=
Time taken: 0.133 seconds, Fetched: 5 row(s)
hive (default)>
//查看表的初始化信息
hive (default)> desc formatted student;
OK
col_name data_type comment
# col_name data_type comment
id int
name string
age int
# Detailed Table Information
Database: default
Owner: root
CreateTime: Mon Dec 30 02:29:31 GMT 2019
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop101:9000/user/hive/warehouse/student
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE false
numFiles 1
numRows -1
rawDataSize -1
totalSize 39
transient_lastDdlTime 1577672971
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim t
serialization.format t
Time taken: 0.182 seconds, Fetched: 34 row(s)
hive (default)> 8、数据定义–外部表
(1)理论
因为表是外部表,所以Hive并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
(2)管理表和外部表的使用场景
每天将收集到的网站日志定期流入HDFS文本文件。在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过SELECT+INSERT进入内部表。
(3)案例实操
分别创建部门和员工外部表,并向表中导入数据
步骤:
先进入 /usr/local/hadoop/module/datas目录下创建一个dept文本
[root@hadoop101 datas]# cd /usr/local/hadoop/module/datas/
[root@hadoop101 datas]# vim dept.txt
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700创建部门表,执行命令如下
hive (default)> create external table if not exists default.dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by 't';
OK
Time taken: 0.123 seconds
hive (default)> 进入 /usr/local/hadoop/module/datas目录下创建一个emp文本,创建员工表
[root@hadoop101 datas]# cd /usr/local/hadoop/module/datas/
[root@hadoop101 datas]# vim emp.txt
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10创建员工表,执行命令如下
hive (default)> create external table if not exists default.emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by 't';
OK
Time taken: 0.171 seconds
hive (default)> 查看创建的表
hive (default)> show tables;
OK
tab_name
db_hive1
dept
emp
hive_test
sqoop_test
student
student1
student2
Time taken: 0.037 seconds, Fetched: 8 row(s)
hive (default)> 向外部表中导入数据,执行命令如下:
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/dept.txt' into table default.dept;
Loading data to table default.dept
Table default.dept stats: [numFiles=1, totalSize=69]
OK
Time taken: 0.724 seconds
hive (default)>
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/emp.txt' into table default.emp;
Loading data to table default.emp
Table default.emp stats: [numFiles=1, totalSize=657]
OK
Time taken: 0.417 seconds
hive (default)> 查询表emp、dept
hive (default)> select * from emp;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
Time taken: 0.144 seconds, Fetched: 14 row(s)
hive (default)>
hive (default)> select * from dept;
OK
dept.deptno dept.dname dept.loc
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
Time taken: 0.075 seconds, Fetched: 4 row(s)
hive (default)> 在分布式文件系统HDFS也可以查看到

需要删除部门表emp,执行命令如下:
hive (default)> show tables;
OK
tab_name
db_hive1
dept
emp
hive_test
sqoop_test
student
student1
student2
Time taken: 0.069 seconds, Fetched: 8 row(s)
hive (default)> drop table emp;
OK
Time taken: 0.196 seconds
hive (default)> show tables;
OK
tab_name
db_hive1
dept
hive_test
sqoop_test
student
student1
student2
Time taken: 0.036 seconds, Fetched: 7 row(s)
hive (default)> 由上得知emp表已经删除了,这是内部表已经删除,我们再去看看外部表(分布式文件系统HDFS查看)

这样做的好处:
- 当内部表的数据被删除,儿外部表的数据还是会被保留不会被删除;
- 当我们想要恢复内部表被删除的数据,只需要执行该表的sql命令即可:
hive (default)> create external table if not exists default.emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by 't';
OK
Time taken: 0.215 seconds
hive (default)> select * from emp;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
Time taken: 0.102 seconds, Fetched: 14 row(s)
hive (default)> 查看表格式化数据
hive (default)> desc formatted dept;
OK
col_name data_type comment
# col_name data_type comment
deptno int
dname string
loc int
# Detailed Table Information
Database: default
Owner: root
CreateTime: Tue Dec 31 02:01:51 GMT 2019
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop101:9000/user/hive/warehouse/dept
Table Type: EXTERNAL_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE true
EXTERNAL TRUE
numFiles 1
totalSize 69
transient_lastDdlTime 1577760554
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim t
serialization.format t
Time taken: 1.611 seconds, Fetched: 33 row(s)
hive (default)> 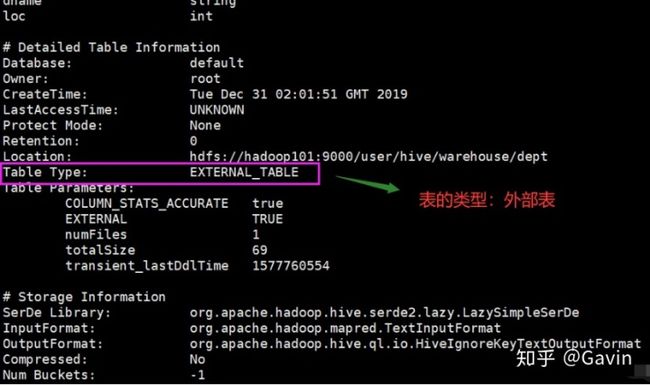
9、管理表与外部表的互相转换
(1)查询表的类型
hive (default)> desc formatted student2;
Table Type: MANAGED_TABLE
hive (default)> (2)修改内部表student2为 EXTERNAL_TABLE
alter table student2 set tblproperties('EXTERNAL'='TRUE');
OK
Time taken: 0.27 seconds
hive (default)> (3)查询表的类型(EXTERNAL_TABLE:外部表)
hive (default)> desc formatted student2;
Table Type: EXTERNAL_TABLE(4)修改外部表student2为内部表
alter table student2 set tblproperties('EXTERNAL'='FALSE');
OK
Time taken: 0.27 seconds
hive (default)> (5)查询表的类型(MANAGED_TABLE :内部表)
hive (default)> desc formatted student2;
Table Type: MANAGED_TABLE 10、分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
分区表基本操作
(1)创建一个分区表(按月分区)
hive (default)> create table stu_partition(id int,name string)
> partitioned by(month string)
> row format delimited fields terminated by 't';
OK
Time taken: 0.449 seconds
hive (default)> (2)查看当前的数据表
hive (default)> show tables;
OK
tab_name
db_hive1
dept
emp
hive_test
sqoop_test
stu_partition
student
student1
student2
Time taken: 0.046 seconds, Fetched: 9 row(s)
hive (default)> 虽然在内部表创建成功,而在外部表HDFS文件系统查看stu_partition数据库的是空表
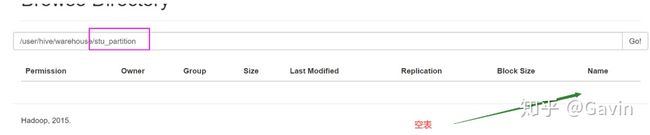
我们需要在分区表里面加载一些数据
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/student.txt' into table stu_partition;
FAILED: SemanticException [Error 10062]: Need to specify partition columns because the destination table is partitioned
hive (default)> 从上面提示错误:由于是分区表,需要指定分区的地方,本身在创建这个分区表都已经被分区了!
正确写法:
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/student.txt' into table stu_partition partition(month="20200623") ;
Loading data to table default.stu_partition partition (month=20200623)
Partition default.stu_partition{month=20200623} stats: [numFiles=1, numRows=0, totalSize=39, rawDataSize=0]
OK
Time taken: 2.211 seconds
hive (default)> 我们可以在外部表HDFS文件系统查看stu_partition数据库的表已经有分区的数据了

查询一下,分区的数据(查询这个分区表还是会进行全表扫描)
hive (default)> select * from stu_partition;
OK
stu_partition.id stu_partition.name stu_partition.month
1001 zhangshan 20200623
1002 lishi 20200623
1003 zhaoliu 20200623
Time taken: 0.729 seconds, Fetched: 3 row(s)
hive (default)> 分区表的结构
hive (default)> select * from stu_partition;
OK
stu_partition.id stu_partition.name stu_partition.month
1001 zhangshan 20200623
1002 lishi 20200623
1003 zhaoliu 20200623
Time taken: 0.189 seconds, Fetched: 3 row(s)
hive (default)> 
当然,也可以创建分区表的:20200624、20200625**,外部表HDFS文件系统就会生成三个文件夹
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/student.txt' into table stu_partition partition(month="20200624") ;
Loading data to table default.stu_partition partition (month=20200624)
Partition default.stu_partition{month=20200624} stats: [numFiles=1, numRows=0, totalSize=39, rawDataSize=0]
OK
Time taken: 0.68 seconds
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/student.txt' into table stu_partition partition(month="20200625") ;
Loading data to table default.stu_partition partition (month=20200625)
Partition default.stu_partition{month=20200625} stats: [numFiles=1, numRows=0, totalSize=39, rawDataSize=0]
OK
Time taken: 0.627 seconds
hive (default)> 
这三个文件夹都将会同时有数据
我们可以在内部表查询测试一下(这个数据将会有三份)
hive (default)> select * from stu_partition;
OK
stu_partition.id stu_partition.name stu_partition.month
1001 zhangshan 20200623
1002 lishi 20200623
1003 zhaoliu 20200623
1001 zhangshan 20200624
1002 lishi 20200624
1003 zhaoliu 20200624
1001 zhangshan 20200625
1002 lishi 20200625
1003 zhaoliu 20200625
Time taken: 0.162 seconds, Fetched: 9 row(s)
hive (default)> 我们也可以按条件查询一个分区表的数据,执行sql命令:
hive (default)> select * from stu_partition where month=20200625 ;
OK
stu_partition.id stu_partition.name stu_partition.month
1001 zhangshan 20200625
1002 lishi 20200625
1003 zhaoliu 20200625
Time taken: 0.6 seconds, Fetched: 3 row(s)
hive (default)> 如果查询二个或多个分区表的数据,执行sql命令(这种写法会将数据排序):
缺点:加载比较慢
hive (default)> select * from stu_partition where month=20200625
> union
> select * from stu_partition where month=20200624;
Query ID = root_20191231153625_7a2ed346-e390-41ae-bb47-83cd31b986e3
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1577801392917_0001, Tracking URL = http://hadoop101:8088/proxy/application_1577801392917_0001/
Kill Command = /usr/local/hadoop/module/hadoop-2.7.2/bin/hadoop job -kill job_1577801392917_0001
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 1
2019-12-31 15:36:49,805 Stage-1 map = 0%, reduce = 0%
2019-12-31 15:37:11,282 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.26 sec
2019-12-31 15:37:22,462 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.76 sec
MapReduce Total cumulative CPU time: 5 seconds 760 msec
Ended Job = job_1577801392917_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 5.76 sec HDFS Read: 14645 HDFS Write: 132 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 760 msec
OK
_u2.id _u2.name _u2.month
1001 zhangshan 20200624
1001 zhangshan 20200625
1002 lishi 20200624
1002 lishi 20200625
1003 zhaoliu 20200624
1003 zhaoliu 20200625
Time taken: 58.974 seconds, Fetched: 6 row(s)
hive (default)> 还有另一种写法,也是创建分区表(单个分区)的:
hive (default)> alter table stu_partition add partition(month='20200626');
OK
Time taken: 0.293 seconds
hive (default)> HDFS文件系统就会生成一个month=20200626文件夹

同时创建多个分区
hive (default)> alter table stu_partition add partition(month='20200627') partition(month='20200628');
OK
Time taken: 0.25 seconds
hive (default)> HDFS文件系统就会生成2个文件夹

删除分区
//删除单个分区
hive (default)> alter table stu_partition drop partition (month='20200628');
Dropped the partition month=20200628
OK
Time taken: 0.732 seconds
hive (default)> 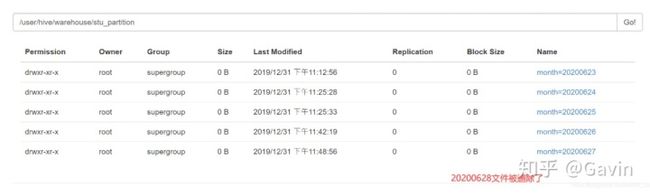
//同时删除多个分区
hive (default)> alter table stu_partition drop partition (month='20200627'), partition (month='20200626');
Dropped the partition month=20200626
Dropped the partition month=20200627
OK
Time taken: 0.331 seconds
hive (default)> 
查看分区表
//查看分区表有多少分区
hive (default)> show partitions stu_partition;
OK
partition
month=20200623
month=20200624
month=20200625
Time taken: 0.162 seconds, Fetched: 3 row(s)
hive (default)>
//查看分区表结构
hive (default)> show partitions stu_partition;
OK
partition
month=20200623
month=20200624
month=20200625
Time taken: 0.162 seconds, Fetched: 3 row(s)
hive (default)> desc formatted stu_partition;
OK
col_name data_type comment
# col_name data_type comment
id int
name string
# Partition Information
# col_name data_type comment
month string
# Detailed Table Information
Database: default
Owner: root
CreateTime: Tue Dec 31 14:55:48 GMT 2019
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop101:9000/user/hive/warehouse/stu_partition
Table Type: MANAGED_TABLE
Table Parameters:
transient_lastDdlTime 1577804148
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim t
serialization.format t
Time taken: 0.107 seconds, Fetched: 33 row(s)
hive (default)> 11、分区表注意事项
(1)创建二级分区表
hive (default)> create table stu2(id int,name string)
> partitioned by (month string, day string)
> row format delimited fields terminated by 't';
OK
Time taken: 0.429 seconds
hive (default)> (2)正常的加载数据
//加载数据到二级分区表中
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/student.txt'
> into table stu2
> partition(month='202006', day='23');
Loading data to table default.stu2 partition (month=202006, day=23)
Partition default.stu2{month=202006, day=23} stats: [numFiles=1, numRows=0, totalSize=39, rawDataSize=0]
OK
Time taken: 1.568 seconds
hive (default)>
//查询二级分区数据
hive (default)> select * from stu2;
OK
stu2.id stu2.name stu2.month stu2.day
1001 zhangshan 202006 23
1002 lishi 202006 23
1003 zhaoliu 202006 23
Time taken: 0.446 seconds, Fetched: 3 row(s)
hive (default)> 在HDFS查看二级分区

//查询分区数据
hive (default)> select * from dept_partition2 where month='202006' and day='23';
OK
dept_partition2.deptno dept_partition2.dname dept_partition2.loc dept_partition2.month dept_partition2.day
Time taken: 0.439 seconds
hive (default)> 12、分区表与数据关联的三种方式
方式一:上传数据后修复
(1)上传数据在HDFS的文件目录,
例如:把/usr/local/hadoop/module/datas/student.txt数据信息上传到HDFS文件系统的文件夹上:

执行命令如下:
hive (default)> dfs -put /usr/local/hadoop/module/datas/student.txt /user/hive/warehouse/stu2/month=202006;
hive (default)> 
当我们在内部表查询,发现查询数据
hive (default)> select * from stu2 where month=202006 and day=23;
OK
stu2.id stu2.name stu2.month stu2.day
1001 zhangshan 202006 23
1002 lishi 202006 23
1003 zhaoliu 202006 23
Time taken: 0.169 seconds, Fetched: 3 row(s)
hive (default)> 假如查询不到数据,我们可以:执行修复命令
hive (default)> msck repair table stu2;
OK
Time taken: 0.131 seconds
hive (default)> 自己的可以查询的到,所以忽略过了!
方式二:上传数据后添加分区
(1) 在HDFS文件系统的/user/hive/warehouse/stu_partition路径下,创建一个month=20200626文件夹,执行命令如下:
hive (default)> dfs -mkdir -p /user/hive/warehouse/stu_partition/month=20200626;
hive (default)> 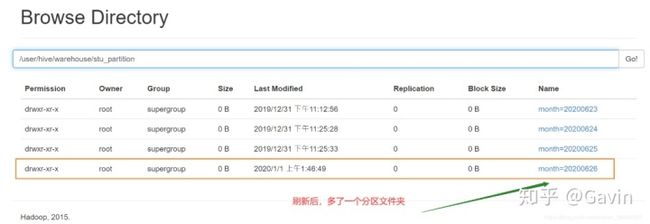
把本地数据/usr/local/hadoop/module/datas/student.txt上传到HDFS文件系统的/user/hive/warehouse/stu_partition/month=20200626路径下,执行命令如下:
hive (default)> dfs -put /usr/local/hadoop/module/datas/student.txt /user/hive/warehouse/stu_partition/month=20200626;
hive (default)> 
//执行添加分区
hive (default)> alter table stu_partition add partition(month='20200626');
OK
Time taken: 0.177 seconds
hive (default)>
//查询数据
hive (default)> select * from stu_partition where month=20200626;
OK
stu_partition.id stu_partition.name stu_partition.month
1001 zhangshan 20200626
1002 lishi 20200626
1003 zhaoliu 20200626
Time taken: 0.157 seconds, Fetched: 3 row(s)
hive (default)> 方式三:创建文件夹后load数据到分区
//创建目录
hive (default)> dfs -mkdir -p /user/hive/warehouse/db_hive1/kiss;
上传数据
//上传数据
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table
dept_partition2 partition(month='201709',day='10');
//查询数据
hive (default)> select * from dept_partition2 where month='201709' and day='10';13、修改表
(1)重命名表
//语法
操作步骤:
//查看当前数据表
由上述得知,该数据student2表已经不存在,却多了student3表,由此可见该表修改成功
同时,当内部表修改成功之后,外部表HDFS文件系统的文件名f也将会发生改变!

(2)增加/修改/替换列信息
语法
//更新列
操作步骤
//更改字段名的命令
由上面得知,增加表的字段成功!
(3)添加表的字段(一个)
hive 由上可得知,多了一个desc字段列,说明添加成功!
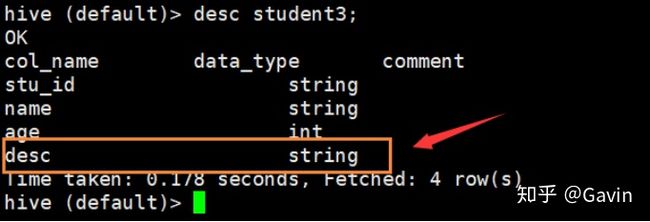
我们再查看student3数据表,可以看到表字段
hive 当然,我们也可替换(replace)数据表的字段
hive 再查看student3数据表结构,可以看到表字段的变化
hive