航空公司客户价值分析
1 目的
对历史客户数据进行分析,区分客户的类型,以便对客户提供更适合的服务。
2 数据探索
查看数据整体情况
import pandas as pd
path = r'C:\Users\Liang\Desktop\Python_shujufenxiyuwajueshizhan\chapter7\demo\data\air_data.csv'
data = pd.read_csv(path, encoding='utf-8')
explore = data.describe(percentiles=[], include='all').T
explore
 把空值、最大值、最小值提取出来,方便查看
把空值、最大值、最小值提取出来,方便查看
explore['null'] = len(data) - explore['count']
explore = explore[['null', 'max', 'min']]
explore
3 数据预处理
丢弃 ‘SUM_YR_1’ 和 ‘SUM_YR_2’ 的空值
# data[data['SUM_YR_1'].notnull()*data['SUM_YR_2'].notnull()] 两中用法结果一样
data = data[data['SUM_YR_1'].notnull()][data['SUM_YR_2'].notnull()]
数据清洗,对符合要求的特征进行提取
index1 = data['SUM_YR_1'] != 0
index2 = data['SUM_YR_2'] != 0
index3 = (data['SEG_KM_SUM'] == 0) & (data['avg_discount'] == 0)
data = data[index1 | index2 | index3]
处理时间序列,求出开通会员的时间和观测窗口结束时间之间的时长,并转化为以月为单位。
import numpy as np
L = pd.to_datetime(filter_data['LOAD_TIME']) - pd.to_datetime(filter_data['FFP_DATE'])
# L
L = L.astype(np.int64)/(60*60*24*10**9)/30
L.describe()
count 62044.000000
mean 49.623036
std 28.262697
min 12.166667
25% 24.500000
50% 42.600000
75% 72.733333
max 114.566667
dtype: float64
4 特征工程
要构建LRFMC模型,来评估客户,进行特征选择
# L在上一步已经提取了
R = data['LAST_TO_END'] / 30
R
F = data['FLIGHT_COUNT']
F
M = data['SEG_KM_SUM']
M.describe()
C = data['avg_discount']
C.describe()
合并上面的Series为一个DataFrame
df = pd.DataFrame(list(zip(L, R, F, M, C)),columns=['L', 'R', 'F', 'M', 'C'])
df.describe()
 对dataframe的数据进行标准化,可以使得聚类更加精确
对dataframe的数据进行标准化,可以使得聚类更加精确
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
mat = scaler.fit_transform(df)
_df = pd.DataFrame(mat, columns=['ZL', 'ZR', 'ZF', 'ZM', 'ZC'])
_df.head()

5 挖掘建模
此处要对客户进行聚类,但数据量是6万多个样本,5个维度,所以使用Mini Batch KMeans算法,来加快建模速度。
先来试试
from sklearn.cluster import MiniBatchKMeans
k = 5
km = MiniBatchKMeans(n_clusters=k)
km.fit(_df)
print(km.cluster_centers_)
print(km.labels_)
模型评估,调参,可视化
画出n_cluster的模型学习曲线,对应评估量为簇内平方和interia
import matplotlib.pyplot as plt
interias = list()
for i in range(3, 9):
km = MiniBatchKMeans(n_clusters=i)
km.fit(_df)
inertia = km.inertia_
interias.append(inertia)
plt.plot(list(range(3, 9)), interias)
plt.xticks(list(range(3, 9)))
plt.xlabel('n_cluster')
plt.ylabel('inertia')
plt.show()

可以明显的发现符合肘部法则,n_cluster=4是最优。
在看轮廓系数随着n_cluster的学习曲线
k = 5
km = MiniBatchKMeans(n_clusters=k)
km.fit(_df)
y_pred = km.labels_
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
silhouette_score(_df,y_pred)# 计算轮廓系数
import matplotlib.pyplot as plt
silhouette_list = []
for i in range(3, 9):
km = MiniBatchKMeans(n_clusters=i)
km.fit(_df)
y_pred = km.labels_
silhouette = silhouette_score(_df,y_pred)
silhouette_list.append(silhouette)
plt.plot(list(range(3, 9)), silhouette_list)
plt.xticks(list(range(3, 9)))
plt.xlabel('n_cluster')
plt.ylabel('silhouette')
plt.show()

轮廓系数是对簇内差异的大小和簇外差异大小的综合评估,越接近于1越好,此处n_cluster=4为最佳,所以确定了参数n_cluster就为4
看一下各个客户群体的数量分布
km = MiniBatchKMeans(n_clusters=4)
km.fit(_df)
km.cluster_centers_
y_pred = km.labels_
km.inertia_
km.n_iter_
r1 = pd.Series(km.labels_).value_counts()
r1
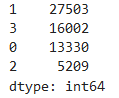
要对聚类后的结果进行评估,通常除了看评估的数学方法以外,还需要结合业务,下面就看一下那些被聚类好的各个客户群的各种特征的分布
把每个样本对应的客户群标签为一列合并到原表中
ff = _df.copy()
ff['label'] = y_pred
ff

对label进行分组处理,并获得最值和平均值
ff.groupby(by='label').max()
ff.groupby(by='label').mean()
使用echarts绘制雷达图,用jupyter lab配合echarts时要按照这个步骤来,不然无法显示图表。
from pyecharts.globals import CurrentConfig, NotebookType
from pyecharts import options as opts
from pyecharts.charts import Page, Radar
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
# 每一类的均值,要是二维的
v1 = [[*list(ff.groupby(by='label').mean().iloc[:,0])]]
v2 = [[*list(ff.groupby(by='label').mean().iloc[:,1])]]
v3 = [[*list(ff.groupby(by='label').mean().iloc[:,2])]]
v4 = [[*list(ff.groupby(by='label').mean().iloc[:,-1])]]
for i in range(4):
pass
schema = []
for feature in list(_df.columns):
mmax = max(list(ff.groupby(by='label')[feature].max()))/1.4
opt = opts.RadarIndicatorItem(name=feature, max_=mmax,min_=-3)
schema.append(opt)
radar = Radar()
radar.add_schema(schema=schema)
radar.add('客户群1', v1, color="blue", areastyle_opts=opts.AreaStyleOpts(0.5))
radar.add('客户群2', v2, color="green", areastyle_opts=opts.AreaStyleOpts(0.4))
radar.add('客户群3', v3, color="red", areastyle_opts=opts.AreaStyleOpts(0.3))
radar.add('客户群4', v4, color="yellow", areastyle_opts=opts.AreaStyleOpts(0.2))
radar.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
radar.set_global_opts(title_opts=opts.TitleOpts(title="客户群特征分布雷达图"))
radar.load_javascript()
radar.render_notebook()
 下面具体看一下客户评价模型LRFMC的各个维度的对比,使用原始数据
下面具体看一下客户评价模型LRFMC的各个维度的对比,使用原始数据
data['label'] = y_pred
data['L'] = (pd.to_datetime(data['LOAD_TIME']) - pd.to_datetime(data['FFP_DATE'])).astype(np.int64)/(60*60*24*10**9)/30
data['L']
对label进行分组,并绘制每个客户群对应的特征
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="whitegrid")
plt.rcParams['font.sans-serif'] = 'SimHei'
p = plt.figure(figsize=(20, 12))
ax1 = p.add_subplot(2, 3, 1)
ax2 = p.add_subplot(2, 3, 2)
ax4 = p.add_subplot(2, 3, 4)
ax5 = p.add_subplot(2, 3, 5)
ax6 = p.add_subplot(2, 3, 6)
groupby_obj = data.groupby(by='label')
R = groupby_obj.mean()['LAST_TO_END']
R
L = groupby_obj.mean()['L']
L
F = groupby_obj.mean()['FLIGHT_COUNT']
F
M = groupby_obj.mean()['SEG_KM_SUM']
M
C = groupby_obj.mean()['avg_discount']
C
sns.barplot(x=['客户群' + str(i) for i in list( + R.index + 1)], y=R.values, palette="rocket", ax=ax1)
ax1.set_ylabel('最近乘机距今的时间长度R')
sns.barplot(x=['客户群' + str(i) for i in list( + L.index + 1)], y=L.values, palette="vlag", ax=ax2)
ax2.set_ylabel('会员入会时间L')
sns.barplot(x=['客户群' + str(i) for i in list( + F.index + 1)], y=F.values, ax=ax4)
ax4.set_ylabel('飞行次数F')
sns.barplot(x=['客户群' + str(i) for i in list( + M.index + 1)], y=M.values, palette="deep", ax=ax5)
ax5.set_ylabel('总飞行里程M')
sns.barplot(x=['客户群' + str(i) for i in list( + C.index + 1)], y=C.values, ax=ax6)
ax6.set_ylabel('平均折扣系数C')
plt.show()
 通过5个维度分析得:
通过5个维度分析得:
客户群1 – 重要挽留用户
客户群2–重要发展用户
客户群3–重要保持用户
客户群4–重要发展
6 应用模型
结合后端框架Django搭建系统—待续