Hadoop 分布式集群搭建教程(2023在校生踩坑版)
博主本人,数据科学与大数据技术双非民办本科在读生,学的很差,配置Hadoop过程中,遇到了好多好多坑,Linux操作系统使用还是比较熟练的,所以大部分遇到的问题都是因为课本上的知识已经更新换代,网上找到的教程也杂乱无章,并且如果按照网上的教程来,课本后面几章的内容不兼容会出现更多的bug....为此我整理了这篇博客,希望可以帮助到跟博主同样情况的同学们。同时希望大家可以点赞关注收藏支持一下 T.T...
学校课本:Hadoop大数据处理实战上海交通大学出版社
根据学校课本的教程一步一步来,踩了巨多坑!Hadoop3.x版本往后更新换代了很多东西,而课本上并没有说明并且一直沿用的老版本,这让我在搭建Hadoop的过程中一步步踩坑,删除虚拟机重新配置了好多次!!!
本篇博客中用到的
jdk版本:1.8
Hadoop版本:3.3.6
zookeeper版本:3.9.0
如遇到包含以上文件名称的语句,请按照自己的版本号更改。
目录
一、创建虚拟机并安装CentOS7
①安装虚拟机软件
②下载CentOS7镜像文件
③创建新的虚拟机
1.在VMware主页点击创建新的虚拟机
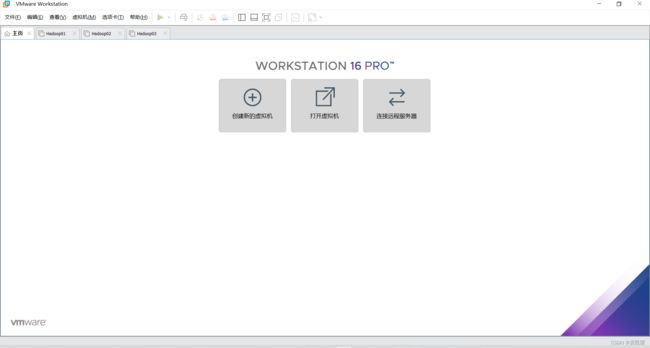
2.指定配置类型和硬件兼容性
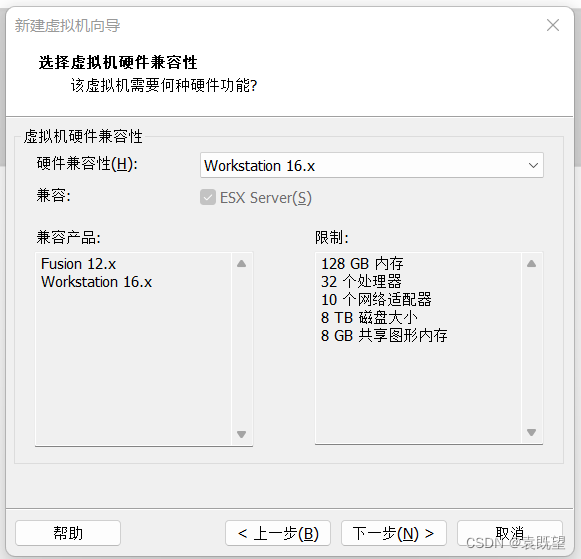
3.指定安装操作系统的镜像文件
4.指定虚拟机名称和安装位置
5.指定处理器配置和虚拟机的内存
6.指定网络类型和I/O控制器类型
7.指定磁盘类型、磁盘、磁盘容量和磁盘文件
8.虚拟机创建完成(尚未安装操作系统)
④安装CentOS7操作系统
1.开始安装CentOS7操作系统
2.选择系统语言
3.指定系统安装位置和系统软件选择
4.配置网络和主机名
5.正式开始安装
二、配置虚拟机集群环境
①修改主机名和设置固定IP
1.修改主机名
2.设置固定IP
3.修改网卡配置文件ifcfg-ens33
②关闭防火墙和新建安装目录
1.关闭防火墙
2.新建安装目录
③安装和配置JDK
1.下载
2.删除OpenJDk
3.上传JDK安装包
④克隆虚拟机和配置主机IP映射
1.克隆虚拟机
2.配置主机映射
3.配置各节点SSH免密码登录
三、搭建Hadoop高可用集群
①安装和配置Zookeeper
1.安装(与前面安装jdk方法一致)
2.复制到Hadoop02和Hadoop03
②安装与配置Hadoop
1.修改配置文件core-site.xml
2.修改配置文件hdfs-site.xml
3.修改配置文件mapred-site.xml
4.修改配置文件yarn-site.xml
5.修改配置文件slaves(Hadoop3.x之后版本均变更为workers)
6.修改配置文件hadoop-env.sh、mapred-env.sh和yarn-env.sh
7.复制到Hadoop02和Hadoop03
③启动与测试Hadoop
1.格式化NameNode
2.格式化ZKFC
3.启动HDFS和YARN
一、创建虚拟机并安装CentOS7
①安装虚拟机软件
这里的演示的版本是VMware16,下载地址:
VMware - Delivering a Digital Fou、ndation For Businesses
VMware是一家领先的虚拟化和云基础设施解决方案提供商。他们的软件产品被广泛用于构建和管理虚拟化环境,从而提供更高的灵活性、可靠性和效率。
②下载CentOS7镜像文件
1、官网下载地址
CentOS Mirrors List
2、清华大学下载地址
Index of /centos/7.9.2009/isos/x86_64/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror|
3、阿里下载地址
centos-7-isos-x86_64安装包下载_开源镜像站-阿里云 (aliyun.com)
这里推荐使用镜像站,官网速度非常慢,镜像站速度有近百倍的提升
③创建新的虚拟机
1.在VMware主页点击创建新的虚拟机
2.指定配置类型和硬件兼容性

3.指定安装操作系统的镜像文件
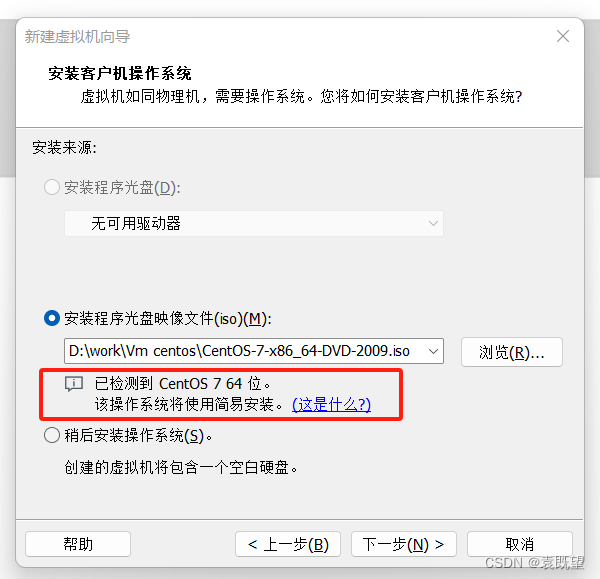
这里一定要注意!!!!!!!坑出现了!!!!!
如果出现以上语句:“该操作系统将使用简易安装”,则选择稍后安装操作系统!
否则后续就会直接跳过,可以参考博主的这篇文章:
CentOS7安装时直接跳过了安装信息摘要页面的解决方法-CSDN博客
4.指定虚拟机名称和安装位置
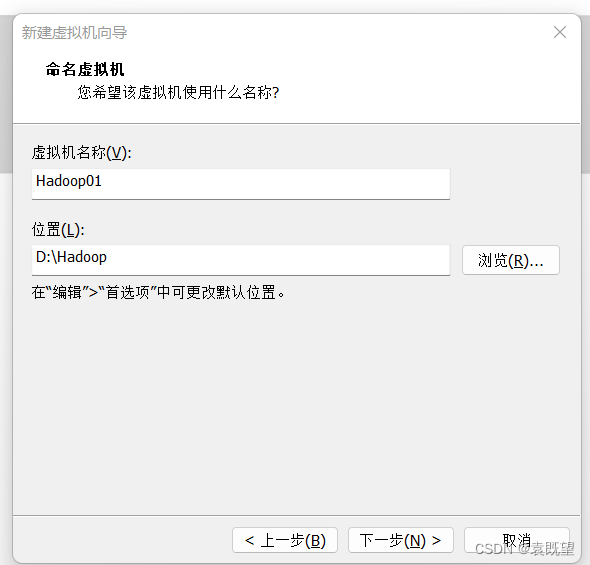
这里推荐改为Hadoop01,后续虚拟机名称依次排号02、03
5.指定处理器配置和虚拟机的内存
6.指定网络类型和I/O控制器类型
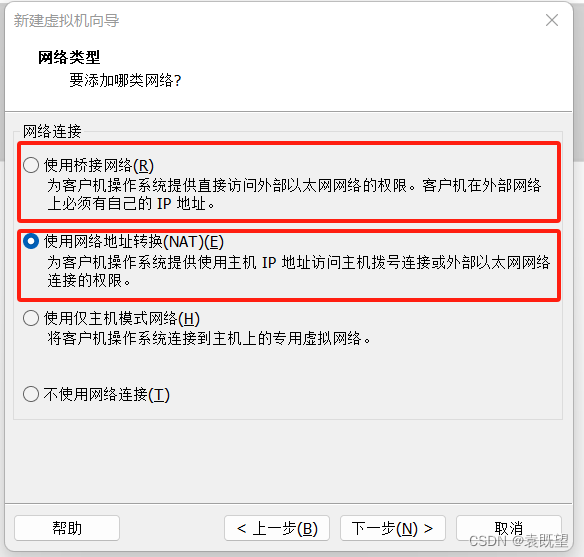
因为校园网的原因,这里博主使用的是NAT模式,桥接模式和NAT模式都是可以的,但是如果跟博主一样使用校园网等内网的话,推荐使用NAT模式。
桥接模式(Bridge Mode)和NAT模式(Network Address Translation Mode)是常用于虚拟机网络设置的两种模式。它们在虚拟机与物理网络之间建立连接,并提供不同的网络访问方式。
桥接模式(Bridge Mode):
- 在桥接模式下,虚拟机的网络接口与物理网络的接口相连,虚拟机会获得与物理网络中其他设备相同的网络访问权限。
- 桥接模式使得虚拟机与物理网络中的其他设备处于同一网络段,虚拟机可以直接与其他设备进行通信,就像是连接在同一个交换机上一样。
- 虚拟机通过桥接模式可以获得唯一的IP地址,与物理网络中的其他设备处于相同的子网中。
- 桥接模式可以使虚拟机与物理网络之间实现无缝的网络通信,适用于需要虚拟机与物理网络中其他设备进行直接通信的场景。
NAT模式(Network Address Translation Mode):
- 在NAT模式下,虚拟机的网络接口通过主机的网络接口与物理网络相连,虚拟机的网络流量会通过主机进行网络地址转换。
- 在NAT模式下,虚拟机获得的IP地址是由主机分配的,虚拟机与物理网络中的其他设备之间的通信需要经过主机进行网络地址转换。
- NAT模式隐藏了虚拟机的真实IP地址,对外表现为主机的IP地址,可以提供一定程度的网络安全性。
- 虚拟机通过NAT模式可以与物理网络中的其他设备进行通信,但无法直接与其他设备建立连接。
区别:
- 桥接模式使得虚拟机与物理网络中的其他设备处于同一网络段,虚拟机可以获得唯一的IP地址,可以直接与其他设备进行通信。而NAT模式下,虚拟机的网络流量需要经过主机进行网络地址转换,虚拟机获得的IP地址是由主机分配的,无法直接与其他设备建立连接。
- 桥接模式提供了更高的网络灵活性和直接性,适用于需要虚拟机与物理网络中其他设备进行直接通信的场景。而NAT模式提供了一定程度的网络安全性,隐藏了虚拟机的真实IP地址,适用于需要虚拟机与物理网络进行通信但不需要直接连接其他设备的场景。
- 在桥接模式下,虚拟机需要与物理网络中的其他设备处于同一网络段,因此需要确保物理网络中有足够的IP地址可用。而NAT模式下,虚拟机获得的IP地址是由主机分配的,不会占用物理网络中的IP地址资源。
选择桥接模式还是NAT模式取决于具体的需求和网络环境。如果需要虚拟机与物理网络中的其他设备直接通信,可以选择桥接模式;如果需要一定程度的网络安全性或者物理网络中的IP地址资源有限,可以选择NAT模式。
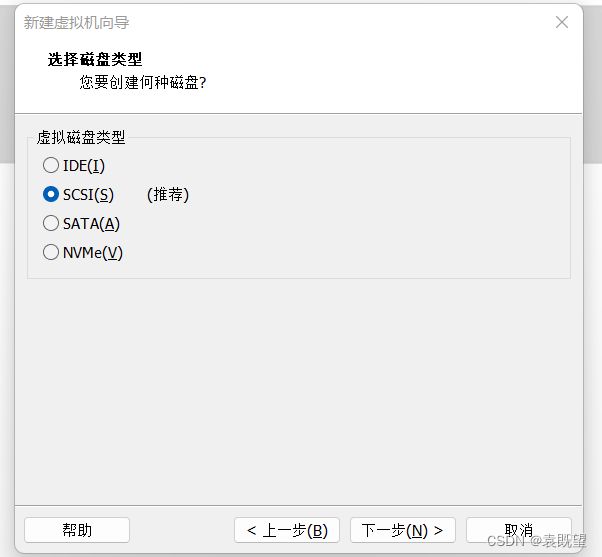
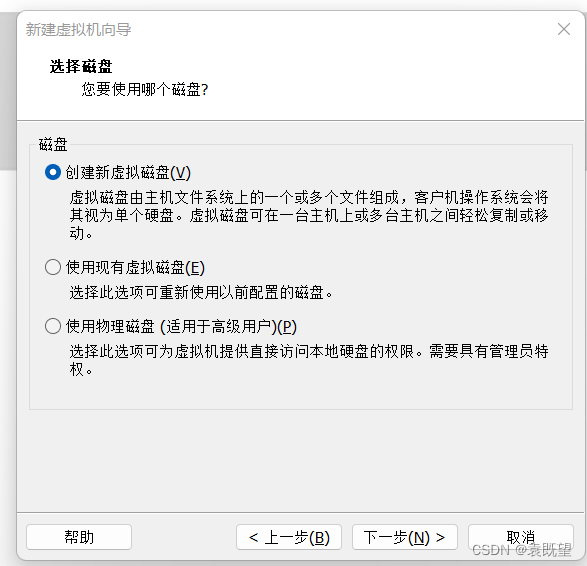
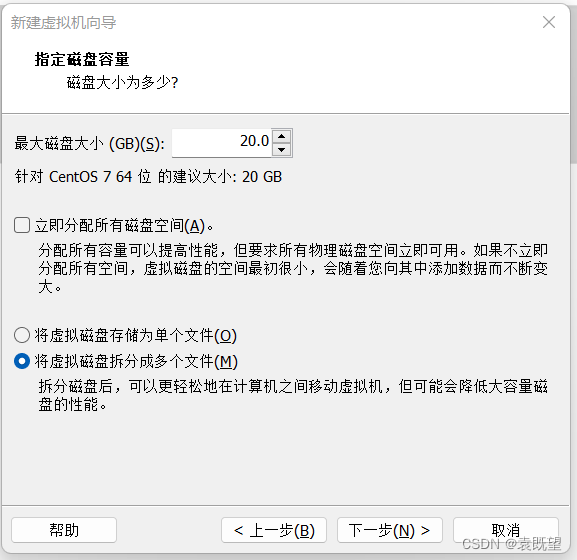
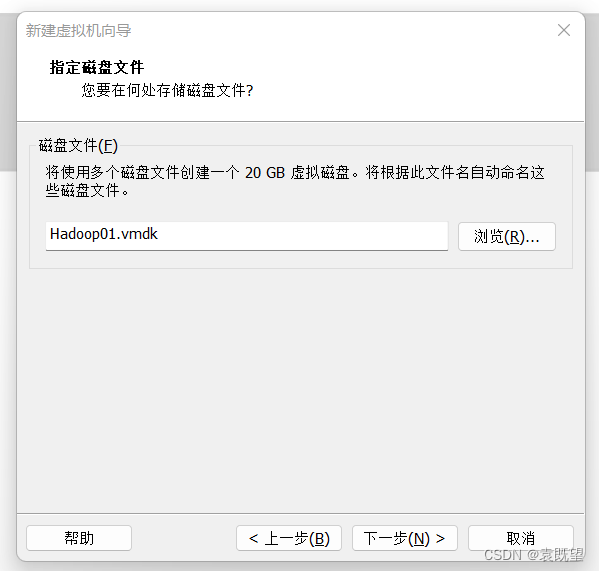
7.指定磁盘类型、磁盘、磁盘容量和磁盘文件
均保持默认即可
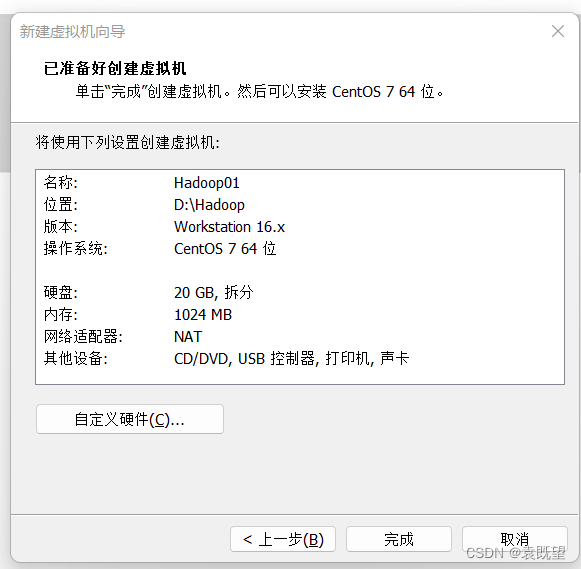
8.虚拟机创建完成(尚未安装操作系统)
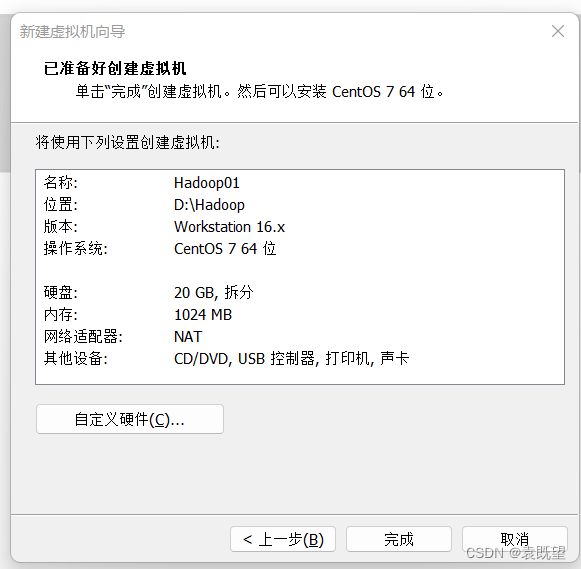 ,
,
这里点击自定义硬件查看一下CentOS7文件是否选择,如果前面选择的稍后安装操作系统,这里需要点进去更改一下:选择使用ISO映像文件
④安装CentOS7操作系统
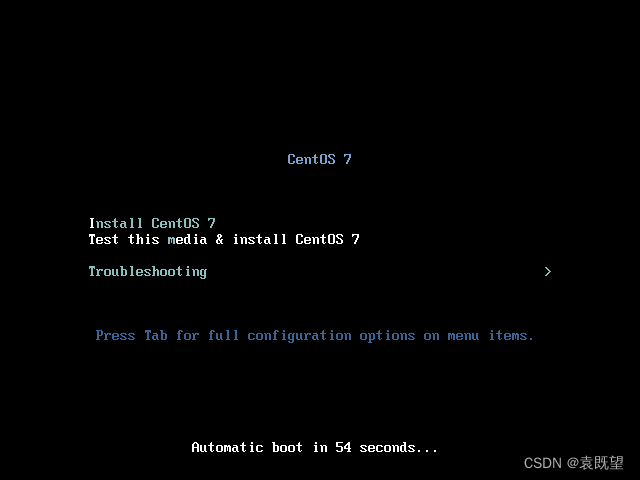
1.开始安装CentOS7操作系统
在首次出现的CentOS7安装界面中,单机以激活键盘,然后使用“↑”“↓”选择“Install CentOS7”选项,然后按回车选择
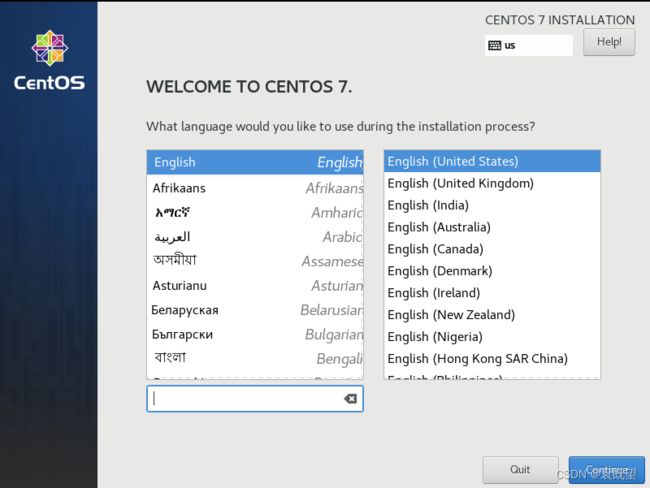
2.选择系统语言
3.指定系统安装位置和系统软件选择
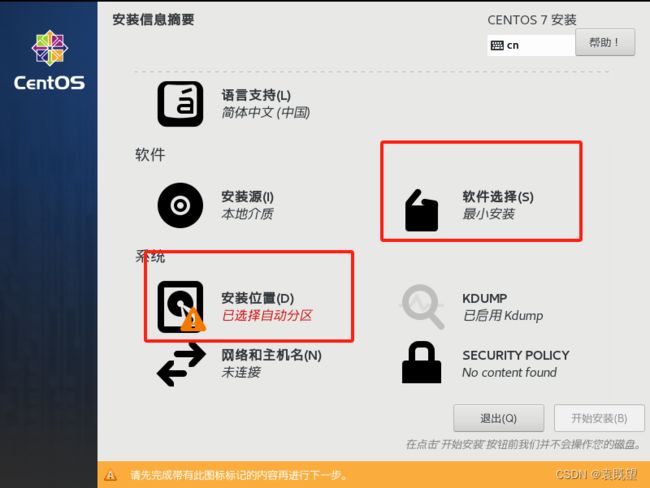
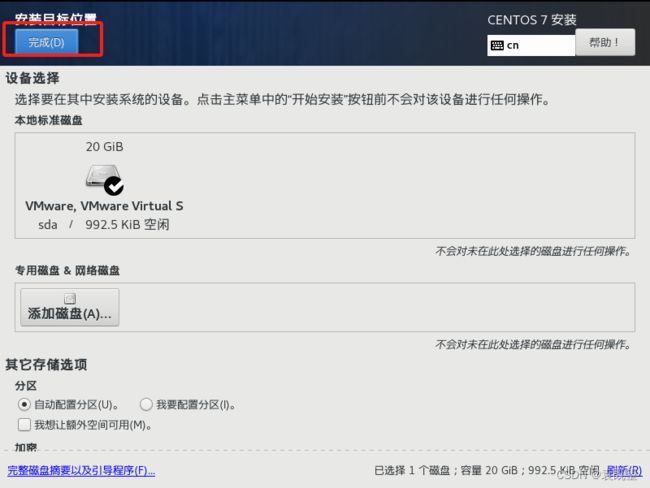
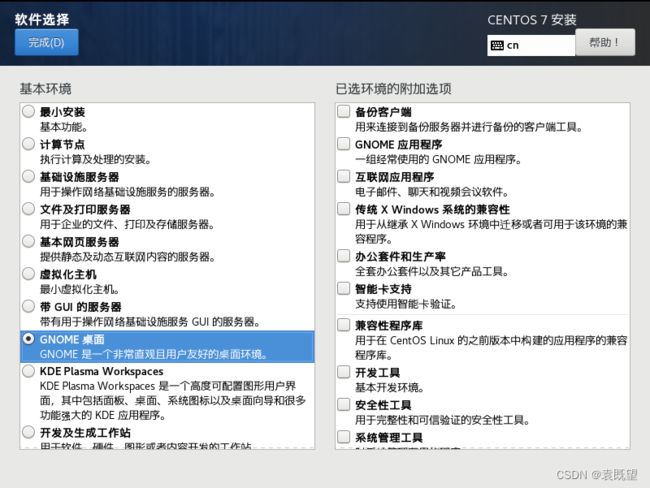
(这里选择GNOME桌面即可)
4.配置网络和主机名
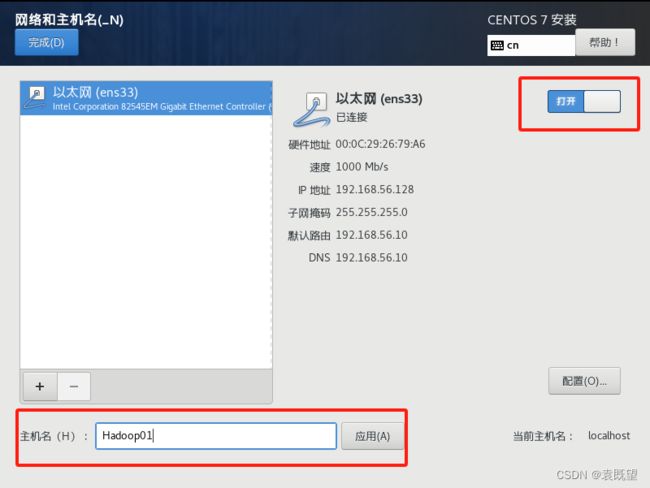
5.正式开始安装
安装过程中会出现“用户设置”界面,可单机“ROOT密码”为root用户设置密码,单机“创建用户”创建一个普通用户或管理员用户。
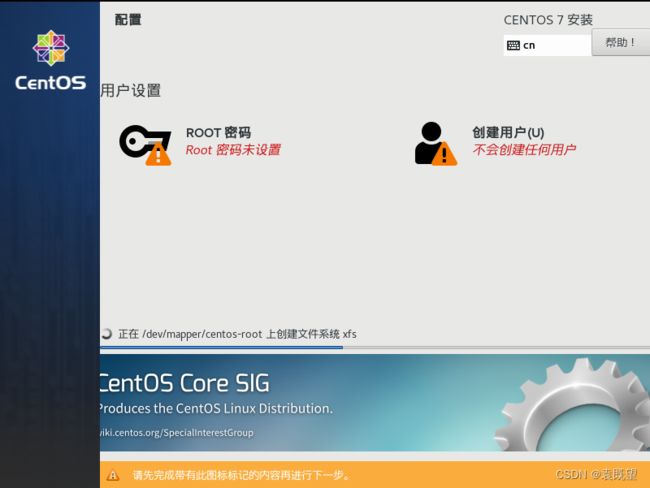
完成后单击“重启”重启操作系统,在重启过程中,还有一个接受许可协议的操作,选择接手之后即可进入登录页面。
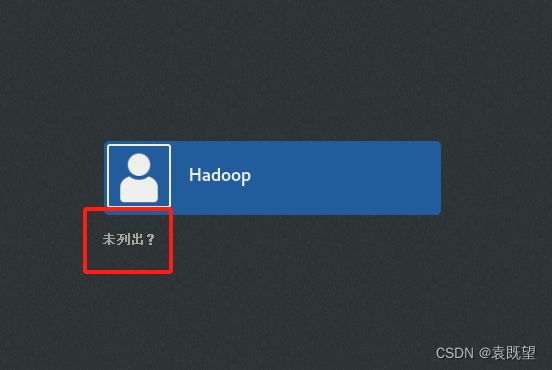
登陆时选择使用root用户登录,单机“未列出”输入root账户及密码。
进入桌面后,右键单击空白区域,选择“打开终端“,即可打开GNOME终端,通过它可以执行各种Shell命令
二、配置虚拟机集群环境
①修改主机名和设置固定IP
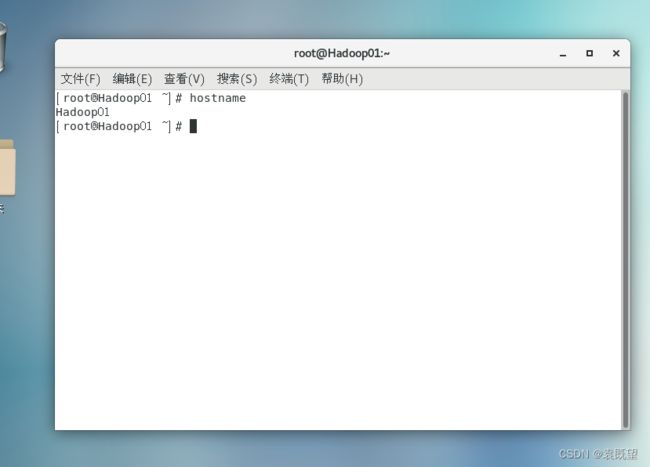
1.修改主机名
执行以下命令查看当前主机名:
# hostname
执行以下命令修改hostname文件,将其内容修改为要使用的主机名:
# vim /etc/hostname
执行以下命令,重启系统使修改生效:
# reboot
2.设置固定IP
默认情况下,CentOS系统的IP地址是自动获取的(即自动分配的),为了避免以后IP地址随意发生改变,导致集群的节点之间无法正常访问,需要为系统设置固定IP。
打开命令终端,执行以下命令,可以查看本机的网卡配置和网络状态信息。
# ifconfig
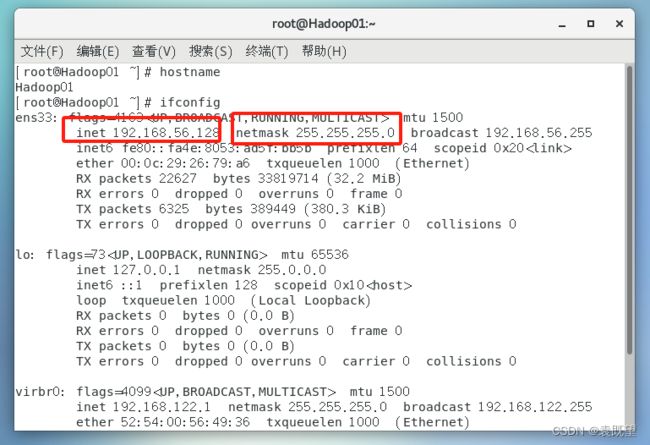
3.修改网卡配置文件ifcfg-ens33
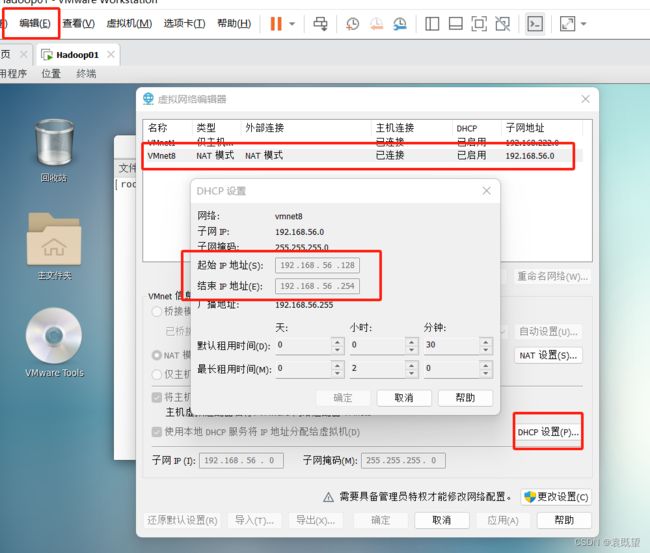
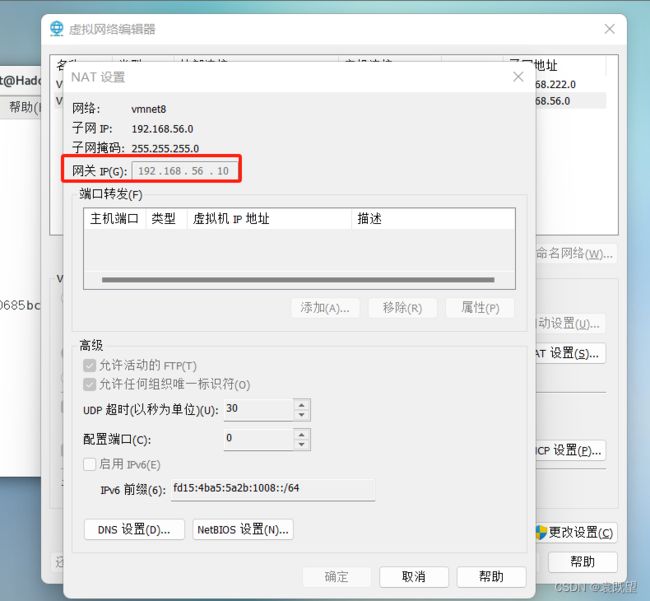
因为博主这里使用的是NAT模式,所以在配置之前,应该先进入虚拟网络设置中,查看NAT模式的起始IP地址和结束IP地址,以及网关
在NAT模式下,虚拟机的网络连接是通过主机的网络连接进行转发的。因此,固定IP地址必须在NAT网络的IP地址范围内,以确保网络通信的正常运行。
在虚拟网络设置中,DHCP设置包括一个IP地址范围,该范围用于自动分配给虚拟机。通常情况下,NAT模式下的DHCP分配的IP地址范围和网关是相互匹配的,所以你应该将网关设置为NAT模式中指定的网关。
如果想为为虚拟机使用固定IP地址,但又不想将其设置在NAT网络的范围内,可以使用桥接模式。在桥接模式下,虚拟机将直接连接到主机网络中,并且可以使用与主机相同的IP地址范围。
注意!在配置固定IP地址时,要确保所选的IP地址在网络中没有冲突,并且不会与其他设备使用的IP地址发生冲突。
执行以下命令,修改网卡配置文件ifcfg-ens33:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
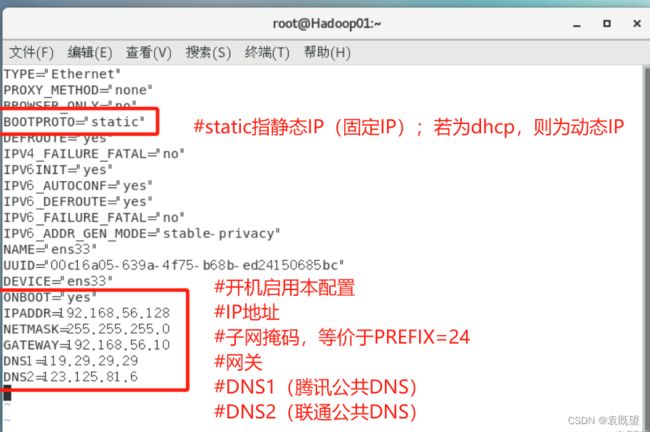
修改完成后,需要执行以下命令重启网络服务
# service network restart
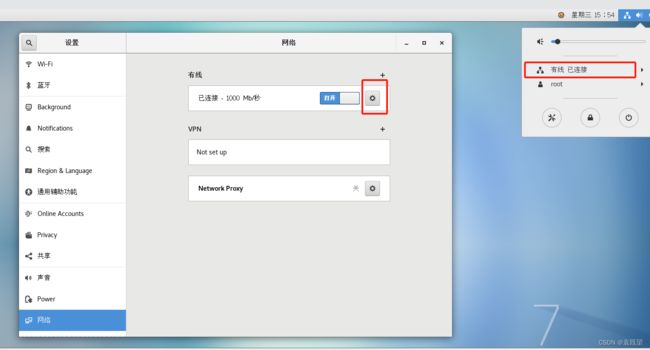
重启完成后,可通过执行”ifconfig“或” ip addr“命令,查看IP地址是否修改成功。也可以按照下图路径查看本机设置的固定IP等信息:
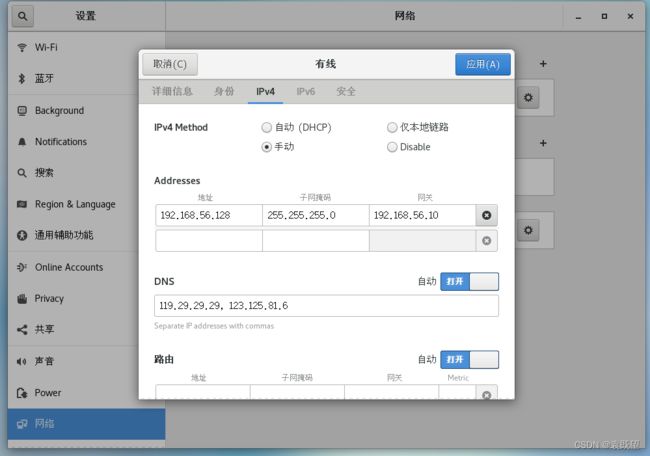
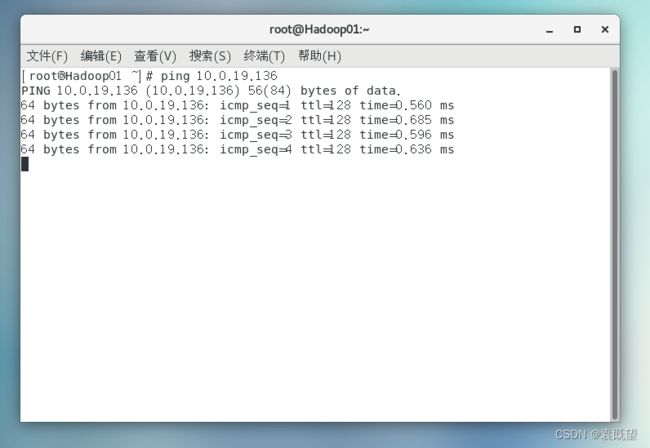
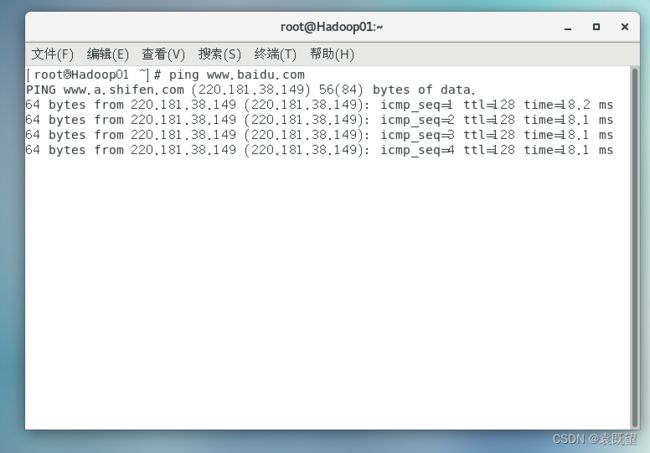
配置完成后,可以ping一下宿主机IP查看是否能ping通,ping一下www.baidu.com查看是否能联网
②关闭防火墙和新建安装目录
1.关闭防火墙
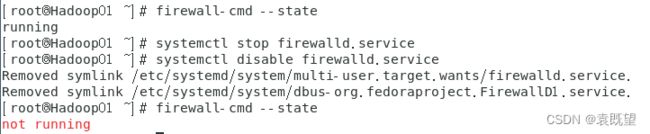
执行以下命令,查看当前防火墙的运行状态(默认为running):
# firewall-cmd --state
或
# systemctl status firewalld.service
执行以下命令关闭防火墙(运行状态变为not running):
# systemctl stop firewalld.service
执行以下命令,禁止防火墙开机启动:
# systemctl disable firewalld.service
重启防火墙的命令为:
systemctl start firewalld.service
使防火墙开机启动的命令为:
systemctl enable firewalld.service
2.新建安装目录
依次执行以下命令,新建安装目录:
mkdir /opt/packages
mkdir /opt/programs
Opt目录:
/opt目录是用于安装可选软件包的位置。在CentOS中,您可以将Hadoop安装在/opt目录下。在这个目录下,您可以创建一个子目录,例如/opt/hadoop,用于存放Hadoop的安装文件和相关配置。Packages(软件包):在Hadoop的上下文中,Packages指的是Hadoop的相关软件包和依赖项。这些软件包包括Hadoop本身以及与Hadoop相关的其他软件,如Hadoop的依赖项(例如Java运行时环境)和其他工具(如Hive、Pig等)。在CentOS中,您可以使用包管理器(如yum)来安装这些软件包,以便在系统中安装和配置Hadoop。
Programs(程序):在Hadoop中,Programs指的是Hadoop的各个组件和工具。Hadoop由多个组件组成,包括Hadoop分布式文件系统(HDFS)和Hadoop分布式计算框架(MapReduce)。此外,还有其他工具和服务,如YARN(资源管理器)、Hive(数据仓库工具)、Pig(数据分析工具)等。这些程序和工具共同构成了Hadoop生态系统,用于处理和分析大规模数据。
总结起来,opt目录是用于存放Hadoop安装文件和配置的位置,packages是指Hadoop的相关软件包和依赖项,而programs是指Hadoop的各个组件和工具,包括HDFS、MapReduce、YARN等。
③安装和配置JDK
1.下载
由于Hadoop平台基于Java开发,严格依赖Java开发环境,因此需要为虚拟机安装JDK。
下载地址:Java Archive Downloads - Java SE 8 (oracle.com)
2.删除OpenJDk
由于CentOS7预装了OpenJDK,但该版本的JDK功能通常有所精简,为了避免系统默认使用OpenJDK,需要先将其卸载,然后再安装使用标准版
执行以下命令,查询已安装的OpenJDK:
rpm -qa|grep openjdk

执行以下命令,将查询到的OpenJDK全部卸载:
rpm -e --nodeps +文件名
(文件名与前面的命令中间的空格不能缺)
删除后再次查看发现为空
3.上传JDK安装包
然后将下载的JDK安装包上传到虚拟机”/opt/packages“目录下
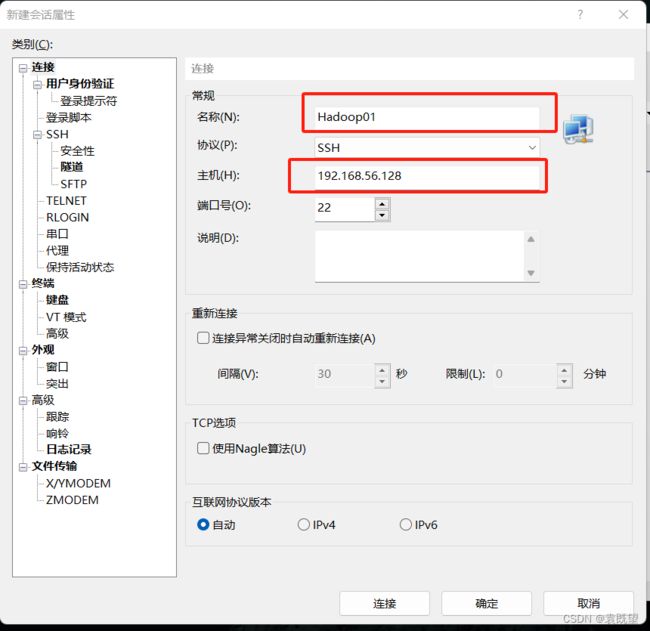
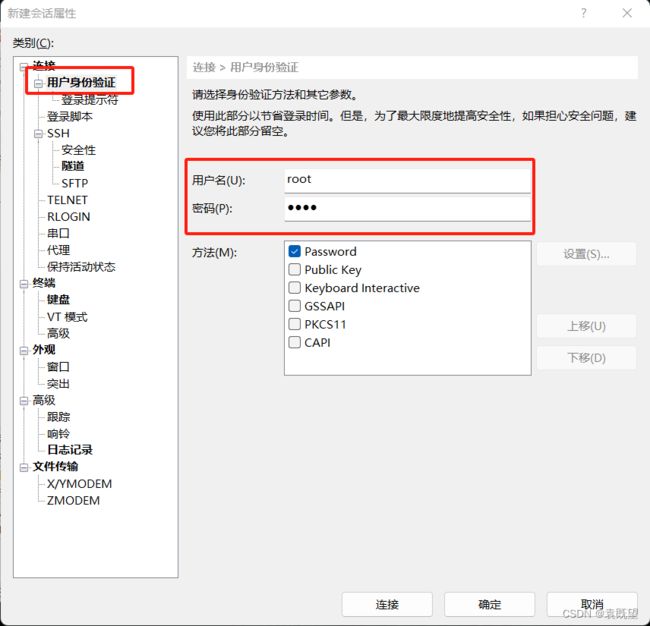
博主这里使用的是XShell(也可以 使用finalshell,WinSCP等)
连接虚拟机:
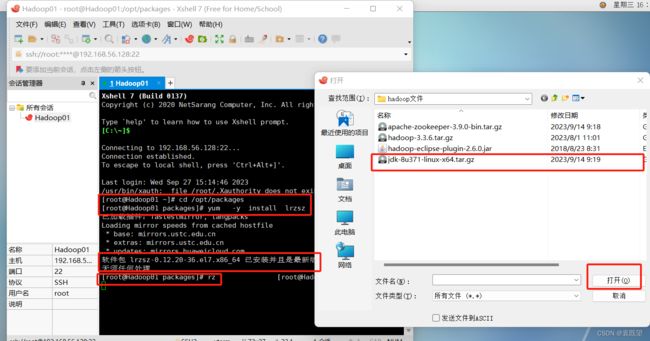
通过以下命令进入该目录
# cd /opt/packages
下载插件
# yum -y install lrzsz
然后使用rz命令上传
# rz
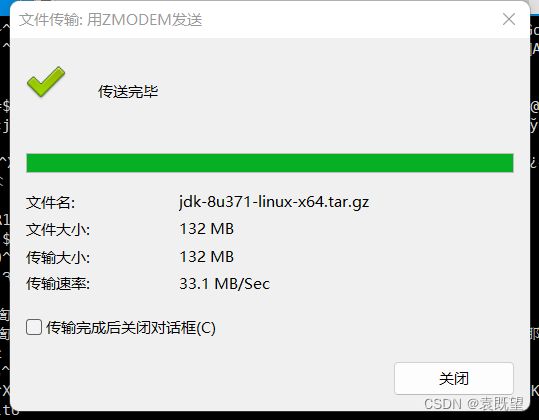
传输完毕后,进入虚拟机执行以下命令,将JDK文件解压到目录”/opt/programs“
tar -zxvf jdk-8u371-linux-x64.tar.gz -C /opt/programs
然后执行以下命令修改文件”/etc/programs“,配置JDK系统环境变量:
vim /etc/profile
在文件末尾加入以下内容:
export JAVA_HOME=/opt/programs/jdk1.8.0_371
export PATH=$PATH:$JAVA_HOME/bin
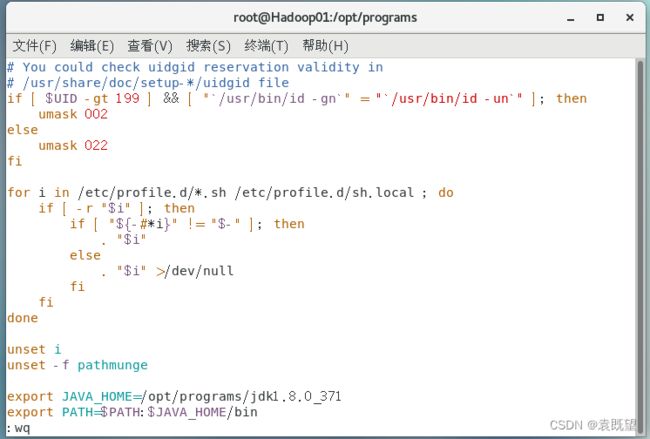
执行以下命令,刷新profile文件,使修改生效:
# source /etc/profile
(注!每次修改profile之后都要刷新才能生效)
执行java -version命令,若能查看到JDK版本,则说明安装成功!

④克隆虚拟机和配置主机IP映射
1.克隆虚拟机
由于集群环境需要多个节点,当一个节点配置完成后,可以借助VMware Workstation软件的克隆功能,对配置好的节点进行完整克隆,以快速获得新的节点。
①Hadoop01---管理---克隆
②按照下图各步骤进行
按照同样的方法,克隆Hadoop01节点。
③修改主机名和IP地址
由于Hadoop02和Hadoop03都是通过克隆Hadoop01得到的,他们的主机名和IP地址都和节点Hadoop01相同,因此需要修改这两个节点的主机名和IP地址,修改方法与前面第二部分的①一致。
2.配置主机映射
通过修改集群中各节点的主机IP映射(即主机IP地址和主机名的对照列表),可以方便的使用主机名进行网络访问,不再需要输入要访问节点的IP地址。
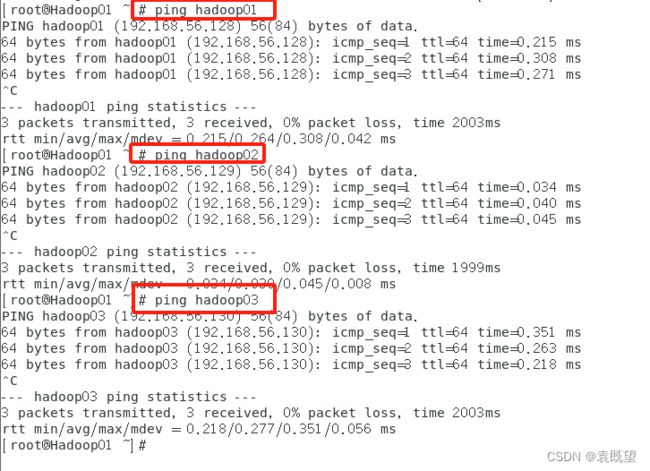
依次启动三个节点,并在三个节点上分别执行以下命令,修改hosts文件
# vim /etc/hosts
在hosts文件末尾添加以下内容(根据自己的IP设置):
192.168.56.128 Hadoop01
192.168.56.129 Hadoop02
192.168.56.130 Hadoop03
然后在各节点使用ping命令测试是否配置成功
3.配置各节点SSH免密码登录
由于集群节点之间需要频繁通信,但Linux系统在相互通信过程中需要验证身份,为了使Hadoo各节点之间能够免密码相互访问,因此需要为各节点配置SSH免密码登录
SSH(Secure Shell)是一种网络协议,用于在不安全的网络上安全地进行远程登录和数据传输。它通过加密和身份验证机制来保护数据的安全性。
使用SSH,你可以安全地远程登录到远程计算机或服务器,并在远程系统上执行命令。SSH提供了身份验证的方式,通常使用用户名和密码进行登录,也可以使用密钥对进行身份验证。一旦建立了SSH连接,所有通过该连接传输的数据都会被加密,从而防止第三方窃听或篡改数据。
SSH还可以用于安全地传输文件,通过SCP(Secure Copy)或SFTP(SSH File Transfer Protocol)协议,你可以在本地计算机和远程服务器之间传输文件,并确保数据的机密性和完整性。
总而言之,SSH是一种安全的远程登录和数据传输协议,广泛用于管理远程服务器、执行远程命令和传输文件。
分别在三个节点中执行以下命令,生成密钥文件:
ssh-keygen
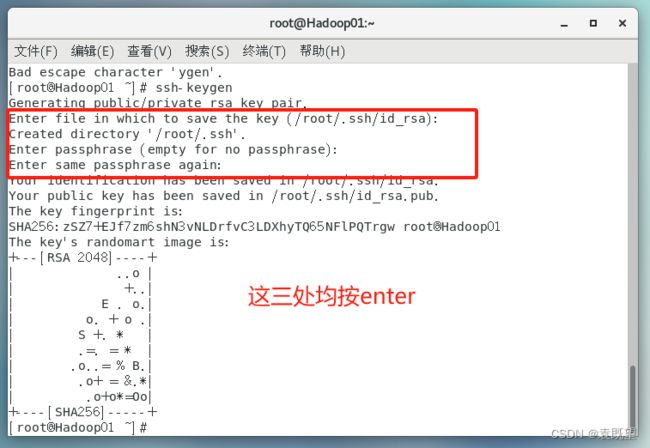
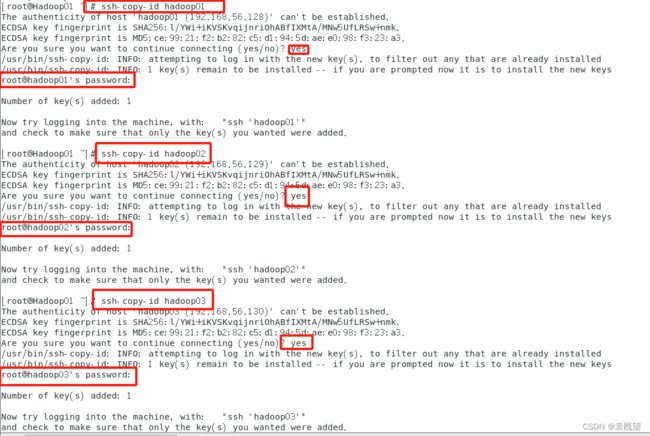
然后分别在三个节点中执行以下命令,将自身的公钥信息复制并追加到全部节点的授权文件authorized_keys中(在命令执行过程中需要确认连结及输入用户密码)
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
authorized_keys是 SSH(Secure Shell)协议中的一个文件,用于管理远程登录的授权密钥。在 SSH 的身份验证过程中,通常使用密码或密钥对进行身份验证。而
authorized_keys文件则用于存储远程服务器上允许访问的公钥(密钥对中的公钥部分),以实现基于密钥的身份验证。当用户尝试通过 SSH 远程登录到服务器时,服务器会检查用户提供的密钥是否存在于
authorized_keys文件中。如果存在匹配的公钥,服务器将验证密钥的有效性,并允许用户登录。通过使用
authorized_keys文件,可以实现更安全和方便的身份验证方式。相比于传统的密码身份验证,使用密钥对进行身份验证可以提供更高的安全性,同时也减少了密码泄露的风险。要使用
authorized_keys文件进行密钥身份验证,首先需要生成密钥对,并将公钥添加到服务器上的authorized_keys文件中。每个用户都可以在自己的主目录下创建一个名为.ssh的隐藏文件夹,并在其中创建authorized_keys文件。然后,将要授权的公钥内容添加到authorized_keys文件中,每个公钥占据一行。总结:
authorized_keys是 SSH 协议中的一个文件,用于存储允许访问远程服务器的公钥,以实现基于密钥的身份验证。使用该文件可以提供更安全和方便的身份验证方式。
全部执行完之后,在各个节点下使用以下命令测试SSH免密码登录是否配置完成
ssh hadoop01
ssh hadoop02
ssh hadoop03

成功登录后可执行exit命令退出登录
三、搭建Hadoop高可用集群
Hadoop 高可用集群和早期版本的 Hadoop 在以下几个方面存在区别:
主从架构:早期版本的 Hadoop 采用了主从架构,其中有一个单一的主节点(NameNode)负责管理文件系统的元数据和协调数据存储。这种设计存在单点故障的风险,如果主节点发生故障,整个系统将无法正常工作。而 Hadoop 高可用集群引入了 HDFS(Hadoop Distributed File System)的高可用性机制,通过使用多个 NameNode 节点和共享存储来实现主备切换,从而提供了更高的容错性和可用性。
故障检测和自动恢复:早期版本的 Hadoop 需要手动处理节点故障和数据恢复。当一个数据节点(DataNode)发生故障时,需要手动将其重新添加到集群中,并执行数据恢复操作。而在 Hadoop 高可用集群中,故障检测和自动恢复是集群的核心功能。当一个数据节点发生故障时,集群会自动检测到并将其替换为其他可用节点,同时自动进行数据的复制和恢复。
资源管理:早期版本的 Hadoop 使用了 MapReduce 作业调度器来管理集群中的资源分配和作业执行。这种调度器对于大规模作业的管理和调度存在一些限制,无法满足复杂的资源管理需求。而在 Hadoop 高可用集群中,引入了 YARN(Yet Another Resource Negotiator)作业调度器,它提供了更灵活和可扩展的资源管理机制,可以同时运行多种类型的作业,并更好地支持多租户环境。
高可用性工具:Hadoop 高可用集群引入了一些专门的工具和组件来实现高可用性。例如,使用 ZooKeeper 来协调和管理集群中的各个组件,以确保它们的一致性和可用性。此外,还引入了自动故障切换机制和监控工具,以便在节点故障时自动切换和恢复服务。
总的来说,Hadoop 高可用集群相对于早期版本的 Hadoop 在容错性、可用性和自动化方面有了显著的改进。它通过引入多个 NameNode 节点、故障检测和自动恢复机制、灵活的资源管理和专门的高可用性工具,提供了更可靠和稳定的分布式数据处理解决方案。
①安装和配置Zookeeper
对于双NameNode的Hadoop高可用分布式集群,需要安装和配置一个zookeeper集群,用于ZKFC,从而保证当活动状态的NameNode失效时,备用状态的NameNode可以自动切换为活动状态
ZKFC 是指 ZooKeeper Failover Controller,是 Hadoop 高可用集群中用于管理和监控 HDFS(Hadoop Distributed File System)的 NameNode 高可用性的组件。
在 Hadoop 高可用集群中,通常会有两个 NameNode 节点,一个是 Active NameNode,负责处理客户端的请求和管理文件系统的元数据;另一个是 Standby NameNode,处于备用状态,用于在 Active NameNode 发生故障时接管其职责。ZKFC 负责监控 Active NameNode 的健康状态,并在 Active NameNode 发生故障时触发自动故障切换,将 Standby NameNode 切换为 Active 状态,确保 HDFS 的高可用性。
ZKFC 依赖于 ZooKeeper,一个分布式协调服务,用于在集群中各个组件之间协调和同步状态信息。ZKFC 将 Active 和 Standby NameNode 的状态信息存储在 ZooKeeper 中,并通过与 ZooKeeper 的交互来监控 Active NameNode 的状态。如果 ZKFC 检测到 Active NameNode 失去响应或发生故障,它将触发故障切换过程,将 Standby NameNode 提升为 Active 状态,并更新 ZooKeeper 中的状态信息。
通过使用 ZKFC,Hadoop 高可用集群可以实现快速而可靠的故障切换,从而减少系统的停机时间,提供持续的服务。ZKFC 确保了 NameNode 的高可用性,并与 ZooKeeper 紧密集成,以实现状态的一致性和可靠的故障检测与切换。
1.安装(与前面安装jdk方法一致)
下载地址:Index of /dist/zookeeper (apache.org)
下载好需要的版本之后,通过Xshell或其他软件将安装包上传(过程与前面jdk的安装一致)到Hadoop01节点的“/opt/packages”目录下,然后执行以下命令进入该目录:
# cd /opt/packages
然后执行以下命令,将zookeeper解压到目录“/opt/programs”下
# tar -zxvf apache-zookeeper-3.9.0-bin.tar.gz -C /opt/programs
执行以下命令进入zookeeper的安装目录:
# cd apache-zookeeper-3.9.0-bin
在该目录下分别创建文件夹“data”和“logs”:
# mkdir data
# mkdir logs
执行以下命令进入“data”文件夹:
# cd data
执行以下命令,新建一个名为“myid”的文件,并写入id号“1”:
# echo '1'>myid
接着进入zookeeper安装目录下的“conf”文件夹,将zoo_sample.cfg文件复制一份并重命名为zoo.cfg:
# cd /opt/programs/apache-zookeeper-3.9.0-bin/conf
# cp zoo_sample.cfg zoo.cfg
然后执行以下命令修改zoo.cfg文件:
# vim zoo.cfg
先将文件中的“dataDir”修改为:
dataDir=/opt/programs/apache-zookeeper-3.9.0-bin/data
然后再在文件末尾加入以下内容:
dataLogDir=/opt/programs/apache-zookeeper-3.9.0-bin/logs
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
2.复制到Hadoop02和Hadoop03
执行以下命令,将Hadoop01节点的整个zookeeper安装目录远程复制到Hadoop02和Hadoop03中:
# scp -r /opt/programs/apache-zookeeper-3.9.0-bin root@hadoop02:/opt/programs/
# scp -r /opt/programs/apache-zookeeper-3.9.0-bin root@hadoop03:/opt/programs/
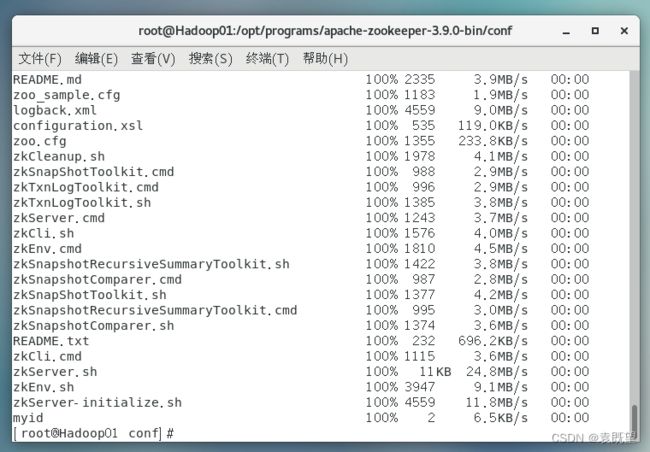
可以在Hadoop02 和 Hadoop03节点的对应目录下ls查看一下是否复制成功
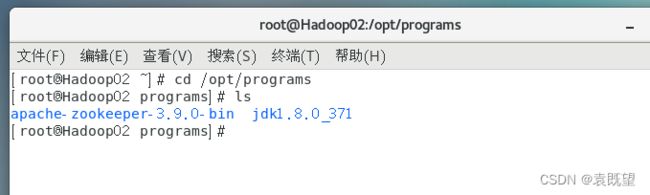
复制完成后,需要将Hadoop02和Hadoop03节点中的myid文件的值修改为对应的数字(2、3)
# vim /opt/programs/apache-zookeeper-3.9.0-bin/data/myid
然后在三个节点上分别执行以下命令,修改文件“/etc/profile”,配置zookeeper的环境变量:
# vim /etc/profile
在文件末尾加入以下内容:
export ZOOKEEPER_HOME=/opt/programs/apache-zookeeper-3.9.0-bin
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin
然后刷新profile文件,使修改生效:
# source /etc/profile
最后在三个节点上分别执行以下命令,启动zookeeper集群:
# zkServer.sh start
出现如下图所示即启动成功:

可以在三个节点下执行以下命令,查看zookeeper集群状态:
# zkServer.sh status



在 ZooKeeper 中,有三个核心角色:
1. Leader(领导者):Leader 是 ZooKeeper 集群中的一个角色,负责处理客户端请求、协调和管理集群中的其他节点。Leader 负责维护 ZooKeeper 数据的一致性,并处理客户端的写操作。在集群中,只有一个节点可以成为 Leader,其他节点处于 Follower 或 Observer 角色。
2. Follower(跟随者):Follower 是 ZooKeeper 集群中的角色,负责跟随 Leader 的指导,参与数据的复制和同步。Follower 接收来自 Leader 的数据更新,并将其应用到本地副本中。Follower 可以处理客户端的读请求,但不能处理写请求。如果 Leader 发生故障,Follower 可以参与选举过程,竞选成为新的 Leader。
3. Observer(观察者):Observer 是 ZooKeeper 集群中的角色,类似于 Follower,但不参与 Leader 的选举过程。Observer 接收来自 Leader 和 Follower 的数据更新,但不参与数据的写操作。Observer 的存在可以增加集群的读取能力,减轻 Leader 和 Follower 的负载压力。
这三个角色共同组成了 ZooKeeper 集群的整体架构。Leader 负责协调和管理集群,Follower 和 Observer 跟随 Leader 的指导,参与数据的复制和同步。通过这种分布式的角色分工,ZooKeeper 实现了高可用性和数据一致性,同时提供了高性能的读写操作。
要停止zookeeper服务,可执行“zkServer.sh stop”命令,要重启zookeeper服务,可执行“zkServer.sh restart”命令
②安装与配置Hadoop
下载地址:Index of /dist/hadoop/core (apache.org)
下载好需要的版本之后,通过Xshell或其他软件将安装包上传(过程与前面jdk、zookeeper的安装一致)到Hadoop01节点的“/opt/packages”目录下,然后执行以下命令进入该目录:
# cd /opt/packages
然后执行以下命令,将hadoop解压到目录“/opt/programs”下:
tar -zxvf hadoop-3.3.6.tar.gz -C /opt/programs
接着进入“/opt/programs/hadoop-3.3.6/etc/hadoop”目录,依次修改配置文件 core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves(又一个坑,Hadoop3.x版本之后,slaves文件更名为workers,所以很多同学会找不到这个文件)、hadoop-env.sh、mapred-env.sh和yarn-env.sh
# cd /opt/programs/hadoop-3.3.6/etc/hadoop
1.修改配置文件core-site.xml
# vim core-site.xml
将
configuration>
fs.defaultFS
hdfs://ns
hadoop.tmp.dir
/opt/programs/hadoop-3.3.6/tmp
ha.zookeeper.quorum
hadoop01:2181,hadoop02:2181,hadoop03:2181
2.修改配置文件hdfs-site.xml
# vim hdfs-site.xml
将
dfs.replication
3
dfs.nameservices
ns
dfs.ha.namenodes.ns
nn1,nn2
dfs.namenode.rpc-address.ns.nn1
hadoop01:9000
dfs.namenode.http-address.ns.nn1
hadoop01:50070
dfs.namenode.rpc-address.ns.nn2
hadoop02:9000
dfs.namenode.http-address.ns.nn2
hadoop02:50070
dfs.namenode.shared.edits.dir
qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/ns
dfs.journalnode.edits.dir
/opt/programs/hadoop-3.3.6/journal/data
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ns
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
3.修改配置文件mapred-site.xml
将
# vim mapred-site.xml
mapreduce.framework.name
yarn
4.修改配置文件yarn-site.xml
# vim yarn-site.xml
将
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop01
yarn.resourcemanager.hostname.rm2
hadoop02
yarn.resourcemanager.zk-address
hadoop01:2181,hadoop02:2181,hadoop03:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
5.修改配置文件slaves(Hadoop3.x之后版本均变更为workers)
# vim workers
将localhost修改为以下内容:
hadoop01
hadoop02
hadoop03
6.修改配置文件hadoop-env.sh、mapred-env.sh和yarn-env.sh
# vim hadoop-env.sh
# vim mapred-env.sh
# vim yarn-env.sh
在hadoop-env.sh、mapred-env.sh和yarn-env.sh中均加入JAVA_HOME环境变量:
export JAVA_HOME=/opt/programs/jdk1.8.0_371
7.复制到Hadoop02和Hadoop03
# scp -r /opt/programs/hadoop-3.3.6 root@hadoop02:/opt/programs/
# scp -r /opt/programs/hadoop-3.3.6 root@hadoop03:/opt/programs/
复制完成后可ls查看一下是否复制成功
![]()
在三个节点上分别执行以下命令,修改文件“/etc/profile”配置Hadoop环境变量:
# vim /etc/profile
在文件末尾添加以下内容:
export HADOOP_HOME=/opt/programs/hadoop-3.3.6
export PATH=$PATH:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后刷新profile文件,使修改生效:
# source /etc/profile
③启动与测试Hadoop
在这一步开始之前,
一定要设置快照!
一定要设置快照!!
一定要设置快照!!!
否则后面出现问题越改越麻烦,最后只能删除重头再来!!!
1.格式化NameNode
由于是第一次启动Hadoop,需要先格式化NameNode,格式化NameNode需要先启动JournalNode(以后就不用了),在三个节点上分别执行以下命令:
# hadoop-daemon.sh start journalnode
可能会出现以下警告,和书上的内容不一致:

但是不必担心,这个警告是因为使用`hadoop-daemon.sh`脚本启动HDFS守护进程已经不推荐使用了,但是没有影响,你可以jps一下查看你的journalnode进程是否启动。
接下来进行格式化操作(此时要保证三个节点均已开机,并且已经启动zookeeper和journalanoed)
# hdfs namenode -format
出现以下信息则说明格式化成功:
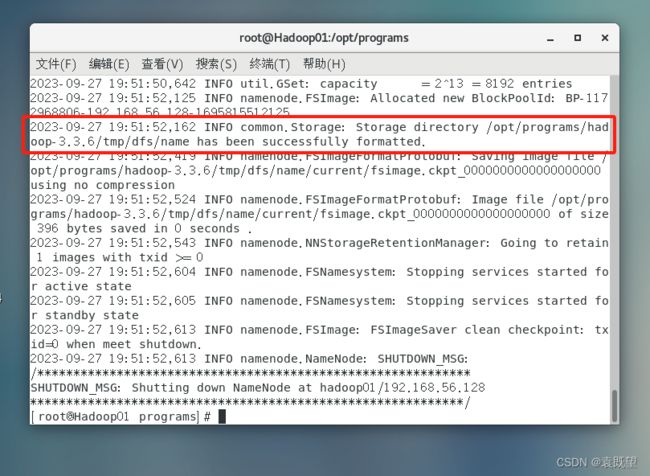
格式化成功后,会在Hadoop安装目录中生成“tmp/dfs/name/current”目录,该目录中则生成了用于存储HDFS文件系统元数据信息的文件fsimage等。
接着执行以下命令进入Hadoop安装目录:
# cd /opt/programs/hadoop-3.3.6
再执行以下命令,将Hadoop01节点Hadoop安装目录下的tmp文件夹远程复制到Hadoop02节点的Hadoop安装目录下:
# scp -r tmp/ root@hadoop02:/opt/programs/hadoop-3.3.6
2.格式化ZKFC
接着在Hadoop01节点上执行以下命令,格式化ZKFC:
# hdfs zkfc -formatZK
若出现以下信息则说明格式化成功:
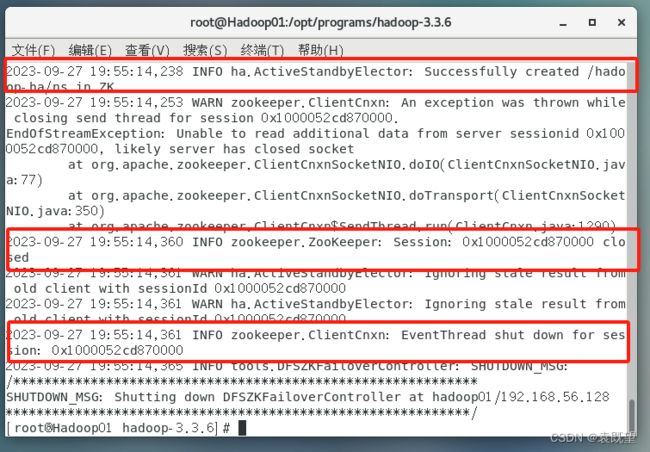
格式化ZKFC只需进行一次,且仅在Hadoop01节点上
3.启动HDFS和YARN
(这一步非常非常非常容易出问题,如果报错,需要仔细查看日志内容,不要随意修改,很容易死在这黎明前的最后一步!!)
在Hadoop01节点上执行以下命令,启动HDFS和YARN:
# start-dfs.sh
# start-yarn.sh
bug1:
如果出现类似报错
[root@localhost sbin]# start-all.sh
Starting namenodes on [hadoop]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [hadoop]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
2018-07-16 05:45:04,628 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
可以查看这篇博文寻找解决办法,感谢这篇博文的作者拯救了我,希望也可以拯救各位:两种解决ERROR: Attempting to operate on hdfs namenode as root的方法_starting namenodes on [localhost] error: attemptin-CSDN博客
解决方法:进入profile文件,在环境变量中添加下面的配置
# vim /etc/profile
添加以下内容
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root注:正常启动后使用jps命令查看进程应该有8个
bug2:
当全部启动后,发现访问8088和50070访问不了,jps查看进程后发现,没有NameNode,参考下面这篇博客,重新格式化了NameNode,并重新执行了前面的过程T.T,终于jps八个进程全都有了
【问题解决】Hadoop集群启动后执行JPS没有DataNode或NameNode_hadoop启动jps缺少namenode_wydxry的博客-CSDN博客
首次启动Hadoop集群 ,要严格按照上面的步骤进行操作(因为涉及格式化问题)
以后再次启动Hadoop集群时,可以按照启动zookeeper、HDFS、YARN的顺序进行,其中,启动zookeeper时,需要在每一个节点上执行一次“zkServer.sh.start",而启动HDFS和YARN时,只需要在Hadoop01上启动命令“start-dfs.sh”和“start-yarn.sh"
停止时,首先在Hadoop01上执行”stop-yarn.sh”和“stop-dfs.sh"命令,然后在每个节点上都执行一次”zkServer.sh.stop”命令。
此外,还可以使用“start-all.sh”和“stop-all.sh”命令来启动集群,但是系统已经建议放弃使用这两个命令,而改用上面的命令。
启动集群后,在宿主机输入 http://IP地址:8088/cluster 可查看YARN的运行状态(即对应用状态进行监测)
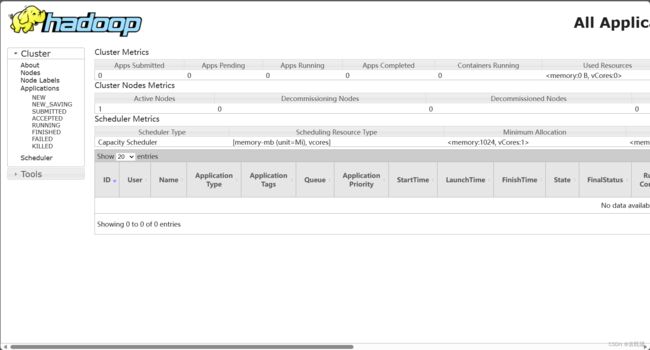
bug3:
如果8088打不开,50070能打开
可以查看下面这位博主的博客:hadoop 8088端口无法访问_hadoop web端口8088-CSDN博客
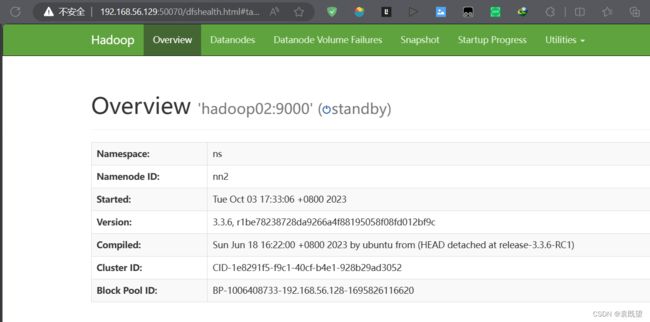
在浏览器输入 http://Hadoop01的IP地址:50070/ 页面显示 “‘Hadoop01:9000’(active)”
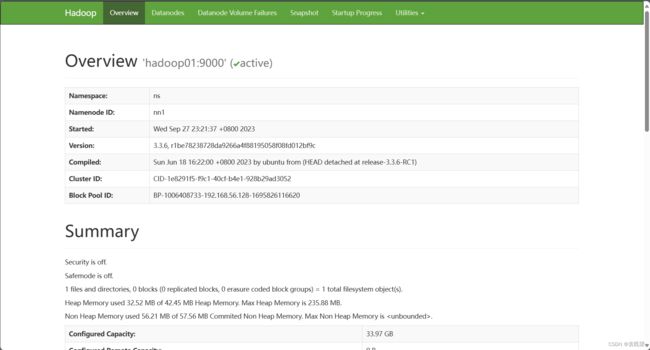
访问 http://Hadoop02的IP地址:50070/ 页面显示“’Hadoop02:9000’(standby)”
正常启动后,三个节点启动的进程应该如下图所示,如果有进程没有启动,那就是存在bug!!
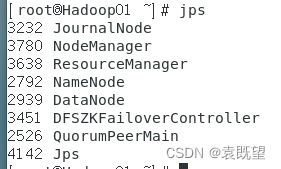
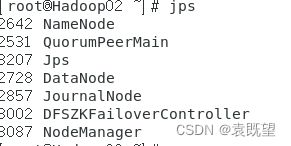
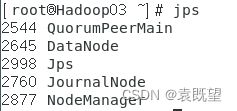
其中:
QuorumPeerMain是ZooKeeper集群所启动的进程;
NameNode、DataNode、JournalNode、DFSZKFailoverController是HDFS集群所启动的进程;
ResourceManager和NodeManager是YARN集群所启动的进程。
希望对各位的Hadoop之旅能够有所帮助!!!
如果觉得对你有帮助,麻烦各位给个点赞收藏加关注哦~