并发设计模式
1、Immutability模式:如何利用不变性解决并发问题?
“多个线程同时读写同一共享变量存在并发问题”,这里的必要条件之一是读写,如果只有读,而没有写,是没有并发问题的。
解决并发问题,其实最简单的办法就是让共享变量只有读操作,而没有写操作。这个办法如此重要,以至于被上升到了一种解决并发问题的设计模式:不变性(Immutability)模式。所谓不变性,简单来讲,就是对象一旦被创建之后,状态就不再发生变化。换句话说,就是变量一旦被赋值,就不允许修改了(没有写操作);没有修改操作,也就是保持了不变性。
(1)快速实现具备不可变性的类
实现一个具备不可变性的类,还是挺简单的。将一个类所有的属性都设置成 final 的,并且只允许存在只读方法,那么这个类基本上就具备不可变性了。更严格的做法是这个类本身也是 final 的,也就是不允许继承。因为子类可以覆盖父类的方法,有可能改变不可变性,所以推荐你在实际工作中,使用这种更严格的做法。
Java SDK 里很多类都具备不可变性,只是由于它们的使用太简单,最后反而被忽略了。例如经常用到的 String 和 Long、Integer、Double 等基础类型的包装类都具备不可变性,这些对象的线程安全性都是靠不可变性来保证的。如果你仔细翻看这些类的声明、属性和方法,你会发现它们都严格遵守不可变类的三点要求:类和属性都是 final 的,所有方法均是只读的。
看到这里你可能会疑惑,Java 的 String 方法也有类似字符替换操作,怎么能说所有方法都是只读的呢?我们结合 String 的源代码来解释一下这个问题,下面的示例代码源自 Java 1.8 SDK,我略做了修改,仅保留了关键属性 value[]和 replace() 方法,你会发现:String 这个类以及它的属性 value[]都是 final 的;而 replace() 方法的实现,就的确没有修改 value[],而是将替换后的字符串作为返回值返回了。
public final class String {
private final char value[];
// 字符替换
String replace(char oldChar,
char newChar) {
//无需替换,直接返回this
if (oldChar == newChar){
return this;
}
int len = value.length;
int i = -1;
/* avoid getfield opcode */
char[] val = value;
//定位到需要替换的字符位置
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
//未找到oldChar,无需替换
if (i >= len) {
return this;
}
//创建一个buf[],这是关键
//用来保存替换后的字符串
char buf[] = new char[len];
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ?
newChar : c;
i++;
}
//创建一个新的字符串返回
//原字符串不会发生任何变化
return new String(buf, true);
}
}通过分析 String 的实现,你可能已经发现了,如果具备不可变性的类,需要提供类似修改的功能,具体该怎么操作呢?做法很简单,那就是创建一个新的不可变对象,这是与可变对象的一个重要区别,可变对象往往是修改自己的属性。
所有的修改操作都创建一个新的不可变对象,你可能会有这种担心:是不是创建的对象太多了,有点太浪费内存呢?是的,这样做的确有些浪费,那如何解决呢?
(2)利用享元模式避免创建重复对象
如果你熟悉面向对象相关的设计模式,相信你一定能想到享元模式(Flyweight Pattern)。利用享元模式可以减少创建对象的数量,从而减少内存占用。Java 语言里面 Long、Integer、Short、Byte 等这些基本数据类型的包装类都用到了享元模式。
如果你熟悉面向对象相关的设计模式,相信你一定能想到享元模式(Flyweight Pattern)。利用享元模式可以减少创建对象的数量,从而减少内存占用。Java 语言里面 Long、Integer、Short、Byte 等这些基本数据类型的包装类都用到了享元模式。
下面我们就以 Long 这个类作为例子,看看它是如何利用享元模式来优化对象的创建的。
享元模式本质上其实就是一个对象池,利用享元模式创建对象的逻辑也很简单:创建之前,首先去对象池里看看是不是存在;如果已经存在,就利用对象池里的对象;如果不存在,就会新创建一个对象,并且把这个新创建出来的对象放进对象池里。
Long 这个类并没有照搬享元模式,Long 内部维护了一个静态的对象池,仅缓存了[-128,127]之间的数字,这个对象池在 JVM 启动的时候就创建好了,而且这个对象池一直都不会变化,也就是说它是静态的。之所以采用这样的设计,是因为 Long 这个对象的状态共有 264 种,实在太多,不宜全部缓存,而[-128,127]之间的数字利用率最高。下面的示例代码出自 Java 1.8,valueOf() 方法就用到了 LongCache 这个缓存,你可以结合着来加深理解。
Long valueOf(long l) {
final int offset = 128;
// [-128,127]直接的数字做了缓存
if (l >= -128 && l <= 127) {
return LongCache
.cache[(int)l + offset];
}
return new Long(l);
}
//缓存,等价于对象池
//仅缓存[-128,127]直接的数字
static class LongCache {
static final Long cache[]
= new Long[-(-128) + 127 + 1];
static {
for(int i=0; i“Integer 和 String 类型的对象不适合做锁”,其实基本上所有的基础类型的包装类都不适合做锁,因为它们内部用到了享元模式,这会导致看上去私有的锁,其实是共有的。例如在下面代码中,本意是 A 用锁 al,B 用锁 bl,各自管理各自的,互不影响。但实际上 al 和 bl 是一个对象,结果 A 和 B 共用的是一把锁。
class A {
Long al=Long.valueOf(1);
public void setAX(){
synchronized (al) {
//省略代码无数
}
}
}
class B {
Long bl=Long.valueOf(1);
public void setBY(){
synchronized (bl) {
//省略代码无数
}
}
}(2)使用 Immutability 模式的注意事项
在使用 Immutability 模式的时候,需要注意以下两点:
① 对象的所有属性都是 final 的,并不能保证不可变性;
② 不可变对象也需要正确发布。
在 Java 语言中,final 修饰的属性一旦被赋值,就不可以再修改,但是如果属性的类型是普通对象,那么这个普通对象的属性是可以被修改的。例如下面的代码中,Bar 的属性 foo 虽然是 final 的,依然可以通过 setAge() 方法来设置 foo 的属性 age。所以,在使用 Immutability 模式的时候一定要确认保持不变性的边界在哪里,是否要求属性对象也具备不可变性。
class Foo{
int age=0;
int name="abc";
}
final class Bar {
final Foo foo;
void setAge(int a){
foo.age=a;
}
}下面我们再看看如何正确地发布不可变对象。不可变对象虽然是线程安全的,但是并不意味着引用这些不可变对象的对象就是线程安全的。例如在下面的代码中,Foo 具备不可变性,线程安全,但是类 Bar 并不是线程安全的,类 Bar 中持有对 Foo 的引用 foo,对 foo 这个引用的修改在多线程中并不能保证可见性和原子性。
//Foo线程安全
final class Foo{
final int age=0;
final int name="abc";
}
//Bar线程不安全
class Bar {
Foo foo;
void setFoo(Foo f){
this.foo=f;
}
}如果你的程序仅仅需要 foo 保持可见性,无需保证原子性,那么可以将 foo 声明为 volatile 变量,这样就能保证可见性。如果你的程序需要保证原子性,那么可以通过原子类来实现。下面的示例代码是合理库存的原子化实现,你应该很熟悉了,其中就是用原子类解决了不可变对象引用的原子性问题。
public class SafeWM {
class WMRange{
final int upper;
final int lower;
WMRange(int upper,int lower){
//省略构造函数实现
}
}
final AtomicReference
rf = new AtomicReference<>(
new WMRange(0,0)
);
// 设置库存上限
void setUpper(int v){
while(true){
WMRange or = rf.get();
// 检查参数合法性
if(v < or.lower){
throw new IllegalArgumentException();
}
WMRange nr = new
WMRange(v, or.lower);
if(rf.compareAndSet(or, nr)){
return;
}
}
}
} 利用 Immutability 模式解决并发问题,也许你觉得有点陌生,其实你天天都在享受它的战果。Java 语言里面的 String 和 Long、Integer、Double 等基础类型的包装类都具备不可变性,这些对象的线程安全性都是靠不可变性来保证的。Immutability 模式是最简单的解决并发问题的方法,建议当你试图解决一个并发问题时,可以首先尝试一下 Immutability 模式,看是否能够快速解决。
具备不变性的对象,只有一种状态,这个状态由对象内部所有的不变属性共同决定。其实还有一种更简单的不变性对象,那就是无状态。无状态对象内部没有属性,只有方法。除了无状态的对象,你可能还听说过无状态的服务、无状态的协议等等。无状态有很多好处,最核心的一点就是性能。在多线程领域,无状态对象没有线程安全问题,无需同步处理,自然性能很好;在分布式领域,无状态意味着可以无限地水平扩展,所以分布式领域里面性能的瓶颈一定不是出在无状态的服务节点上。
2、Copy-on-Write模式:不是延时策略的COW
Java 里 String 这个类在实现 replace() 方法的时候,并没有更改原字符串里面 value[]数组的内容,而是创建了一个新字符串,这种方法在解决不可变对象的修改问题时经常用到。如果你深入地思考这个方法,你会发现它本质上是一种 Copy-on-Write 方法。所谓 Copy-on-Write,经常被缩写为 COW 或者 CoW,顾名思义就是写时复制。
不可变对象的写操作往往都是使用 Copy-on-Write 方法解决的,当然 Copy-on-Write 的应用领域并不局限于 Immutability 模式。下面我们先简单介绍一下 Copy-on-Write 的应用领域,让你对它有个更全面的认识。
(1)Copy-on-Write 模式的应用领域
CopyOnWriteArrayList 和 CopyOnWriteArraySet 这两个 Copy-on-Write 容器,它们背后的设计思想就是 Copy-on-Write;通过 Copy-on-Write 这两个容器实现的读操作是无锁的,由于无锁,所以将读操作的性能发挥到了极致。
除了 Java 这个领域,Copy-on-Write 在操作系统领域也有广泛的应用。
我第一次接触 Copy-on-Write 其实就是在操作系统领域。类 Unix 的操作系统中创建进程的 API 是 fork(),传统的 fork() 函数会创建父进程的一个完整副本,例如父进程的地址空间现在用到了 1G 的内存,那么 fork() 子进程的时候要复制父进程整个进程的地址空间(占有 1G 内存)给子进程,这个过程是很耗时的。而 Linux 中的 fork() 函数就聪明得多了,fork() 子进程的时候,并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间;只用在父进程或者子进程需要写入的时候才会复制地址空间,从而使父子进程拥有各自的地址空间。
本质上来讲,父子进程的地址空间以及数据都是要隔离的,使用 Copy-on-Write 更多地体现的是一种延时策略,只有在真正需要复制的时候才复制,而不是提前复制好,同时 Copy-on-Write 还支持按需复制,所以 Copy-on-Write 在操作系统领域是能够提升性能的。相比较而言,Java 提供的 Copy-on-Write 容器,由于在修改的同时会复制整个容器,所以在提升读操作性能的同时,是以内存复制为代价的。这里你会发现,同样是应用 Copy-on-Write,不同的场景,对性能的影响是不同的。
在操作系统领域,除了创建进程用到了 Copy-on-Write,很多文件系统也同样用到了,例如 Btrfs (B-Tree File System)、aufs(advanced multi-layered unification filesystem)等。
除了上面我们说的 Java 领域、操作系统领域,很多其他领域也都能看到 Copy-on-Write 的身影:Docker 容器镜像的设计是 Copy-on-Write,甚至分布式源码管理系统 Git 背后的设计思想都有 Copy-on-Write……
不过,Copy-on-Write 最大的应用领域还是在函数式编程领域。函数式编程的基础是不可变性(Immutability),所以函数式编程里面所有的修改操作都需要 Copy-on-Write 来解决。你或许会有疑问,“所有数据的修改都需要复制一份,性能是不是会成为瓶颈呢?”你的担忧是有道理的,之所以函数式编程早年间没有兴起,性能绝对拖了后腿。但是随着硬件性能的提升,性能问题已经慢慢变得可以接受了。而且,Copy-on-Write 也远不像 Java 里的 CopyOnWriteArrayList 那样笨:整个数组都复制一遍。Copy-on-Write 也是可以按需复制的,如果你感兴趣可以参考Purely Functional Data Structures这本书,里面描述了各种具备不变性的数据结构的实现。
CopyOnWriteArrayList 和 CopyOnWriteArraySet 这两个 Copy-on-Write 容器在修改的时候会复制整个数组,所以如果容器经常被修改或者这个数组本身就非常大的时候,是不建议使用的。反之,如果是修改非常少、数组数量也不大,并且对读性能要求苛刻的场景,使用 Copy-on-Write 容器效果就非常好了。下面我们结合一个真实的案例来讲解一下。
(2)案例
一个 RPC 框架,有点类似 Dubbo,服务提供方是多实例分布式部署的,所以服务的客户端在调用 RPC 的时候,会选定一个服务实例来调用,这个选定的过程本质上就是在做负载均衡,而做负载均衡的前提是客户端要有全部的路由信息。例如在下图中,A 服务的提供方有 3 个实例,分别是 192.168.1.1、192.168.1.2 和 192.168.1.3,客户端在调用目标服务 A 前,首先需要做的是负载均衡,也就是从这 3 个实例中选出 1 个来,然后再通过 RPC 把请求发送选中的目标实例。

RPC 框架的一个核心任务就是维护服务的路由关系,我们可以把服务的路由关系简化成下图所示的路由表。当服务提供方上线或者下线的时候,就需要更新客户端的这张路由表。
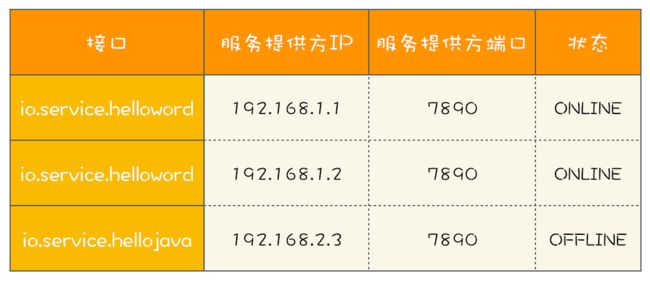
我们首先来分析一下如何用程序来实现。每次 RPC 调用都需要通过负载均衡器来计算目标服务的 IP 和端口号,而负载均衡器需要通过路由表获取接口的所有路由信息,也就是说,每次 RPC 调用都需要访问路由表,所以访问路由表这个操作的性能要求是很高的。不过路由表对数据的一致性要求并不高,一个服务提供方从上线到反馈到客户端的路由表里,即便有 5 秒钟,很多时候也都是能接受的(5 秒钟,对于以纳秒作为时钟周期的 CPU 来说,那何止是一万年,所以路由表对一致性的要求并不高)。而且路由表是典型的读多写少类问题,写操作的量相比于读操作,可谓是沧海一粟,少得可怜。
通过以上分析,你会发现一些关键词:对读的性能要求很高,读多写少,弱一致性。它们综合在一起,你会想到什么呢?CopyOnWriteArrayList 和 CopyOnWriteArraySet 天生就适用这种场景啊。所以下面的示例代码中,RouteTable 这个类内部我们通过ConcurrentHashMap
下面我们再来思考 Router 该如何设计,服务提供方的每一次上线、下线都会更新路由信息,这时候你有两种选择。一种是通过更新 Router 的一个状态位来标识,如果这样做,那么所有访问该状态位的地方都需要同步访问,这样很影响性能。另外一种就是采用 Immutability 模式,每次上线、下线都创建新的 Router 对象或者删除对应的 Router 对象。由于上线、下线的频率很低,所以后者是最好的选择。
Router 的实现代码如下所示,是一种典型 Immutability 模式的实现,需要你注意的是我们重写了 equals 方法,这样 CopyOnWriteArraySet 的 add() 和 remove() 方法才能正常工作。
//路由信息
public final class Router{
private final String ip;
private final Integer port;
private final String iface;
//构造函数
public Router(String ip,
Integer port, String iface){
this.ip = ip;
this.port = port;
this.iface = iface;
}
//重写equals方法
public boolean equals(Object obj){
if (obj instanceof Router) {
Router r = (Router)obj;
return iface.equals(r.iface) &&
ip.equals(r.ip) &&
port.equals(r.port);
}
return false;
}
public int hashCode() {
//省略hashCode相关代码
}
}
//路由表信息
public class RouterTable {
//Key:接口名
//Value:路由集合
ConcurrentHashMap>
rt = new ConcurrentHashMap<>();
//根据接口名获取路由表
public Set get(String iface){
return rt.get(iface);
}
//删除路由
public void remove(Router router) {
Set set=rt.get(router.iface);
if (set != null) {
set.remove(router);
}
}
//增加路由
public void add(Router router) {
Set set = rt.computeIfAbsent(
route.iface, r ->
new CopyOnWriteArraySet<>());
set.add(router);
}
} 目前 Copy-on-Write 在 Java 并发编程领域知名度不是很高,很多人都在无意中把它忽视了,但其实 Copy-on-Write 才是最简单的并发解决方案。它是如此简单,以至于 Java 中的基本数据类型 String、Integer、Long 等都是基于 Copy-on-Write 方案实现的。
Copy-on-Write 是一项非常通用的技术方案,在很多领域都有着广泛的应用。不过,它也有缺点的,那就是消耗内存,每次修改都需要复制一个新的对象出来,好在随着自动垃圾回收(GC)算法的成熟以及硬件的发展,这种内存消耗已经渐渐可以接受了。所以在实际工作中,如果写操作非常少,那你就可以尝试用一下 Copy-on-Write,效果还是不错的。
3、线程本地存储模式:没有共享,就没有伤害
解决并发问题的一个重要方法:避免共享。
我们曾经一遍一遍又一遍地重复,多个线程同时读写同一共享变量存在并发问题。前面两篇文章我们突破的是写,没有写操作自然没有并发问题了。其实还可以突破共享变量,没有共享变量也不会有并发问题,正所谓是没有共享,就没有伤害。
那如何避免共享呢?思路其实很简单,多个人争一个球总容易出矛盾,那就每个人发一个球。对应到并发编程领域,就是每个线程都拥有自己的变量,彼此之间不共享,也就没有并发问题了。
线程封闭,其本质上就是避免共享。你已经知道通过局部变量可以做到避免共享,那还有没有其他方法可以做到呢?有的,Java 语言提供的线程本地存储(ThreadLocal)就能够做到。下面我们先看看 ThreadLocal 到底该如何使用。
(1)ThreadLocal 的使用方法
下面这个静态类 ThreadId 会为每个线程分配一个唯一的线程 Id,如果一个线程前后两次调用 ThreadId 的 get() 方法,两次 get() 方法的返回值是相同的。但如果是两个线程分别调用 ThreadId 的 get() 方法,那么两个线程看到的 get() 方法的返回值是不同的。若你是初次接触 ThreadLocal,可能会觉得奇怪,为什么相同线程调用 get() 方法结果就相同,而不同线程调用 get() 方法结果就不同呢?
static class ThreadId {
static final AtomicLong
nextId=new AtomicLong(0);
//定义ThreadLocal变量
static final ThreadLocal
tl=ThreadLocal.withInitial(
()->nextId.getAndIncrement());
//此方法会为每个线程分配一个唯一的Id
static long get(){
return tl.get();
}
} 能有这个奇怪的结果,都是 ThreadLocal 的杰作,不过在详细解释 ThreadLocal 的工作原理之前,我们再看一个实际工作中可能遇到的例子来加深一下对 ThreadLocal 的理解。你可能知道 SimpleDateFormat 不是线程安全的,那如果需要在并发场景下使用它,你该怎么办呢?
其实有一个办法就是用 ThreadLocal 来解决,下面的示例代码就是 ThreadLocal 解决方案的具体实现,这段代码与前面 ThreadId 的代码高度相似,同样地,不同线程调用 SafeDateFormat 的 get() 方法将返回不同的 SimpleDateFormat 对象实例,由于不同线程并不共享 SimpleDateFormat,所以就像局部变量一样,是线程安全的。
static class SafeDateFormat {
//定义ThreadLocal变量
static final ThreadLocal
tl=ThreadLocal.withInitial(
()-> new SimpleDateFormat(
"yyyy-MM-dd HH:mm:ss"));
static DateFormat get(){
return tl.get();
}
}
//不同线程执行下面代码
//返回的df是不同的
DateFormat df =
SafeDateFormat.get(); 通过上面两个例子,相信你对 ThreadLocal 的用法以及应用场景都了解了,下面我们就来详细解释 ThreadLocal 的工作原理。
(2)ThreadLocal 的工作原理
在解释 ThreadLocal 的工作原理之前, 你先自己想想:如果让你来实现 ThreadLocal 的功能,你会怎么设计呢?ThreadLocal 的目标是让不同的线程有不同的变量 V,那最直接的方法就是创建一个 Map,它的 Key 是线程,Value 是每个线程拥有的变量 V,ThreadLocal 内部持有这样的一个 Map 就可以了。你可以参考下面的示意图和示例代码来理解。

class MyThreadLocal {
Map locals =
new ConcurrentHashMap<>();
//获取线程变量
T get() {
return locals.get(
Thread.currentThread());
}
//设置线程变量
void set(T t) {
locals.put(
Thread.currentThread(), t);
}
} 那 Java 的 ThreadLocal 是这么实现的吗?这一次我们的设计思路和 Java 的实现差异很大。Java 的实现里面也有一个 Map,叫做 ThreadLocalMap,不过持有 ThreadLocalMap 的不是 ThreadLocal,而是 Thread。Thread 这个类内部有一个私有属性 threadLocals,其类型就是 ThreadLocalMap,ThreadLocalMap 的 Key 是 ThreadLocal。你可以结合下面的示意图和精简之后的 Java 实现代码来理解。
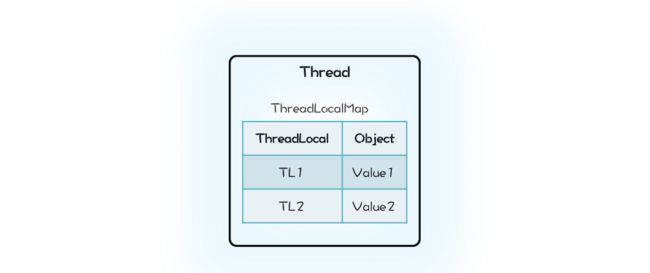
class Thread {
//内部持有ThreadLocalMap
ThreadLocal.ThreadLocalMap
threadLocals;
}
class ThreadLocal{
public T get() {
//首先获取线程持有的
//ThreadLocalMap
ThreadLocalMap map =
Thread.currentThread()
.threadLocals;
//在ThreadLocalMap中
//查找变量
Entry e =
map.getEntry(this);
return e.value;
}
static class ThreadLocalMap{
//内部是数组而不是Map
Entry[] table;
//根据ThreadLocal查找Entry
Entry getEntry(ThreadLocal key){
//省略查找逻辑
}
//Entry定义
static class Entry extends
WeakReference{
Object value;
}
}
} 初看上去,我们的设计方案和 Java 的实现仅仅是 Map 的持有方不同而已,我们的设计里面 Map 属于 ThreadLocal,而 Java 的实现里面 ThreadLocalMap 则是属于 Thread。这两种方式哪种更合理呢?很显然 Java 的实现更合理一些。在 Java 的实现方案里面,ThreadLocal 仅仅是一个代理工具类,内部并不持有任何与线程相关的数据,所有和线程相关的数据都存储在 Thread 里面,这样的设计容易理解。而从数据的亲缘性上来讲,ThreadLocalMap 属于 Thread 也更加合理。
当然还有一个更加深层次的原因,那就是不容易产生内存泄露。在我们的设计方案中,ThreadLocal 持有的 Map 会持有 Thread 对象的引用,这就意味着,只要 ThreadLocal 对象存在,那么 Map 中的 Thread 对象就永远不会被回收。ThreadLocal 的生命周期往往都比线程要长,所以这种设计方案很容易导致内存泄露。而 Java 的实现中 Thread 持有 ThreadLocalMap,而且 ThreadLocalMap 里对 ThreadLocal 的引用还是弱引用(WeakReference),所以只要 Thread 对象可以被回收,那么 ThreadLocalMap 就能被回收。Java 的这种实现方案虽然看上去复杂一些,但是更加安全。
Java 的 ThreadLocal 实现应该称得上深思熟虑了,不过即便如此深思熟虑,还是不能百分百地让程序员避免内存泄露,例如在线程池中使用 ThreadLocal,如果不谨慎就可能导致内存泄露。
(3)ThreadLocal 与内存泄露
在线程池中使用 ThreadLocal 为什么可能导致内存泄露呢?原因就出在线程池中线程的存活时间太长,往往都是和程序同生共死的,这就意味着 Thread 持有的 ThreadLocalMap 一直都不会被回收,再加上 ThreadLocalMap 中的 Entry 对 ThreadLocal 是弱引用(WeakReference),所以只要 ThreadLocal 结束了自己的生命周期是可以被回收掉的。但是 Entry 中的 Value 却是被 Entry 强引用的,所以即便 Value 的生命周期结束了,Value 也是无法被回收的,从而导致内存泄露。
那在线程池中,我们该如何正确使用 ThreadLocal 呢?其实很简单,既然 JVM 不能做到自动释放对 Value 的强引用,那我们手动释放就可以了。如何能做到手动释放呢?估计你马上想到 try{}finally{}方案了,这个简直就是手动释放资源的利器。示例的代码如下,你可以参考学习。
ExecutorService es;
ThreadLocal tl;
es.execute(()->{
//ThreadLocal增加变量
tl.set(obj);
try {
// 省略业务逻辑代码
}finally {
//手动清理ThreadLocal
tl.remove();
}
});(4)InheritableThreadLocal 与继承性
通过 ThreadLocal 创建的线程变量,其子线程是无法继承的。也就是说你在线程中通过 ThreadLocal 创建了线程变量 V,而后该线程创建了子线程,你在子线程中是无法通过 ThreadLocal 来访问父线程的线程变量 V 的。
如果你需要子线程继承父线程的线程变量,那该怎么办呢?其实很简单,Java 提供了 InheritableThreadLocal 来支持这种特性,InheritableThreadLocal 是 ThreadLocal 子类,所以用法和 ThreadLocal 相同,这里就不多介绍了。
不过,我完全不建议你在线程池中使用 InheritableThreadLocal,不仅仅是因为它具有 ThreadLocal 相同的缺点——可能导致内存泄露,更重要的原因是:线程池中线程的创建是动态的,很容易导致继承关系错乱,如果你的业务逻辑依赖 InheritableThreadLocal,那么很可能导致业务逻辑计算错误,而这个错误往往比内存泄露更要命。
线程本地存储模式本质上是一种避免共享的方案,由于没有共享,所以自然也就没有并发问题。如果你需要在并发场景中使用一个线程不安全的工具类,最简单的方案就是避免共享。避免共享有两种方案,一种方案是将这个工具类作为局部变量使用,另外一种方案就是线程本地存储模式。这两种方案,局部变量方案的缺点是在高并发场景下会频繁创建对象,而线程本地存储方案,每个线程只需要创建一个工具类的实例,所以不存在频繁创建对象的问题。
线程本地存储模式是解决并发问题的常用方案,所以 Java SDK 也提供了相应的实现:ThreadLocal。通过上面我们的分析,你应该能体会到 Java SDK 的实现已经是深思熟虑了,不过即便如此,仍不能尽善尽美,例如在线程池中使用 ThreadLocal 仍可能导致内存泄漏,所以使用 ThreadLocal 还是需要你打起精神,足够谨慎。
4、Guarded Suspension模式:等待唤醒机制的规范实现
前不久,同事小灰工作中遇到一个问题,他开发了一个 Web 项目:Web 版的文件浏览器,通过它用户可以在浏览器里查看服务器上的目录和文件。这个项目依赖运维部门提供的文件浏览服务,而这个文件浏览服务只支持消息队列(MQ)方式接入。消息队列在互联网大厂中用的非常多,主要用作流量削峰和系统解耦。在这种接入方式中,发送消息和消费结果这两个操作之间是异步的,你可以参考下面的示意图来理解。
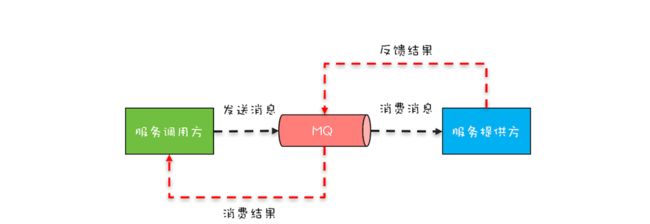
在小灰的这个 Web 项目中,用户通过浏览器发过来一个请求,会被转换成一个异步消息发送给 MQ,等 MQ 返回结果后,再将这个结果返回至浏览器。小灰同学的问题是:给 MQ 发送消息的线程是处理 Web 请求的线程 T1,但消费 MQ 结果的线程并不是线程 T1,那线程 T1 如何等待 MQ 的返回结果呢?为了便于你理解这个场景,我将其代码化了,示例代码如下。
class Message{
String id;
String content;
}
//该方法可以发送消息
void send(Message msg){
//省略相关代码
}
//MQ消息返回后会调用该方法
//该方法的执行线程不同于
//发送消息的线程
void onMessage(Message msg){
//省略相关代码
}
//处理浏览器发来的请求
Respond handleWebReq(){
//创建一消息
Message msg1 = new
Message("1","{...}");
//发送消息
send(msg1);
//如何等待MQ返回的消息呢?
String result = ...;
}异步转同步问题吗?仔细分析,的确是这样,不过在那一篇文章中我们只是介绍了最终方案,让你知其然,但是并没有介绍这个方案是如何设计出来的,今天咱们再仔细聊聊这个问题,让你知其所以然,遇到类似问题也能自己设计出方案来。
(1)Guarded Suspension 模式
上面小灰遇到的问题,在现实世界里比比皆是,只是我们一不小心就忽略了。比如,项目组团建要外出聚餐,我们提前预订了一个包间,然后兴冲冲地奔过去,到那儿后大堂经理看了一眼包间,发现服务员正在收拾,就会告诉我们:“您预订的包间服务员正在收拾,请您稍等片刻。”过了一会,大堂经理发现包间已经收拾完了,于是马上带我们去包间就餐。
我们等待包间收拾完的这个过程和小灰遇到的等待 MQ 返回消息本质上是一样的,都是等待一个条件满足:就餐需要等待包间收拾完,小灰的程序里要等待 MQ 返回消息。
那我们来看看现实世界里是如何解决这类问题的呢?现实世界里大堂经理这个角色很重要,我们是否等待,完全是由他来协调的。通过类比,相信你也一定有思路了:我们的程序里,也需要这样一个大堂经理。的确是这样,那程序世界里的大堂经理该如何设计呢?其实设计方案前人早就搞定了,而且还将其总结成了一个设计模式:Guarded Suspension。所谓 Guarded Suspension,直译过来就是“保护性地暂停”。那下面我们就来看看,Guarded Suspension 模式是如何模拟大堂经理进行保护性地暂停的。
下图就是 Guarded Suspension 模式的结构图,非常简单,一个对象 GuardedObject,内部有一个成员变量——受保护的对象,以及两个成员方法——get(Predicate p)和onChanged(T obj)方法。其中,对象 GuardedObject 就是我们前面提到的大堂经理,受保护对象就是餐厅里面的包间;受保护对象的 get() 方法对应的是我们的就餐,就餐的前提条件是包间已经收拾好了,参数 p 就是用来描述这个前提条件的;受保护对象的 onChanged() 方法对应的是服务员把包间收拾好了,通过 onChanged() 方法可以 fire 一个事件,而这个事件往往能改变前提条件 p 的计算结果。下图中,左侧的绿色线程就是需要就餐的顾客,而右侧的蓝色线程就是收拾包间的服务员。

GuardedObject 的内部实现非常简单,是管程的一个经典用法,你可以参考下面的示例代码,核心是:get() 方法通过条件变量的 await() 方法实现等待,onChanged() 方法通过条件变量的 signalAll() 方法实现唤醒功能。逻辑还是很简单的,所以这里就不再详细介绍了。
class GuardedObject{
//受保护的对象
T obj;
final Lock lock =
new ReentrantLock();
final Condition done =
lock.newCondition();
final int timeout=1;
//获取受保护对象
T get(Predicate p) {
lock.lock();
try {
//MESA管程推荐写法
while(!p.test(obj)){
done.await(timeout,
TimeUnit.SECONDS);
}
}catch(InterruptedException e){
throw new RuntimeException(e);
}finally{
lock.unlock();
}
//返回非空的受保护对象
return obj;
}
//事件通知方法
void onChanged(T obj) {
lock.lock();
try {
this.obj = obj;
done.signalAll();
} finally {
lock.unlock();
}
}
} (2)扩展 Guarded Suspension 模式
上面我们介绍了 Guarded Suspension 模式及其实现,这个模式能够模拟现实世界里大堂经理的角色,那现在我们再来看看这个“大堂经理”能否解决小灰同学遇到的问题。
Guarded Suspension 模式里 GuardedObject 有两个核心方法,一个是 get() 方法,一个是 onChanged() 方法。很显然,在处理 Web 请求的方法 handleWebReq() 中,可以调用 GuardedObject 的 get() 方法来实现等待;在 MQ 消息的消费方法 onMessage() 中,可以调用 GuardedObject 的 onChanged() 方法来实现唤醒。
//处理浏览器发来的请求
Respond handleWebReq(){
//创建一消息
Message msg1 = new
Message("1","{...}");
//发送消息
send(msg1);
//利用GuardedObject实现等待
GuardedObject go
=new GuardObjec<>();
Message r = go.get(
t->t != null);
}
void onMessage(Message msg){
//如何找到匹配的go?
GuardedObject go=???
go.onChanged(msg);
} 但是在实现的时候会遇到一个问题,handleWebReq() 里面创建了 GuardedObject 对象的实例 go,并调用其 get() 方等待结果,那在 onMessage() 方法中,如何才能够找到匹配的 GuardedObject 对象呢?这个过程类似服务员告诉大堂经理某某包间已经收拾好了,大堂经理如何根据包间找到就餐的人。现实世界里,大堂经理的头脑中,有包间和就餐人之间的关系图,所以服务员说完之后大堂经理立刻就能把就餐人找出来。
我们可以参考大堂经理识别就餐人的办法,来扩展一下 Guarded Suspension 模式,从而使它能够很方便地解决小灰同学的问题。在小灰的程序中,每个发送到 MQ 的消息,都有一个唯一性的属性 id,所以我们可以维护一个 MQ 消息 id 和 GuardedObject 对象实例的关系,这个关系可以类比大堂经理大脑里维护的包间和就餐人的关系。
有了这个关系,我们来看看具体如何实现。下面的示例代码是扩展 Guarded Suspension 模式的实现,扩展后的 GuardedObject 内部维护了一个 Map,其 Key 是 MQ 消息 id,而 Value 是 GuardedObject 对象实例,同时增加了静态方法 create() 和 fireEvent();create() 方法用来创建一个 GuardedObject 对象实例,并根据 key 值将其加入到 Map 中,而 fireEvent() 方法则是模拟的大堂经理根据包间找就餐人的逻辑。
class GuardedObject{
//受保护的对象
T obj;
final Lock lock =
new ReentrantLock();
final Condition done =
lock.newCondition();
final int timeout=2;
//保存所有GuardedObject
final static Map
gos=new ConcurrentHashMap<>();
//静态方法创建GuardedObject
static GuardedObject
create(K key){
GuardedObject go=new GuardedObject();
gos.put(key, go);
return go;
}
static void
fireEvent(K key, T obj){
GuardedObject go=gos.remove(key);
if (go != null){
go.onChanged(obj);
}
}
//获取受保护对象
T get(Predicate p) {
lock.lock();
try {
//MESA管程推荐写法
while(!p.test(obj)){
done.await(timeout,
TimeUnit.SECONDS);
}
}catch(InterruptedException e){
throw new RuntimeException(e);
}finally{
lock.unlock();
}
//返回非空的受保护对象
return obj;
}
//事件通知方法
void onChanged(T obj) {
lock.lock();
try {
this.obj = obj;
done.signalAll();
} finally {
lock.unlock();
}
}
} 这样利用扩展后的 GuardedObject 来解决小灰同学的问题就很简单了,具体代码如下所示。
//处理浏览器发来的请求
Respond handleWebReq(){
int id=序号生成器.get();
//创建一消息
Message msg1 = new
Message(id,"{...}");
//创建GuardedObject实例
GuardedObject go=
GuardedObject.create(id);
//发送消息
send(msg1);
//等待MQ消息
Message r = go.get(
t->t != null);
}
void onMessage(Message msg){
//唤醒等待的线程
GuardedObject.fireEvent(
msg.id, msg);
} Guarded Suspension 模式本质上是一种等待唤醒机制的实现,只不过 Guarded Suspension 模式将其规范化了。规范化的好处是你无需重头思考如何实现,也无需担心实现程序的可理解性问题,同时也能避免一不小心写出个 Bug 来。但 Guarded Suspension 模式在解决实际问题的时候,往往还是需要扩展的,扩展的方式有很多,本篇文章就直接对 GuardedObject 的功能进行了增强,Dubbo 中 DefaultFuture 这个类也是采用的这种方式,你可以对比着来看,相信对 DefaultFuture 的实现原理会理解得更透彻。当然,你也可以创建新的类来实现对 Guarded Suspension 模式的扩展。
Guarded Suspension 模式也常被称作 Guarded Wait 模式、Spin Lock 模式(因为使用了 while 循环去等待),这些名字都很形象,不过它还有一个更形象的非官方名字:多线程版本的 if。单线程场景中,if 语句是不需要等待的,因为在只有一个线程的条件下,如果这个线程被阻塞,那就没有其他活动线程了,这意味着 if 判断条件的结果也不会发生变化了。但是多线程场景中,等待就变得有意义了,这种场景下,if 判断条件的结果是可能发生变化的。所以,用“多线程版本的 if”来理解这个模式会更简单。
5、Balking模式:再谈线程安全的单例模式
“多线程版本的 if”来理解 Guarded Suspension 模式,不同于单线程中的 if,这个“多线程版本的 if”是需要等待的,而且还很执着,必须要等到条件为真。但很显然这个世界,不是所有场景都需要这么执着,有时候我们还需要快速放弃。
需要快速放弃的一个最常见的例子是各种编辑器提供的自动保存功能。自动保存功能的实现逻辑一般都是隔一定时间自动执行存盘操作,存盘操作的前提是文件做过修改,如果文件没有执行过修改操作,就需要快速放弃存盘操作。下面的示例代码将自动保存功能代码化了,很显然 AutoSaveEditor 这个类不是线程安全的,因为对共享变量 changed 的读写没有使用同步,那如何保证 AutoSaveEditor 的线程安全性呢?
class AutoSaveEditor{
//文件是否被修改过
boolean changed=false;
//定时任务线程池
ScheduledExecutorService ses =
Executors.newSingleThreadScheduledExecutor();
//定时执行自动保存
void startAutoSave(){
ses.scheduleWithFixedDelay(()->{
autoSave();
}, 5, 5, TimeUnit.SECONDS);
}
//自动存盘操作
void autoSave(){
if (!changed) {
return;
}
changed = false;
//执行存盘操作
//省略且实现
this.execSave();
}
//编辑操作
void edit(){
//省略编辑逻辑
......
changed = true;
}
}解决这个问题相信你一定手到擒来了:读写共享变量 changed 的方法 autoSave() 和 edit() 都加互斥锁就可以了。这样做虽然简单,但是性能很差,原因是锁的范围太大了。那我们可以将锁的范围缩小,只在读写共享变量 changed 的地方加锁,实现代码如下所示。
//自动存盘操作
void autoSave(){
synchronized(this){
if (!changed) {
return;
}
changed = false;
}
//执行存盘操作
//省略且实现
this.execSave();
}
//编辑操作
void edit(){
//省略编辑逻辑
......
synchronized(this){
changed = true;
}
} 如果你深入地分析一下这个示例程序,你会发现,示例中的共享变量是一个状态变量,业务逻辑依赖于这个状态变量的状态:当状态满足某个条件时,执行某个业务逻辑,其本质其实不过就是一个 if 而已,放到多线程场景里,就是一种“多线程版本的 if”。这种“多线程版本的 if”的应用场景还是很多的,所以也有人把它总结成了一种设计模式,叫做 Balking 模式。
(1)Balking 模式的经典实现
Balking 模式本质上是一种规范化地解决“多线程版本的 if”的方案,对于上面自动保存的例子,使用 Balking 模式规范化之后的写法如下所示,你会发现仅仅是将 edit() 方法中对共享变量 changed 的赋值操作抽取到了 change() 中,这样的好处是将并发处理逻辑和业务逻辑分开。
boolean changed=false;
//自动存盘操作
void autoSave(){
synchronized(this){
if (!changed) {
return;
}
changed = false;
}
//执行存盘操作
//省略且实现
this.execSave();
}
//编辑操作
void edit(){
//省略编辑逻辑
......
change();
}
//改变状态
void change(){
synchronized(this){
changed = true;
}
}(2)用 volatile 实现 Balking 模式
前面我们用 synchronized 实现了 Balking 模式,这种实现方式最为稳妥,建议你实际工作中也使用这个方案。不过在某些特定场景下,也可以使用 volatile 来实现,但使用 volatile 的前提是对原子性没有要求。
有一个 RPC 框架路由表的案例,在 RPC 框架中,本地路由表是要和注册中心进行信息同步的,应用启动的时候,会将应用依赖服务的路由表从注册中心同步到本地路由表中,如果应用重启的时候注册中心宕机,那么会导致该应用依赖的服务均不可用,因为找不到依赖服务的路由表。为了防止这种极端情况出现,RPC 框架可以将本地路由表自动保存到本地文件中,如果重启的时候注册中心宕机,那么就从本地文件中恢复重启前的路由表。这其实也是一种降级的方案。
自动保存路由表和前面介绍的编辑器自动保存原理是一样的,也可以用 Balking 模式实现,不过我们这里采用 volatile 来实现,实现的代码如下所示。之所以可以采用 volatile 来实现,是因为对共享变量 changed 和 rt 的写操作不存在原子性的要求,而且采用 scheduleWithFixedDelay() 这种调度方式能保证同一时刻只有一个线程执行 autoSave() 方法。
//路由表信息
public class RouterTable {
//Key:接口名
//Value:路由集合
ConcurrentHashMap>
rt = new ConcurrentHashMap<>();
//路由表是否发生变化
volatile boolean changed;
//将路由表写入本地文件的线程池
ScheduledExecutorService ses=
Executors.newSingleThreadScheduledExecutor();
//启动定时任务
//将变更后的路由表写入本地文件
public void startLocalSaver(){
ses.scheduleWithFixedDelay(()->{
autoSave();
}, 1, 1, MINUTES);
}
//保存路由表到本地文件
void autoSave() {
if (!changed) {
return;
}
changed = false;
//将路由表写入本地文件
//省略其方法实现
this.save2Local();
}
//删除路由
public void remove(Router router) {
Set set=rt.get(router.iface);
if (set != null) {
set.remove(router);
//路由表已发生变化
changed = true;
}
}
//增加路由
public void add(Router router) {
Set set = rt.computeIfAbsent(
route.iface, r ->
new CopyOnWriteArraySet<>());
set.add(router);
//路由表已发生变化
changed = true;
}
} Balking 模式有一个非常典型的应用场景就是单次初始化,下面的示例代码是它的实现。这个实现方案中,我们将 init() 声明为一个同步方法,这样同一个时刻就只有一个线程能够执行 init() 方法;init() 方法在第一次执行完时会将 inited 设置为 true,这样后续执行 init() 方法的线程就不会再执行 doInit() 了。
class InitTest{
boolean inited = false;
synchronized void init(){
if(inited){
return;
}
//省略doInit的实现
doInit();
inited=true;
}
}线程安全的单例模式本质上其实也是单次初始化,所以可以用 Balking 模式来实现线程安全的单例模式,下面的示例代码是其实现。这个实现虽然功能上没有问题,但是性能却很差,因为互斥锁 synchronized 将 getInstance() 方法串行化了,那有没有办法可以优化一下它的性能呢?
class Singleton{
private static
Singleton singleton;
//构造方法私有化
private Singleton(){}
//获取实例(单例)
public synchronized static
Singleton getInstance(){
if(singleton == null){
singleton=new Singleton();
}
return singleton;
}
}办法当然是有的,那就是经典的双重检查(Double Check)方案,下面的示例代码是其详细实现。在双重检查方案中,一旦 Singleton 对象被成功创建之后,就不会执行 synchronized(Singleton.class){}相关的代码,也就是说,此时 getInstance() 方法的执行路径是无锁的,从而解决了性能问题。不过需要你注意的是,这个方案中使用了 volatile 来禁止编译优化,其原因你可以参考《01 | 可见性、原子性和有序性问题:并发编程 Bug 的源头》中相关的内容。至于获取锁后的二次检查,则是出于对安全性负责。
class Singleton{
private static volatile
Singleton singleton;
//构造方法私有化
private Singleton() {}
//获取实例(单例)
public static Singleton
getInstance() {
//第一次检查
if(singleton==null){
synchronize(Singleton.class){
//获取锁后二次检查
if(singleton==null){
singleton=new Singleton();
}
}
}
return singleton;
}
}Balking 模式和 Guarded Suspension 模式从实现上看似乎没有多大的关系,Balking 模式只需要用互斥锁就能解决,而 Guarded Suspension 模式则要用到管程这种高级的并发原语;但是从应用的角度来看,它们解决的都是“线程安全的 if”语义,不同之处在于,Guarded Suspension 模式会等待 if 条件为真,而 Balking 模式不会等待。
Balking 模式的经典实现是使用互斥锁,你可以使用 Java 语言内置 synchronized,也可以使用 SDK 提供 Lock;如果你对互斥锁的性能不满意,可以尝试采用 volatile 方案,不过使用 volatile 方案需要你更加谨慎。
当然你也可以尝试使用双重检查方案来优化性能,双重检查中的第一次检查,完全是出于对性能的考量:避免执行加锁操作,因为加锁操作很耗时。而加锁之后的二次检查,则是出于对安全性负责。双重检查方案在优化加锁性能方面经常用到,例如实现缓存按需加载功能时,也用到了双重检查方案。
6、Thread-Per-Message模式:最简单实用的分工方法
我们曾经把并发编程领域的问题总结为三个核心问题:分工、同步和互斥。其中,同步和互斥相关问题更多地源自微观,而分工问题则是源自宏观。我们解决问题,往往都是从宏观入手,在编程领域,软件的设计过程也是先从概要设计开始,而后才进行详细设计。同样,解决并发编程问题,首要问题也是解决宏观的分工问题。
并发编程领域里,解决分工问题也有一系列的设计模式,比较常用的主要有 Thread-Per-Message 模式、Worker Thread 模式、生产者 - 消费者模式等等。今天我们重点介绍 Thread-Per-Message 模式。
(1)如何理解 Thread-Per-Message 模式
现实世界里,很多事情我们都需要委托他人办理,一方面受限于我们的能力,总有很多搞不定的事,比如教育小朋友,搞不定怎么办呢?只能委托学校老师了;另一方面受限于我们的时间,比如忙着写 Bug,哪有时间买别墅呢?只能委托房产中介了。委托他人代办有一个非常大的好处,那就是可以专心做自己的事了。
在编程领域也有很多类似的需求,比如写一个 HTTP Server,很显然只能在主线程中接收请求,而不能处理 HTTP 请求,因为如果在主线程中处理 HTTP 请求的话,那同一时间只能处理一个请求,太慢了!怎么办呢?可以利用代办的思路,创建一个子线程,委托子线程去处理 HTTP 请求。
这种委托他人办理的方式,在并发编程领域被总结为一种设计模式,叫做 Thread-Per-Message 模式,简言之就是为每个任务分配一个独立的线程。这是一种最简单的分工方法,实现起来也非常简单。
(2)用 Thread 实现 Thread-Per-Message 模式
Thread-Per-Message 模式的一个最经典的应用场景是网络编程里服务端的实现,服务端为每个客户端请求创建一个独立的线程,当线程处理完请求后,自动销毁,这是一种最简单的并发处理网络请求的方法。
网络编程里最简单的程序当数 echo 程序了,echo 程序的服务端会原封不动地将客户端的请求发送回客户端。例如,客户端发送 TCP 请求"Hello World",那么服务端也会返回"Hello World"。
下面我们就以 echo 程序的服务端为例,介绍如何实现 Thread-Per-Message 模式。
在 Java 语言中,实现 echo 程序的服务端还是很简单的。只需要 30 行代码就能够实现,示例代码如下,我们为每个请求都创建了一个 Java 线程,核心代码是:new Thread(()->{...}).start()。
final ServerSocketChannel =
ServerSocketChannel.open().bind(
new InetSocketAddress(8080));
//处理请求
try {
while (true) {
// 接收请求
SocketChannel sc = ssc.accept();
// 每个请求都创建一个线程
new Thread(()->{
try {
// 读Socket
ByteBuffer rb = ByteBuffer
.allocateDirect(1024);
sc.read(rb);
//模拟处理请求
Thread.sleep(2000);
// 写Socket
ByteBuffer wb =
(ByteBuffer)rb.flip();
sc.write(wb);
// 关闭Socket
sc.close();
}catch(Exception e){
throw new UncheckedIOException(e);
}
}).start();
}
} finally {
ssc.close();
} 如果你熟悉网络编程,相信你一定会提出一个很尖锐的问题:上面这个 echo 服务的实现方案是不具备可行性的。原因在于 Java 中的线程是一个重量级的对象,创建成本很高,一方面创建线程比较耗时,另一方面线程占用的内存也比较大。所以,为每个请求创建一个新的线程并不适合高并发场景。
于是,你开始质疑 Thread-Per-Message 模式,而且开始重新思索解决方案,这时候很可能你会想到 Java 提供的线程池。你的这个思路没有问题,但是引入线程池难免会增加复杂度。其实你完全可以换一个角度来思考这个问题,语言、工具、框架本身应该是帮助我们更敏捷地实现方案的,而不是用来否定方案的,Thread-Per-Message 模式作为一种最简单的分工方案,Java 语言支持不了,显然是 Java 语言本身的问题。
Java 语言里,Java 线程是和操作系统线程一一对应的,这种做法本质上是将 Java 线程的调度权完全委托给操作系统,而操作系统在这方面非常成熟,所以这种做法的好处是稳定、可靠,但是也继承了操作系统线程的缺点:创建成本高。为了解决这个缺点,Java 并发包里提供了线程池等工具类。这个思路在很长一段时间里都是很稳妥的方案,但是这个方案并不是唯一的方案。
业界还有另外一种方案,叫做轻量级线程。这个方案在 Java 领域知名度并不高,但是在其他编程语言里却叫得很响,例如 Go 语言、Lua 语言里的协程,本质上就是一种轻量级的线程。轻量级的线程,创建的成本很低,基本上和创建一个普通对象的成本相似;并且创建的速度和内存占用相比操作系统线程至少有一个数量级的提升,所以基于轻量级线程实现 Thread-Per-Message 模式就完全没有问题了。
Java 语言目前也已经意识到轻量级线程的重要性了,OpenJDK 有个 Loom 项目,就是要解决 Java 语言的轻量级线程问题,在这个项目中,轻量级线程被叫做 Fiber。下面我们就来看看基于 Fiber 如何实现 Thread-Per-Message 模式。
(3)用 Fiber 实现 Thread-Per-Message 模式
Loom 项目在设计轻量级线程时,充分考量了当前 Java 线程的使用方式,采取的是尽量兼容的态度,所以使用上还是挺简单的。用 Fiber 实现 echo 服务的示例代码如下所示,对比 Thread 的实现,你会发现改动量非常小,只需要把 new Thread(()->{...}).start() 换成 Fiber.schedule(()->{}) 就可以了。
final ServerSocketChannel ssc =
ServerSocketChannel.open().bind(
new InetSocketAddress(8080));
//处理请求
try{
while (true) {
// 接收请求
final SocketChannel sc =
ssc.accept();
Fiber.schedule(()->{
try {
// 读Socket
ByteBuffer rb = ByteBuffer
.allocateDirect(1024);
sc.read(rb);
//模拟处理请求
LockSupport.parkNanos(2000*1000000);
// 写Socket
ByteBuffer wb =
(ByteBuffer)rb.flip()
sc.write(wb);
// 关闭Socket
sc.close();
} catch(Exception e){
throw new UncheckedIOException(e);
}
});
}//while
}finally{
ssc.close();
}那使用 Fiber 实现的 echo 服务是否能够达到预期的效果呢?我们可以在 Linux 环境下做一个简单的实验,步骤如下:
1、首先通过 ulimit -u 512 将用户能创建的最大进程数(包括线程)设置为 512;
2、启动 Fiber 实现的 echo 程序;
3、利用压测工具 ab 进行压测:ab -r -c 20000 -n 200000 http:// 测试机 IP 地址:8080/
压测执行结果如下:
Concurrency Level: 20000
Time taken for tests: 67.718 seconds
Complete requests: 200000
Failed requests: 0
Write errors: 0
Non-2xx responses: 200000
Total transferred: 16400000 bytes
HTML transferred: 0 bytes
Requests per second: 2953.41 [#/sec] (mean)
Time per request: 6771.844 [ms] (mean)
Time per request: 0.339 [ms] (mean, across all concurrent requests)
Transfer rate: 236.50 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 557 3541.6 1 63127
Processing: 2000 2010 31.8 2003 2615
Waiting: 1986 2008 30.9 2002 2615
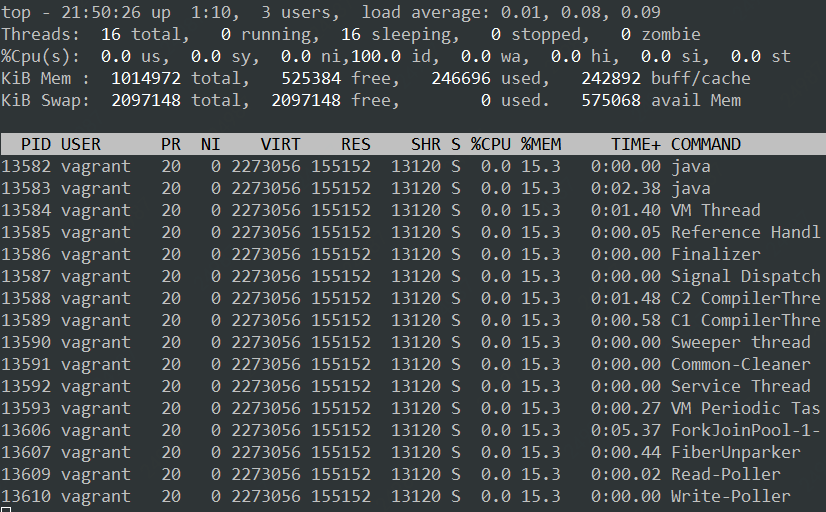
Total: 2000 2567 3543.9 2004 65293你会发现即便在 20000 并发下,该程序依然能够良好运行。同等条件下,Thread 实现的 echo 程序 512 并发都抗不过去,直接就 OOM 了。
如果你通过 Linux 命令 top -Hp pid 查看 Fiber 实现的 echo 程序的进程信息,你可以看到该进程仅仅创建了 16(不同 CPU 核数结果会不同)个操作系统线程。
并发编程领域的分工问题,指的是如何高效地拆解任务并分配给线程。前面我们在并发工具类模块中已经介绍了不少解决分工问题的工具类,例如 Future、CompletableFuture 、CompletionService、Fork/Join 计算框架等,这些工具类都能很好地解决特定应用场景的问题,所以,这些工具类曾经是 Java 语言引以为傲的。不过这些工具类都继承了 Java 语言的老毛病:太复杂。
如果你一直从事 Java 开发,估计你已经习以为常了,习惯性地认为这个复杂度是正常的。不过这个世界时刻都在变化,曾经正常的复杂度,现在看来也许就已经没有必要了,例如 Thread-Per-Message 模式如果使用线程池方案就会增加复杂度。
Thread-Per-Message 模式在 Java 领域并不是那么知名,根本原因在于 Java 语言里的线程是一个重量级的对象,为每一个任务创建一个线程成本太高,尤其是在高并发领域,基本就不具备可行性。不过这个背景条件目前正在发生巨变,Java 语言未来一定会提供轻量级线程,这样基于轻量级线程实现 Thread-Per-Message 模式就是一个非常靠谱的选择。
当然,对于一些并发度没那么高的异步场景,例如定时任务,采用 Thread-Per-Message 模式是完全没有问题的。实际工作中,我就见过完全基于 Thread-Per-Message 模式实现的分布式调度框架,这个框架为每个定时任务都分配了一个独立的线程。
7、Worker Thread模式:如何避免重复创建线程?
我们介绍了一种最简单的分工模式——Thread-Per-Message 模式,对应到现实世界,其实就是委托代办。这种分工模式如果用 Java Thread 实现,频繁地创建、销毁线程非常影响性能,同时无限制地创建线程还可能导致 OOM,所以在 Java 领域使用场景就受限了。
要想有效避免线程的频繁创建、销毁以及 OOM 问题,就不得不提今天我们要细聊的,也是 Java 领域使用最多的 Worker Thread 模式。
(1)Worker Thread 模式及其实现
Worker Thread 模式可以类比现实世界里车间的工作模式:车间里的工人,有活儿了,大家一起干,没活儿了就聊聊天等着。你可以参考下面的示意图来理解,Worker Thread 模式中 Worker Thread 对应到现实世界里,其实指的就是车间里的工人。不过这里需要注意的是,车间里的工人数量往往是确定的。
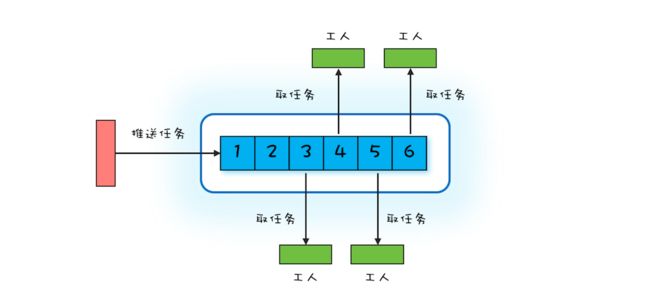
那在编程领域该如何模拟车间的这种工作模式呢?或者说如何去实现 Worker Thread 模式呢?通过上面的图,你很容易就能想到用阻塞队列做任务池,然后创建固定数量的线程消费阻塞队列中的任务。其实你仔细想会发现,这个方案就是 Java 语言提供的线程池。
线程池有很多优点,例如能够避免重复创建、销毁线程,同时能够限制创建线程的上限等等。学习完上一篇文章后你已经知道,用 Java 的 Thread 实现 Thread-Per-Message 模式难以应对高并发场景,原因就在于频繁创建、销毁 Java 线程的成本有点高,而且无限制地创建线程还可能导致应用 OOM。线程池,则恰好能解决这些问题。
那我们还是以 echo 程序为例,看看如何用线程池来实现。
下面的示例代码是用线程池实现的 echo 服务端,相比于 Thread-Per-Message 模式的实现,改动非常少,仅仅是创建了一个最多线程数为 500 的线程池 es,然后通过 es.execute() 方法将请求处理的任务提交给线程池处理。
ExecutorService es = Executors
.newFixedThreadPool(500);
final ServerSocketChannel ssc =
ServerSocketChannel.open().bind(
new InetSocketAddress(8080));
//处理请求
try {
while (true) {
// 接收请求
SocketChannel sc = ssc.accept();
// 将请求处理任务提交给线程池
es.execute(()->{
try {
// 读Socket
ByteBuffer rb = ByteBuffer
.allocateDirect(1024);
sc.read(rb);
//模拟处理请求
Thread.sleep(2000);
// 写Socket
ByteBuffer wb =
(ByteBuffer)rb.flip();
sc.write(wb);
// 关闭Socket
sc.close();
}catch(Exception e){
throw new UncheckedIOException(e);
}
});
}
} finally {
ssc.close();
es.shutdown();
} (1)正确地创建线程池
① Java 的线程池既能够避免无限制地创建线程导致 OOM,也能避免无限制地接收任务导致 OOM。只不过后者经常容易被我们忽略,例如在上面的实现中,就被我们忽略了。所以强烈建议你用创建有界的队列来接收任务。
② 当请求量大于有界队列的容量时,就需要合理地拒绝请求。如何合理地拒绝呢?这需要你结合具体的业务场景来制定,即便线程池默认的拒绝策略能够满足你的需求,也同样建议你在创建线程池时,清晰地指明拒绝策略。
③ 同时,为了便于调试和诊断问题,我也强烈建议你在实际工作中给线程赋予一个业务相关的名字。
综合以上这三点建议,echo 程序中创建线程可以使用下面的示例代码。
ExecutorService es = new ThreadPoolExecutor(
50, 500,
60L, TimeUnit.SECONDS,
//注意要创建有界队列
new LinkedBlockingQueue(2000),
//建议根据业务需求实现ThreadFactory
r->{
return new Thread(r, "echo-"+ r.hashCode());
},
//建议根据业务需求实现RejectedExecutionHandler
new ThreadPoolExecutor.CallerRunsPolicy()); (2)避免线程死锁
使用线程池过程中,还要注意一种线程死锁的场景。如果提交到相同线程池的任务不是相互独立的,而是有依赖关系的,那么就有可能导致线程死锁。实际工作中,我就亲历过这种线程死锁的场景。具体现象是应用每运行一段时间偶尔就会处于无响应的状态,监控数据看上去一切都正常,但是实际上已经不能正常工作了。
这个出问题的应用,相关的逻辑精简之后,如下图所示,该应用将一个大型的计算任务分成两个阶段,第一个阶段的任务会等待第二阶段的子任务完成。在这个应用里,每一个阶段都使用了线程池,而且两个阶段使用的还是同一个线程池。
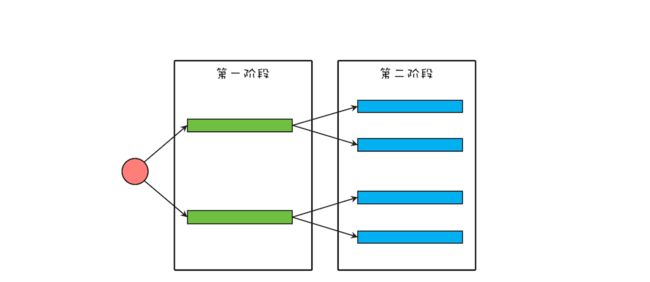
我们可以用下面的示例代码来模拟该应用,如果你执行下面的这段代码,会发现它永远执行不到最后一行。执行过程中没有任何异常,但是应用已经停止响应了。
//L1、L2阶段共用的线程池
ExecutorService es = Executors.
newFixedThreadPool(2);
//L1阶段的闭锁
CountDownLatch l1=new CountDownLatch(2);
for (int i=0; i<2; i++){
System.out.println("L1");
//执行L1阶段任务
es.execute(()->{
//L2阶段的闭锁
CountDownLatch l2=new CountDownLatch(2);
//执行L2阶段子任务
for (int j=0; j<2; j++){
es.execute(()->{
System.out.println("L2");
l2.countDown();
});
}
//等待L2阶段任务执行完
l2.await();
l1.countDown();
});
}
//等着L1阶段任务执行完
l1.await();
System.out.println("end");当应用出现类似问题时,首选的诊断方法是查看线程栈。下图是上面示例代码停止响应后的线程栈,你会发现线程池中的两个线程全部都阻塞在 l2.await(); 这行代码上了,也就是说,线程池里所有的线程都在等待 L2 阶段的任务执行完,那 L2 阶段的子任务什么时候能够执行完呢?永远都没那一天了,为什么呢?因为线程池里的线程都阻塞了,没有空闲的线程执行 L2 阶段的任务了。

原因找到了,那如何解决就简单了,最简单粗暴的办法就是将线程池的最大线程数调大,如果能够确定任务的数量不是非常多的话,这个办法也是可行的,否则这个办法就行不通了。其实这种问题通用的解决方案是为不同的任务创建不同的线程池。对于上面的这个应用,L1 阶段的任务和 L2 阶段的任务如果各自都有自己的线程池,就不会出现这种问题了。
最后再次强调一下:提交到相同线程池中的任务一定是相互独立的,否则就一定要慎重。
我们曾经说过,解决并发编程里的分工问题,最好的办法是和现实世界做对比。对比现实世界构建编程领域的模型,能够让模型更容易理解。上一篇我们介绍的 Thread-Per-Message 模式,类似于现实世界里的委托他人办理,而今天介绍的 Worker Thread 模式则类似于车间里工人的工作模式。如果你在设计阶段,发现对业务模型建模之后,模型非常类似于车间的工作模式,那基本上就能确定可以在实现阶段采用 Worker Thread 模式来实现。
Worker Thread 模式和 Thread-Per-Message 模式的区别有哪些呢?从现实世界的角度看,你委托代办人做事,往往是和代办人直接沟通的;对应到编程领域,其实现也是主线程直接创建了一个子线程,主子线程之间是可以直接通信的。而车间工人的工作方式则是完全围绕任务展开的,一个具体的任务被哪个工人执行,预先是无法知道的;对应到编程领域,则是主线程提交任务到线程池,但主线程并不关心任务被哪个线程执行。
Worker Thread 模式能避免线程频繁创建、销毁的问题,而且能够限制线程的最大数量。Java 语言里可以直接使用线程池来实现 Worker Thread 模式,线程池是一个非常基础和优秀的工具类,甚至有些大厂的编码规范都不允许用 new Thread() 来创建线程的,必须使用线程池。
不过使用线程池还是需要格外谨慎的,除了今天重点讲到的如何正确创建线程池、如何避免线程死锁问题,还需要注意前面我们曾经提到的 ThreadLocal 内存泄露问题。同时对于提交到线程池的任务,还要做好异常处理,避免异常的任务从眼前溜走,从业务的角度看,有时没有发现异常的任务后果往往都很严重。
8、两阶段终止模式:如何优雅地终止线程?
从纯技术的角度看,都是启动多线程去执行一个异步任务。既启动,那又该如何终止呢?今天咱们就从技术的角度聊聊如何优雅地终止线程,正所谓有始有终。
线程执行完或者出现异常就会进入终止状态。这样看,终止一个线程看上去很简单啊!一个线程执行完自己的任务,自己进入终止状态,这的确很简单。不过我们今天谈到的“优雅地终止线程”,不是自己终止自己,而是在一个线程 T1 中,终止线程 T2;这里所谓的“优雅”,指的是给 T2 一个机会料理后事,而不是被一剑封喉。
Java 语言的 Thread 类中曾经提供了一个 stop() 方法,用来终止线程,可是早已不建议使用了,原因是这个方法用的就是一剑封喉的做法,被终止的线程没有机会料理后事。
既然不建议使用 stop() 方法,那在 Java 领域,我们又该如何优雅地终止线程呢?
(1)如何理解两阶段终止模式
前辈们经过认真对比分析,已经总结出了一套成熟的方案,叫做两阶段终止模式。顾名思义,就是将终止过程分成两个阶段,其中第一个阶段主要是线程 T1 向线程 T2发送终止指令,而第二阶段则是线程 T2响应终止指令。

那在 Java 语言里,终止指令是什么呢?这个要从 Java 线程的状态转换过程说起。Java 线程的状态转换图,如下图所示。

从这个图里你会发现,Java 线程进入终止状态的前提是线程进入 RUNNABLE 状态,而实际上线程也可能处在休眠状态,也就是说,我们要想终止一个线程,首先要把线程的状态从休眠状态转换到 RUNNABLE 状态。如何做到呢?这个要靠 Java Thread 类提供的 interrupt() 方法,它可以将休眠状态的线程转换到 RUNNABLE 状态。
线程转换到 RUNNABLE 状态之后,我们如何再将其终止呢?RUNNABLE 状态转换到终止状态,优雅的方式是让 Java 线程自己执行完 run() 方法,所以一般我们采用的方法是设置一个标志位,然后线程会在合适的时机检查这个标志位,如果发现符合终止条件,则自动退出 run() 方法。这个过程其实就是我们前面提到的第二阶段:响应终止指令。
综合上面这两点,我们能总结出终止指令,其实包括两方面内容:interrupt() 方法和线程终止的标志位。
理解了两阶段终止模式之后,下面我们看一个实际工作中的案例。
(2)用两阶段终止模式终止监控操作
实际工作中,有些监控系统需要动态地采集一些数据,一般都是监控系统发送采集指令给被监控系统的监控代理,监控代理接收到指令之后,从监控目标收集数据,然后回传给监控系统,详细过程如下图所示。出于对性能的考虑(有些监控项对系统性能影响很大,所以不能一直持续监控),动态采集功能一般都会有终止操作。
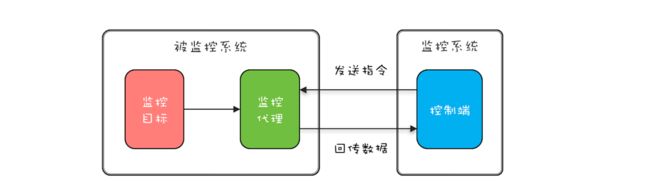
下面的示例代码是监控代理简化之后的实现,start() 方法会启动一个新的线程 rptThread 来执行监控数据采集和回传的功能,stop() 方法需要优雅地终止线程 rptThread,那 stop() 相关功能该如何实现呢?
class Proxy {
boolean started = false;
//采集线程
Thread rptThread;
//启动采集功能
synchronized void start(){
//不允许同时启动多个采集线程
if (started) {
return;
}
started = true;
rptThread = new Thread(()->{
while (true) {
//省略采集、回传实现
report();
//每隔两秒钟采集、回传一次数据
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
}
}
//执行到此处说明线程马上终止
started = false;
});
rptThread.start();
}
//终止采集功能
synchronized void stop(){
//如何实现?
}
} 按照两阶段终止模式,我们首先需要做的就是将线程 rptThread 状态转换到 RUNNABLE,做法很简单,只需要在调用 rptThread.interrupt() 就可以了。线程 rptThread 的状态转换到 RUNNABLE 之后,如何优雅地终止呢?下面的示例代码中,我们选择的标志位是线程的中断状态:Thread.currentThread().isInterrupted() ,需要注意的是,我们在捕获 Thread.sleep() 的中断异常之后,通过 Thread.currentThread().interrupt() 重新设置了线程的中断状态,因为 JVM 的异常处理会清除线程的中断状态。
class Proxy {
boolean started = false;
//采集线程
Thread rptThread;
//启动采集功能
synchronized void start(){
//不允许同时启动多个采集线程
if (started) {
return;
}
started = true;
rptThread = new Thread(()->{
while (!Thread.currentThread().isInterrupted()){
//省略采集、回传实现
report();
//每隔两秒钟采集、回传一次数据
try {
Thread.sleep(2000);
} catch (InterruptedException e){
//重新设置线程中断状态
Thread.currentThread().interrupt();
}
}
//执行到此处说明线程马上终止
started = false;
});
rptThread.start();
}
//终止采集功能
synchronized void stop(){
rptThread.interrupt();
}
}上面的示例代码的确能够解决当前的问题,但是建议你在实际工作中谨慎使用。原因在于我们很可能在线程的 run() 方法中调用第三方类库提供的方法,而我们没有办法保证第三方类库正确处理了线程的中断异常,例如第三方类库在捕获到 Thread.sleep() 方法抛出的中断异常后,没有重新设置线程的中断状态,那么就会导致线程不能够正常终止。所以强烈建议你设置自己的线程终止标志位,例如在下面的代码中,使用 isTerminated 作为线程终止标志位,此时无论是否正确处理了线程的中断异常,都不会影响线程优雅地终止。
class Proxy {
//线程终止标志位
volatile boolean terminated = false;
boolean started = false;
//采集线程
Thread rptThread;
//启动采集功能
synchronized void start(){
//不允许同时启动多个采集线程
if (started) {
return;
}
started = true;
terminated = false;
rptThread = new Thread(()->{
while (!terminated){
//省略采集、回传实现
report();
//每隔两秒钟采集、回传一次数据
try {
Thread.sleep(2000);
} catch (InterruptedException e){
//重新设置线程中断状态
Thread.currentThread().interrupt();
}
}
//执行到此处说明线程马上终止
started = false;
});
rptThread.start();
}
//终止采集功能
synchronized void stop(){
//设置中断标志位
terminated = true;
//中断线程rptThread
rptThread.interrupt();
}
}(3)如何优雅地终止线程池
Java 领域用的最多的还是线程池,而不是手动地创建线程。那我们该如何优雅地终止线程池呢?
线程池提供了两个方法:shutdown()和shutdownNow()。这两个方法有什么区别呢?要了解它们的区别,就先需要了解线程池的实现原理。
我们曾经讲过,Java 线程池是生产者 - 消费者模式的一种实现,提交给线程池的任务,首先是进入一个阻塞队列中,之后线程池中的线程从阻塞队列中取出任务执行。
shutdown() 方法是一种很保守的关闭线程池的方法。线程池执行 shutdown() 后,就会拒绝接收新的任务,但是会等待线程池中正在执行的任务和已经进入阻塞队列的任务都执行完之后才最终关闭线程池。
而 shutdownNow() 方法,相对就激进一些了,线程池执行 shutdownNow() 后,会拒绝接收新的任务,同时还会中断线程池中正在执行的任务,已经进入阻塞队列的任务也被剥夺了执行的机会,不过这些被剥夺执行机会的任务会作为 shutdownNow() 方法的返回值返回。因为 shutdownNow() 方法会中断正在执行的线程,所以提交到线程池的任务,如果需要优雅地结束,就需要正确地处理线程中断。
如果提交到线程池的任务不允许取消,那就不能使用 shutdownNow() 方法终止线程池。不过,如果提交到线程池的任务允许后续以补偿的方式重新执行,也是可以使用 shutdownNow() 方法终止线程池的。《Java 并发编程实战》这本书第 7 章《取消与关闭》的“shutdownNow 的局限性”一节中,提到一种将已提交但尚未开始执行的任务以及已经取消的正在执行的任务保存起来,以便后续重新执行的方案,你可以参考一下,方案很简单,这里就不详细介绍了。
其实分析完 shutdown() 和 shutdownNow() 方法你会发现,它们实质上使用的也是两阶段终止模式,只是终止指令的范围不同而已,前者只影响阻塞队列接收任务,后者范围扩大到线程池中所有的任务。
两阶段终止模式是一种应用很广泛的并发设计模式,在 Java 语言中使用两阶段终止模式来优雅地终止线程,需要注意两个关键点:一个是仅检查终止标志位是不够的,因为线程的状态可能处于休眠态;另一个是仅检查线程的中断状态也是不够的,因为我们依赖的第三方类库很可能没有正确处理中断异常。
当你使用 Java 的线程池来管理线程的时候,需要依赖线程池提供的 shutdown() 和 shutdownNow() 方法来终止线程池。不过在使用时需要注意它们的应用场景,尤其是在使用 shutdownNow() 的时候,一定要谨慎。
9、生产者-消费者模式:用流水线思想提高效率
Worker Thread 模式类比的是工厂里车间工人的工作模式。但其实在现实世界,工厂里还有一种流水线的工作模式,类比到编程领域,就是生产者 - 消费者模式。
生产者 - 消费者模式在编程领域的应用也非常广泛,前面我们曾经提到,Java 线程池本质上就是用生产者 - 消费者模式实现的,所以每当使用线程池的时候,其实就是在应用生产者 - 消费者模式。
当然,除了在线程池中的应用,为了提升性能,并发编程领域很多地方也都用到了生产者 - 消费者模式,例如 Log4j2 中异步 Appender 内部也用到了生产者 - 消费者模式。所以今天我们就来深入地聊聊生产者 - 消费者模式,看看它具体有哪些优点,以及如何提升系统的性能。
(1)生产者 - 消费者模式的优点
生产者 - 消费者模式的核心是一个任务队列,生产者线程生产任务,并将任务添加到任务队列中,而消费者线程从任务队列中获取任务并执行。下面是生产者 - 消费者模式的一个示意图,你可以结合它来理解。
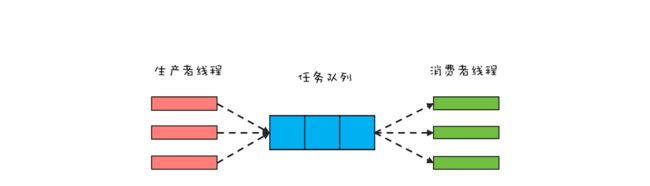
从架构设计的角度来看,生产者 - 消费者模式有一个很重要的优点,就是解耦。解耦对于大型系统的设计非常重要,而解耦的一个关键就是组件之间的依赖关系和通信方式必须受限。在生产者 - 消费者模式中,生产者和消费者没有任何依赖关系,它们彼此之间的通信只能通过任务队列,所以生产者 - 消费者模式是一个不错的解耦方案。
除了架构设计上的优点之外,生产者 - 消费者模式还有一个重要的优点就是支持异步,并且能够平衡生产者和消费者的速度差异。在生产者 - 消费者模式中,生产者线程只需要将任务添加到任务队列而无需等待任务被消费者线程执行完,也就是说任务的生产和消费是异步的,这是与传统的方法之间调用的本质区别,传统的方法之间调用是同步的。
你或许会有这样的疑问,异步化处理最简单的方式就是创建一个新的线程去处理,那中间增加一个“任务队列”究竟有什么用呢?我觉得主要还是用于平衡生产者和消费者的速度差异。我们假设生产者的速率很慢,而消费者的速率很高,比如是 1:3,如果生产者有 3 个线程,采用创建新的线程的方式,那么会创建 3 个子线程,而采用生产者 - 消费者模式,消费线程只需要 1 个就可以了。Java 语言里,Java 线程和操作系统线程是一一对应的,线程创建得太多,会增加上下文切换的成本,所以 Java 线程不是越多越好,适量即可。而生产者 - 消费者模式恰好能支持你用适量的线程。
(2)支持批量执行以提升性能
轻量级的线程,如果使用轻量级线程,就没有必要平衡生产者和消费者的速度差异了,因为轻量级线程本身就是廉价的,那是否意味着生产者 - 消费者模式在性能优化方面就无用武之地了呢?当然不是,有一类并发场景应用生产者 - 消费者模式就有奇效,那就是批量执行任务。
例如,我们要在数据库里 INSERT 1000 条数据,有两种方案:第一种方案是用 1000 个线程并发执行,每个线程 INSERT 一条数据;第二种方案是用 1 个线程,执行一个批量的 SQL,一次性把 1000 条数据 INSERT 进去。这两种方案,显然是第二种方案效率更高,其实这样的应用场景就是我们上面提到的批量执行场景。
一个监控系统动态采集的案例,其实最终回传的监控数据还是要存入数据库的(如下图)。但被监控系统往往有很多,如果每一条回传数据都直接 INSERT 到数据库,那么这个方案就是上面提到的第一种方案:每个线程 INSERT 一条数据。很显然,更好的方案是批量执行 SQL,那如何实现呢?这就要用到生产者 - 消费者模式了。

利用生产者 - 消费者模式实现批量执行 SQL 非常简单:将原来直接 INSERT 数据到数据库的线程作为生产者线程,生产者线程只需将数据添加到任务队列,然后消费者线程负责将任务从任务队列中批量取出并批量执行。
在下面的示例代码中,我们创建了 5 个消费者线程负责批量执行 SQL,这 5 个消费者线程以 while(true){} 循环方式批量地获取任务并批量地执行。需要注意的是,从任务队列中获取批量任务的方法 pollTasks() 中,首先是以阻塞方式获取任务队列中的一条任务,而后则是以非阻塞的方式获取任务;之所以首先采用阻塞方式,是因为如果任务队列中没有任务,这样的方式能够避免无谓的循环。
//任务队列
BlockingQueue bq=new
LinkedBlockingQueue<>(2000);
//启动5个消费者线程
//执行批量任务
void start() {
ExecutorService es=executors
.newFixedThreadPool(5);
for (int i=0; i<5; i++) {
es.execute(()->{
try {
while (true) {
//获取批量任务
List ts=pollTasks();
//执行批量任务
execTasks(ts);
}
} catch (Exception e) {
e.printStackTrace();
}
});
}
}
//从任务队列中获取批量任务
List pollTasks()
throws InterruptedException{
List ts=new LinkedList<>();
//阻塞式获取一条任务
Task t = bq.take();
while (t != null) {
ts.add(t);
//非阻塞式获取一条任务
t = bq.poll();
}
return ts;
}
//批量执行任务
execTasks(List ts) {
//省略具体代码无数
} (3)支持分阶段提交以提升性能
利用生产者 - 消费者模式还可以轻松地支持一种分阶段提交的应用场景。我们知道写文件如果同步刷盘性能会很慢,所以对于不是很重要的数据,我们往往采用异步刷盘的方式。我曾经参与过一个项目,其中的日志组件是自己实现的,采用的就是异步刷盘方式,刷盘的时机是:
① ERROR 级别的日志需要立即刷盘;
② 数据积累到 500 条需要立即刷盘;
③ 存在未刷盘数据,且 5 秒钟内未曾刷盘,需要立即刷盘。
这个日志组件的异步刷盘操作本质上其实就是一种分阶段提交。下面我们具体看看用生产者 - 消费者模式如何实现。在下面的示例代码中,可以通过调用 info()和error() 方法写入日志,这两个方法都是创建了一个日志任务 LogMsg,并添加到阻塞队列中,调用 info()和error() 方法的线程是生产者;而真正将日志写入文件的是消费者线程,在 Logger 这个类中,我们只创建了 1 个消费者线程,在这个消费者线程中,会根据刷盘规则执行刷盘操作,逻辑很简单,这里就不赘述了。
class Logger {
//任务队列
final BlockingQueue bq
= new BlockingQueue<>();
//flush批量
static final int batchSize=500;
//只需要一个线程写日志
ExecutorService es =
Executors.newFixedThreadPool(1);
//启动写日志线程
void start(){
File file=File.createTempFile(
"foo", ".log");
final FileWriter writer=
new FileWriter(file);
this.es.execute(()->{
try {
//未刷盘日志数量
int curIdx = 0;
long preFT=System.currentTimeMillis();
while (true) {
LogMsg log = bq.poll(
5, TimeUnit.SECONDS);
//写日志
if (log != null) {
writer.write(log.toString());
++curIdx;
}
//如果不存在未刷盘数据,则无需刷盘
if (curIdx <= 0) {
continue;
}
//根据规则刷盘
if (log!=null && log.level==LEVEL.ERROR ||
curIdx == batchSize ||
System.currentTimeMillis()-preFT>5000){
writer.flush();
curIdx = 0;
preFT=System.currentTimeMillis();
}
}
}catch(Exception e){
e.printStackTrace();
} finally {
try {
writer.flush();
writer.close();
}catch(IOException e){
e.printStackTrace();
}
}
});
}
//写INFO级别日志
void info(String msg) {
bq.put(new LogMsg(
LEVEL.INFO, msg));
}
//写ERROR级别日志
void error(String msg) {
bq.put(new LogMsg(
LEVEL.ERROR, msg));
}
}
//日志级别
enum LEVEL {
INFO, ERROR
}
class LogMsg {
LEVEL level;
String msg;
//省略构造函数实现
LogMsg(LEVEL lvl, String msg){}
//省略toString()实现
String toString(){}
} Java 语言提供的线程池本身就是一种生产者 - 消费者模式的实现,但是线程池中的线程每次只能从任务队列中消费一个任务来执行,对于大部分并发场景这种策略都没有问题。但是有些场景还是需要自己来实现,例如需要批量执行以及分阶段提交的场景。
生产者 - 消费者模式在分布式计算中的应用也非常广泛。在分布式场景下,你可以借助分布式消息队列(MQ)来实现生产者 - 消费者模式。MQ 一般都会支持两种消息模型,一种是点对点模型,一种是发布订阅模型。这两种模型的区别在于,点对点模型里一个消息只会被一个消费者消费,和 Java 的线程池非常类似(Java 线程池的任务也只会被一个线程执行);而发布订阅模型里一个消息会被多个消费者消费,本质上是一种消息的广播,在多线程编程领域,你可以结合观察者模式实现广播功能。
10、避免共享的设计模式
Immutability 模式、Copy-on-Write 模式和线程本地存储模式本质上都是为了避免共享,只是实现手段不同而已。这 3 种设计模式的实现都很简单,但是实现过程中有些细节还是需要格外注意的。例如,使用 Immutability 模式需要注意对象属性的不可变性,使用 Copy-on-Write 模式需要注意性能问题,使用线程本地存储模式需要注意异步执行问题。所以,每篇文章最后我设置的课后思考题的目的就是提醒你注意这些细节。
Account 这个类是不是具备不可变性。这个类初看上去属于不可变对象的中规中矩实现,而实质上这个实现是有问题的,原因在于 StringBuffer 不同于 String,StringBuffer 不具备不可变性,通过 getUser() 方法获取 user 之后,是可以修改 user 的。一个简单的解决方案是让 getUser() 方法返回 String 对象。
public final class Account{
private final
StringBuffer user;
public Account(String user){
this.user =
new StringBuffer(user);
}
//返回的StringBuffer并不具备不可变性
public StringBuffer getUser(){
return this.user;
}
public String toString(){
return "user"+user;
}
}Java SDK 中为什么没有提供 CopyOnWriteLinkedList。这是一个开放性的问题,没有标准答案,但是性能问题一定是其中一个很重要的原因,毕竟完整地复制 LinkedList 性能开销太大了。
在异步场景中,是否可以使用 Spring 的事务管理器。答案显然是不能的,Spring 使用 ThreadLocal 来传递事务信息,因此这个事务信息是不能跨线程共享的。实际工作中有很多类库都是用 ThreadLocal 传递上下文信息的,这种场景下如果有异步操作,一定要注意上下文信息是不能跨线程共享的。
11、多线程版本 IF 的设计模式
Guarded Suspension 模式和 Balking 模式都可以简单地理解为“多线程版本的 if”,但它们的区别在于前者会等待 if 条件变为真,而后者则不需要等待。
Guarded Suspension 模式的经典实现是使用管程,很多初学者会简单地用线程 sleep 的方式实现,比如用线程 sleep 方式实现的。但不推荐你使用这种方式,最重要的原因是性能,如果 sleep 的时间太长,会影响响应时间;sleep 的时间太短,会导致线程频繁地被唤醒,消耗系统资源。
同时,示例代码的实现也有问题:由于 obj 不是 volatile 变量,所以即便 obj 被设置了正确的值,执行 while(!p.test(obj)) 的线程也有可能看不到,从而导致更长时间的 sleep。
//获取受保护对象
T get(Predicate p) {
try {
//obj的可见性无法保证
while(!p.test(obj)){
TimeUnit.SECONDS
.sleep(timeout);
}
}catch(InterruptedException e){
throw new RuntimeException(e);
}
//返回非空的受保护对象
return obj;
}
//事件通知方法
void onChanged(T obj) {
this.obj = obj;
} 实现 Balking 模式最容易忽视的就是竞态条件问题。比如,存在竞态条件问题。因此,在多线程场景中使用 if 语句时,一定要多问自己一遍:是否存在竞态条件。
class Test{
volatile boolean inited = false;
int count = 0;
void init(){
//存在竞态条件
if(inited){
return;
}
//有可能多个线程执行到这里
inited = true;
//计算count的值
count = calc();
}
} 12、三种最简单的分工模式
Thread-Per-Message 模式、Worker Thread 模式和生产者 - 消费者模式是三种最简单实用的多线程分工方法。虽说简单,但也还是有许多细节需要你多加小心和注意。
Thread-Per-Message 模式在实现的时候需要注意是否存在线程的频繁创建、销毁以及是否可能导致 OOM。关于如何快速解决 OOM 问题的。在高并发场景中,最简单的办法其实是限流。当然,限流方案也并不局限于解决 Thread-Per-Message 模式中的 OOM 问题。
Worker Thread 模式的实现,需要注意潜在的线程死锁问题。示例代码就存在线程死锁。描述得很贴切和形象:“工厂里只有一个工人,他的工作就是同步地等待工厂里其他人给他提供东西,然而并没有其他人,他将等到天荒地老,海枯石烂!”因此,共享线程池虽然能够提供线程池的使用效率,但一定要保证一个前提,那就是:任务之间没有依赖关系。
ExecutorService pool = Executors
.newSingleThreadExecutor();
//提交主任务
pool.submit(() -> {
try {
//提交子任务并等待其完成,
//会导致线程死锁
String qq=pool.submit(()->"QQ").get();
System.out.println(qq);
} catch (Exception e) {
}
});Java 线程池本身就是一种生产者 - 消费者模式的实现,所以大部分场景你都不需要自己实现,直接使用 Java 的线程池就可以了。但若能自己灵活地实现生产者 - 消费者模式会更好,比如可以实现批量执行和分阶段提交,不过这过程中还需要注意如何优雅地终止线程。
如何优雅地终止线程?两阶段终止模式是一种通用的解决方案。但其实终止生产者 - 消费者服务还有一种更简单的方案,叫做“毒丸”对象。“毒丸”对象有过详细的介绍。简单来讲,“毒丸”对象是生产者生产的一条特殊任务,然后当消费者线程读到“毒丸”对象时,会立即终止自身的执行。
下面是用“毒丸”对象终止写日志线程的具体实现,整体的实现过程还是很简单的:类 Logger 中声明了一个“毒丸”对象 poisonPill ,当消费者线程从阻塞队列 bq 中取出一条 LogMsg 后,先判断是否是“毒丸”对象,如果是,则 break while 循环,从而终止自己的执行。
class Logger {
//用于终止日志执行的“毒丸”
final LogMsg poisonPill =
new LogMsg(LEVEL.ERROR, "");
//任务队列
final BlockingQueue bq
= new BlockingQueue<>();
//只需要一个线程写日志
ExecutorService es =
Executors.newFixedThreadPool(1);
//启动写日志线程
void start(){
File file=File.createTempFile(
"foo", ".log");
final FileWriter writer=
new FileWriter(file);
this.es.execute(()->{
try {
while (true) {
LogMsg log = bq.poll(
5, TimeUnit.SECONDS);
//如果是“毒丸”,终止执行
if(poisonPill.equals(logMsg)){
break;
}
//省略执行逻辑
}
} catch(Exception e){
} finally {
try {
writer.flush();
writer.close();
}catch(IOException e){}
}
});
}
//终止写日志线程
public void stop() {
//将“毒丸”对象加入阻塞队列
bq.add(poisonPill);
es.shutdown();
}
} 13、高性能限流器Guava RateLimiter
首先我们来看看 Guava RateLimiter 是如何解决高并发场景下的限流问题的。Guava 是 Google 开源的 Java 类库,提供了一个工具类 RateLimiter。我们先来看看 RateLimiter 的使用,让你对限流有个感官的印象。假设我们有一个线程池,它每秒只能处理两个任务,如果提交的任务过快,可能导致系统不稳定,这个时候就需要用到限流。
在下面的示例代码中,我们创建了一个流速为 2 个请求 / 秒的限流器,这里的流速该怎么理解呢?直观地看,2 个请求 / 秒指的是每秒最多允许 2 个请求通过限流器,其实在 Guava 中,流速还有更深一层的意思:是一种匀速的概念,2 个请求 / 秒等价于 1 个请求 /500 毫秒。
在向线程池提交任务之前,调用 acquire() 方法就能起到限流的作用。通过示例代码的执行结果,任务提交到线程池的时间间隔基本上稳定在 500 毫秒。
//限流器流速:2个请求/秒
RateLimiter limiter =
RateLimiter.create(2.0);
//执行任务的线程池
ExecutorService es = Executors
.newFixedThreadPool(1);
//记录上一次执行时间
prev = System.nanoTime();
//测试执行20次
for (int i=0; i<20; i++){
//限流器限流
limiter.acquire();
//提交任务异步执行
es.execute(()->{
long cur=System.nanoTime();
//打印时间间隔:毫秒
System.out.println(
(cur-prev)/1000_000);
prev = cur;
});
}
输出结果:
...
500
499
499
500
499(1)经典限流算法:令牌桶算法
Guava 的限流器使用上还是很简单的,那它是如何实现的呢?Guava 采用的是令牌桶算法,其核心是要想通过限流器,必须拿到令牌。也就是说,只要我们能够限制发放令牌的速率,那么就能控制流速了。令牌桶算法的详细描述如下:
① 令牌以固定的速率添加到令牌桶中,假设限流的速率是 r/ 秒,则令牌每 1/r 秒会添加一个;
② 假设令牌桶的容量是 b ,如果令牌桶已满,则新的令牌会被丢弃;
③ 请求能够通过限流器的前提是令牌桶中有令牌。
这个算法中,限流的速率 r 还是比较容易理解的,但令牌桶的容量 b 该怎么理解呢?b 其实是 burst 的简写,意义是限流器允许的最大突发流量。比如 b=10,而且令牌桶中的令牌已满,此时限流器允许 10 个请求同时通过限流器,当然只是突发流量而已,这 10 个请求会带走 10 个令牌,所以后续的流量只能按照速率 r 通过限流器。
令牌桶这个算法,如何用 Java 实现呢?很可能你的直觉会告诉你生产者 - 消费者模式:一个生产者线程定时向阻塞队列中添加令牌,而试图通过限流器的线程则作为消费者线程,只有从阻塞队列中获取到令牌,才允许通过限流器。
这个算法看上去非常完美,而且实现起来非常简单,如果并发量不大,这个实现并没有什么问题。可实际情况却是使用限流的场景大部分都是高并发场景,而且系统压力已经临近极限了,此时这个实现就有问题了。问题就出在定时器上,在高并发场景下,当系统压力已经临近极限的时候,定时器的精度误差会非常大,同时定时器本身会创建调度线程,也会对系统的性能产生影响。
那还有什么好的实现方式呢?当然有,Guava 的实现就没有使用定时器,下面我们就来看看它是如何实现的。
(2)Guava 如何实现令牌桶算法
Guava 实现令牌桶算法,用了一个很简单的办法,其关键是记录并动态计算下一令牌发放的时间。下面我们以一个最简单的场景来介绍该算法的执行过程。假设令牌桶的容量为 b=1,限流速率 r = 1 个请求 / 秒,如下图所示,如果当前令牌桶中没有令牌,下一个令牌的发放时间是在第 3 秒,而在第 2 秒的时候有一个线程 T1 请求令牌,此时该如何处理呢?

对于这个请求令牌的线程而言,很显然需要等待 1 秒,因为 1 秒以后(第 3 秒)它就能拿到令牌了。此时需要注意的是,下一个令牌发放的时间也要增加 1 秒,为什么呢?因为第 3 秒发放的令牌已经被线程 T1 预占了。处理之后如下图所示。

假设 T1 在预占了第 3 秒的令牌之后,马上又有一个线程 T2 请求令牌,如下图所示。

很显然,由于下一个令牌产生的时间是第 4 秒,所以线程 T2 要等待两秒的时间,才能获取到令牌,同时由于 T2 预占了第 4 秒的令牌,所以下一令牌产生时间还要增加 1 秒,完全处理之后,如下图所示。

上面线程 T1、T2 都是在下一令牌产生时间之前请求令牌,如果线程在下一令牌产生时间之后请求令牌会如何呢?假设在线程 T1 请求令牌之后的 5 秒,也就是第 7 秒,线程 T3 请求令牌,如下图所示。

由于在第 5 秒已经产生了一个令牌,所以此时线程 T3 可以直接拿到令牌,而无需等待。在第 7 秒,实际上限流器能够产生 3 个令牌,第 5、6、7 秒各产生一个令牌。由于我们假设令牌桶的容量是 1,所以第 6、7 秒产生的令牌就丢弃了,其实等价地你也可以认为是保留的第 7 秒的令牌,丢弃的第 5、6 秒的令牌,也就是说第 7 秒的令牌被线程 T3 占有了,于是下一令牌的的产生时间应该是第 8 秒,如下图所示。

通过上面简要地分析,你会发现,我们只需要记录一个下一令牌产生的时间,并动态更新它,就能够轻松完成限流功能。我们可以将上面的这个算法代码化,示例代码如下所示,依然假设令牌桶的容量是 1。关键是 reserve() 方法,这个方法会为请求令牌的线程预分配令牌,同时返回该线程能够获取令牌的时间。其实现逻辑就是上面提到的:如果线程请求令牌的时间在下一令牌产生时间之后,那么该线程立刻就能够获取令牌;反之,如果请求时间在下一令牌产生时间之前,那么该线程是在下一令牌产生的时间获取令牌。由于此时下一令牌已经被该线程预占,所以下一令牌产生的时间需要加上 1 秒。
class SimpleLimiter {
//下一令牌产生时间
long next = System.nanoTime();
//发放令牌间隔:纳秒
long interval = 1000_000_000;
//预占令牌,返回能够获取令牌的时间
synchronized long reserve(long now){
//请求时间在下一令牌产生时间之后
//重新计算下一令牌产生时间
if (now > next){
//将下一令牌产生时间重置为当前时间
next = now;
}
//能够获取令牌的时间
long at=next;
//设置下一令牌产生时间
next += interval;
//返回线程需要等待的时间
return Math.max(at, 0L);
}
//申请令牌
void acquire() {
//申请令牌时的时间
long now = System.nanoTime();
//预占令牌
long at=reserve(now);
long waitTime=max(at-now, 0);
//按照条件等待
if(waitTime > 0) {
try {
TimeUnit.NANOSECONDS
.sleep(waitTime);
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
}如果令牌桶的容量大于 1,又该如何处理呢?按照令牌桶算法,令牌要首先从令牌桶中出,所以我们需要按需计算令牌桶中的数量,当有线程请求令牌时,先从令牌桶中出。具体的代码实现如下所示。我们增加了一个 resync() 方法,在这个方法中,如果线程请求令牌的时间在下一令牌产生时间之后,会重新计算令牌桶中的令牌数,新产生的令牌的计算公式是:(now-next)/interval,你可对照上面的示意图来理解。reserve() 方法中,则增加了先从令牌桶中出令牌的逻辑,不过需要注意的是,如果令牌是从令牌桶中出的,那么 next 就无需增加一个 interval 了。
class SimpleLimiter {
//当前令牌桶中的令牌数量
long storedPermits = 0;
//令牌桶的容量
long maxPermits = 3;
//下一令牌产生时间
long next = System.nanoTime();
//发放令牌间隔:纳秒
long interval = 1000_000_000;
//请求时间在下一令牌产生时间之后,则
// 1.重新计算令牌桶中的令牌数
// 2.将下一个令牌发放时间重置为当前时间
void resync(long now) {
if (now > next) {
//新产生的令牌数
long newPermits=(now-next)/interval;
//新令牌增加到令牌桶
storedPermits=min(maxPermits,
storedPermits + newPermits);
//将下一个令牌发放时间重置为当前时间
next = now;
}
}
//预占令牌,返回能够获取令牌的时间
synchronized long reserve(long now){
resync(now);
//能够获取令牌的时间
long at = next;
//令牌桶中能提供的令牌
long fb=min(1, storedPermits);
//令牌净需求:首先减掉令牌桶中的令牌
long nr = 1 - fb;
//重新计算下一令牌产生时间
next = next + nr*interval;
//重新计算令牌桶中的令牌
this.storedPermits -= fb;
return at;
}
//申请令牌
void acquire() {
//申请令牌时的时间
long now = System.nanoTime();
//预占令牌
long at=reserve(now);
long waitTime=max(at-now, 0);
//按照条件等待
if(waitTime > 0) {
try {
TimeUnit.NANOSECONDS
.sleep(waitTime);
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
}经典的限流算法有两个,一个是令牌桶算法(Token Bucket),另一个是漏桶算法(Leaky Bucket)。令牌桶算法是定时向令牌桶发送令牌,请求能够从令牌桶中拿到令牌,然后才能通过限流器;而漏桶算法里,请求就像水一样注入漏桶,漏桶会按照一定的速率自动将水漏掉,只有漏桶里还能注入水的时候,请求才能通过限流器。令牌桶算法和漏桶算法很像一个硬币的正反面,所以你可以参考令牌桶算法的实现来实现漏桶算法。
上面我们介绍了 Guava 是如何实现令牌桶算法的,我们的示例代码是对 Guava RateLimiter 的简化,Guava RateLimiter 扩展了标准的令牌桶算法,比如还能支持预热功能。对于按需加载的缓存来说,预热后缓存能支持 5 万 TPS 的并发,但是在预热前 5 万 TPS 的并发直接就把缓存击垮了,所以如果需要给该缓存限流,限流器也需要支持预热功能,在初始阶段,限制的流速 r 很小,但是动态增长的。预热功能的实现非常复杂,Guava 构建了一个积分函数来解决这个问题,如果你感兴趣,可以继续深入研究。
14、高性能网络应用框架Netty
Netty 是一个高性能网络应用框架,应用非常普遍,目前在 Java 领域里,Netty 基本上成为网络程序的标配了。Netty 框架功能丰富,也非常复杂,今天我们主要分析 Netty 框架中的线程模型,而线程模型直接影响着网络程序的性能。
在介绍 Netty 的线程模型之前,我们首先需要把问题搞清楚,了解网络编程性能的瓶颈在哪里,然后再看 Netty 的线程模型是如何解决这个问题的。
(1)网络编程性能的瓶颈
一个简单的网络程序 echo,采用的是阻塞式 I/O(BIO)。BIO 模型里,所有 read() 操作和 write() 操作都会阻塞当前线程的,如果客户端已经和服务端建立了一个连接,而迟迟不发送数据,那么服务端的 read() 操作会一直阻塞,所以使用 BIO 模型,一般都会为每个 socket 分配一个独立的线程,这样就不会因为线程阻塞在一个 socket 上而影响对其他 socket 的读写。BIO 的线程模型如下图所示,每一个 socket 都对应一个独立的线程;为了避免频繁创建、消耗线程,可以采用线程池,但是 socket 和线程之间的对应关系并不会变化。
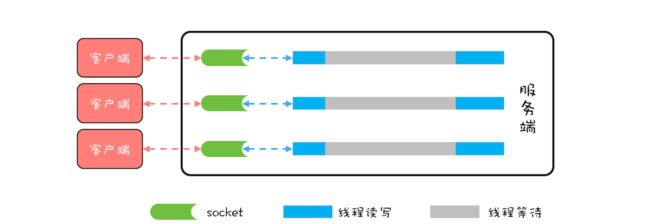
BIO 这种线程模型适用于 socket 连接不是很多的场景;但是现在的互联网场景,往往需要服务器能够支撑十万甚至百万连接,而创建十万甚至上百万个线程显然并不现实,所以 BIO 线程模型无法解决百万连接的问题。如果仔细观察,你会发现互联网场景中,虽然连接多,但是每个连接上的请求并不频繁,所以线程大部分时间都在等待 I/O 就绪。也就是说线程大部分时间都阻塞在那里,这完全是浪费,如果我们能够解决这个问题,那就不需要这么多线程了。
顺着这个思路,我们可以将线程模型优化为下图这个样子,可以用一个线程来处理多个连接,这样线程的利用率就上来了,同时所需的线程数量也跟着降下来了。这个思路很好,可是使用 BIO 相关的 API 是无法实现的,这是为什么呢?因为 BIO 相关的 socket 读写操作都是阻塞式的,而一旦调用了阻塞式 API,在 I/O 就绪前,调用线程会一直阻塞,也就无法处理其他的 socket 连接了。

好在 Java 里还提供了非阻塞式(NIO)API,利用非阻塞式 API 就能够实现一个线程处理多个连接了。那具体如何实现呢?现在普遍都是采用 Reactor 模式,包括 Netty 的实现。所以,要想理解 Netty 的实现,接下来我们就需要先了解一下 Reactor 模式。
(2)Reactor 模式
下面是 Reactor 模式的类结构图,其中 Handle 指的是 I/O 句柄,在 Java 网络编程里,它本质上就是一个网络连接。Event Handler 很容易理解,就是一个事件处理器,其中 handle_event() 方法处理 I/O 事件,也就是每个 Event Handler 处理一个 I/O Handle;get_handle() 方法可以返回这个 I/O 的 Handle。Synchronous Event Demultiplexer 可以理解为操作系统提供的 I/O 多路复用 API,例如 POSIX 标准里的 select() 以及 Linux 里面的 epoll()。

Reactor 模式的核心自然是 Reactor 这个类,其中 register_handler() 和 remove_handler() 这两个方法可以注册和删除一个事件处理器;handle_events() 方式是核心,也是 Reactor 模式的发动机,这个方法的核心逻辑如下:首先通过同步事件多路选择器提供的 select() 方法监听网络事件,当有网络事件就绪后,就遍历事件处理器来处理该网络事件。由于网络事件是源源不断的,所以在主程序中启动 Reactor 模式,需要以 while(true){} 的方式调用 handle_events() 方法。
void Reactor::handle_events(){
//通过同步事件多路选择器提供的
//select()方法监听网络事件
select(handlers);
//处理网络事件
for(h in handlers){
h.handle_event();
}
}
// 在主程序中启动事件循环
while (true) {
handle_events();(3)Netty 中的线程模型
Netty 的实现虽然参考了 Reactor 模式,但是并没有完全照搬,Netty 中最核心的概念是事件循环(EventLoop),其实也就是 Reactor 模式中的 Reactor,负责监听网络事件并调用事件处理器进行处理。在 4.x 版本的 Netty 中,网络连接和 EventLoop 是稳定的多对 1 关系,而 EventLoop 和 Java 线程是 1 对 1 关系,这里的稳定指的是关系一旦确定就不再发生变化。也就是说一个网络连接只会对应唯一的一个 EventLoop,而一个 EventLoop 也只会对应到一个 Java 线程,所以一个网络连接只会对应到一个 Java 线程。
一个网络连接对应到一个 Java 线程上,有什么好处呢?最大的好处就是对于一个网络连接的事件处理是单线程的,这样就避免了各种并发问题。
Netty 中的线程模型可以参考下图,这个图和前面我们提到的理想的线程模型图非常相似,核心目标都是用一个线程处理多个网络连接。
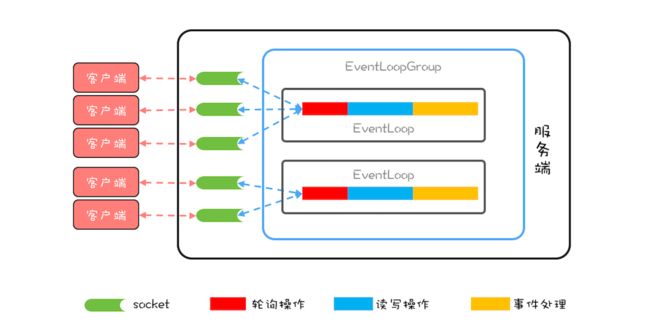
Netty 中还有一个核心概念是 EventLoopGroup,顾名思义,一个 EventLoopGroup 由一组 EventLoop 组成。实际使用中,一般都会创建两个 EventLoopGroup,一个称为 bossGroup,一个称为 workerGroup。为什么会有两个 EventLoopGroup 呢?
这个和 socket 处理网络请求的机制有关,socket 处理 TCP 网络连接请求,是在一个独立的 socket 中,每当有一个 TCP 连接成功建立,都会创建一个新的 socket,之后对 TCP 连接的读写都是由新创建处理的 socket 完成的。也就是说处理 TCP 连接请求和读写请求是通过两个不同的 socket 完成的。上面我们在讨论网络请求的时候,为了简化模型,只是讨论了读写请求,而没有讨论连接请求。
在 Netty 中,bossGroup 就用来处理连接请求的,而 workerGroup 是用来处理读写请求的。bossGroup 处理完连接请求后,会将这个连接提交给 workerGroup 来处理, workerGroup 里面有多个 EventLoop,那新的连接会交给哪个 EventLoop 来处理呢?这就需要一个负载均衡算法,Netty 中目前使用的是轮询算法。
下面我们用 Netty 重新实现以下 echo 程序的服务端,近距离感受一下 Netty。
(4)用 Netty 实现 Echo 程序服务端
下面的示例代码基于 Netty 实现了 echo 程序服务端:首先创建了一个事件处理器(等同于 Reactor 模式中的事件处理器),然后创建了 bossGroup 和 workerGroup,再之后创建并初始化了 ServerBootstrap,代码还是很简单的,不过有两个地方需要注意一下。
第一个,如果 NettybossGroup 只监听一个端口,那 bossGroup 只需要 1 个 EventLoop 就可以了,多了纯属浪费。
第二个,默认情况下,Netty 会创建“2*CPU 核数”个 EventLoop,由于网络连接与 EventLoop 有稳定的关系,所以事件处理器在处理网络事件的时候是不能有阻塞操作的,否则很容易导致请求大面积超时。如果实在无法避免使用阻塞操作,那可以通过线程池来异步处理。
//事件处理器
final EchoServerHandler serverHandler
= new EchoServerHandler();
//boss线程组
EventLoopGroup bossGroup
= new NioEventLoopGroup(1);
//worker线程组
EventLoopGroup workerGroup
= new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer() {
@Override
public void initChannel(SocketChannel ch){
ch.pipeline().addLast(serverHandler);
}
});
//bind服务端端口
ChannelFuture f = b.bind(9090).sync();
f.channel().closeFuture().sync();
} finally {
//终止工作线程组
workerGroup.shutdownGracefully();
//终止boss线程组
bossGroup.shutdownGracefully();
}
//socket连接处理器
class EchoServerHandler extends
ChannelInboundHandlerAdapter {
//处理读事件
@Override
public void channelRead(
ChannelHandlerContext ctx, Object msg){
ctx.write(msg);
}
//处理读完成事件
@Override
public void channelReadComplete(
ChannelHandlerContext ctx){
ctx.flush();
}
//处理异常事件
@Override
public void exceptionCaught(
ChannelHandlerContext ctx, Throwable cause) {
cause.printStackTrace();
ctx.close();
}
} Netty 是一个款优秀的网络编程框架,性能非常好,为了实现高性能的目标,Netty 做了很多优化,例如优化了 ByteBuffer、支持零拷贝等等,和并发编程相关的就是它的线程模型了。Netty 的线程模型设计得很精巧,每个网络连接都关联到了一个线程上,这样做的好处是:对于一个网络连接,读写操作都是单线程执行的,从而避免了并发程序的各种问题。
15、高性能队列Disruptor
Java SDK 提供了 2 个有界队列:ArrayBlockingQueue 和 LinkedBlockingQueue,它们都是基于 ReentrantLock 实现的,在高并发场景下,锁的效率并不高,那有没有更好的替代品呢?有,今天我们就介绍一种性能更高的有界队列:Disruptor。
Disruptor 是一款高性能的有界内存队列,目前应用非常广泛,Log4j2、Spring Messaging、HBase、Storm 都用到了 Disruptor,那 Disruptor 的性能为什么这么高呢?Disruptor 项目团队曾经写过一篇论文,详细解释了其原因,可以总结为如下:
① 内存分配更加合理,使用 RingBuffer 数据结构,数组元素在初始化时一次性全部创建,提升缓存命中率;对象循环利用,避免频繁 GC。
② 能够避免伪共享,提升缓存利用率。
③ 采用无锁算法,避免频繁加锁、解锁的性能消耗。
④ 支持批量消费,消费者可以无锁方式消费多个消息。
其中,前三点涉及到的知识比较多,所以今天咱们重点讲解前三点,不过在详细介绍这些知识之前,我们先来聊聊 Disruptor 如何使用,好让你先对 Disruptor 有个感官的认识。
下面的代码出自官方示例,我略做了一些修改,相较而言,Disruptor 的使用比 Java SDK 提供 BlockingQueue 要复杂一些,但是总体思路还是一致的,其大致情况如下:
在 Disruptor 中,生产者生产的对象(也就是消费者消费的对象)称为 Event,使用 Disruptor 必须自定义 Event,例如示例代码的自定义 Event 是 LongEvent;
构建 Disruptor 对象除了要指定队列大小外,还需要传入一个 EventFactory,示例代码中传入的是LongEvent::new;
消费 Disruptor 中的 Event 需要通过 handleEventsWith() 方法注册一个事件处理器,发布 Event 则需要通过 publishEvent() 方法。
//自定义Event
class LongEvent {
private long value;
public void set(long value) {
this.value = value;
}
}
//指定RingBuffer大小,
//必须是2的N次方
int bufferSize = 1024;
//构建Disruptor
Disruptor disruptor
= new Disruptor<>(
LongEvent::new,
bufferSize,
DaemonThreadFactory.INSTANCE);
//注册事件处理器
disruptor.handleEventsWith(
(event, sequence, endOfBatch) ->
System.out.println("E: "+event));
//启动Disruptor
disruptor.start();
//获取RingBuffer
RingBuffer ringBuffer
= disruptor.getRingBuffer();
//生产Event
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++){
bb.putLong(0, l);
//生产者生产消息
ringBuffer.publishEvent(
(event, sequence, buffer) ->
event.set(buffer.getLong(0)), bb);
Thread.sleep(1000);
} (1)RingBuffer 如何提升性能
Java SDK 中 ArrayBlockingQueue 使用数组作为底层的数据存储,而 Disruptor 是使用 RingBuffer 作为数据存储。RingBuffer 本质上也是数组,所以仅仅将数据存储从数组换成 RingBuffer 并不能提升性能,但是 Disruptor 在 RingBuffer 的基础上还做了很多优化,其中一项优化就是和内存分配有关的。
在介绍这项优化之前,你需要先了解一下程序的局部性原理。简单来讲,程序的局部性原理指的是在一段时间内程序的执行会限定在一个局部范围内。这里的“局部性”可以从两个方面来理解,一个是时间局部性,另一个是空间局部性。时间局部性指的是程序中的某条指令一旦被执行,不久之后这条指令很可能再次被执行;如果某条数据被访问,不久之后这条数据很可能再次被访问。而空间局部性是指某块内存一旦被访问,不久之后这块内存附近的内存也很可能被访问。
CPU 的缓存就利用了程序的局部性原理:CPU 从内存中加载数据 X 时,会将数据 X 缓存在高速缓存 Cache 中,实际上 CPU 缓存 X 的同时,还缓存了 X 周围的数据,因为根据程序具备局部性原理,X 周围的数据也很有可能被访问。从另外一个角度来看,如果程序能够很好地体现出局部性原理,也就能更好地利用 CPU 的缓存,从而提升程序的性能。Disruptor 在设计 RingBuffer 的时候就充分考虑了这个问题,下面我们就对比着 ArrayBlockingQueue 来分析一下。
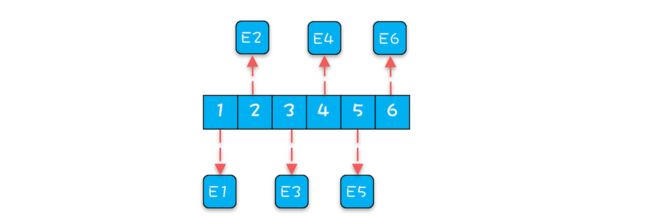
首先是 ArrayBlockingQueue。生产者线程向 ArrayBlockingQueue 增加一个元素,每次增加元素 E 之前,都需要创建一个对象 E,如下图所示,ArrayBlockingQueue 内部有 6 个元素,这 6 个元素都是由生产者线程创建的,由于创建这些元素的时间基本上是离散的,所以这些元素的内存地址大概率也不是连续的。
下面我们再看看 Disruptor 是如何处理的。Disruptor 内部的 RingBuffer 也是用数组实现的,但是这个数组中的所有元素在初始化时是一次性全部创建的,所以这些元素的内存地址大概率是连续的,相关的代码如下所示。
for (int i=0; iDisruptor 内部 RingBuffer 的结构可以简化成下图,那问题来了,数组中所有元素内存地址连续能提升性能吗?能!为什么呢?因为消费者线程在消费的时候,是遵循空间局部性原理的,消费完第 1 个元素,很快就会消费第 2 个元素;当消费第 1 个元素 E1 的时候,CPU 会把内存中 E1 后面的数据也加载进 Cache,如果 E1 和 E2 在内存中的地址是连续的,那么 E2 也就会被加载进 Cache 中,然后当消费第 2 个元素的时候,由于 E2 已经在 Cache 中了,所以就不需要从内存中加载了,这样就能大大提升性能。

除此之外,在 Disruptor 中,生产者线程通过 publishEvent() 发布 Event 的时候,并不是创建一个新的 Event,而是通过 event.set() 方法修改 Event, 也就是说 RingBuffer 创建的 Event 是可以循环利用的,这样还能避免频繁创建、删除 Event 导致的频繁 GC 问题。
(2)如何避免“伪共享”
高效利用 Cache,能够大大提升性能,所以要努力构建能够高效利用 Cache 的内存结构。而从另外一个角度看,努力避免不能高效利用 Cache 的内存结构也同样重要。
有一种叫做“伪共享(False sharing)”的内存布局就会使 Cache 失效,那什么是“伪共享”呢?
伪共享和 CPU 内部的 Cache 有关,Cache 内部是按照缓存行(Cache Line)管理的,缓存行的大小通常是 64 个字节;CPU 从内存中加载数据 X,会同时加载 X 后面(64-size(X))个字节的数据。下面的示例代码出自 Java SDK 的 ArrayBlockingQueue,其内部维护了 4 个成员变量,分别是队列数组 items、出队索引 takeIndex、入队索引 putIndex 以及队列中的元素总数 count。
/** 队列数组 */
final Object[] items;
/** 出队索引 */
int takeIndex;
/** 入队索引 */
int putIndex;
/** 队列中元素总数 */
int count;当 CPU 从内存中加载 takeIndex 的时候,会同时将 putIndex 以及 count 都加载进 Cache。下图是某个时刻 CPU 中 Cache 的状况,为了简化,缓存行中我们仅列出了 takeIndex 和 putIndex。
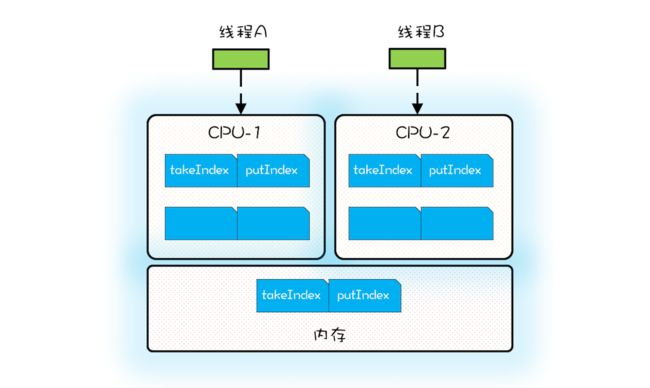
假设线程 A 运行在 CPU-1 上,执行入队操作,入队操作会修改 putIndex,而修改 putIndex 会导致其所在的所有核上的缓存行均失效;此时假设运行在 CPU-2 上的线程执行出队操作,出队操作需要读取 takeIndex,由于 takeIndex 所在的缓存行已经失效,所以 CPU-2 必须从内存中重新读取。入队操作本不会修改 takeIndex,但是由于 takeIndex 和 putIndex 共享的是一个缓存行,就导致出队操作不能很好地利用 Cache,这其实就是伪共享。简单来讲,伪共享指的是由于共享缓存行导致缓存无效的场景。
ArrayBlockingQueue 的入队和出队操作是用锁来保证互斥的,所以入队和出队不会同时发生。如果允许入队和出队同时发生,那就会导致线程 A 和线程 B 争用同一个缓存行,这样也会导致性能问题。所以为了更好地利用缓存,我们必须避免伪共享,那如何避免呢?
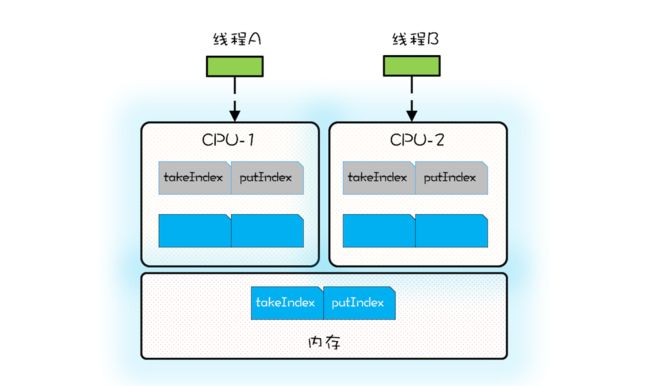
方案很简单,每个变量独占一个缓存行、不共享缓存行就可以了,具体技术是缓存行填充。比如想让 takeIndex 独占一个缓存行,可以在 takeIndex 的前后各填充 56 个字节,这样就一定能保证 takeIndex 独占一个缓存行。下面的示例代码出自 Disruptor,Sequence 对象中的 value 属性就能避免伪共享,因为这个属性前后都填充了 56 个字节。Disruptor 中很多对象,例如 RingBuffer、RingBuffer 内部的数组都用到了这种填充技术来避免伪共享。
//前:填充56字节
class LhsPadding{
long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding{
volatile long value;
}
//后:填充56字节
class RhsPadding extends Value{
long p9, p10, p11, p12, p13, p14, p15;
}
class Sequence extends RhsPadding{
//省略实现
}(3)Disruptor 中的无锁算法
ArrayBlockingQueue 是利用管程实现的,中规中矩,生产、消费操作都需要加锁,实现起来简单,但是性能并不十分理想。Disruptor 采用的是无锁算法,很复杂,但是核心无非是生产和消费两个操作。Disruptor 中最复杂的是入队操作,所以我们重点来看看入队操作是如何实现的。
对于入队操作,最关键的要求是不能覆盖没有消费的元素;对于出队操作,最关键的要求是不能读取没有写入的元素,所以 Disruptor 中也一定会维护类似出队索引和入队索引这样两个关键变量。Disruptor 中的 RingBuffer 维护了入队索引,但是并没有维护出队索引,这是因为在 Disruptor 中多个消费者可以同时消费,每个消费者都会有一个出队索引,所以 RingBuffer 的出队索引是所有消费者里面最小的那一个。
下面是 Disruptor 生产者入队操作的核心代码,看上去很复杂,其实逻辑很简单:如果没有足够的空余位置,就出让 CPU 使用权,然后重新计算;反之则用 CAS 设置入队索引。
//生产者获取n个写入位置
do {
//cursor类似于入队索引,指的是上次生产到这里
current = cursor.get();
//目标是在生产n个
next = current + n;
//减掉一个循环
long wrapPoint = next - bufferSize;
//获取上一次的最小消费位置
long cachedGatingSequence = gatingSequenceCache.get();
//没有足够的空余位置
if (wrapPoint>cachedGatingSequence || cachedGatingSequence>current){
//重新计算所有消费者里面的最小值位置
long gatingSequence = Util.getMinimumSequence(
gatingSequences, current);
//仍然没有足够的空余位置,出让CPU使用权,重新执行下一循环
if (wrapPoint > gatingSequence){
LockSupport.parkNanos(1);
continue;
}
//从新设置上一次的最小消费位置
gatingSequenceCache.set(gatingSequence);
} else if (cursor.compareAndSet(current, next)){
//获取写入位置成功,跳出循环
break;
}
} while (true);Disruptor 在优化并发性能方面可谓是做到了极致,优化的思路大体是两个方面,一个是利用无锁算法避免锁的争用,另外一个则是将硬件(CPU)的性能发挥到极致。尤其是后者,在 Java 领域基本上属于经典之作了。
发挥硬件的能力一般是 C 这种面向硬件的语言常干的事儿,C 语言领域经常通过调整内存布局优化内存占用,而 Java 领域则用的很少,原因在于 Java 可以智能地优化内存布局,内存布局对 Java 程序员的透明的。这种智能的优化大部分场景是很友好的,但是如果你想通过填充方式避免伪共享就必须绕过这种优化,关于这方面 Disruptor 提供了经典的实现,你可以参考。
由于伪共享问题如此重要,所以 Java 也开始重视它了,比如 Java 8 中,提供了避免伪共享的注解:@sun.misc.Contended,通过这个注解就能轻松避免伪共享(需要设置 JVM 参数 -XX:-RestrictContended)。不过避免伪共享是以牺牲内存为代价的,所以具体使用的时候还是需要仔细斟酌。
16、高性能数据库连接池HiKariCP
只要和数据库打交道,就免不了使用数据库连接池。业界知名的数据库连接池有不少,例如 c3p0、DBCP、Tomcat JDBC Connection Pool、Druid 等,不过最近最火的是 HiKariCP。
HiKariCP 号称是业界跑得最快的数据库连接池,这两年发展得顺风顺水,尤其是 Springboot 2.0 将其作为默认数据库连接池后,江湖一哥的地位已是毋庸置疑了。那它为什么那么快呢?今天咱们就重点聊聊这个话题。
(1)什么是数据库连接池
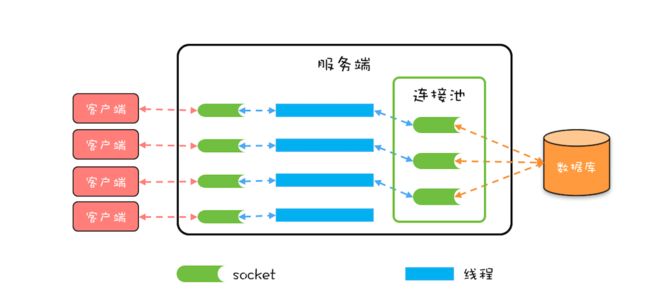
在详细分析 HiKariCP 高性能之前,我们有必要先简单介绍一下什么是数据库连接池。本质上,数据库连接池和线程池一样,都属于池化资源,作用都是避免重量级资源的频繁创建和销毁,对于数据库连接池来说,也就是避免数据库连接频繁创建和销毁。如下图所示,服务端会在运行期持有一定数量的数据库连接,当需要执行 SQL 时,并不是直接创建一个数据库连接,而是从连接池中获取一个;当 SQL 执行完,也并不是将数据库连接真的关掉,而是将其归还到连接池中。
在实际工作中,我们都是使用各种持久化框架来完成数据库的增删改查,基本上不会直接和数据库连接池打交道,为了能让你更好地理解数据库连接池的工作原理,下面的示例代码并没有使用任何框架,而是原生地使用 HiKariCP。执行数据库操作基本上是一系列规范化的步骤:
① 通过数据源获取一个数据库连接;
② 创建 Statement;
③ 执行 SQL;
④ 通过 ResultSet 获取 SQL 执行结果;
⑤ 释放 ResultSet;
⑥ 释放 Statement;
⑦ 释放数据库连接。
下面的示例代码,通过 ds.getConnection() 获取一个数据库连接时,其实是向数据库连接池申请一个数据库连接,而不是创建一个新的数据库连接。同样,通过 conn.close() 释放一个数据库连接时,也不是直接将连接关闭,而是将连接归还给数据库连接池。
//数据库连接池配置
HikariConfig config = new HikariConfig();
config.setMinimumIdle(1);
config.setMaximumPoolSize(2);
config.setConnectionTestQuery("SELECT 1");
config.setDataSourceClassName("org.h2.jdbcx.JdbcDataSource");
config.addDataSourceProperty("url", "jdbc:h2:mem:test");
// 创建数据源
DataSource ds = new HikariDataSource(config);
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
// 获取数据库连接
conn = ds.getConnection();
// 创建Statement
stmt = conn.createStatement();
// 执行SQL
rs = stmt.executeQuery("select * from abc");
// 获取结果
while (rs.next()) {
int id = rs.getInt(1);
......
}
} catch(Exception e) {
e.printStackTrace();
} finally {
//关闭ResultSet
close(rs);
//关闭Statement
close(stmt);
//关闭Connection
close(conn);
}
//关闭资源
void close(AutoCloseable rs) {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}HiKariCP 官方网站解释了其性能之所以如此之高的秘密。微观上 HiKariCP 程序编译出的字节码执行效率更高,站在字节码的角度去优化 Java 代码,HiKariCP 的作者对性能的执着可见一斑,不过遗憾的是他并没有详细解释都做了哪些优化。而宏观上主要是和两个数据结构有关,一个是 FastList,另一个是 ConcurrentBag。下面我们来看看它们是如何提升 HiKariCP 的性能的。
(2)FastList 解决了哪些性能问题
按照规范步骤,执行完数据库操作之后,需要依次关闭 ResultSet、Statement、Connection,但是总有粗心的同学只是关闭了 Connection,而忘了关闭 ResultSet 和 Statement。为了解决这种问题,最好的办法是当关闭 Connection 时,能够自动关闭 Statement。为了达到这个目标,Connection 就需要跟踪创建的 Statement,最简单的办法就是将创建的 Statement 保存在数组 ArrayList 里,这样当关闭 Connection 的时候,就可以依次将数组中的所有 Statement 关闭。
HiKariCP 觉得用 ArrayList 还是太慢,当通过 conn.createStatement() 创建一个 Statement 时,需要调用 ArrayList 的 add() 方法加入到 ArrayList 中,这个是没有问题的;但是当通过 stmt.close() 关闭 Statement 的时候,需要调用 ArrayList 的 remove() 方法来将其从 ArrayList 中删除,这里是有优化余地的。
假设一个 Connection 依次创建 6 个 Statement,分别是 S1、S2、S3、S4、S5、S6,按照正常的编码习惯,关闭 Statement 的顺序一般是逆序的,关闭的顺序是:S6、S5、S4、S3、S2、S1,而 ArrayList 的 remove(Object o) 方法是顺序遍历查找,逆序删除而顺序查找,这样的查找效率就太慢了。如何优化呢?很简单,优化成逆序查找就可以了。

HiKariCP 中的 FastList 相对于 ArrayList 的一个优化点就是将 remove(Object element) 方法的查找顺序变成了逆序查找。除此之外,FastList 还有另一个优化点,是 get(int index) 方法没有对 index 参数进行越界检查,HiKariCP 能保证不会越界,所以不用每次都进行越界检查。
整体来看,FastList 的优化点还是很简单的。下面我们再来聊聊 HiKariCP 中的另外一个数据结构 ConcurrentBag,看看它又是如何提升性能的。
(3)ConcurrentBag 解决了哪些性能问题
如果让我们自己来实现一个数据库连接池,最简单的办法就是用两个阻塞队列来实现,一个用于保存空闲数据库连接的队列 idle,另一个用于保存忙碌数据库连接的队列 busy;获取连接时将空闲的数据库连接从 idle 队列移动到 busy 队列,而关闭连接时将数据库连接从 busy 移动到 idle。这种方案将并发问题委托给了阻塞队列,实现简单,但是性能并不是很理想。因为 Java SDK 中的阻塞队列是用锁实现的,而高并发场景下锁的争用对性能影响很大。
//忙碌队列
BlockingQueue busy;
//空闲队列
BlockingQueue idle; HiKariCP 并没有使用 Java SDK 中的阻塞队列,而是自己实现了一个叫做 ConcurrentBag 的并发容器。ConcurrentBag 的设计最初源自 C#,它的一个核心设计是使用 ThreadLocal 避免部分并发问题,不过 HiKariCP 中的 ConcurrentBag 并没有完全参考 C# 的实现,下面我们来看看它是如何实现的。
ConcurrentBag 中最关键的属性有 4 个,分别是:用于存储所有的数据库连接的共享队列 sharedList、线程本地存储 threadList、等待数据库连接的线程数 waiters 以及分配数据库连接的工具 handoffQueue。其中,handoffQueue 用的是 Java SDK 提供的 SynchronousQueue,SynchronousQueue 主要用于线程之间传递数据。
//用于存储所有的数据库连接
CopyOnWriteArrayList sharedList;
//线程本地存储中的数据库连接
ThreadLocal> threadList;
//等待数据库连接的线程数
AtomicInteger waiters;
//分配数据库连接的工具
SynchronousQueue handoffQueue; 当线程池创建了一个数据库连接时,通过调用 ConcurrentBag 的 add() 方法加入到 ConcurrentBag 中,下面是 add() 方法的具体实现,逻辑很简单,就是将这个连接加入到共享队列 sharedList 中,如果此时有线程在等待数据库连接,那么就通过 handoffQueue 将这个连接分配给等待的线程。
//将空闲连接添加到队列
void add(final T bagEntry){
//加入共享队列
sharedList.add(bagEntry);
//如果有等待连接的线程,
//则通过handoffQueue直接分配给等待的线程
while (waiters.get() > 0
&& bagEntry.getState() == STATE_NOT_IN_USE
&& !handoffQueue.offer(bagEntry)) {
yield();
}
}通过 ConcurrentBag 提供的 borrow() 方法,可以获取一个空闲的数据库连接,borrow() 的主要逻辑是:
① 首先查看线程本地存储是否有空闲连接,如果有,则返回一个空闲的连接;
② 如果线程本地存储中无空闲连接,则从共享队列中获取。
③ 如果共享队列中也没有空闲的连接,则请求线程需要等待。
需要注意的是,线程本地存储中的连接是可以被其他线程窃取的,所以需要用 CAS 方法防止重复分配。在共享队列中获取空闲连接,也采用了 CAS 方法防止重复分配。
T borrow(long timeout, final TimeUnit timeUnit){
// 先查看线程本地存储是否有空闲连接
final List释放连接需要调用 ConcurrentBag 提供的 requite() 方法,该方法的逻辑很简单,首先将数据库连接状态更改为 STATE_NOT_IN_USE,之后查看是否存在等待线程,如果有,则分配给等待线程;如果没有,则将该数据库连接保存到线程本地存储里。
//释放连接
void requite(final T bagEntry){
//更新连接状态
bagEntry.setState(STATE_NOT_IN_USE);
//如果有等待的线程,则直接分配给线程,无需进入任何队列
for (int i = 0; waiters.get() > 0; i++) {
if (bagEntry.getState() != STATE_NOT_IN_USE
|| handoffQueue.offer(bagEntry)) {
return;
} else if ((i & 0xff) == 0xff) {
parkNanos(MICROSECONDS.toNanos(10));
} else {
yield();
}
}
//如果没有等待的线程,则进入线程本地存储
final ListHiKariCP 中的 FastList 和 ConcurrentBag 这两个数据结构使用得非常巧妙,虽然实现起来并不复杂,但是对于性能的提升非常明显,根本原因在于这两个数据结构适用于数据库连接池这个特定的场景。FastList 适用于逆序删除场景;而 ConcurrentBag 通过 ThreadLocal 做一次预分配,避免直接竞争共享资源,非常适合池化资源的分配。
在实际工作中,我们遇到的并发问题千差万别,这时选择合适的并发数据结构就非常重要了。当然能选对的前提是对特定场景的并发特性有深入的了解,只有了解到无谓的性能消耗在哪里,才能对症下药。
17、Actor模型:面向对象原生的并发模型
上学的时候,有门计算机专业课叫做面向对象编程,学这门课的时候有个问题困扰了我很久,按照面向对象编程的理论,对象之间通信需要依靠消息,而实际上,像 C++、Java 这些面向对象的语言,对象之间通信,依靠的是对象方法。对象方法和过程语言里的函数本质上没有区别,有入参、有出参,思维方式很相似,使用起来都很简单。那面向对象理论里的消息是否就等价于面向对象语言里的对象方法呢?很长一段时间里,我都以为对象方法是面向对象理论中消息的一种实现,直到接触到 Actor 模型,才明白消息压根不是这个实现法。
(1)Hello Actor 模型
Actor 模型本质上是一种计算模型,基本的计算单元称为 Actor,换言之,在 Actor 模型中,所有的计算都是在 Actor 中执行的。在面向对象编程里面,一切都是对象;在 Actor 模型里,一切都是 Actor,并且 Actor 之间是完全隔离的,不会共享任何变量。
当看到“不共享任何变量”的时候,相信你一定会眼前一亮,并发问题的根源就在于共享变量,而 Actor 模型中 Actor 之间不共享变量,那用 Actor 模型解决并发问题,一定是相当顺手。的确是这样,所以很多人就把 Actor 模型定义为一种并发计算模型。其实 Actor 模型早在 1973 年就被提出来了,只是直到最近几年才被广泛关注,一个主要原因就在于它是解决并发问题的利器,而最近几年随着多核处理器的发展,并发问题被推到了风口浪尖上。
但是 Java 语言本身并不支持 Actor 模型,所以如果你想在 Java 语言里使用 Actor 模型,就需要借助第三方类库,目前能完备地支持 Actor 模型而且比较成熟的类库就是 Akka 了。在详细介绍 Actor 模型之前,我们就先基于 Akka 写一个 Hello World 程序,让你对 Actor 模型先有个感官的印象。
在下面的示例代码中,我们首先创建了一个 ActorSystem(Actor 不能脱离 ActorSystem 存在);之后创建了一个 HelloActor,Akka 中创建 Actor 并不是 new 一个对象出来,而是通过调用 system.actorOf() 方法创建的,该方法返回的是 ActorRef,而不是 HelloActor;最后通过调用 ActorRef 的 tell() 方法给 HelloActor 发送了一条消息 “Actor” 。
//该Actor当收到消息message后,
//会打印Hello message
static class HelloActor
extends UntypedActor {
@Override
public void onReceive(Object message) {
System.out.println("Hello " + message);
}
}
public static void main(String[] args) {
//创建Actor系统
ActorSystem system = ActorSystem.create("HelloSystem");
//创建HelloActor
ActorRef helloActor =
system.actorOf(Props.create(HelloActor.class));
//发送消息给HelloActor
helloActor.tell("Actor", ActorRef.noSender());
}通过这个例子,你会发现 Actor 模型和面向对象编程契合度非常高,完全可以用 Actor 类比面向对象编程里面的对象,而且 Actor 之间的通信方式完美地遵守了消息机制,而不是通过对象方法来实现对象之间的通信。那 Actor 中的消息机制和面向对象语言里的对象方法有什么区别呢?
(2)消息和对象方法的区别
在没有计算机的时代,异地的朋友往往是通过写信来交流感情的,但信件发出去之后,也许会在寄送过程中弄丢了,也有可能寄到后,对方一直没有时间写回信……这个时候都可以让邮局“背个锅”,不过无论如何,也不过是重写一封,生活继续。
Actor 中的消息机制,就可以类比这现实世界里的写信。Actor 内部有一个邮箱(Mailbox),接收到的消息都是先放到邮箱里,如果邮箱里有积压的消息,那么新收到的消息就不会马上得到处理,也正是因为 Actor 使用单线程处理消息,所以不会出现并发问题。你可以把 Actor 内部的工作模式想象成只有一个消费者线程的生产者 - 消费者模式。
所以,在 Actor 模型里,发送消息仅仅是把消息发出去而已,接收消息的 Actor 在接收到消息后,也不一定会立即处理,也就是说 Actor 中的消息机制完全是异步的。而调用对象方法,实际上是同步的,对象方法 return 之前,调用方会一直等待。
除此之外,调用对象方法,需要持有对象的引用,所有的对象必须在同一个进程中。而在 Actor 中发送消息,类似于现实中的写信,只需要知道对方的地址就可以,发送消息和接收消息的 Actor 可以不在一个进程中,也可以不在同一台机器上。因此,Actor 模型不但适用于并发计算,还适用于分布式计算。
(3)Actor 的规范化定义
通过上面的介绍,相信你应该已经对 Actor 有一个感官印象了,下面我们再来看看 Actor 规范化的定义是什么样的。Actor 是一种基础的计算单元,具体来讲包括三部分能力,分别是:
① 处理能力,处理接收到的消息。
② 存储能力,Actor 可以存储自己的内部状态,并且内部状态在不同 Actor 之间是绝对隔离的。
③ 通信能力,Actor 可以和其他 Actor 之间通信。
当一个 Actor 接收的一条消息之后,这个 Actor 可以做以下三件事:
① 创建更多的 Actor;
② 发消息给其他 Actor;
③ 确定如何处理下一条消息。
其中前两条还是很好理解的,就是最后一条,该如何去理解呢?前面我们说过 Actor 具备存储能力,它有自己的内部状态,所以你也可以把 Actor 看作一个状态机,把 Actor 处理消息看作是触发状态机的状态变化;而状态机的变化往往要基于上一个状态,触发状态机发生变化的时刻,上一个状态必须是确定的,所以确定如何处理下一条消息,本质上不过是改变内部状态。
在多线程里面,由于可能存在竞态条件,所以根据当前状态确定如何处理下一条消息还是有难度的,需要使用各种同步工具,但在 Actor 模型里,由于是单线程处理,所以就不存在竞态条件问题了。
(4)用 Actor 实现累加器
支持并发的累加器可能是最简单并且有代表性的并发问题了,可以基于互斥锁方案实现,也可以基于原子类实现,但今天我们要尝试用 Actor 来实现。
在下面的示例代码中,CounterActor 内部持有累计值 counter,当 CounterActor 接收到一个数值型的消息 message 时,就将累计值 counter += message;但如果是其他类型的消息,则打印当前累计值 counter。在 main() 方法中,我们启动了 4 个线程来执行累加操作。整个程序没有锁,也没有 CAS,但是程序是线程安全的。
//累加器
static class CounterActor extends UntypedActor {
private int counter = 0;
@Override
public void onReceive(Object message){
//如果接收到的消息是数字类型,执行累加操作,
//否则打印counter的值
if (message instanceof Number) {
counter += ((Number) message).intValue();
} else {
System.out.println(counter);
}
}
}
public static void main(String[] args) throws InterruptedException {
//创建Actor系统
ActorSystem system = ActorSystem.create("HelloSystem");
//4个线程生产消息
ExecutorService es = Executors.newFixedThreadPool(4);
//创建CounterActor
ActorRef counterActor =
system.actorOf(Props.create(CounterActor.class));
//生产4*100000个消息
for (int i=0; i<4; i++) {
es.execute(()->{
for (int j=0; j<100000; j++) {
counterActor.tell(1, ActorRef.noSender());
}
});
}
//关闭线程池
es.shutdown();
//等待CounterActor处理完所有消息
Thread.sleep(1000);
//打印结果
counterActor.tell("", ActorRef.noSender());
//关闭Actor系统
system.shutdown();
}Actor 模型是一种非常简单的计算模型,其中 Actor 是最基本的计算单元,Actor 之间是通过消息进行通信。Actor 与面向对象编程(OOP)中的对象匹配度非常高,在面向对象编程里,系统由类似于生物细胞那样的对象构成,对象之间也是通过消息进行通信,所以在面向对象语言里使用 Actor 模型基本上不会有违和感。
在 Java 领域,除了可以使用 Akka 来支持 Actor 模型外,还可以使用 Vert.x,不过相对来说 Vert.x 更像是 Actor 模型的隐式实现,对应关系不像 Akka 那样明显,不过本质上也是一种 Actor 模型。
Actor 可以创建新的 Actor,这些 Actor 最终会呈现出一个树状结构,非常像现实世界里的组织结构,所以利用 Actor 模型来对程序进行建模,和现实世界的匹配度非常高。Actor 模型和现实世界一样都是异步模型,理论上不保证消息百分百送达,也不保证消息送达的顺序和发送的顺序是一致的,甚至无法保证消息会被百分百处理。虽然实现 Actor 模型的厂商都在试图解决这些问题,但遗憾的是解决得并不完美,所以使用 Actor 模型也是有成本的。
18、软件事务内存:借鉴数据库的并发经验
很多同学反馈说,工作了挺长时间但是没有机会接触并发编程,实际上我们天天都在写并发程序,只不过并发相关的问题都被类似 Tomcat 这样的 Web 服务器以及 MySQL 这样的数据库解决了。尤其是数据库,在解决并发问题方面,可谓成绩斐然,它的事务机制非常简单易用,能甩 Java 里面的锁、原子类十条街。技术无边界,很显然要借鉴一下。
其实很多编程语言都有从数据库的事务管理中获得灵感,并且总结出了一个新的并发解决方案:软件事务内存(Software Transactional Memory,简称 STM)。传统的数据库事务,支持 4 个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability),也就是大家常说的 ACID,STM 由于不涉及到持久化,所以只支持 ACI。
STM 的使用很简单,下面我们以经典的转账操作为例,看看用 STM 该如何实现。
(1)用 STM 实现转账
并发转账的例子,示例代码如下。简单地使用 synchronized 将 transfer() 方法变成同步方法并不能解决并发问题,因为还存在死锁问题。
class UnsafeAccount {
//余额
private long balance;
//构造函数
public UnsafeAccount(long balance) {
this.balance = balance;
}
//转账
void transfer(UnsafeAccount target, long amt){
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}该转账操作若使用数据库事务就会非常简单,如下面的示例代码所示。如果所有 SQL 都正常执行,则通过 commit() 方法提交事务;如果 SQL 在执行过程中有异常,则通过 rollback() 方法回滚事务。数据库保证在并发情况下不会有死锁,而且还能保证前面我们说的原子性、一致性、隔离性和持久性,也就是 ACID。
Connection conn = null;
try{
//获取数据库连接
conn = DriverManager.getConnection();
//设置手动提交事务
conn.setAutoCommit(false);
//执行转账SQL
......
//提交事务
conn.commit();
} catch (Exception e) {
//出现异常回滚事务
conn.rollback();
}那如果用 STM 又该如何实现呢?Java 语言并不支持 STM,不过可以借助第三方的类库来支持,Multiverse就是个不错的选择。下面的示例代码就是借助 Multiverse 实现了线程安全的转账操作,相比较上面线程不安全的 UnsafeAccount,其改动并不大,仅仅是将余额的类型从 long 变成了 TxnLong ,将转账的操作放到了 atomic(()->{}) 中。
class Account{
//余额
private TxnLong balance;
//构造函数
public Account(long balance){
this.balance = StmUtils.newTxnLong(balance);
}
//转账
public void transfer(Account to, int amt){
//原子化操作
atomic(()->{
if (this.balance.get() > amt) {
this.balance.decrement(amt);
to.balance.increment(amt);
}
});
}
}一个关键的 atomic() 方法就把并发问题解决了,这个方案看上去比传统的方案的确简单了很多,那它是如何实现的呢?数据库事务发展了几十年了,目前被广泛使用的是 MVCC(全称是 Multi-Version Concurrency Control),也就是多版本并发控制。
MVCC 可以简单地理解为数据库事务在开启的时候,会给数据库打一个快照,以后所有的读写都是基于这个快照的。当提交事务的时候,如果所有读写过的数据在该事务执行期间没有发生过变化,那么就可以提交;如果发生了变化,说明该事务和有其他事务读写的数据冲突了,这个时候是不可以提交的。
为了记录数据是否发生了变化,可以给每条数据增加一个版本号,这样每次成功修改数据都会增加版本号的值。MVCC 的工作原理和乐观锁非常相似。有不少 STM 的实现方案都是基于 MVCC 的,例如知名的 Clojure STM。
下面我们就用最简单的代码基于 MVCC 实现一个简版的 STM,这样你会对 STM 以及 MVCC 的工作原理有更深入的认识。
(1)自己实现 STM
我们首先要做的,就是让 Java 中的对象有版本号,在下面的示例代码中,VersionedRef 这个类的作用就是将对象 value 包装成带版本号的对象。按照 MVCC 理论,数据的每一次修改都对应着一个唯一的版本号,所以不存在仅仅改变 value 或者 version 的情况,用不变性模式就可以很好地解决这个问题,所以 VersionedRef 这个类被我们设计成了不可变的。
所有对数据的读写操作,一定是在一个事务里面,TxnRef 这个类负责完成事务内的读写操作,读写操作委托给了接口 Txn,Txn 代表的是读写操作所在的当前事务, 内部持有的 curRef 代表的是系统中的最新值。
//带版本号的对象引用
public final class VersionedRef {
final T value;
final long version;
//构造方法
public VersionedRef(T value, long version) {
this.value = value;
this.version = version;
}
}
//支持事务的引用
public class TxnRef {
//当前数据,带版本号
volatile VersionedRef curRef;
//构造方法
public TxnRef(T value) {
this.curRef = new VersionedRef(value, 0L);
}
//获取当前事务中的数据
public T getValue(Txn txn) {
return txn.get(this);
}
//在当前事务中设置数据
public void setValue(T value, Txn txn) {
txn.set(this, value);
}
} STMTxn 是 Txn 最关键的一个实现类,事务内对于数据的读写,都是通过它来完成的。STMTxn 内部有两个 Map:inTxnMap,用于保存当前事务中所有读写的数据的快照;writeMap,用于保存当前事务需要写入的数据。每个事务都有一个唯一的事务 ID txnId,这个 txnId 是全局递增的。
STMTxn 有三个核心方法,分别是读数据的 get() 方法、写数据的 set() 方法和提交事务的 commit() 方法。其中,get() 方法将要读取数据作为快照放入 inTxnMap,同时保证每次读取的数据都是一个版本。set() 方法会将要写入的数据放入 writeMap,但如果写入的数据没被读取过,也会将其放入 inTxnMap。
至于 commit() 方法,我们为了简化实现,使用了互斥锁,所以事务的提交是串行的。commit() 方法的实现很简单,首先检查 inTxnMap 中的数据是否发生过变化,如果没有发生变化,那么就将 writeMap 中的数据写入(这里的写入其实就是 TxnRef 内部持有的 curRef);如果发生过变化,那么就不能将 writeMap 中的数据写入了。
//事务接口
public interface Txn {
T get(TxnRef ref);
void set(TxnRef ref, T value);
}
//STM事务实现类
public final class STMTxn implements Txn {
//事务ID生成器
private static AtomicLong txnSeq = new AtomicLong(0);
//当前事务所有的相关数据
private Map inTxnMap = new HashMap<>();
//当前事务所有需要修改的数据
private Map writeMap = new HashMap<>();
//当前事务ID
private long txnId;
//构造函数,自动生成当前事务ID
STMTxn() {
txnId = txnSeq.incrementAndGet();
}
//获取当前事务中的数据
@Override
public T get(TxnRef ref) {
//将需要读取的数据,加入inTxnMap
if (!inTxnMap.containsKey(ref)) {
inTxnMap.put(ref, ref.curRef);
}
return (T) inTxnMap.get(ref).value;
}
//在当前事务中修改数据
@Override
public void set(TxnRef ref, T value) {
//将需要修改的数据,加入inTxnMap
if (!inTxnMap.containsKey(ref)) {
inTxnMap.put(ref, ref.curRef);
}
writeMap.put(ref, value);
}
//提交事务
boolean commit() {
synchronized (STM.commitLock) {
//是否校验通过
boolean isValid = true;
//校验所有读过的数据是否发生过变化
for(Map.Entry entry : inTxnMap.entrySet()){
VersionedRef curRef = entry.getKey().curRef;
VersionedRef readRef = entry.getValue();
//通过版本号来验证数据是否发生过变化
if (curRef.version != readRef.version) {
isValid = false;
break;
}
}
//如果校验通过,则所有更改生效
if (isValid) {
writeMap.forEach((k, v) -> {
k.curRef = new VersionedRef(v, txnId);
});
}
return isValid;
}
} 下面我们来模拟实现 Multiverse 中的原子化操作 atomic()。atomic() 方法中使用了类似于 CAS 的操作,如果事务提交失败,那么就重新创建一个新的事务,重新执行。
@FunctionalInterface
public interface TxnRunnable {
void run(Txn txn);
}
//STM
public final class STM {
//私有化构造方法
private STM() {
//提交数据需要用到的全局锁
static final Object commitLock = new Object();
//原子化提交方法
public static void atomic(TxnRunnable action) {
boolean committed = false;
//如果没有提交成功,则一直重试
while (!committed) {
//创建新的事务
STMTxn txn = new STMTxn();
//执行业务逻辑
action.run(txn);
//提交事务
committed = txn.commit();
}
}
}}就这样,我们自己实现了 STM,并完成了线程安全的转账操作,使用方法和 Multiverse 差不多,这里就不赘述了,具体代码如下面所示。
class Account {
//余额
private TxnRef balance;
//构造方法
public Account(int balance) {
this.balance = new TxnRef(balance);
}
//转账操作
public void transfer(Account target, int amt){
STM.atomic((txn)->{
Integer from = balance.getValue(txn);
balance.setValue(from-amt, txn);
Integer to = target.balance.getValue(txn);
target.balance.setValue(to+amt, txn);
});
}
} STM 借鉴的是数据库的经验,数据库虽然复杂,但仅仅存储数据,而编程语言除了有共享变量之外,还会执行各种 I/O 操作,很显然 I/O 操作是很难支持回滚的。所以,STM 也不是万能的。目前支持 STM 的编程语言主要是函数式语言,函数式语言里的数据天生具备不可变性,利用这种不可变性实现 STM 相对来说更简单。
19、协程:更轻量级的线程
Java 语言里解决并发问题靠的是多线程,但线程是个重量级的对象,不能频繁创建、销毁,而且线程切换的成本也很高,为了解决这些问题,Java SDK 提供了线程池。然而用好线程池并不容易,Java 围绕线程池提供了很多工具类,这些工具类学起来也不容易。那有没有更好的解决方案呢?Java 语言里目前还没有,但是其他语言里有,这个方案就是协程(Coroutine)。
我们可以把协程简单地理解为一种轻量级的线程。从操作系统的角度来看,线程是在内核态中调度的,而协程是在用户态调度的,所以相对于线程来说,协程切换的成本更低。协程虽然也有自己的栈,但是相比线程栈要小得多,典型的线程栈大小差不多有 1M,而协程栈的大小往往只有几 K 或者几十 K。所以,无论是从时间维度还是空间维度来看,协程都比线程轻量得多。
支持协程的语言还是挺多的,例如 Golang、Python、Lua、Kotlin 等都支持协程。下面我们就以 Golang 为代表,看看协程是如何在 Golang 中使用的。
(1)Golang 中的协程
在 Golang 中创建协程非常简单,在下面的示例代码中,要让 hello() 方法在一个新的协程中执行,只需要go hello("World") 这一行代码就搞定了。你可以对比着想想在 Java 里是如何“辛勤”地创建线程和线程池的吧,我的感觉一直都是:每次写完 Golang 的代码,就再也不想写 Java 代码了。
import (
"fmt"
"time"
)
func hello(msg string) {
fmt.Println("Hello " + msg)
}
func main() {
//在新的协程中执行hello方法
go hello("World")
fmt.Println("Run in main")
//等待100毫秒让协程执行结束
time.Sleep(100 * time.Millisecond)
}利用协程能够很好地实现 Thread-Per-Message 模式。Thread-Per-Message 模式非常简单,其实越是简单的模式,功能上就越稳定,可理解性也越好。
下面的示例代码是用 Golang 实现的 echo 程序的服务端,用的是 Thread-Per-Message 模式,为每个成功建立连接的 socket 分配一个协程,相比 Java 线程池的实现方案,Golang 中协程的方案更简单。
import (
"log"
"net"
)
func main() {
//监听本地9090端口
socket, err := net.Listen("tcp", "127.0.0.1:9090")
if err != nil {
log.Panicln(err)
}
defer socket.Close()
for {
//处理连接请求
conn, err := socket.Accept()
if err != nil {
log.Panicln(err)
}
//处理已经成功建立连接的请求
go handleRequest(conn)
}
}
//处理已经成功建立连接的请求
func handleRequest(conn net.Conn) {
defer conn.Close()
for {
buf := make([]byte, 1024)
//读取请求数据
size, err := conn.Read(buf)
if err != nil {
return
}
//回写相应数据
conn.Write(buf[:size])
}
}(2)利用协程实现同步
其实协程并不仅限于实现 Thread-Per-Message 模式,它还可以将异步模式转换为同步模式。异步编程虽然近几年取得了长足发展,但是异步的思维模式对于普通人来讲毕竟是有难度的,只有线性的思维模式才是适合所有人的。而线性的思维模式反映到编程世界,就是同步。
在 Java 里使用多线程并发地处理 I/O,基本上用的都是异步非阻塞模型,这种模型的异步主要是靠注册回调函数实现的,那能否都使用同步处理呢?显然是不能的。因为同步意味着等待,而线程等待,本质上就是一种严重的浪费。不过对于协程来说,等待的成本就没有那么高了,所以基于协程实现同步非阻塞是一个可行的方案。
OpenResty 里实现的 cosocket 就是一种同步非阻塞方案,借助 cosocket 我们可以用线性的思维模式来编写非阻塞的程序。下面的示例代码是用 cosocket 实现的 socket 程序的客户端,建立连接、发送请求、读取响应所有的操作都是同步的,由于 cosocket 本身是非阻塞的,所以这些操作虽然是同步的,但是并不会阻塞。
-- 创建socket
local sock = ngx.socket.tcp()
-- 设置socket超时时间
sock:settimeouts(connect_timeout, send_timeout, read_timeout)
-- 连接到目标地址
local ok, err = sock:connect(host, port)
if not ok then
- -- 省略异常处理
end
-- 发送请求
local bytes, err = sock:send(request_data)
if not bytes then
-- 省略异常处理
end
-- 读取响应
local line, err = sock:receive()
if err then
-- 省略异常处理
end
-- 关闭socket
sock:close()
-- 处理读取到的数据line
handle(line)(3)结构化并发编程
Golang 中的 go 语句让协程用起来太简单了,但是这种简单也蕴藏着风险。要深入了解这个风险是什么,就需要先了解一下 goto 语句的前世今生。
在我上学的时候,各种各样的编程语言书籍中都会谈到不建议使用 goto 语句,原因是 goto 语句会让程序变得混乱,当时对于这个问题我也没有多想,不建议用那就不用了。那为什么 goto 语句会让程序变得混乱呢?混乱具体指的又是什么呢?多年之后,我才了解到所谓的混乱指的是代码的书写顺序和执行顺序不一致。代码的书写顺序,代表的是我们的思维过程,如果思维的过程与代码执行的顺序不一致,那就会干扰我们对代码的理解。我们的思维是线性的,傻傻地一条道儿跑到黑,而 goto 语句太灵活,随时可以穿越时空,实在是太“混乱”了。
首先发现 goto 语句是“毒药”的人是著名的计算机科学家艾兹格·迪科斯彻(Edsger Dijkstra),同时他还提出了结构化程序设计。在结构化程序设计中,可以使用三种基本控制结构来代替 goto,这三种基本的控制结构就是今天我们广泛使用的顺序结构、选择结构和循环结构。


这三种基本的控制结构奠定了今天高级语言的基础,如果仔细观察这三种结构,你会发现它们的入口和出口只有一个,这意味它们是可组合的,而且组合起来一定是线性的,整体来看,代码的书写顺序和执行顺序也是一致的。
我们以前写的并发程序,是否违背了结构化程序设计呢?这个问题以前并没有被关注,但是最近两年,随着并发编程的快速发展,已经开始有人关注了,而且剑指 Golang 中的 go 语句,指其为“毒药”,类比的是 goto 语句。详情可以参考相关的文章。
Golang 中的 go 语句不过是快速创建协程的方法而已,这篇文章本质上并不仅仅在批判 Golang 中的 go 语句,而是在批判开启新的线程(或者协程)异步执行这种粗糙的做法,违背了结构化程序设计,Java 语言其实也在其列。
当开启一个新的线程时,程序会并行地出现两个分支,主线程一个分支,子线程一个分支,这两个分支很多情况下都是天各一方、永不相见。而结构化的程序,可以有分支,但是最终一定要汇聚,不能有多个出口,因为只有这样它们组合起来才是线性的。
最近几年支持协程的开发语言越来越多了,Java OpenSDK 中 Loom 项目的目标就是支持协程,相信不久的将来,Java 程序员也可以使用协程来解决并发问题了。
计算机里很多面向开发人员的技术,大多数都是在解决一个问题:易用性。协程作为一项并发编程技术,本质上也不过是解决并发工具的易用性问题而已。对于易用性,我觉得最重要的就是要适应我们的思维模式,在工作的前几年,我并没有怎么关注它,但是最近几年思维模式已成为我重点关注的对象。因为思维模式对工作的很多方面都会产生影响,例如质量。
一个软件产品是否能够活下去,从质量的角度看,最核心的就是代码写得好。那什么样的代码是好代码呢?我觉得,最根本的是可读性好。可读性好的代码,意味着大家都可以上手,而且上手后不会大动干戈。那如何让代码的可读性好呢?很简单,换位思考,用大众、普通的思维模式去写代码,而不是炫耀自己的各种设计能力。我觉得好的代码,就像人民的艺术一样,应该是为人民群众服务的,只有根植于广大群众之中,才有生命力。
20、CSP模型:Golang的主力队员
Golang 是一门号称从语言层面支持并发的编程语言,支持并发是 Golang 一个非常重要的特性,Golang 支持协程,协程可以类比 Java 中的线程,解决并发问题的难点就在于线程(协程)之间的协作。
那 Golang 是如何解决协作问题的呢?
总的来说,Golang 提供了两种不同的方案:一种方案支持协程之间以共享内存的方式通信,Golang 提供了管程和原子类来对协程进行同步控制,这个方案与 Java 语言类似;另一种方案支持协程之间以消息传递(Message-Passing)的方式通信,本质上是要避免共享,Golang 的这个方案是基于 CSP(Communicating Sequential Processes)模型实现的。Golang 比较推荐的方案是后者。
(1)什么是 CSP 模型
Actor 模型中 Actor 之间就是不能共享内存的,彼此之间通信只能依靠消息传递的方式。Golang 实现的 CSP 模型和 Actor 模型看上去非常相似,Golang 程序员中有句格言:“不要以共享内存方式通信,要以通信方式共享内存(Don’t communicate by sharing memory, share memory by communicating)。”虽然 Golang 中协程之间,也能够以共享内存的方式通信,但是并不推荐;而推荐的以通信的方式共享内存,实际上指的就是协程之间以消息传递方式来通信。
下面我们先结合一个简单的示例,看看 Golang 中协程之间是如何以消息传递的方式实现通信的。我们示例的目标是打印从 1 累加到 100 亿的结果,如果使用单个协程来计算,大概需要 4 秒多的时间。单个协程,只能用到 CPU 中的一个核,为了提高计算性能,我们可以用多个协程来并行计算,这样就能发挥多核的优势了。
在下面的示例代码中,我们用了 4 个子协程来并行执行,这 4 个子协程分别计算[1, 25 亿]、(25 亿, 50 亿]、(50 亿, 75 亿]、(75 亿, 100 亿],最后再在主协程中汇总 4 个子协程的计算结果。主协程要汇总 4 个子协程的计算结果,势必要和 4 个子协程之间通信,Golang 中协程之间通信推荐的是使用 channel,channel 你可以形象地理解为现实世界里的管道。另外,calc() 方法的返回值是一个只能接收数据的 channel ch,它创建的子协程会把计算结果发送到这个 ch 中,而主协程也会将这个计算结果通过 ch 读取出来。
import (
"fmt"
"time"
)
func main() {
// 变量声明
var result, i uint64
// 单个协程执行累加操作
start := time.Now()
for i = 1; i <= 10000000000; i++ {
result += i
}
// 统计计算耗时
elapsed := time.Since(start)
fmt.Printf("执行消耗的时间为:", elapsed)
fmt.Println(", result:", result)
// 4个协程共同执行累加操作
start = time.Now()
ch1 := calc(1, 2500000000)
ch2 := calc(2500000001, 5000000000)
ch3 := calc(5000000001, 7500000000)
ch4 := calc(7500000001, 10000000000)
// 汇总4个协程的累加结果
result = <-ch1 + <-ch2 + <-ch3 + <-ch4
// 统计计算耗时
elapsed = time.Since(start)
fmt.Printf("执行消耗的时间为:", elapsed)
fmt.Println(", result:", result)
}
// 在协程中异步执行累加操作,累加结果通过channel传递
func calc(from uint64, to uint64) <-chan uint64 {
// channel用于协程间的通信
ch := make(chan uint64)
// 在协程中执行累加操作
go func() {
result := from
for i := from + 1; i <= to; i++ {
result += i
}
// 将结果写入channel
ch <- result
}()
// 返回结果是用于通信的channel
return ch
}(2)CSP 模型与生产者 - 消费者模式
你可以简单地把 Golang 实现的 CSP 模型类比为生产者 - 消费者模式,而 channel 可以类比为生产者 - 消费者模式中的阻塞队列。不过,需要注意的是 Golang 中 channel 的容量可以是 0,容量为 0 的 channel 在 Golang 中被称为无缓冲的 channel,容量大于 0 的则被称为有缓冲的 channel。
无缓冲的 channel 类似于 Java 中提供的 SynchronousQueue,主要用途是在两个协程之间做数据交换。比如上面累加器的示例代码中,calc() 方法内部创建的 channel 就是无缓冲的 channel。
而创建一个有缓冲的 channel 也很简单,在下面的示例代码中,我们创建了一个容量为 4 的 channel,同时创建了 4 个协程作为生产者、4 个协程作为消费者。
// 创建一个容量为4的channel
ch := make(chan int, 4)
// 创建4个协程,作为生产者
for i := 0; i < 4; i++ {
go func() {
ch <- 7
}()
}
// 创建4个协程,作为消费者
for i := 0; i < 4; i++ {
go func() {
o := <-ch
fmt.Println("received:", o)
}()
}Golang 中的 channel 是语言层面支持的,所以可以使用一个左向箭头(<-)来完成向 channel 发送数据和读取数据的任务,使用上还是比较简单的。Golang 中的 channel 是支持双向传输的,所谓双向传输,指的是一个协程既可以通过它发送数据,也可以通过它接收数据。
不仅如此,Golang 中还可以将一个双向的 channel 变成一个单向的 channel,在累加器的例子中,calc() 方法中创建了一个双向 channel,但是返回的就是一个只能接收数据的单向 channel,所以主协程中只能通过它接收数据,而不能通过它发送数据,如果试图通过它发送数据,编译器会提示错误。对比之下,双向变单向的功能,如果以 SDK 方式实现,还是很困难的。
(3)CSP 模型与 Actor 模型的区别
同样是以消息传递的方式来避免共享,那 Golang 实现的 CSP 模型和 Actor 模型有什么区别呢?
第一个最明显的区别就是:Actor 模型中没有 channel。虽然 Actor 模型中的 mailbox 和 channel 非常像,看上去都像个 FIFO 队列,但是区别还是很大的。Actor 模型中的 mailbox 对于程序员来说是“透明”的,mailbox 明确归属于一个特定的 Actor,是 Actor 模型中的内部机制;而且 Actor 之间是可以直接通信的,不需要通信中介。但 CSP 模型中的 channel 就不一样了,它对于程序员来说是“可见”的,是通信的中介,传递的消息都是直接发送到 channel 中的。
第二个区别是:Actor 模型中发送消息是非阻塞的,而 CSP 模型中是阻塞的。Golang 实现的 CSP 模型,channel 是一个阻塞队列,当阻塞队列已满的时候,向 channel 中发送数据,会导致发送消息的协程阻塞。
第三个区别则是关于消息送达的。 Actor 模型理论上不保证消息百分百送达,而在 Golang 实现的 CSP 模型中,是能保证消息百分百送达的。不过这种百分百送达也是有代价的,那就是有可能会导致死锁。
比如,下面这段代码就存在死锁问题,在主协程中,我们创建了一个无缓冲的 channel ch,然后从 ch 中接收数据,此时主协程阻塞,main() 方法中的主协程阻塞,整个应用就阻塞了。这就是 Golang 中最简单的一种死锁。
func main() {
// 创建一个无缓冲的channel
ch := make(chan int)
// 主协程会阻塞在此处,发生死锁
<- ch
}Golang 中虽然也支持传统的共享内存的协程间通信方式,但是推荐的还是使用 CSP 模型,以通信的方式共享内存。
Golang 中实现的 CSP 模型功能上还是很丰富的,例如支持 select 语句,select 语句类似于网络编程里的多路复用函数 select(),只要有一个 channel 能够发送成功或者接收到数据就可以跳出阻塞状态。鉴于篇幅原因,我就点到这里,不详细介绍那么多了。
CSP 模型是托尼·霍尔(Tony Hoare)在 1978 年提出的,不过这个模型这些年一直都在发展,其理论远比 Golang 的实现复杂得多,如果你感兴趣,可以参考霍尔写的Communicating Sequential Processes这本电子书。另外,霍尔在并发领域还有一项重要成就,那就是提出了霍尔管程模型,这个你应该很熟悉了,Java 领域解决并发问题的理论基础就是它。
Java 领域可以借助第三方的类库JCSP来支持 CSP 模型,相比 Golang 的实现,JCSP 更接近理论模型,如果你感兴趣,可以下载学习。不过需要注意的是,JCSP 并没有经过广泛的生产环境检验,所以并不建议你在生产环境中使用。