RocketMQ 中DLedger框架 基于Raft算法实现选主及日志同步
broker 在集群模式下,需要实现两个功能点:
1、多节点broker之间commitLog 日志文件内容同步;无论是 写主读从,一写多读,多主模式等。 同一个group内 master-slave 集群内,数据需要同步
2、能够自动容灾,即主节点挂了之后能够自动产生新的主节点,不影响对外提供服务
数据同步:传统 Mater/Slave 模式就可以支持
自动选主及切换: Zookeeper组件, 以及基于Raft等 分布式一致性算法实现。
基于zookeeper组件,需要额外部署zk集群
raft 算法支持选主和日志复制等功能。rocketMQ DLedger 就是基于raft算法,实现的高可用的多副本的broker架构
DLedger 是如何实现raft算法的? rocketMQ 是如何将 commitLog 与 DLedger 相结合的?
broker架构图变化:
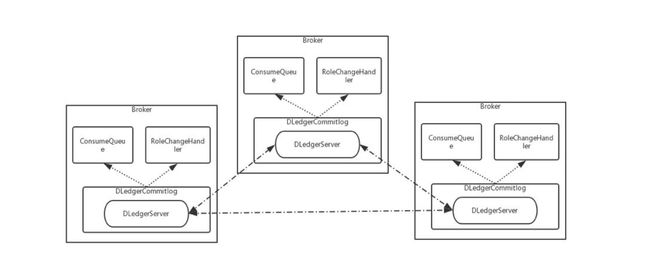
与原有Maser/Slave 结构相比,多了 RoleChangeHandler, commitLog变为 DLedgerCommitLog
DLedger 将 原有 commitLog 进行包装,产生一种新的数据格式的log。
不影响原有的commitLog的功能作用。同时实现DLedger自身功能
DLedgerCommitlog 结构: 给原有commitLog 加了一个 head。即commitLog内容作为DLedgerCommitlog 的body

Raft算法:分布式一致性算法。
主要功能体现在三个方面:1)选主; 2)日志复制; 3)安全性
选主
LeaderElector
角色(Role):
1) Leader 主节点:发送心跳,和日志;如果发现比leader更新的任期(term),则变为follower。
2) Candidate 候选节点: 发送投票请求用于成为leader,如果发现比leader更新的任期(term),则变为follower
3) Follower 跟随者: 响应 Leader 和 Candidate的请求。超过选举时间未收到Leader的心跳请求和candidate的选举请求,则成为candidate。Follower 不能发起投票,不能直接成为leader
raft算法,三种状态间的流转过程:
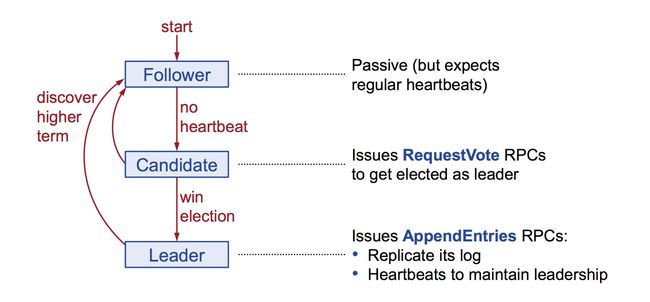
DLedger实现有所不同。
DLedger中实现:
主要类:
DLedgerConfig :多副本模块相关的配置信息
MemberState : 节点状态。上述三种节点状态
协议相关:
DLedgerClientProtocol DLedgerProtocol DLedgerProtocolHander
节点封装:DLedgerServer
DLedgerLeaderElector : 选主实现
主要实现:io.openmessaging.storage.dledger.DLedgerLeaderElector

流程:
1、DLedgerServer#startup() 节点启动: 其中会启动选主器
DLedgerLeaderElector#startup()
线程每 10 ms 会检查一次节点角色,并作相应处理
public class StateMaintainer extends ShutdownAbleThread {
public StateMaintainer(String name, Logger logger) {
super(name, logger);
}
@Override public void doWork() {
try {
// 如果该节点参与了选举,则需要重置定时器,并启用状态机
if (DLedgerLeaderElector.this.dLedgerConfig.isEnableLeaderElector()) {
DLedgerLeaderElector.this.refreshIntervals(dLedgerConfig);
DLedgerLeaderElector.this.maintainState();
}
sleep(10);
} catch (Throwable t) {
DLedgerLeaderElector.logger.error("Error in heartbeat", t);
}
}
}2、判断当前节点是否参与选主,并根据当前节点的角色做不同处理
private void maintainState() throws Exception {
// 核心逻辑处理
if (memberState.isLeader()) {
// 如果当前节点是leader,则处理leader逻辑: 将当前节点term确认为term,确认leaderId,并发送给其他节点
// 领导者,主节点,该状态下,需要定时向从节点发送心跳包,用来传播数据、确保其领导地位。
maintainAsLeader();
} else if (memberState.isFollower()) {
/**
* 如果当前节点是 follower, 则努力成为候选节点。
* 会开启定时器,尝试进入到candidate状态,以便发起投票选举,同时一旦收到主节点的心跳包,则重置定时器。
*/
maintainAsFollower();
} else {
// 如果当前节点为候选节点,则需要参与投票逻辑.. raft 核心逻辑
maintainAsCandidate();
}
}节点状态开始默认为候选者
MemberState private volatile Role role = CANDIDATE;
所以会执行:maintainAsCandidate(); 方法
3、初始化后第一次进行选主:
初始化候选者后,会发起投票
candidate 每次发起投票时,会先给自己投一票
假如开始时,所有节点一起启动,则所有节点都给自己投票。当收到其他节点的投票请求时,因为已经投票给自己,则本轮投票不会投给其他节点。那么如果候选者每次投给自己,则永远选不出leader了吗?
由于节点收到其他节点投票请求时已经投给自己,则会返回 REJECT_ALREADY_VOTED
此时发起投票节点处理为
parseResult = VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT; nextTimeToRequestVote = getNextTimeToRequestVote();
此时获取下次投票时间:getNextTimeToRequestVote() 会返回 300 - 1000 ms 之间随机时间。 思考下:返回随机时间而不是固定时间的原因
经过上述操作后,后续到第三轮能选出leader。
由于有一个节点(下文称为node0)会先到投票时间。此时会先更新term,且会将voteFor更新为null
// 如果上一次的投票结果为 等待下一次投票 或者 需要更新term . 则会先更新term
if (lastParseResult == VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT || needIncreaseTermImmediately) {
long prevTerm = memberState.currTerm();
term = memberState.nextTerm();
logger.info("{}_[INCREASE_TERM] from {} to {}", memberState.getSelfId(), prevTerm, term);
lastParseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
}第二轮发起投票时,由于其他节点还没更新term。所以其他节点收到投票请求后,term小于投票请求的term,会返回还没准备好投票并设置 needIncreaseTermImmediately 为true,先更新term。 同样会执行上述方法。
发起投票请求节点(node0),收到其他节点未准备好应答后,会设置结果为 parseResult = VoteResponse.ParseResult.REVOTE_IMMEDIATELY;
立马重新发起投票。
第三轮:
node0立马重新发起投票,其他节点由于更新了term和node0一致,且设置了voteFor 为null,此时会同意投票请求。node0会成为leader
成为leader后的操作:
changeRoleToLeader(term)
更新leaderId,更新term。更新role为leader。等待下一次 StateMaintainer 线程执行maintainAsLeader();方法
4、leader 当选后会做哪些事情
判断心跳包发送间隔并发送心跳包。心跳包中包含的内容有:当前的term,leaderId。
leader通过不断地发送心跳包来维持自己的leader地位
其他节点收到心跳包的处理 handleHeartBeat(),主要判断term和leaderId是否符合预期。
1)如果心跳包的term小于当前节点,返回term过期,说明leader节点已经过期了需要重新选举了;
2)如果心跳包term等于当前节点,符合预期。同时判断心跳包中的leaderId和当前节点维护的leaderId是否一致,第一次收到心跳包时,当前节点没有leaderId,变成follower状态。并设置leaderId
3)如果心跳包的term大于当前节点。说明当前节点term需要增加了,要更新到和leader一致。 设置 needIncreaseTermImmediately=true。并更新节点为cadidate状态。
此处有个注意点:在DLedger中,只要cadidate才能更新term。和raft算法中有所不同。
5、假如leader宕机了,出问题了。不会发心跳包了。等情况
follower在超时时间内未收心跳包,则会成为cadidate。并走候选者逻辑,可能会发起投票。重新选主
private void maintainAsFollower() {
if (DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > 2 * heartBeatTimeIntervalMs) {
synchronized (memberState) {
if (memberState.isFollower() && (DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > maxHeartBeatLeak * heartBeatTimeIntervalMs)) {
logger.info("[{}][HeartBeatTimeOut] lastLeaderHeartBeatTime: {} heartBeatTimeIntervalMs: {} lastLeader={}", memberState.getSelfId(), new Timestamp(lastLeaderHeartBeatTime), heartBeatTimeIntervalMs, memberState.getLeaderId());
changeRoleToCandidate(memberState.currTerm());
}
}
}
}