JavaScript教程9 - Node.js
Node.js
安装Node.js
https://nodejs.org/
npm
npm其实是Node.js的包管理工具(package manager)。
命令行模式
执行node hello.js运行一个.js文件。
Node交互模式
可以执行node进入Node交互式环境
使用严格模式
如果在JavaScript文件开头写上’use strict’;,那么Node在执行该JavaScript时将使用严格模式。但是,在服务器环境下,如果有很多JavaScript文件,每个文件都写上’use strict’;很麻烦。我们可以给Nodejs传递一个参数,让Node直接为所有js文件开启严格模式:
node --use_strict calc.js
后续代码,如无特殊说明,我们都会直接给Node传递–use_strict参数来开启严格模式。
小结
用文本编辑器写JavaScript程序,然后保存为后缀为.js的文件,就可以用node直接运行这个程序了。
Node的交互模式和直接运行.js文件有什么区别呢?
直接输入node进入交互模式,相当于启动了Node解释器,但是等待你一行一行地输入源代码,每输入一行就执行一行。
直接运行node hello.js文件相当于启动了Node解释器,然后一次性把hello.js文件的源代码给执行了,你是没有机会以交互的方式输入源代码的。
在编写JavaScript代码的时候,完全可以一边在文本编辑器里写代码,一边开一个Node交互式命令窗口,在写代码的过程中,把部分代码粘到命令行去验证,事半功倍!前提是得有个27’的超大显示器!
搭建Node开发环境
安装Visual Studio Code
https://code.visualstudio.com/
运行和调试JavaScript
VS Code以文件夹作为工程目录(Workspace Dir),所有的JavaScript文件都存放在该目录下。此外,VS Code在工程目录下还需要一个.vscode的配置目录,里面存放里VS Code需要的配置文件。
模块
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Node环境中,一个.js文件就称之为一个模块(module)。
使用模块有什么好处?
- 最大的好处是大大提高了代码的可维护性。
- 其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Node内置的模块和来自第三方的模块。
- 使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。
我们把hello.js改造一下,创建一个函数,这样我们就可以在其他地方调用这个函数:
'use strict';
var s = 'Hello';
function greet(name) {
console.log(s + ', ' + name + '!');
}
module.exports = greet; // 把函数greet作为模块的输出暴露出去,这样其他模块就可以使用greet函数了。
问题是其他模块怎么使用hello模块的这个greet函数呢?我们再编写一个main.js文件,调用hello模块的greet函数:
'use strict';
// 引入hello模块:
var greet = require('./hello'); // 变量greet就是在hello.js中我们用module.exports = greet;输出的greet函数。在使用require()引入模块的时候,请注意模块的相对路径。
var s = 'xxx';
greet(s); // Hello, xxx!
CommonJS规范
这种模块加载机制被称为CommonJS规范。在这个规范下,每个.js文件都是一个模块,它们内部各自使用的变量名和函数名都互不冲突,例如,hello.js和main.js都申明了全局变量var s = ‘xxx’,但互不影响。
一个模块想要对外暴露变量(函数也是变量),可以用module.exports = variable;,一个模块要引用其他模块暴露的变量,用var ref = require(‘module_name’);就拿到了引用模块的变量。
深入了解模块原理
JavaScript语言本身并没有一种模块机制来保证不同模块可以使用相同的变量名。
Node.js也并不会增加任何JavaScript语法。实现“模块”功能的奥妙就在于JavaScript是一种函数式编程语言,它支持闭包。如果我们把一段JavaScript代码用一个函数包装起来,这段代码的所有“全局”变量就变成了函数内部的局部变量。
但是,模块的输出module.exports怎么实现?
变量module是Node在加载js文件前准备的一个变量,并将其传入加载函数,我们在hello.js中可以直接使用变量module原因就在于它实际上是函数的一个参数:
module.exports = greet;
通过把参数module传递给load()函数,hello.js就顺利地把一个变量传递给了Node执行环境,Node会把module变量保存到某个地方。
由于Node保存了所有导入的module,当我们用require()获取module时,Node找到对应的module,把这个module的exports变量返回,这样,另一个模块就顺利拿到了模块的输出:
var greet = require('./hello');
module.exports vs exports
方法一:对module.exports赋值:
// hello.js
function hello() {
console.log('Hello, world!');
}
function greet(name) {
console.log('Hello, ' + name + '!');
}
module.exports = {
hello: hello,
greet: greet
};
方法二:直接使用exports:
// hello.js
function hello() {
console.log('Hello, world!');
}
function greet(name) {
console.log('Hello, ' + name + '!');
}
function hello() {
console.log('Hello, world!');
}
exports.hello = hello;
exports.greet = greet;
结论
如果要输出一个键值对象{},可以利用exports这个已存在的空对象{},并继续在上面添加新的键值;
如果要输出一个函数或数组,必须直接对module.exports对象赋值。
所以我们可以得出结论:直接对module.exports赋值,可以应对任何情况:
module.exports = {
foo: function () { return 'foo'; }
};
或者:
module.exports = function () { return 'foo'; };
最终,我们强烈建议使用module.exports = xxx的方式来输出模块变量,这样,你只需要记忆一种方法。
基本模块
global
在前面的JavaScript课程中,我们已经知道,JavaScript有且仅有一个全局对象,在浏览器中,叫window对象。而在Node.js环境中,也有唯一的全局对象,但不叫window,而叫global,这个对象的属性和方法也和浏览器环境的window不同。进入Node.js交互环境,可以直接输入:
global.console
Console {
log: [Function: bound ],
info: [Function: bound ],
warn: [Function: bound ],
error: [Function: bound ],
dir: [Function: bound ],
time: [Function: bound ],
timeEnd: [Function: bound ],
trace: [Function: bound trace],
assert: [Function: bound ],
Console: [Function: Console] }
process
process也是Node.js提供的一个对象,它代表当前Node.js进程。通过process对象可以拿到许多有用信息:
> process === global.process;
true
> process.version;
'v5.2.0'
> process.platform;
'darwin'
> process.arch;
'x64'
> process.cwd(); //返回当前工作目录
'/Users/xxx'
> process.chdir('/private/tmp'); // 切换当前工作目录
undefined
> process.cwd();
'/private/tmp'
JavaScript程序是由事件驱动执行的单线程模型,Node.js也不例外。Node.js不断执行响应事件的JavaScript函数,直到没有任何响应事件的函数可以执行时,Node.js就退出了。
如果我们想要在下一次事件响应中执行代码,可以调用process.nextTick():
// test.js
// process.nextTick()将在下一轮事件循环中调用:
process.nextTick(function () {
console.log('nextTick callback!');
});
console.log('nextTick was set!');
用Node执行上面的代码node test.js,你会看到,打印输出是:
nextTick was set!
nextTick callback!
这说明传入process.nextTick()的函数不是立刻执行,而是要等到下一次事件循环。
Node.js进程本身的事件就由process对象来处理。如果我们响应exit事件,就可以在程序即将退出时执行某个回调函数:
// 程序即将退出时的回调函数:
process.on('exit', function (code) {
console.log('about to exit with code: ' + code);
});
判断JavaScript执行环境
有很多JavaScript代码既能在浏览器中执行,也能在Node环境执行,但有些时候,程序本身需要判断自己到底是在什么环境下执行的,常用的方式就是根据浏览器和Node环境提供的全局变量名称来判断:
if (typeof(window) === 'undefined') {
console.log('node.js');
} else {
console.log('browser');
}
fs
Node.js内置的fs模块就是文件系统模块,负责读写文件。
和所有其它JavaScript模块不同的是,fs模块同时提供了异步和同步的方法。
回顾一下什么是异步方法。因为JavaScript的单线程模型,执行IO操作时,JavaScript代码无需等待,而是传入回调函数后,继续执行后续JavaScript代码。比如jQuery提供的getJSON()操作:
$.getJSON('http://example.com/ajax', function (data) {
console.log('IO结果返回后执行...');
});
console.log('不等待IO结果直接执行后续代码...');
而同步的IO操作则需要等待函数返回:
// 根据网络耗时,函数将执行几十毫秒~几秒不等:
var data = getJSONSync('http://example.com/ajax');
- 同步操作的好处是代码简单,缺点是程序将等待IO操作,在等待时间内,无法响应其它任何事件。
- 而异步读取不用等待IO操作,但代码较麻烦。
异步读文件
按照JavaScript的标准,fs.readFile异步读取一个文本文件的代码如下:
'use strict';
var fs = require('fs');
fs.readFile('sample.txt', 'utf-8', function (err, data) {
if (err) {
console.log(err);
} else {
console.log(data);
}
});
请注意,sample.txt文件必须在当前目录下,且文件编码为utf-8。
异步读取时,传入的回调函数接收两个参数,当正常读取时,err参数为null,data参数为读取到的String。当读取发生错误时,err参数代表一个错误对象,data为undefined。这也是Node.js标准的回调函数:第一个参数代表错误信息,第二个参数代表结果。后面我们还会经常编写这种回调函数。
如果我们要读取的文件不是文本文件,而是二进制文件,怎么办?
下面的例子演示了如何读取一个图片文件:
'use strict';
var fs = require('fs');
fs.readFile('sample.png', function (err, data) {
if (err) {
console.log(err);
} else {
console.log(data);
console.log(data.length + ' bytes');
}
});
当读取二进制文件时,不传入文件编码时,回调函数的data参数将返回一个Buffer对象。在Node.js中,Buffer对象就是一个包含零个或任意个字节的数组(注意和Array不同)。
Buffer对象可以和String作转换,例如,把一个Buffer对象转换成String:
// Buffer -> String
var text = data.toString('utf-8');
console.log(text);
或者把一个String转换成Buffer:
// String -> Buffer
var buf = Buffer.from(text, 'utf-8');
console.log(buf);
同步读文件
用**fs.readFileSync()**同步读取一个文本文件的代码如下:
'use strict';
var fs = require('fs');
try {
var data = fs.readFileSync('sample.txt', 'utf-8');
console.log(data);
} catch (err) {
// 出错了
}
写文件
将数据写入文件是通过**fs.writeFile()**实现的:
'use strict';
var fs = require('fs');
var data = 'Hello, Node.js';
fs.writeFile('output.txt', data, function (err) {
if (err) {
console.log(err);
} else {
console.log('ok.');
}
});
writeFile()的参数依次为文件名、数据和回调函数。如果传入的数据是String,默认按UTF-8编码写入文本文件,如果传入的参数是Buffer,则写入的是二进制文件。回调函数由于只关心成功与否,因此只需要一个err参数。
和readFile()类似,writeFile()也有一个同步方法,叫writeFileSync():
'use strict';
var fs = require('fs');
var data = 'Hello, Node.js';
fs.writeFileSync('output.txt', data);
stat
如果我们要获取文件大小,创建时间等信息,可以使用fs.stat(),它返回一个Stat对象,能告诉我们文件或目录的详细信息:
'use strict';
var fs = require('fs');
fs.stat('sample.txt', function (err, stat) {
if (err) {
console.log(err);
} else {
// 是否是文件:
console.log('isFile: ' + stat.isFile());
// 是否是目录:
console.log('isDirectory: ' + stat.isDirectory());
if (stat.isFile()) {
// 文件大小:
console.log('size: ' + stat.size);
// 创建时间, Date对象:
console.log('birth time: ' + stat.birthtime);
// 修改时间, Date对象:
console.log('modified time: ' + stat.mtime);
}
}
});
stat()也有一个对应的同步函数statSync()。
异步还是同步
在fs模块中,提供同步方法是为了方便使用。那我们到底是应该用异步方法还是同步方法呢?
由于Node环境执行的JavaScript代码是服务器端代码,所以,绝大部分需要在服务器运行期反复执行业务逻辑的代码,必须使用异步代码,否则,同步代码在执行时期,服务器将停止响应,因为JavaScript只有一个执行线程。
服务器启动时如果需要读取配置文件,或者结束时需要写入到状态文件时,可以使用同步代码,因为这些代码只在启动和结束时执行一次,不影响服务器正常运行时的异步执行
stream
stream是Node.js提供的又一个仅在服务区端可用的模块,目的是支持“流”这种数据结构。
什么是流?流是一种抽象的数据结构。想象水流,当在水管中流动时,就可以从某个地方(例如自来水厂)源源不断地到达另一个地方(比如你家的洗手池)。我们也可以把数据看成是数据流,比如你敲键盘的时候,就可以把每个字符依次连起来,看成字符流。这个流是从键盘输入到应用程序,实际上它还对应着一个名字:标准输入流(stdin)。
如果应用程序把字符一个一个输出到显示器上,这也可以看成是一个流,这个流也有名字:标准输出流(stdout)。流的特点是数据是有序的,而且必须依次读取,或者依次写入,不能像Array那样随机定位。
有些流用来读取数据,比如从文件读取数据时,可以打开一个文件流,然后从文件流中不断地读取数据。有些流用来写入数据,比如向文件写入数据时,只需要把数据不断地往文件流中写进去就可以了。
在Node.js中,流也是一个对象,我们只需要响应流的事件就可以了:data事件表示流的数据已经可以读取了,end事件表示这个流已经到末尾了,没有数据可以读取了,error事件表示出错了。
下面是一个从文件流读取文本内容的示例:
'use strict';
var fs = require('fs');
// 打开一个流:
var rs = fs.createReadStream('sample.txt', 'utf-8');
rs.on('data', function (chunk) {
console.log('DATA:')
console.log(chunk);
});
rs.on('end', function () {
console.log('END');
});
rs.on('error', function (err) {
console.log('ERROR: ' + err);
});
要注意,data事件可能会有多次,每次传递的chunk是流的一部分数据。
要以流的形式写入文件,只需要不断调用write()方法,最后以end()结束:
'use strict';
var fs = require('fs');
var ws1 = fs.createWriteStream('output1.txt', 'utf-8');
ws1.write('使用Stream写入文本数据...\n');
ws1.write('END.');
ws1.end();
var ws2 = fs.createWriteStream('output2.txt');
ws2.write(new Buffer('使用Stream写入二进制数据...\n', 'utf-8'));
ws2.write(new Buffer('END.', 'utf-8'));
ws2.end();
所有可以读取数据的流都继承自stream.Readable,所有可以写入的流都继承自stream.Writable。
pipe
就像可以把两个水管串成一个更长的水管一样,两个流也可以串起来。一个Readable流和一个Writable流串起来后,所有的数据自动从Readable流进入Writable流,这种操作叫pipe。
在Node.js中,Readable流有一个pipe()方法,就是用来干这件事的。
让我们用pipe()把一个文件流和另一个文件流串起来,这样源文件的所有数据就自动写入到目标文件里了,所以,这实际上是一个复制文件的程序:
'use strict';
var fs = require('fs');
var rs = fs.createReadStream('sample.txt');
var ws = fs.createWriteStream('copied.txt');
rs.pipe(ws);
默认情况下,当Readable流的数据读取完毕,end事件触发后,将自动关闭Writable流。如果我们不希望自动关闭Writable流,需要传入参数:
readable.pipe(writable, { end: false });
http
HTTP协议
要理解Web服务器程序的工作原理,首先,我们要对HTTP协议有基本的了解
HTTP服务器
要开发HTTP服务器程序,从头处理TCP连接,解析HTTP是不现实的。这些工作实际上已经由Node.js自带的http模块完成了。应用程序并不直接和HTTP协议打交道,而是操作http模块提供的request和response对象。
request对象封装了HTTP请求,我们调用request对象的属性和方法就可以拿到所有HTTP请求的信息;
response对象封装了HTTP响应,我们操作response对象的方法,就可以把HTTP响应返回给浏览器。
用Node.js实现一个HTTP服务器程序非常简单。我们来实现一个最简单的Web程序hello.js,它对于所有请求,都返回Hello world!:
'use strict';
// 导入http模块:
var http = require('http');
// 创建http server,并传入回调函数:
var server = http.createServer(function (request, response) {
// 回调函数接收request和response对象,
// 获得HTTP请求的method和url:
console.log(request.method + ': ' + request.url);
// 将HTTP响应200写入response, 同时设置Content-Type: text/html:
response.writeHead(200, {'Content-Type': 'text/html'});
// 将HTTP响应的HTML内容写入response:
response.end('Hello world!
');
});
// 让服务器监听8080端口:
server.listen(8080);
console.log('Server is running at http://127.0.0.1:8080/');
在命令提示符下运行该程序,可以看到以下输出:
$ node hello.js
Server is running at http://127.0.0.1:8080/
不要关闭命令提示符,直接打开浏览器输入http://localhost:8080
文件服务器
让我们继续扩展一下上面的Web程序。我们可以设定一个目录,然后让Web程序变成一个文件服务器。要实现这一点,我们只需要解析request.url中的路径,然后在本地找到对应的文件,把文件内容发送出去就可以了。
解析URL需要用到Node.js提供的url模块,它使用起来非常简单,通过parse()将一个字符串解析为一个Url对象:
'use strict';
var url = require('url');
console.log(url.parse('http://user:[email protected]:8080/path/to/file?query=string#hash'));
处理本地文件目录需要使用Node.js提供的path模块,它可以方便地构造目录:
'use strict';
var path = require('path');
// 解析当前目录:
var workDir = path.resolve('.'); // '/Users/xxx'
// 组合完整的文件路径:当前目录+'pub'+'index.html':
var filePath = path.join(workDir, 'pub', 'index.html');
// '/Users/xxx/pub/index.html'
最后,我们实现一个文件服务器file_server.js:
'use strict';
var
fs = require('fs'),
url = require('url'),
path = require('path'),
http = require('http');
// 从命令行参数获取root目录,默认是当前目录:
var root = path.resolve(process.argv[2] || '.');
console.log('Static root dir: ' + root);
// 创建服务器:
var server = http.createServer(function (request, response) {
// 获得URL的path,类似 '/css/bootstrap.css':
var pathname = url.parse(request.url).pathname;
// 获得对应的本地文件路径,类似 '/srv/www/css/bootstrap.css':
var filepath = path.join(root, pathname);
// 获取文件状态:
fs.stat(filepath, function (err, stats) {
if (!err && stats.isFile()) {
// 没有出错并且文件存在:
console.log('200 ' + request.url);
// 发送200响应:
response.writeHead(200);
// 将文件流导向response:
fs.createReadStream(filepath).pipe(response);
} else {
// 出错了或者文件不存在:
console.log('404 ' + request.url);
// 发送404响应:
response.writeHead(404);
response.end('404 Not Found');
}
});
});
server.listen(8080);
console.log('Server is running at http://127.0.0.1:8080/');
没有必要手动读取文件内容。由于response对象本身是一个Writable Stream,直接用pipe()方法就实现了自动读取文件内容并输出到HTTP响应。
在命令行运行node file_server.js /path/to/dir,把/path/to/dir改成你本地的一个有效的目录,然后在浏览器中输入http://localhost:8080/index.html。
crypto
crypto模块的目的是为了提供通用的加密和哈希算法。用纯JavaScript代码实现这些功能不是不可能,但速度会非常慢。Nodejs用C/C++实现这些算法后,通过cypto这个模块暴露为JavaScript接口,这样用起来方便,运行速度也快。
MD5和SHA1
MD5是一种常用的哈希算法,用于给任意数据一个“签名”。这个签名通常用一个十六进制的字符串表示:
const crypto = require('crypto');
const hash = crypto.createHash('md5');
// 可任意多次调用update():
hash.update('Hello, world!');
hash.update('Hello, nodejs!');
console.log(hash.digest('hex'));
update()方法默认字符串编码为UTF-8,也可以传入Buffer。
如果要计算SHA1,只需要把’md5’改成’sha1’,就可以得到SHA1的结果1f32b9c9932c02227819a4151feed43e131aca40。
还可以使用更安全的sha256和sha512。
Hmac
Hmac算法也是一种哈希算法,它可以利用MD5或SHA1等哈希算法。不同的是,Hmac还需要一个密钥:
const crypto = require('crypto');
const hmac = crypto.createHmac('sha256', 'secret-key');
hmac.update('Hello, world!');
hmac.update('Hello, nodejs!');
console.log(hmac.digest('hex')); // 80f7e22570...
只要密钥发生了变化,那么同样的输入数据也会得到不同的签名,因此,可以把Hmac理解为用随机数“增强”的哈希算法。
AES
AES是一种常用的对称加密算法,加解密都用同一个密钥。crypto模块提供了AES支持,但是需要自己封装好函数,便于使用:
const crypto = require('crypto');
function aesEncrypt(data, key) {
const cipher = crypto.createCipher('aes192', key);
var crypted = cipher.update(data, 'utf8', 'hex');
crypted += cipher.final('hex');
return crypted;
}
function aesDecrypt(encrypted, key) {
const decipher = crypto.createDecipher('aes192', key);
var decrypted = decipher.update(encrypted, 'hex', 'utf8');
decrypted += decipher.final('utf8');
return decrypted;
}
var data = 'Hello, this is a secret message!';
var key = 'Password!';
var encrypted = aesEncrypt(data, key);
var decrypted = aesDecrypt(encrypted, key);
console.log('Plain text: ' + data);
console.log('Encrypted text: ' + encrypted);
console.log('Decrypted text: ' + decrypted);
注意到AES有很多不同的算法,如aes192,aes-128-ecb,aes-256-cbc等,AES除了密钥外还可以指定IV(Initial Vector),不同的系统只要IV不同,用相同的密钥加密相同的数据得到的加密结果也是不同的。加密结果通常有两种表示方法:hex和base64,这些功能Nodejs全部都支持,但是在应用中要注意,如果加解密双方一方用Nodejs,另一方用Java、PHP等其它语言,需要仔细测试。如果无法正确解密,要确认双方是否遵循同样的AES算法,字符串密钥和IV是否相同,加密后的数据是否统一为hex或base64格式。
Diffie-Hellman
DH算法是一种密钥交换协议,它可以让双方在不泄漏密钥的情况下协商出一个密钥来。
用crypto模块实现DH算法如下:
const crypto = require('crypto');
// xiaoming's keys:
var ming = crypto.createDiffieHellman(512);
var ming_keys = ming.generateKeys();
var prime = ming.getPrime();
var generator = ming.getGenerator();
console.log('Prime: ' + prime.toString('hex'));
console.log('Generator: ' + generator.toString('hex'));
// xiaohong's keys:
var hong = crypto.createDiffieHellman(prime, generator);
var hong_keys = hong.generateKeys();
// exchange and generate secret:
var ming_secret = ming.computeSecret(hong_keys);
var hong_secret = hong.computeSecret(ming_keys);
// print secret:
console.log('Secret of Xiao Ming: ' + ming_secret.toString('hex'));
console.log('Secret of Xiao Hong: ' + hong_secret.toString('hex'));
RSA
RSA算法是一种非对称加密算法,即由一个私钥和一个公钥构成的密钥对,通过私钥加密,公钥解密,或者通过公钥加密,私钥解密。其中,公钥可以公开,私钥必须保密。
下面,使用crypto模块提供的方法,即可实现非对称加解密。
首先,我们用私钥加密,公钥解密:
const
fs = require('fs'),
crypto = require('crypto');
// 从文件加载key:
function loadKey(file) {
// key实际上就是PEM编码的字符串:
return fs.readFileSync(file, 'utf8');
}
let
prvKey = loadKey('./rsa-prv.pem'),
pubKey = loadKey('./rsa-pub.pem'),
message = 'Hello, world!';
// 使用私钥加密:
let enc_by_prv = crypto.privateEncrypt(prvKey, Buffer.from(message, 'utf8'));
console.log('encrypted by private key: ' + enc_by_prv.toString('hex'));
let dec_by_pub = crypto.publicDecrypt(pubKey, enc_by_prv);
console.log('decrypted by public key: ' + dec_by_pub.toString('utf8'));
执行后,可以得到解密后的消息,与原始消息相同。
接下来我们使用公钥加密,私钥解密:
// 使用公钥加密:
let enc_by_pub = crypto.publicEncrypt(pubKey, Buffer.from(message, 'utf8'));
console.log('encrypted by public key: ' + enc_by_pub.toString('hex'));
// 使用私钥解密:
let dec_by_prv = crypto.privateDecrypt(prvKey, enc_by_pub);
console.log('decrypted by private key: ' + dec_by_prv.toString('utf8'));
执行得到的解密后的消息仍与原始消息相同。
如果我们把message字符串的长度增加到很长,例如1M,这时,执行RSA加密会得到一个类似这样的错误:data too large for key size,这是因为RSA加密的原始信息必须小于Key的长度。那如何用RSA加密一个很长的消息呢?实际上,RSA并不适合加密大数据,而是先生成一个随机的AES密码,用AES加密原始信息,然后用RSA加密AES口令,这样,实际使用RSA时,给对方传的密文分两部分,一部分是AES加密的密文,另一部分是RSA加密的AES口令。对方用RSA先解密出AES口令,再用AES解密密文,即可获得明文。
证书
crypto模块也可以处理数字证书。数字证书通常用在SSL连接,也就是Web的https连接。一般情况下,https连接只需要处理服务器端的单向认证,如无特殊需求(例如自己作为Root给客户发认证证书),建议用反向代理服务器如Nginx等Web服务器去处理证书。
Web开发
Web应用开发可以说是目前软件开发中最重要的部分。Web开发也经历了好几个阶段:
- 静态Web页面:由文本编辑器直接编辑并生成静态的HTML页面,如果要修改Web页面的内容,就需要再次编辑HTML源文件,早期的互联网Web页面就是静态的;
- CGI:由于静态Web页面无法与用户交互,比如用户填写了一个注册表单,静态Web页面就无法处理。要处理用户发送的动态数据,出现了Common Gateway Interface,简称CGI,用C/C++编写。
- ASP/JSP/PHP:由于Web应用特点是修改频繁,用C/C++这样的低级语言非常不适合Web开发,而脚本语言由于开发效率高,与HTML结合紧密,因此,迅速取代了CGI模式。ASP是微软推出的用VBScript脚本编程的Web开发技术,而JSP用Java来编写脚本,PHP本身则是开源的脚本语言。
- MVC:为了解决直接用脚本语言嵌入HTML导致的可维护性差的问题,Web应用也引入了Model-View-Controller的模式,来简化Web开发。ASP发展为ASP.Net,JSP和PHP也有一大堆MVC框架。
目前,Web开发技术仍在快速发展中,异步开发、新的MVVM前端技术层出不穷。
由于Node.js把JavaScript引入了服务器端,因此,原来必须使用PHP/Java/C#/Python/Ruby等其他语言来开发服务器端程序,现在可以使用Node.js开发了!
用Node.js开发Web服务器端,有几个显著的优势:
- 一是后端语言也是JavaScript,以前掌握了前端JavaScript的开发人员,现在可以同时编写后端代码;
- 二是前后端统一使用JavaScript,就没有切换语言的障碍了;
- 三是速度快,非常快!这得益于Node.js天生是异步的。
在Node.js诞生后的短短几年里,出现了无数种Web框架、ORM框架、模版引擎、测试框架、自动化构建工具,数量之多,即使是JavaScript老司机,也不免眼花缭乱。
koa
koa是Express的下一代基于Node.js的web框架,目前有1.x和2.0两个版本。
创建koa2工程
- koa middleware
处理URL
- koa-router
- 处理post请求
- 重构
- Controller Middleware
使用Nunjucks
Nunjucks是一个模板引擎。
模板引擎就是基于模板配合数据构造出字符串输出的一个组件。
使用MVC
- MVC
MVC:Model-View-Controller,中文名“模型-视图-控制器”。
- 异步函数是C:Controller,Controller负责业务逻辑,比如检查用户名是否存在,取出用户信息等等;
- 包含变量{{ name }}的模板就是V:View,View负责显示逻辑,通过简单地替换一些变量,View最终输出的就是用户看到的HTML。
- MVC中的Model在哪?Model是用来传给View的,这样View在替换变量的时候,就可以从Model中取出相应的数据。
mysql
使用Sequelize
使用Sequelize操作数据库的一般步骤就是:
- 首先,通过某个Model对象的findAll()方法获取实例;
- 如果要更新实例,先对实例属性赋新值,再调用save()方法;
- 如果要删除实例,直接调用destroy()方法。
- 注意findAll()方法可以接收where、order这些参数,这和将要生成的SQL语句是对应的。
建立Model
每个Model必须遵守一套规范:
- 统一主键,名称必须是id,类型必须是STRING(50);
- 主键可以自己指定,也可以由框架自动生成(如果为null或undefined);
- 所有字段默认为NOT NULL,除非显式指定;
- 统一timestamp机制,每个Model必须有createdAt、updatedAt和version,分别记录创建时间、修改时间和版本号。其中,createdAt和updatedAt以BIGINT存储时间戳,最大的好处是无需处理时区,排序方便。version每次修改时自增。
mocha
如果你听说过“测试驱动开发”(TDD:Test-Driven Development),单元测试就不陌生。
mocha是JavaScript的一种单元测试框架,既可以在浏览器环境下运行,也可以在Node.js环境下运行。
使用mocha,我们就只需要专注于编写单元测试本身,然后,让mocha去自动运行所有的测试,并给出测试结果。
mocha的特点主要有:
- 既可以测试简单的JavaScript函数,又可以测试异步代码,因为异步是JavaScript的特性之一;
- 可以自动运行所有测试,也可以只运行特定的测试;
- 可以支持before、after、beforeEach和afterEach来编写初始化代码。
编写测试
如果我们想对这个函数进行测试,可以写一个test.js,然后使用Node.js提供的assert模块进行断言
异步测试
用mocha测试一个函数是非常简单的,但是,在JavaScript的世界中,更多的时候,我们编写的是异步代码,所以,我们需要用mocha测试异步函数。
Http测试
用mocha测试一个async函数是非常方便的。现在,当我们有了一个koa的Web应用程序时,我们怎么用mocha来自动化测试Web应用程序呢?
一个简单的想法就是在测试前启动koa的app,然后运行async测试,在测试代码中发送http请求,收到响应后检查结果,这样,一个基于http接口的测试就可以自动运行。
在测试前,我们在package.json中添加devDependencies,除了mocha外,我们还需要一个简单而强大的测试模块supertest。
WebSocket
WebSocket是HTML5新增的协议,它的目的是在浏览器和服务器之间建立一个不受限的双向通信的通道,比如说,服务器可以在任意时刻发送消息给浏览器。
为什么传统的HTTP协议不能做到WebSocket实现的功能?这是因为HTTP协议是一个请求-响应协议,请求必须先由浏览器发给服务器,服务器才能响应这个请求,再把数据发送给浏览器。换句话说,浏览器不主动请求,服务器是没法主动发数据给浏览器的。
这样一来,要在浏览器中搞一个实时聊天,在线炒股(不鼓励),或者在线多人游戏的话就没法实现了,只能借助Flash这些插件。
也有人说,HTTP协议其实也能实现啊,比如用轮询或者Comet。轮询是指浏览器通过JavaScript启动一个定时器,然后以固定的间隔给服务器发请求,询问服务器有没有新消息。这个机制的缺点一是实时性不够,二是频繁的请求会给服务器带来极大的压力。
Comet本质上也是轮询,但是在没有消息的情况下,服务器先拖一段时间,等到有消息了再回复。这个机制暂时地解决了实时性问题,但是它带来了新的问题:以多线程模式运行的服务器会让大部分线程大部分时间都处于挂起状态,极大地浪费服务器资源。另外,一个HTTP连接在长时间没有数据传输的情况下,链路上的任何一个网关都可能关闭这个连接,而网关是我们不可控的,这就要求Comet连接必须定期发一些ping数据表示连接“正常工作”。
以上两种机制都治标不治本,所以,HTML5推出了WebSocket标准,让浏览器和服务器之间可以建立无限制的全双工通信,任何一方都可以主动发消息给对方。
WebSocket协议
为什么WebSocket连接可以实现全双工通信而HTTP连接不行呢?实际上HTTP协议是建立在TCP协议之上的,TCP协议本身就实现了全双工通信,但是HTTP协议的请求-应答机制限制了全双工通信。WebSocket连接建立以后,其实只是简单规定了一下:接下来,咱们通信就不使用HTTP协议了,直接互相发数据吧。
安全的WebSocket连接机制和HTTPS类似。首先,浏览器用wss://xxx创建WebSocket连接时,会先通过HTTPS创建安全的连接,然后,该HTTPS连接升级为WebSocket连接,底层通信走的仍然是安全的SSL/TLS协议。
使用ws
ws模块
在Node.js中,使用最广泛的WebSocket模块是ws。
创建WebSocket连接
现在,这个简单的服务器端WebSocket程序就编写好了。如何真正创建WebSocket并且给服务器发消息呢?
- 方法是在浏览器中写JavaScript代码。
- 我们还可以直接用ws模块提供的WebSocket来充当客户端。换句话说,ws模块既包含了服务器端,又包含了客户端。
同源策略
从上面的测试可以看出,WebSocket协议本身不要求同源策略(Same-origin Policy),也就是某个地址为http://a.com的网页可以通过WebSocket连接到ws://b.com。但是,浏览器会发送Origin的HTTP头给服务器,服务器可以根据Origin拒绝这个WebSocket请求。所以,是否要求同源要看服务器端如何检查。
路由
还需要注意到服务器在响应connection事件时并未检查请求的路径,因此,在客户端打开ws://localhost:3000/any/path可以写任意的路径。
实际应用中还需要根据不同的路径实现不同的功能。
编写聊天室
要创建真正的WebSocket应用,首先,得有一个基于MVC的Web应用,也就是我们在前面用koa2和Nunjucks创建的Web,在此基础上,把WebSocket添加进来,才算完整。
因此,本节的目标是基于WebSocket创建一个在线聊天室。
REST
自从Roy Fielding博士在2000年他的博士论文中提出REST(Representational State Transfer)风格的软件架构模式后,REST就基本上迅速取代了复杂而笨重的SOAP,成为Web API的标准了。
REST就是一种设计API的模式。最常用的数据格式是JSON。由于JSON能直接被JavaScript读取,所以,以JSON格式编写的REST风格的API具有简单、易读、易用的特点。
编写API有什么好处呢?由于API就是把Web App的功能全部封装了,所以,通过API操作数据,可以极大地把前端和后端的代码隔离,使得后端代码易于测试,前端代码编写更简单。
此外,如果我们把前端页面看作是一种用于展示的客户端,那么API就是为客户端提供数据、操作数据的接口。这种设计可以获得极高的扩展性。例如,当用户需要在手机上购买商品时,只需要开发针对iOS和Android的两个客户端,通过客户端访问API,就可以完成通过浏览器页面提供的功能,而后端代码基本无需改动。
当一个Web应用以API的形式对外提供功能时,整个应用的结构就扩展为:
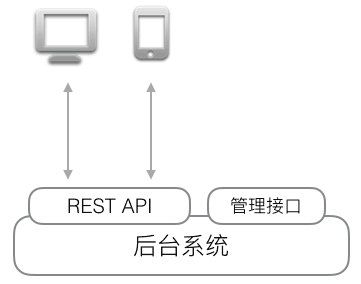
编写REST API
编写REST API,实际上就是编写处理HTTP请求的async函数,不过,REST请求和普通的HTTP请求有几个特殊的地方:
- REST请求仍然是标准的HTTP请求,但是,除了GET请求外,POST、PUT等请求的body是JSON数据格式,请求的Content-Type为application/json;
- REST响应返回的结果是JSON数据格式,因此,响应的Content-Type也是application/json。
REST规范定义了资源的通用访问格式,虽然它不是一个强制要求,但遵守该规范可以让人易于理解。
koa处理REST
bodyParser()这个middleware可以解析请求的JSON数据并绑定到ctx.request.body上,输出JSON时我们先指定ctx.response.type = ‘application/json’,然后把JavaScript对象赋值给ctx.response.body就完成了REST请求的处理。
开发REST API
我们在这个工程中约定了如下规范:
- REST API的返回值全部是object对象,而不是简单的number、boolean、null或者数组;
- REST API必须使用前缀/api/。
Service
为了操作Product,我们用products.js封装所有操作,可以把它视为一个Service>
API
编写API时,需要注意:
- 如果客户端传递了JSON格式的数据(例如,POST请求),则async函数可以通过ctx.request.body直接访问已经反序列化的JavaScript对象。这是由bodyParser()这个middleware完成的。如果ctx.request.body为undefined,说明缺少middleware,或者middleware没有正确配置。
- 如果API路径带有参数,参数必须用:表示,例如,DELETE /api/products/:id,客户端传递的URL可能就是/api/products/A001,参数id对应的值就是A001,要获得这个参数,我们用ctx.params.id。
- 类似的,如果API路径有多个参数,例如,/api/products/:pid/reviews/:rid,则这两个参数分别用ctx.params.pid和ctx.params.rid获取。
- 这个功能由koa-router这个middleware提供。
- API路径的参数永远是字符串!
MVC
有了API以后,我们就可以编写MVC,在页面上调用API完成操作。
当products变化时,Vue会自动更新表格的内容。