Java开发手册(嵩山版)阅读笔记
Java开发手册(嵩山版)阅读笔记
- 前言
- 一、编程规范
-
- (一)命名风格
-
- 9、【强制】POJO 类中的任何布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列化错误。
- 下面是网友遇到的这个坑和解决办法
- 总结
- (二)常量定义
-
- 1. 【强制】不允许任何魔法值(即未经预先定义的常量)直接出现在代码中。
- (四)OOP规约
-
- 6. 【强制】Object的 equals方法容易抛空指针异常,应使用常量或确定有值的对象来调用 equals。
- 7. 【强制】所有整型包装类对象之间值的比较,全部使用equals方法比较。
- 9. 【强制】浮点数之间的等值判断,基本数据类型不能用==来比较,包装数据类型不能用equals 来判断。
- 10. 【强制】如上所示BigDecimal的等值比较应使用 compareTo()方法,而不是equals()方法。
- 11. 【强制】定义数据对象DO类时,属性类型要与数据库字段类型相匹配。
- 13. 关于基本数据类型与包装数据类型的使用标准如下:
- 25. 【推荐】慎用 Object的 clone方法来拷贝对象。
- (六)集合处理
-
- 3. 【强制】在使用java.util.stream.Collectors类的 toMap()方法转为Map集合时,一定要使 用含有参数类型为BinaryOperator,参数名为mergeFunction 的方法,否则当出现相同key 值时会抛出IllegalStateException 异常。
-
- 正例:
- 反例:
- 4. 【强制】在使用java.util.stream.Collectors类的 toMap()方法转为Map集合时,一定要注 意当value为null时会抛NPE异常。
-
- 正例
- 反例
- 10. 【强制】在使用Collection 接口任何实现类的addAll()方法时,都要对输入的集合参数进行 NPE判断。
- 11. 【强制】使用工具类Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方法, 它的add/remove/clear方法会抛出UnsupportedOperationException 异常。
- 10. 【强制】在使用Collection 接口任何实现类的addAll()方法时,都要对输入的集合参数进行 NPE判断。
- 14. 【强制】不要在foreach循环里进行元素的remove/add操作。remove元素请使用Iterator 方式,如果并发操作,需要对Iterator对象加锁。
-
- 14.1、正例
- 14.2、反例:
- 17.【推荐】集合初始化时,指定集合初始值大小。
- 19.【推荐】高度注意 Map 类集合 K/V 能不能存储 null 值的情况,如下表格:
- (八) 控制语句
-
- 2. 【强制】当switch 括号内的变量类型为String并且此变量为外部参数时,必须先进行null 判断。
- 五、MySQL数据库
-
- (三) SQL语句
-
- 1、【强制】不要使用count(列名)或count(常量)来替代count(\*),count(\*)是SQL92定义的标 准统计行数的语法,跟数据库无关,跟NULL和非 NULL无关。
- 2、【强制】count(distinct col) 计算该列除NULL之外的不重复行数,注意 count(distinct col1, col2) 如果其中一列全为NULL,那么即使另一列有不同的值,也返回为0。
- 3、【强制】当某一列的值全是NULL时,count(col)的返回结果为0,但 sum(col)的返回结果为 NULL,因此使用sum()时需注意NPE问题。
- 4. 【强制】使用 ISNULL()来判断是否为 NULL值。
前言
在阅读《Java开发手册(嵩山版)》时,一些不熟悉的规范、不理解的规范记录下来,以备复习,避免以后踩坑;
免费下载网址:藏经阁_阿里云开发者社区_云计算社区-阿里云
一、编程规范
(一)命名风格
9、【强制】POJO 类中的任何布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列化错误。
说明:在本文 MySQL 规约中的建表约定第一条,表达是与否的变量采用 is_xxx 的命名方式,所以,需要
在设置从 is_xxx 到 xxx 的映射关系。
反例:定义为基本数据类型 Boolean isDeleted 的属性,它的方法也是 isDeleted(),框架在反向解析的时
候,“误以为”对应的属性名称是 deleted,导致属性获取不到,进而抛出异常。
下面是网友遇到的这个坑和解决办法
Fastjson关于is开头序列化问题
boolean类型命名is开头参数会引起序列化错误
总结
如果数据库字段设置的是
![]()
对应的model类使用的是lombok插件的@Data注解就不会出现这种情况
(二)常量定义
1. 【强制】不允许任何魔法值(即未经预先定义的常量)直接出现在代码中。
反例: // 本例中,开发者A定义了缓存的key,然后开发者B使用缓存时少了下划线,即key是"Id#taobao"+tradeId,导致 出现故障 String key = “Id#taobao_” + tradeId; cache.put(key, value);
(四)OOP规约
6. 【强制】Object的 equals方法容易抛空指针异常,应使用常量或确定有值的对象来调用 equals。
正例:“test”.equals(object); 反例:object.equals(“test”); 说明:推荐使用 JDK7 引入的工具类 java.util.Objects#equals(Object a, Object b)
7. 【强制】所有整型包装类对象之间值的比较,全部使用equals方法比较。
说明:对于Integer var = ? 在-128至127 之间的赋值,Integer 对象是在 IntegerCache.cache 产生, 会复用已有对象,这个区间内的 Integer 值可以直接使用==进行判断,但是这个区间之外的所有数据,都 会在堆上产生,并不会复用已有对象,这是一个大坑,推荐使用 equals方法进行判断。
9. 【强制】浮点数之间的等值判断,基本数据类型不能用==来比较,包装数据类型不能用equals 来判断。
说明:浮点数采用“尾数+阶码”的编码方式,类似于科学计数法的“有效数字+指数”的表示方式。二进 制无法精确表示大部分的十进制小数,具体原理参考《码出高效》。
反例:
float a = 1.0F - 0.9F;
float b = 0.9F - 0.8F;
if (a == b) {
// 预期进入此代码块,执行其它业务逻辑
// 但事实上a==b的结果为false
}
Float x = Float.valueOf(a); Float y = Float.valueOf(b); if (x.equals(y)){
// 预期进入此代码块,执行其它业务逻辑
// 但事实上equals的结果为false
}
正例:
(1) 指定一个误差范围,两个浮点数的差值在此范围之内,则认为是相等的。
float a = 1.0F - 0.9F; float b = 0.9F - 0.8F; float diff = 1e-6F;
if (Math.abs(a - b) < diff) { System.out.println("true"); }
(2) 使用BigDecimal 来定义值,再进行浮点数的运算操作。
BigDecimal a = new BigDecimal("1.0");
BigDecimal b = new BigDecimal("0.9");
BigDecimal c = new BigDecimal("0.8");
BigDecimal x = a.subtract(b);
BigDecimal y = b.subtract(c);
if (x.compareTo(y) == 0) { System.out.println("true"); }
10. 【强制】如上所示BigDecimal的等值比较应使用 compareTo()方法,而不是equals()方法。
说明:equals()方法会比较值和精度(1.0与1.00返回结果为false),而compareTo()则会忽略精度。
11. 【强制】定义数据对象DO类时,属性类型要与数据库字段类型相匹配。
正例:数据库字段的 bigint 必须与类属性的 Long 类型相对应。 反例:某个案例的数据库表id 字段定义类型bigint unsigned,实际类对象属性为 Integer,随着 id 越来 越大,超过 Integer 的表示范围而溢出成为负数。
13. 关于基本数据类型与包装数据类型的使用标准如下:
1) 【强制】所有的 POJO类属性必须使用包装数据类型。
2) 【强制】RPC 方法的返回值和参数必须使用包装数据类型。
3) 【推荐】所有的局部变量使用基本数据类型。
说明:POJO类属性没有初值是提醒使用者在需要使用时,必须自己显式地进行赋值,任何 NPE问题,或 者入库检查,都由使用者来保证。
正例:数据库的查询结果可能是 null,因为自动拆箱,用基本数据类型接收有 NPE 风险。
反例:某业务的交易报表上显示成交总额涨跌情况,即正负 x%,x为基本数据类型,调用的 RPC 服务,调 用不成功时,返回的是默认值,页面显示为 0%,这是不合理的,应该显示成中划线-。所以包装数据类型 的 null值,能够表示额外的信息,如:远程调用失败,异常退出。
25. 【推荐】慎用 Object的 clone方法来拷贝对象。
说明:对象clone 方法默认是浅拷贝,若想实现深拷贝,需覆写clone 方法实现域对象的深度遍历式拷贝。
(六)集合处理
3. 【强制】在使用java.util.stream.Collectors类的 toMap()方法转为Map集合时,一定要使 用含有参数类型为BinaryOperator,参数名为mergeFunction 的方法,否则当出现相同key 值时会抛出IllegalStateException 异常。
说明:参数mergeFunction 的作用是当出现 key重复时,自定义对 value 的处理策略。
正例:
@Test
void test01(){
List<Pair<String, Double>> pairArrayList = new ArrayList<>(3);
pairArrayList.add(new Pair<>("version", 12.10));
pairArrayList.add(new Pair<>("version", 12.19));
pairArrayList.add(new Pair<>("version", 6.28));
// 生成的map集合中只有一个键值对:version=6.28
Map<String, Double> map = pairArrayList.stream()
.collect(Collectors.toMap(Pair::getKey, Pair::getValue, (v1, v2) -> v2));
if (MapUtils.isNotEmpty(map)) {
map.forEach((k,v) -> System.out.println(k + "->" + v));
}
}
@Test
void test010(){
String[] departments = new String[]{"iERP","iERP","EIBU"};
Map<Integer, String> map = Arrays.stream(departments)
.collect(Collectors.toMap(String::hashCode, String::toString, (v1, v2) -> v2));
if (MapUtils.isNotEmpty(map)) {
map.forEach((k,v) -> System.out.println(k + "->" + v));
}
}
反例:
@Test
void test011(){
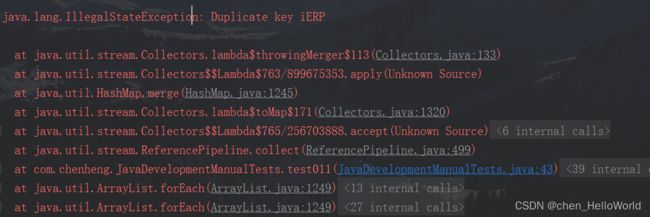
String[] departments = new String[]{"iERP","iERP","EIBU"};
Map<Integer, String> map = Arrays.stream(departments)
.collect(Collectors.toMap(String::hashCode, String::toString));
}
4. 【强制】在使用java.util.stream.Collectors类的 toMap()方法转为Map集合时,一定要注 意当value为null时会抛NPE异常。
说明:在java.util.HashMap 的merge 方法里会进行如下的判断: if (value == null || remappingFunction == null) throw new NullPointerException();
正例
@Test
void test02(){
List<Pair<String, Double>> pairArrayList = new ArrayList<>(2);
pairArrayList.add(new Pair<>("version1", 8.3));
pairArrayList.add(new Pair<>("version2", null));
Map<String, Double> map = pairArrayList.stream().filter(p -> Objects.nonNull(p.getValue()))
.collect(Collectors.toMap(Pair::getKey, Pair::getValue, (v1, v2) -> v2));
if (MapUtils.isNotEmpty(map)) {
map.forEach((k,v) -> System.out.println(k + "->" + v));
}
}
反例
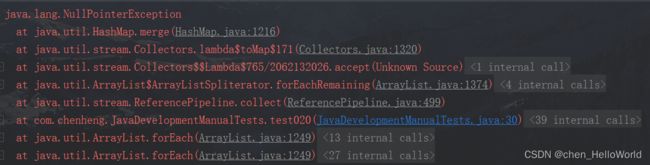
@Test
void test020(){
List<Pair<String, Double>> pairArrayList = new ArrayList<>(2);
pairArrayList.add(new Pair<>("version1", 8.3));
pairArrayList.add(new Pair<>("version2", null));
Map<String, Double> map = pairArrayList.stream()
.collect(Collectors.toMap(Pair::getKey, Pair::getValue, (v1, v2) -> v2));
if (MapUtils.isNotEmpty(map)) {
map.forEach((k,v) -> System.out.println(k + "->" + v));
}
}
10. 【强制】在使用Collection 接口任何实现类的addAll()方法时,都要对输入的集合参数进行 NPE判断。
说明:在ArrayList#addAll 方法的第一行代码即 Object[] a = c.toArray(); 其中 c为输入集合参数,如果 为 null,则直接抛出异常。
11. 【强制】使用工具类Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方法, 它的add/remove/clear方法会抛出UnsupportedOperationException 异常。
说明:asList 的返回对象是一个 Arrays内部类,并没有实现集合的修改方法。Arrays.asList 体现的是适配 器模式,只是转换接口,后台的数据仍是数组。 String[] str = new String[] { “chen”, “yang”, “hao” }; List list = Arrays.asList(str); 第一种情况:list.add(“yangguanbao”); 运行时异常。 第二种情况:str[0] = “change”; 也会随之修改,反之亦然。
10. 【强制】在使用Collection 接口任何实现类的addAll()方法时,都要对输入的集合参数进行 NPE判断。
说明:在ArrayList#addAll 方法的第一行代码即 Object[] a = c.toArray(); 其中 c为输入集合参数,如果 为 null,则直接抛出异常。
@Test
void test03(){
List<String> names = null;
List<String> result = new ArrayList<>();
result.addAll(names);
}
原因
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
结果

14. 【强制】不要在foreach循环里进行元素的remove/add操作。remove元素请使用Iterator 方式,如果并发操作,需要对Iterator对象加锁。
14.1、正例
@Test
void test04(){
List<String> result = new ArrayList<>();
result.add("1");
result.add("2");
Iterator<String> iterator = result.iterator();
while (iterator.hasNext()) {
String value = iterator.next();
if (StringUtils.equals("1", value)) {
iterator.remove();
}
}
result.forEach(System.out::println);
}
@Test
void test040(){
List<String> result = new ArrayList<>();
result.add("1");
result.add("2");
result.removeIf(value -> StringUtils.equals("1", value));
result.forEach(System.out::println);
}
@Test
void test041(){
List<String> result = new ArrayList<>();
result.add("1");
result.add("2");
for (String value : result) {
if (StringUtils.equals("1", value)) {
result.remove(value);
}
}
result.forEach(System.out::println);
}
14.2、反例:
@Test
void test042(){
List<String> result = new ArrayList<>();
result.add("1");
result.add("2");
result.forEach(value -> {
if (StringUtils.equals("1", value)) {
result.remove(value);
}
});
result.forEach(System.out::println);
}

17.【推荐】集合初始化时,指定集合初始值大小。
说明:HashMap 使用 HashMap(int initialCapacity) 初始化,如果暂时无法确定集合大小,那么指定默
认值(16)即可。
正例:initialCapacity = (需要存储的元素个数 / 负载因子) + 1。注意负载因子(即 loader factor)默认
为 0.75,如果暂时无法确定初始值大小,请设置为 16(即默认值)。
反例: HashMap 需要放置 1024 个元素,由于没有设置容量初始大小,随着元素增加而被迫不断扩容,
resize()方法总共会调用 8 次,反复重建哈希表和数据迁移。当放置的集合元素个数达千万级时会影响程序性能。
19.【推荐】高度注意 Map 类集合 K/V 能不能存储 null 值的情况,如下表格:
| 集合类 | Key | Value | Super | 线程安全 |
|---|---|---|---|---|
| Hashtable | 不允许为 null | 不允许为 null | Dictionary | 线程安全 |
| ConcurrentHashMap | 不允许为 null | 不允许为 null | AbstractMap | 锁分段技术(JDK8:CAS) |
| TreeMap | 不允许为 null | 允许为 null | AbstractMap | 线程不安全 |
| HashMap | 允许为 null | 允许为 null | AbstractMap | 线程不安全 |
反例:由于 HashMap 的干扰,很多人认为 ConcurrentHashMap 是可以置入 null 值,而事实上,存储
null 值时会抛出 NPE 异常。
(八) 控制语句
2. 【强制】当switch 括号内的变量类型为String并且此变量为外部参数时,必须先进行null 判断。
反例:如下的代码输出是什么?
@Test
void test06(){
this.method(null);
}
private void method(String param) {
/*if (Objects.isNull(param)) {
return;
}*/
switch (param){
case "sth":
System.out.println("it's sth");
break;
case "null":
System.out.println("it's null");
break;
default:
System.out.println("default");
}
}
现象:

五、MySQL数据库
(三) SQL语句
1、【强制】不要使用count(列名)或count(常量)来替代count(*),count(*)是SQL92定义的标 准统计行数的语法,跟数据库无关,跟NULL和非 NULL无关。
说明:count(*)会统计值为NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
2、【强制】count(distinct col) 计算该列除NULL之外的不重复行数,注意 count(distinct col1, col2) 如果其中一列全为NULL,那么即使另一列有不同的值,也返回为0。
3、【强制】当某一列的值全是NULL时,count(col)的返回结果为0,但 sum(col)的返回结果为 NULL,因此使用sum()时需注意NPE问题。
正例:可以使用如下方式来避免 sum的NPE 问题:SELECT IFNULL(SUM(column), 0) FROM table;
4. 【强制】使用 ISNULL()来判断是否为 NULL值。
说明:NULL 与任何值的直接比较都为 NULL。 1) NULL<>NULL 的返回结果是 NULL,而不是 false。 2) NULL=NULL 的返回结果是 NULL,而不是 true。 3) NULL<>1 的返回结果是 NULL,而不是 true。
反例:在SQL 语句中,如果在 null前换行,影响可读性。select * from table where column1 is null and column3 is not null; 而ISNULL(column)是一个整体,简洁易懂。从性能数据上分析,ISNULL(column) 执行效率更快一些。