一文带你了解Linux内核epoll实现原理与机制。
一、epoll_create()
-
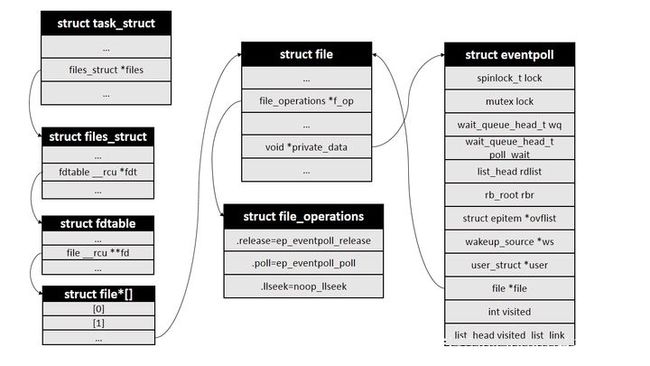
系统调用epoll_create()会创建一个epoll实例并返回该实例对应的文件描述符fd。在内核中,每个epoll实例会和一个struct eventpoll类型的对象一一对应,该对象是epoll的核心,其声明在fs/eventpoll.c文件中.
-
epoll_create的接口定义在这里,主要源码分析如下:
-
首先创建一个struct eventpoll对象:
struct eventpoll *ep = NULL;
...
error = ep_alloc(&ep);
if (error < 0)
return error;
然后分配一个未使用的文件描述符:
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));
if (fd < 0) {
error = fd;
goto out_free_ep;
}-
然后创建一个struct file对象,将file中的struct file_operations *f_op设置为全局变量eventpoll_fops,将void *private指向刚创建的eventpoll对象ep:
struct file *file;
...
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep, O_RDWR | (flags & O_CLOEXEC));
if (IS_ERR(file)) {
error = PTR_ERR(file);
goto out_free_fd;
}-
然后设置eventpoll中的file指针:
-
ep->file = file;
-
最后将文件描述符添加到当前进程的文件描述符表中,并返回给用户
-
fd_install(fd, file);
return fd; -
操作结束后主要结构关系如下图:
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
二、epoll_ctl()
-
系统调用epoll_ctl()在内核中的定义如下,各个参数的含义可参见epoll_ctl的man手册
-
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd, struct epoll_event __user *, event)
-
epoll_ctl()首先判断op是不是删除操作,如果不是则将event参数从用户空间拷贝到内核中:
struct epoll_event epds;
...
if (ep_op_has_event(op) &&
copy_from_user(&epds, event, sizeof(struct epoll_event)))
goto error_return;
ep_op_has_event()实际就是判断op是不是删除操作:
static inline int ep_op_has_event(int op)
{
return op != EPOLL_CTL_DEL;
}-
接下来判断用户是否设置了EPOLLEXCLUSIVE标志,这个标志是4.5版本内核才有的,主要是为了解决同一个文件描述符同时被添加到多个epoll实例中造成的“惊群”问题,详细描述可以看这里。 这个标志的设置有一些限制条件,比如只能是在EPOLL_CTL_ADD操作中设置,而且对应的文件描述符本身不能是一个epoll实例,下面代码就是对这些限制的检查:
/*
*epoll adds to the wakeup queue at EPOLL_CTL_ADD time only,
* so EPOLLEXCLUSIVE is not allowed for a EPOLL_CTL_MOD operation.
* Also, we do not currently supported nested exclusive wakeups.
*/
if (epds.events & EPOLLEXCLUSIVE) {
if (op == EPOLL_CTL_MOD)
goto error_tgt_fput;
if (op == EPOLL_CTL_ADD && (is_file_epoll(tf.file) ||
(epds.events & ~EPOLLEXCLUSIVE_OK_BITS)))
goto error_tgt_fput;
}-
接下来从传入的文件描述符开始,一步步获得struct file对象,再从struct file中的private_data字段获得struct eventpoll对象:
struct fd f, tf;
struct eventpoll *ep;
...
f = fdget(epfd);
...
tf = fdget(fd);
...
ep = f.file->private_data;-
如果要添加的文件描述符本身也代表一个epoll实例,那么有可能会造成死循环,内核对此情况做了检查,如果存在死循环则返回错误。这部分的代码目前我还没细看,这里不再贴出。
-
接下来会从epoll实例的红黑树里寻找和被监控文件对应的epollitem对象,如果不存在,也就是之前没有添加过该文件,返回的会是NULL。
struct epitem *epi;
...
epi = ep_find(ep, tf.file, fd);-
ep_find()函数本质是一个红黑树查找过程,红黑树查找和插入使用的比较函数是ep_cmp_ffd(),先比较struct file对象的地址大小,相同的话再比较文件描述符大小。struct file对象地址相同的一种情况是通过dup()系统调用将不同的文件描述符指向同一个struct file对象。
static inline int ep_cmp_ffd(struct epoll_filefd *p1,
struct epoll_filefd *p2)
{
return (p1->file > p2->file ? +1:
(p1->file < p2->file ? -1 : p1->fd - p2->fd));
}-
接下来会根据操作符op的不同做不同的处理,这里我们只看op等于EPOLL_CTL_ADD时的添加操作。首先会判断上一步操作中返回的epollitem对象地址是否为NULL,不是NULL说明该文件已经添加过了,返回错误,否则调用ep_insert()函数进行真正的添加操作。在添加文件之前内核会自动为该文件增加POLLERR和POLLHUP事件。
if (!epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_insert(ep, &epds, tf.file, fd, full_check);
} else
error = -EEXIST;
if (full_check)
clear_tfile_check_list();
ep_insert()返回之后会判断full_check标志,该标志和上文提到的死循环检测相关,这里也略去。三、ep_insert()
-
ep_insert()函数中,首先判断epoll实例中监视的文件数量是否已超过限制,没问题则为待添加的文件创建一个epollitem对象:
int error, revents, pwake = 0;
unsigned long flags;
long user_watches;
struct epitem *epi;
struct ep_pqueue epq;
user_watches = atomic_long_read(&ep->user->epoll_watches);
if (unlikely(user_watches >= max_user_watches))
return -ENOSPC;
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
return -ENOMEM;-
接下来是对epollitem的初始化:
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
epi->nwait = 0;
epi->next = EP_UNACTIVE_PTR;
if (epi->event.events & EPOLLWAKEUP) {
error = ep_create_wakeup_source(epi);
if (error)
goto error_create_wakeup_source;
} else {
RCU_INIT_POINTER(epi->ws, NULL);
}-
接下来是比较重要的操作:将epollitem对象添加到被监视文件的等待队列上去。等待队列实际上就是一个回调函数链表,定义在/include/linux/wait.h文件中。因为不同文件系统的实现不同,无法直接通过struct file对象获取等待队列,因此这里通过struct file的poll操作,以回调的方式返回对象的等待队列,这里设置的回调函数是ep_ptable_queue_proc:
struct ep_pqueue epq;
...
/* Initialize the poll table using the queue callback */
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
/*
* Attach the item to the poll hooks and get current event bits.
* We can safely use the file* here because its usage count has
* been increased by the caller of this function. Note that after
* this operation completes, the poll callback can start hitting
* the new item.
*/
revents = ep_item_poll(epi, &epq.pt);-
上面代码中结构体ep_queue的作用是能够在poll的回调函数中取得对应的epollitem对象,这种做法在Linux内核里非常常见。
-
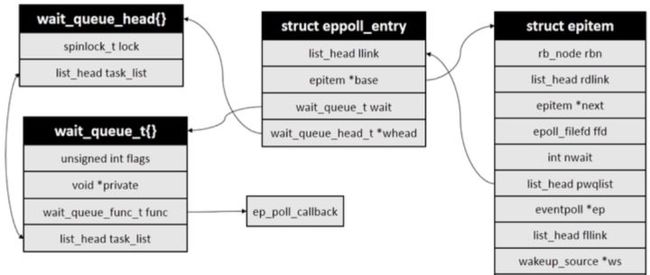
在回调函数ep_ptable_queue_proc中,内核会创建一个struct eppoll_entry对象,然后将等待队列中的回调函数设置为ep_poll_callback()。也就是说,当被监控文件有事件到来时,比如socker收到数据时,ep_poll_callback()会被回调。ep_ptable_queue_proc()代码如下:
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
if (epi->event.events & EPOLLEXCLUSIVE)
add_wait_queue_exclusive(whead, &pwq->wait);
else
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}-
eppoll_entry和epitem等结构关系如下图:
-
在回到ep_insert()函数中。ep_item_poll()调用完成之后,会将epitem中的fllink字段添加到struct file中的f_ep_links链表中,这样就可以通过struct file找到所有对应的struct epollitem对象,进而通过struct epollitem找到所有的epoll实例对应的struct eventpoll。
spin_lock(&tfile->f_lock); list_add_tail_rcu(&epi->fllink, &tfile->f_ep_links); spin_unlock(&tfile->f_lock);
然后就是将epollitem插入到红黑树中:1 ep_rbtree_insert(ep, epi) 最后再更新下状态就返回了,插入操作也就完成了。 在返回之前还会判断一次刚才添加的文件是不是当前已经有事件就绪了,如果是就将其加入到epoll的就绪链表中,关于就绪链表放到下一部分中讲,这里略过。
-
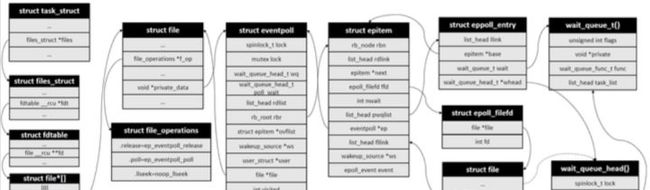
最后是我画的几个结构体之间的结构图。
四、分析如下
-
在通过epoll_ctl(2)向epoll中添加被监视文件描述符时,会将ep_poll_callback()作为回调函数添加被监视文件的等待队列中。下面分析ep_poll_callback()函数
1004 static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
1005 {
1006 int pwake = 0;
1007 unsigned long flags;
1008 struct epitem *epi = ep_item_from_wait(wait);
1009 struct eventpoll *ep = epi->ep;
1010 int ewake = 0;
1008行首先调用ep_item_from_wait()来获取到与被监视文件描述符相关联的结构体struct epitem,获取方法就是利用container_of宏。
1009行再根据struct epitem的ep字段获取到代表epoll对象实例的结构体struct eventpoll。
1012 if ((unsigned long)key & POLLFREE) {
1013 ep_pwq_from_wait(wait)->whead = NULL;
1014 /*
1015 * whead = NULL above can race with ep_remove_wait_queue()
1016 * which can do another remove_wait_queue() after us, so we
1017 * can't use __remove_wait_queue(). whead->lock is held by
1018 * the caller.
1019 */
1020 list_del_init(&wait->task_list);
1021 }-
判断返回的事件掩码里是否设置了标志位POLLFREE(什么时候会设置该标志?),如果是则将当前等待对象从文件描述符的等待队列中删除(疑问:注释是什么意思?为什么不需要加锁?)。
-
接下来对epoll的实例加锁:
1023 spin_lock_irqsave(&ep->lock, flags);-
接下来判断epitem中的事件掩码是不是并没有包括任何poll(2)事件,如果是的话,则解锁后直接返回:
1025 /*
1026 * If the event mask does not contain any poll(2) event, we consider the
1027 * descriptor to be disabled. This condition is likely the effect of the
1028 * EPOLLONESHOT bit that disables the descriptor when an event is received,
1029 * until the next EPOLL_CTL_MOD will be issued.
1030 */
1031 if (!(epi->event.events & ~EP_PRIVATE_BITS))
1032 goto out_unlock;-
什么时候会出现上述情况呢?注释里也说了,就是在设置了EPOLLONESHOT标志的时候。对EPOLLONESHOT标志的处理是在epoll_wait()的返回过程,调用ep_send_events_proc()的时候,如果设置了EPOLLONESHOT标志则将EP_PRIVATE_BITS以外的标志位全部清0:
1552 if (epi->event.events & EPOLLONESHOT)
1553 epi->event.events &= EP_PRIVATE_BITS;-
接下来判断返回的事件里是否有用户真正感兴趣的事件,没有则解锁后返回,否则继续。
1034 /*
1035 * Check the events coming with the callback. At this stage, not
1036 * every device reports the events in the "key" parameter of the
1037 * callback. We need to be able to handle both cases here, hence the
1038 * test for "key" != NULL before the event match test.
1039 */
1040 if (key && !((unsigned long) key & epi->event.events))
1041 goto out_unlock;-
如果此时就绪链表rdllist没有被其他进程访问,则直接将当前文件描述符添加到rdllist链表中,否则的话添加到ovflist链表中。ovflist默认值是EP_UNACTIVE_PTR,epoll_wait()遍历rdllist之前会把ovflist设置为NULL,遍历完再恢复为EP_UNACTIVE_PTR,因此通过判断ovflist的值是不是EP_UNACTIVE_PTR可知此时rdllist是不是正在被访问。
1049 if (unlikely(ep->ovflist != EP_UNACTIVE_PTR)) {
1050 if (epi->next == EP_UNACTIVE_PTR) {
1051 epi->next = ep->ovflist;
1052 ep->ovflist = epi;
1053 if (epi->ws) {
1054 /*
1055 * Activate ep->ws since epi->ws may get
1056 * deactivated at any time.
1057 */
1058 __pm_stay_awake(ep->ws);
1059 }
1060
1061 }
1062 goto out_unlock;
1063 }
1064
1065 /* If this file is already in the ready list we exit soon */
1066 if (!ep_is_linked(&epi->rdllink)) {
1067 list_add_tail(&epi->rdllink, &ep->rdllist);
1068 ep_pm_stay_awake_rcu(epi);
1069 }-
如果是描述符是添加到ovflist链表中,说明此时已经有ep_wait()准备返回了,因此不用再唤醒epoll实例的等待队列,因此1062行直接跳到解锁处;否则的话,则唤醒因为调用epoll_wait()而等待在epoll实例等待队列上的进程(这里最多只会唤醒一个进程):
1075 if (waitqueue_active(&ep->wq)) {
1076 if ((epi->event.events & EPOLLEXCLUSIVE) &&
1077 !((unsigned long)key & POLLFREE)) {
1078 switch ((unsigned long)key & EPOLLINOUT_BITS) {
1079 case POLLIN:
1080 if (epi->event.events & POLLIN)
1081 ewake = 1;
1082 break;
1083 case POLLOUT:
1084 if (epi->event.events & POLLOUT)
1085 ewake = 1;
1086 break;
1087 case 0:
1088 ewake = 1;
1089 break;
1090 }
1091 }
1092 wake_up_locked(&ep->wq);
1093 }-
如果epoll实例的poll队列非空,也会唤醒等待在poll队列上的进程,不过是在解锁后才会进行唤醒操作。
1094 if (waitqueue_active(&ep->poll_wait))
1095 pwake++;-
最后解锁并返回:
1097 out_unlock:
1098 spin_unlock_irqrestore(&ep->lock, flags);
1099
1100 /* We have to call this outside the lock */
1101 if (pwake)
1102 ep_poll_safewake(&ep->poll_wait);
1103
1104 if (epi->event.events & EPOLLEXCLUSIVE)
1105 return ewake;
1106
1107 return 1;-
注意到ep_poll_callback()的返回值和EPOLLEXCLUSIVE标志有关,该标志是用来处理这种情况:当多个进程中的不同epoll实例在监视同一个文件描述符时,如果该文件描述符上有事件发生,则所有的epoll实例所在进程都将被唤醒,这样有可能造成“惊群”(thundering herd)。
五、epoll惊群原因分析
-
考虑如下情况(实际一般不会做,这里只是举个例子):
在主线程中创建一个socket、绑定到本地端口并监听 在主线程中创建一个epoll实例(epoll_create(2)) 将监听socket添加到epoll中(epoll_ctl(2)) 创建多个子线程,每个子线程都共享步骤2里创建的同一个epoll文件描述符,然后调用epoll_wait(2)等待事件到来accept(2) 请求到来,新连接建立 这里的问题就是,在第5步的时候,会有多少个线程被唤醒而从epoll_wait()调用返回?答案是不一定,可能只有一个,也可能有部分,也可能是全部。当然在多个线程都唤醒的情况下,只会有一个线程accept()调用会成功。
-
为何如此?从内核代码分析,原因如下:
在调用epoll_wait(2)的时候,设置的epoll的等待队列回调函数是default_wake_function,添加队列的时候调用的是
__add_wait_queue_exclusive()。
ep_poll_callback()中唤醒操作调用的是wake_up_locked(&ep->wq),最终会调用__wake_up_common,后者会判断exclusive标志:
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
unsigned flags = curr->flags;
if (curr->func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}-
因为__wake_up_common()的调用是从wake_up_locked()开始的,__wake_up_common的各个参数值为:
q: struct eventpoll.wq
mode: TASK_NORMAL
nr_exclusive:1
wake_flags: 0
key:NULL。-
局部变量curr的值可以通过epoll_wait()的源码得到,具体为:
curr->flags: WQ_FLAG_EXCLUSIVE curr->func: default_wake_function default_wake_function调用的是try_to_wake_up。而try_to_wake_up只有在要唤醒的进程状态不是TASK_NORMAL时才会返回0,TASK_NORMAL的定义是(TASK_INTERRUPTIBLE | TASK_UNINTERRUPTIBLE)。
-
因此__wake_up_common里的if条件会在第一次判断的时候就满足,唤醒一个进程后便返回了,那为什么实际测试会发现有多个进程被唤醒呢?
-
原因就在于这个唯一被唤醒的进程。
-
当某个等待在epoll实例上的进程被唤醒后,最终会进入到ep_scan_ready_list() 这个函数中,ep_scan_ready_list()会以回调方式调用ep_send_events_proc()来将数据复制到用户空间。而ep_scan_ready_list()函数在返回之前会再次判断epoll的就绪链表rdllist是否为空,如果不为空的话,就会再唤醒其他进程!下面就是ep_scan_ready_list()返回之前的判断操作:
if (!list_empty(&ep->rdllist)) {
/*
* Wake up (if active) both the eventpoll wait list and
* the ->poll() wait list (delayed after we release the lock).
*/
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}-
而在水平触发方式下,从就绪链表中移出来的文件描述符,如果当前仍有事件就绪(可读、可写等),会在复制到用户空间后被再次添加到就绪链表中:
if (epi->event.events & EPOLLONESHOT)
epi->event.events &= EP_PRIVATE_BITS;
else if (!(epi->event.events & EPOLLET)) {
/*
* If this file has been added with Level
* Trigger mode, we need to insert back inside
* the ready list, so that the next call to
* epoll_wait() will check again the events
* availability. At this point, no one can insert
* into ep->rdllist besides us. The epoll_ctl()
* callers are locked out by
* ep_scan_ready_list() holding "mtx" and the
* poll callback will queue them in ep->ovflist.
*/
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
}-
因此在水平触发模式下,被唤醒的进程又会去唤醒其他进程,除非当前事件已经被处理完或者所有进程都已经被唤醒(被唤醒的进程会从epoll等待队列上移除)。