爬虫取中间文本_掌握这几个知识,零基础学爬虫技术不是异想天开
爬虫技术门槛不高,想要从头自学爬虫,“工欲善其事,必先利其器”,Python功能强大,语法简洁易上手,是网络爬虫的有力工具,建议用Python语言入手。
韦世东,资深爬虫工程师,《Python 3 反爬虫原理与绕过实战》的作者,他就是从互联网运营岗位的小白自学Python,转行成为资深爬虫工程师。
爬虫路要怎么走?他说提前规划十分有必要。结合自身从小白开始学爬虫的经历,他给初学者提出了 5 个建议。希望对题主有所帮助。
这份爬虫的武林秘籍您收好!

1. 从入门到大师,中间还有多少坑
入门爬虫并不难,但是爬虫作为一门综合技术,需要爬虫工程师具备很强的综合能力。
不仅要对数据抽取、网络请求有所了解,前端、后端、APP、甚至是 PC 端的应用程序都要了解。在这个过程中,你需要迈过 3 个难点。
JavaScript 就是其中之一。它会给实际操作带来一定困难,比如,代码混淆、参数加密,还有一些响应事件,你必须用鼠标点击才能完成的操作,这要求你一定要了解 JavaScript。
APP 是另一个难点。除了代码混淆、参数加密之外,APP 还会在外面加个壳然后加固,就算你逆向,也很难看到它的代码。
深度学习是第三个难点。深度学习是目前各大行业都在融入的技术领域。用深度学习进行验证码识别、字体反爬等。
我发现很多朋友其实对于验证码识别、JavaScript 混淆、WebSocket 和字体反爬虫有一种莫名的恐惧感,觉得这些是很难解决的问题。
实际上,只要我们了解其工作原理,就能够找到突破口。爬虫与反爬虫都是综合知识的应用,单纯了解某个反爬虫的实现方法或绕过技巧是不够的,我们应该深入了解其实现原理,这样才能够在爬虫工程师的职业道路上走得更远。

2. 三分钟热度,我该如何坚持下去
坚持是一件很难的事。从初级爬虫工程师成长为高级爬虫工程师,中间必然要经过很多困难。切记三分钟热度,要学会给自己设置阶段性的小目标。
第一阶段:储备好基础知识,先找到一份爬虫相关的工作,着手锻炼。这个阶段,你可以在社群里试着帮助其他小伙伴解决问题,收获肯定和成就感,给自己一个前进的动力。
第二阶段:随着业务量的不断增加,你需要储备更多的知识,开始接触到爬虫的更深层次。
第三阶段:任何爬虫工程师都会接触到反爬虫,你在爬取别人家数据的同时,也要防止自己的数据被爬取。
第四阶段:要追求数据的精细化和精准化。
在学习的过程中,你肯定会遇到操作上的各种问题。这时候要勤翻文档、多读源码,也可以把自己解决问题的过程写成技术文章,转变角度去看问题,问题似乎迎刃而解。
让知识从吸收再到转化,从不懂到了解再到掌握。另外,通过自己的技术输出,还能让爬虫产生价值,转化为收入。
你可以将自己的技术历程写成一本书,或者一个博客,或者制作成一节直播课,这些不仅可以帮助其他入门的开发者,也是推动你继续学习的动力。

3. 为何我感觉越来越困难
无论是在学习的过程中还是工作中,我总会遇到千奇百怪的需求和反爬虫。
作为一名爬虫工程师,你注定会遇到奇葩的需求和反爬虫。这就像后端研发要面对产品经理和并发挑战一样,更像学武之人要经常与不同的对手切磋武艺一样。
遇到这些,只会使你变得更强!
虽然不停地学习,也略有进步,但总感觉遇到的挑战越来越困难。
如果你遇到了上面这些问题,说明你正处于技术瓶颈期。瓶颈期来的越早,说明你进步越快。
如何突破瓶颈期呢?
坚持和学习是让你能够撑到突破瓶颈的最好办法,虽然你会感觉很难熬。解决技术问题的最好方式不是看书就是做实验,如果你遇到的问题能够通过学习解决,那赶紧买本书或者买一份教程;如果你遇到的问题不能通过学习解决,那就多做一些实验。
必杀技:有时候几天想不出来的问题,出去逛一逛,回来就会有新的思路了。
工作很忙,每天大部分时间都是写路径查找语法(Xpath、CSS 选择器),学习和研究的时间很少,似乎很难再有进步。
对于路径查找语法,想必你早已了然于胸。你可以尝试跟公司领导进行交流,看看是否能减少些路径查找语法的工作量(这类型工作通常交给新入职的工程师或者实习生,一方面能够让其快速熟悉业务,另一方面能够减少技术主力的重复工作量),将更多的时间放在技术难点的研究上。
4. 爬虫工程师的职业路径
如果你是一个爬虫工程师,那你大概率是一个 Python 开发者。从入门 Python 到成为一个爬虫工程师,大致路线是这样:Python 开发者——爬虫入门——初级爬虫工程师......
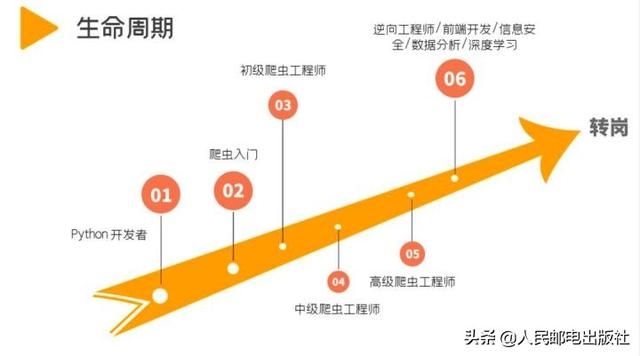
爬虫职位,一线城市居多。在数据驱动型的公司里,爬虫工程师会比较受重视。从初级爬虫工程师到高级爬虫工程师,因为承担责任的不同,薪水在 10k 到 30k 之间浮动。

爬虫工程师每天都要面对不断变化的网页,充满了新鲜感与挑战。有时候你觉得这份工作还不错,但是有时候又觉得工作不是特别好,所以要不要转行,一直是你纠结的问题。
与其纠结,不如选择扎根目前的领域,垂直下来,切忌摇摆不定。毕竟中途转行,一切又要从头开始,薪水对折,还要重新学习其他领域的新知识。这中间的得失,要慎重考虑。

5. 爬虫究竟合不合法
2010 年,软件工程师 Pete Warden 因构建了一个网络爬虫从 Facebook 上收集数据,而收到 Facebook 的一封勒令停止通知函。他立刻停止了自己的行动。有人问他为什么要依从 Facebook 的要求,他说:“大数据虽然很便宜,但律师费可不便宜。”
所以君子之间,要遵守 robots 协议。
大数据时代,很多公司通过使用网络爬虫来采集公开信息。虽然目前还没有一条完全针对爬虫的法律条款,但爬虫工程师们心里还是要有一条线,千万不要踩过界。不然稍有不慎就可能从入门到入狱。
日常爬虫工作中,一些注意事项要了然于胸。涉及到个人隐私、企业详细信息的不能爬。一些具有商业用途的数据、版权类数据或者是机密信息,也不能爬。
在做爬虫工作时,应注意控制爬虫的访问频率,当爬虫程序所产生的流量超过网站流量的 1/3,如果出现任何问题,你是要负责的。
还要注意数据的最终流向,是否被用作违法用途。如果你违法破解了别人的产品,还将具体方法公开,这也是不被允许的。
另外,不是所有的数据都能被分享的,在熟练业务的同时也要注意这些法律问题,免得给自己或者公司带来麻烦。
如果你是一名爬虫工程师,那以上的问题你在工作中都可能会遇到。快速上手爬虫虽然不是难事,但贵在坚持,多读源码,多看文档。希望每一个正在入门和学习爬虫的你,都能静下心来,认真学习,实现突破。
王国维在《人间词话》中说:
古今之成大事业、大学问者,必经过三种之境界: “昨夜西风凋碧树,独上高楼,望尽天涯路。” 此第一境也。 “ 衣带渐宽终不悔,为伊消得人憔悴。” 此第二境也。“众里寻他千百度,蓦然回首,那人却在,灯火阑珊处。”此第三境也。
也就是说,经过第一阶段的登高望远,总结和学习前人经验,和第二阶段为实现目标专注、坚持不懈地学习,方能实现第三阶段的豁然开朗,有所建树。与君共勉!
本文转自图灵教育,作者韦世东,有改动。
相关阅读:
《Python 3反爬虫原理与绕过实战》

韦世东 著
本书适合有工作实践的爬虫工程师和前、后端开发者。
本书分为红和蓝,进攻和防守两端,爬虫工程师就是红色方,进攻方,前后端开发者要保护他们的数据,增加爬虫程序对数据获取的难度,就是蓝色防守方,从“攻”与“防”两个角度描述了爬虫技术与反爬虫技术的对抗过程,并详细介绍了这其中的原理和具体实现方法。
通过这本书,你将了解到签名验证、文本混淆、动态渲染、加密解密、代码混淆和行为验证码等反爬虫技术的成因和绕过方法。掌握这些知识后,你的理论基础将非常扎实,能够轻松应对一线大厂中高级爬虫工程师面试的理论和思路问题。
实战方面,除了本书搭建的 21 个在线练习示例之外,还结合工作中遇到的综合反爬虫进行演练,从而稳步提升个人技术实力。
韦世东老师图灵直播回看:
1.爬虫工程师‘养成’指南,如何规划职业成长路径
https://www.bilibili.com/video/av83667121?
2.手把手教你Python源码的阅读和调试
https://www.bilibili.com/video/av91303459?
《Python3网络爬虫开发实战》

崔庆才 著
本书首先介绍了环境配置和基础知识,然后讨论了urllib、requests、正则表达式、Beautiful Soup、XPath、pyquery、数据存储、Ajax数据爬取等内容,接着通过多个案例介绍了不同场景下如何实现数据爬取,最后介绍了pyspider框架、Scrapy框架和分布式爬虫。
内容丰富,基本上涵盖了从入门到初级爬虫工程师,甚至到中级爬虫工程师阶段需要用到的知识。